文章目录
前言
保证消息的到达是使用MQ的一个关键也是一个前提
