
文章目录
- Abstract
- Introduction
- [Related Work](#Related Work)
-
- [Semantic Segmentation and Semantic Mapping](#Semantic Segmentation and Semantic Mapping)
- [Layout estimation and view synthesis](#Layout estimation and view synthesis)
- [Learning in Simulation Environments](#Learning in Simulation Environments)
- [CROSS-VIEW SEMANTIC SEGMENTATION](#CROSS-VIEW SEMANTIC SEGMENTATION)
-
- [Problem Formulation](#Problem Formulation)
- [Framework of the View Parsing Network](#Framework of the View Parsing Network)
- [Sim-to-real Adaptation](#Sim-to-real Adaptation)
- [Network configuration](#Network configuration)
- Conclusion
Abstract
感知环境在人类空间感知中起着至关重要的作用,它从观察中提取物体的空间形态以及自由空间。为了使机器人具有这种周围感知能力,我们引入了一种新的视觉任务,称为跨视图语义分割,以及一个名为视图解析网络(VPN)的框架来解决它 。在跨视图语义分割任务中,训练智能体将第一视图的观察结果解析成一个自上而下的语义图,该图在像素级上指示所有对象的空间位置。这项任务的主要问题是我们缺乏对自顶向下视图数据的真实注释。为了解决这个问题,我们在3D图形环境中训练VPN,并利用域适应技术将其传输到处理现实世界的数据。我们在合成代理和真实代理上评估我们的VPN。实验结果表明,该模型可以有效地利用不同视角和多模态的信息来理解空间信息。我们在LoCoBot机器人上的进一步实验表明,我们的模型能够从2D图像输入中实现周围感知能力
Introduction
语义理解的最新进展使机器感知能够将场景精确地分割为有意义的区域和对象1,2。这些语义分割技术已经为许多自动化应用带来了好处,比如自动驾驶。虽然语义分割网络可以识别静态图像中的语义内容,但它还远远不足以使机器人在未知环境中感知并在其中自由导航。一个重要的原因是,解析后的第一视图语义掩码仍然是纯图像级的,没有提供任何关于周围环境的重要信息。为了从纯图像输入中感知空间配置,一种直观的方法是显式训练网络来推断直接包含周围环境空间配置信息的自上而下的语义图。基于自顶向下的语义图,我们可以推断出周围区域和物体的位置坐标和功能属性。
为了使机器能够从2D图像中捕获周围环境的空间结构,我们探索了一种新的基于图像的场景理解任务,即跨视图语义分割 。与标准语义分割预测输入图像中每个像素的标签不同,交叉视图语义分割旨在从一组第一视图观察结果中预测自上而下的语义图(如图1所示)。所得的自上而下的语义图作为周围环境的2.5D空间表示,表示了椅子和人等离散物体的空间布局,以及地板和墙壁等物品类别。请注意,虽然有大量的3D方法重建环境的文献,但我们的方法有其独特的优势。例如,基于三维传感器的机器人感知系统不仅在传感器设置上成本昂贵,而且在计算能力上也很昂贵。相反,交叉视图语义分割的自上而下视图地图可以帮助机器人以轻量级和高效的方式了解其周围环境。在许多情况下,如移动机器人的自由空间探索,高度信息不是那么重要,2D自顶向下的语义地图足以提供空间信息,而且计算成本要低得多。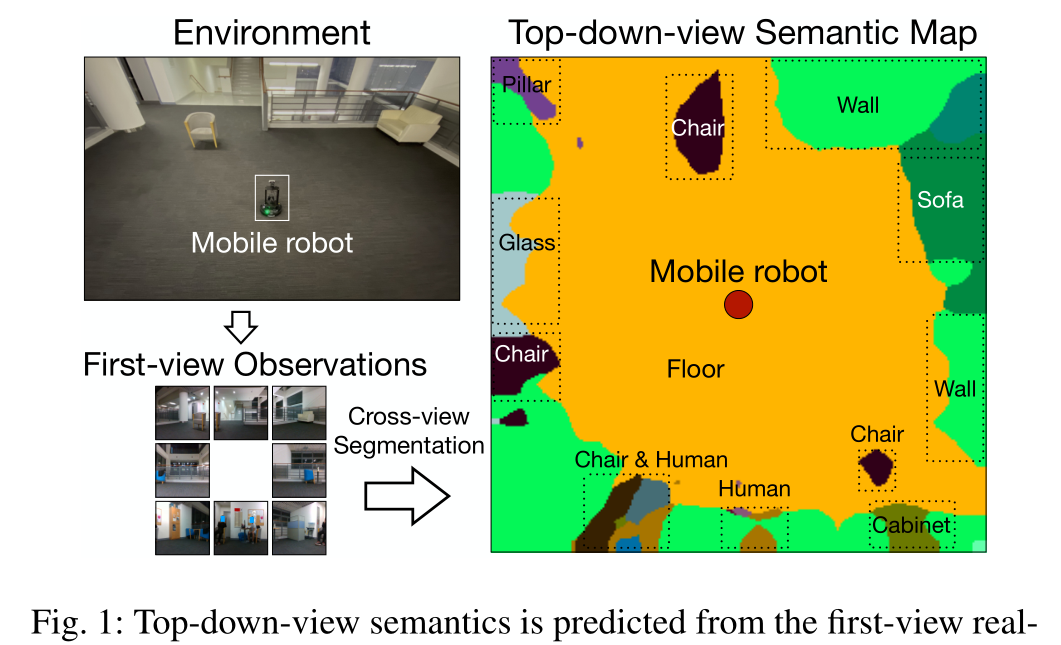
在跨视图语义分割中,自上而下的语义是根据第一视图真实世界的观察结果来预测的。来自多个角度的输入观测被融合。请注意,此图中的结果是在没有对真实数据进行训练的情况下生成的。
跨视图语义分割的难点之一是难以收集自顶向下的语义标注。最近,人们提出了House3D5和CARLA6等仿真环境来训练导航智能体,在这些环境中,摄像机可以放置在模拟场景的任何位置,同时可以提取多种模态的观测结果。因此,我们利用模拟环境来获取跨视图注释数据。为了缩小合成场景与真实场景之间的领域差距,我们通过领域适应将仿真环境中训练的模型转移到真实场景中。
在这项工作中,我们提出了一个具有视图解析网络(VPN)的新框架,用于使用模拟环境进行跨视图语义分割,然后将其转移到现实环境中。在VPN中,设计了一个视图转换模块,用于聚合多个不同角度、不同模态的第一视图观测信息。它输出带有对象空间布局的自顶向下视图语义图。我们在House3D环境的室内场景5和CARLA环境的室外驾驶场景6上对所提出的模型进行了评估。此外,为了展示跨视图语义任务对视觉导航的帮助,我们进行了真实机器人的演示。
我们的主要贡献如下:(1)我们引入了一种新的任务,称为跨视图语义分割,使机器人能够灵活地感知周围环境。(2)提出了一种基于视图解析网络的框架,该框架可以有效地学习和聚合多角度、多模式的首视图观测数据的特征。(3)我们进一步应用领域自适应技术来转移我们的模型,使其可以在没有任何额外注释的情况下工作在真实数据中。
Related Work
Semantic Segmentation and Semantic Mapping
用于语义分割的深度学习网络7设计用于在一个视图内按像素分割图像。带有逐像素注释的图像数据集(如cityscape3)用于语义分割网络的训练。在机器人领域1,2,8,9中也有大量关于语义映射的文献,它提供了环境的语义抽象和与机器人通信的方法。
Layout estimation and view synthesis
布局估计一直是一个活跃的研究课题(即房间布局估计10,空闲空间估计11,道路布局估计12,13)。以前的方法大多使用布局或几何约束的注释进行估计,而我们提出的框架直接从图像中估计自顶向下的视图地图,而不需要中间步骤估计场景的3D结构。另一方面,视图合成已经在许多著作14,b15中进行了探讨。它们的重点是生成逼真的横视图像,而横视分割的目的是解析不同视图之间的语义。
Learning in Simulation Environments
考虑到当前的图形仿真引擎可以渲染逼真的场景,识别算法可以在从仿真引擎提取的数据上进行训练(例如,对于视觉导航模型16)。当用模拟图像训练的模型转移到真实场景时,已经提出了几种技术来解决领域自适应问题。我们的工作不是直接处理视觉导航任务,而是从第一视图观察中解析自顶向下的语义图。由此产生的自顶向下视图地图将进一步促进视觉导航。
CROSS-VIEW SEMANTIC SEGMENTATION
Problem Formulation
跨视图语义分割的目标是:给定第一视图的观测值作为输入,算法必须生成自顶向下的语义图。自顶向下的语义图是摄像机在自顶向下的一定高度上拍摄的地图,并对每个像素的语义标签进行标注。输入的第一视图观测值是一组具有不同模态的图像。机器人的摄像头以N个不同的角度捕捉它们(360度/N度间隔)。
Framework of the View Parsing Network
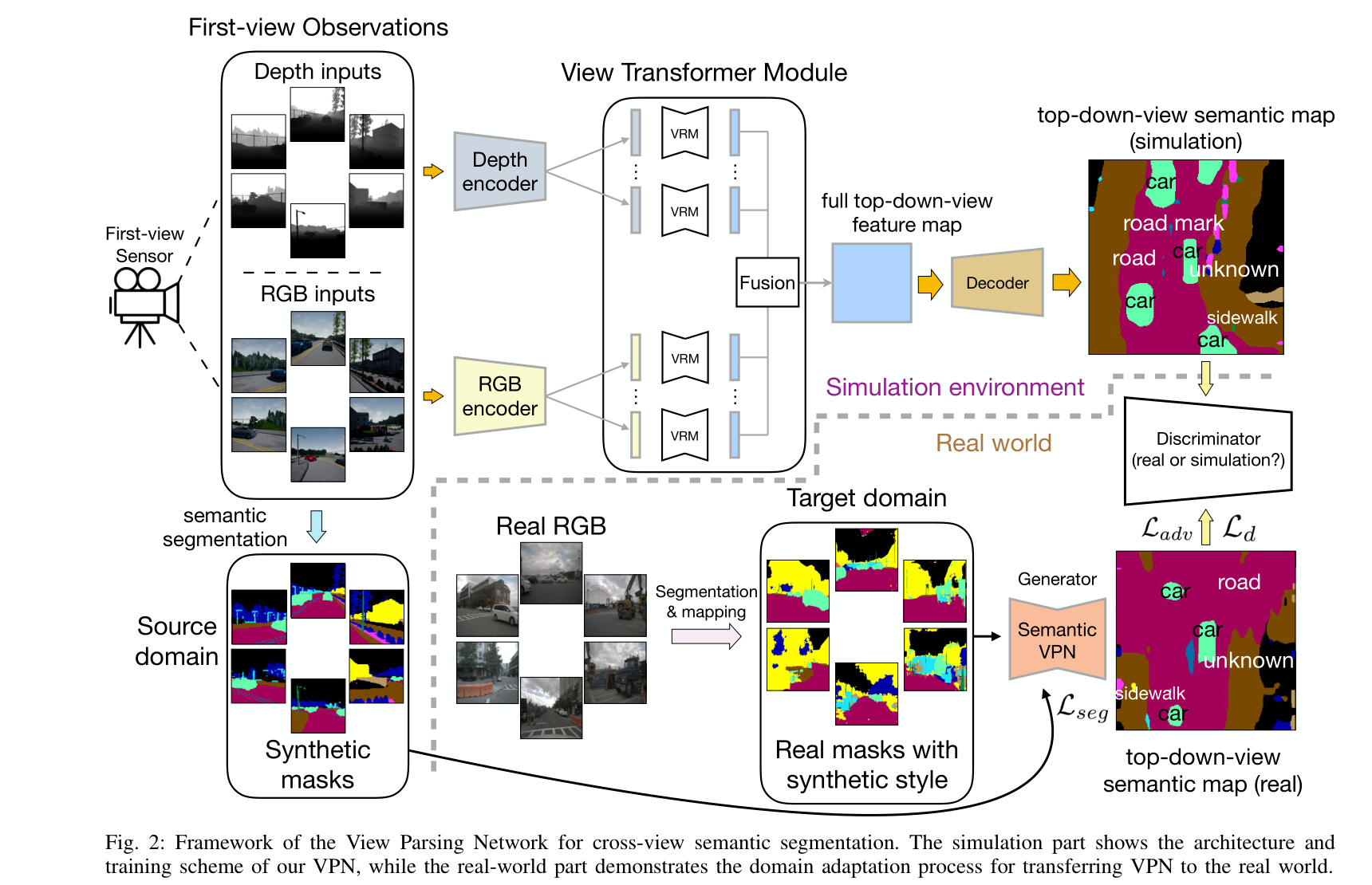
面向跨视图语义分割的视图解析网络框架。仿真部分展示了我们的VPN的体系结构和训练方案,而现实部分展示了将VPN转移到现实世界的域适应过程。
图2说明了我们的框架的两个阶段。在第一阶段,我们提出了视图解析网络(VPN)来学习和聚合仿真环境中多个第一视图观察的特征。在VPN中,首先将第一视图观测值输入编码器以提取第一视图特征映射。对于每种模式,VPN都有相应的编码器来处理它。所有这些来自不同角度和不同模式的第一视图特征图都被转换,然后在视图转换模块中聚合成一个自顶向下的特征图。然后将聚合的特征图解码为自顶向下的语义图。如何转换和聚合这些第一视图特征图的细节可以在第III-D节中找到。在框架的第二阶段,我们将VPN从模拟环境中学到的知识转移到现实世界的数据中。为了适应我们的跨视图语义分割任务和我们的VPN架构,我们对17提出的域自适应算法做了一些修改。这部分的更多细节将在第III-C节中披露。
查看变压器模块。尽管编码器-解码器结构在经典语义分割区域7中取得了巨大的成功,但我们的实验(参见表III)表明,它在跨视图语义分割任务中表现不佳。如图2所示,从三维环境中的一个空间位置,我们首先以偶数角度从N个角度和M种模式(图2中N = 6,M = 2)采样N×M第一视角观测,以便捕获全面的信息。第一视图观测分别由M个编码器对M个对应模态进行编码。这些基于cnn的编码器提取了N × M个空间特征映射作为第一视图输入。然后将所有这些特征映射输入视图转换模块(VTM)。VTM将这些视图特征图从首视空间转换为自顶向下的特征空间,并进行融合,得到一个包含足够空间信息的最终特征图。最后,利用卷积解码器对其进行解码,预测自顶向下的语义图。我们推测这是因为在标准的语义分割架构中,输出空间特征图的接受野与输入空间特征图大致对齐。然而,在跨视图语义分割中,自上而下视图图上的每个像素都应该考虑所有输入的第一视图特征图,而不仅仅是一个局部的接受域区域。
针对当前语义分割结构的缺陷,设计了视图转换模块(View Transformer module - ule, VTM)来学习首视特征图与自顶向下特征图之间所有空间位置的依赖关系。VTM不会改变输入特征映射的形状,因此它可以插入到任何现有的编码器-解码器类型的网络架构中进行经典的语义分割。它由VRM (View Relation Module)和VFM (View Fusion Module)两部分组成。图2中心的图表说明了整个过程:第一个视图特征图首先被平面化,而通道尺寸保持不变。然后,我们使用视图关系模块R来学习平坦的首视图特征图和平坦的自上而下特征图中任意两个像素位置之间的关系。那就是:
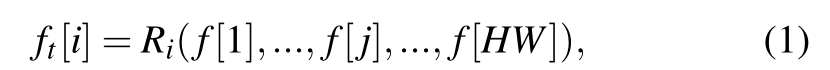
其中i,j∈[0,HW)分别为自上而下特征图t∈RHW×C和首视特征图f∈RHW×C沿平坦维度的索引,Ri为自上而下特征图第i个像素与首视特征图每个像素之间的关系建模。
在这里,我们简单地在视图关系模块r中使用多层感知器(MLP)。之后,自上而下的视图特征映射被重塑回H ×W ×C。注意,每个第一视图输入都有自己的VRM,以便根据自己的观察结果获得自顶向下的特征映射ti∈RH×W×C。为了聚合所有观测输入的信息,我们使用VFM将这些自上而下的特征图融合在一起。
Sim-to-real Adaptation
为了将我们的VPN推广到真实世界的数据,而不需要真实世界的真实情况,我们实现了如图2所示的模拟到真实的域自适应方案来缩小差距。该方案包括像素级自适应和输出空间自适应。进行像素级适应。为了减轻域移位,我们对现实世界的输入采用像素级自适应,使它们看起来更像模拟数据的风格。语义掩码是一种理想的中层表示,没有纹理间隙,同时包含足够的信息,易于传递。这一过程可表述如下: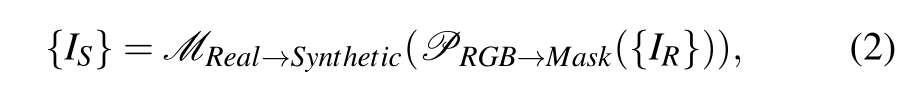
其中IR、IS分别是真实的RGB图像和合成风格的语义掩码,PRGB→mask是现有的语义分割模型,将真实世界的RGB解析为语义掩码,MReal→Synthetic是构建真实世界与仿真环境之间的概念映射的语义类别映射过程。
输出空间自适应。除了输入数据的像素级转移之外,我们还基于17中提出的方法设计了结构化输出空间的对抗训练方案。这里的生成器G是一个视图解析网络,生成自顶向下的视图预测P,如我们前面所示,它由在仿真环境中对语义数据进行训练的VPN的权重初始化。在训练阶段,我们首先将一组输入图像从源域{Is}转发到G,并使用正态分割损失Lseg对其进行优化。然后使用G从目标域{It}提取图像的特征映射Fi (softmax层后),并使用鉴别器区分Ft是否来自源域。对G进行优化的损失函数可以写成: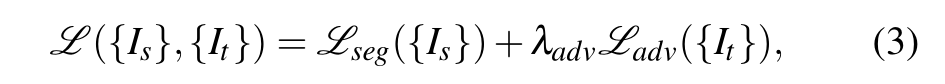
其中Lseg是用于语义分割的交叉熵损失,Ladv用于训练G并欺骗鉴别器d。鉴别器Ld的损失函数是用于二元源和目标分类的交叉熵损失。
Network configuration
为了平衡效率和性能,我们使用ResNet-18作为编码器。我们去掉了最后一个残差块和平均池层,使得编码特征图的分辨率仍然很大,从而更好地保留了视图的细节。我们使用7中使用的金字塔池模块作为解码器。对于每个视图关系模块,我们只使用两层MLP。我们选择这个是因为两层MLP不会带来太多额外的计算,因此我们可以保持我们的模型遵循轻量级和高效的基本原理。VRM的输入和输出维度均为HIWI,其中HI和WI分别为中间特征图的高度和宽度。至于视图融合模块,我们只是添加了所有的特征,以保持形状的一致性。对于生成器G,我们使用4视图VPN的体系结构。对于鉴别器D,我们在17中采用了相同的架构。它有5个卷积层,每个卷积层后面都有一个参数为0.2的泄漏ReLU(最后一层除外)。我们使用HRNet18对cityscape数据集3进行预训练,从真实世界的图像中提取语义掩码。
Conclusion
在这项工作中,我们提出了跨视图语义分割任务来感知环境,并设计了一个神经架构视图解析网络(VPN)来解决这个问题。基于实验结果,我们证明了VPN可以应用于移动机器人,通过轻量级和高效的自顶向下的语义图来促进周围感知。在许多情况下,物体的高度信息不重要,VPN可以是一个不错的选择相比,传统的3 d - base方法是昂贵的数据存储器和计算。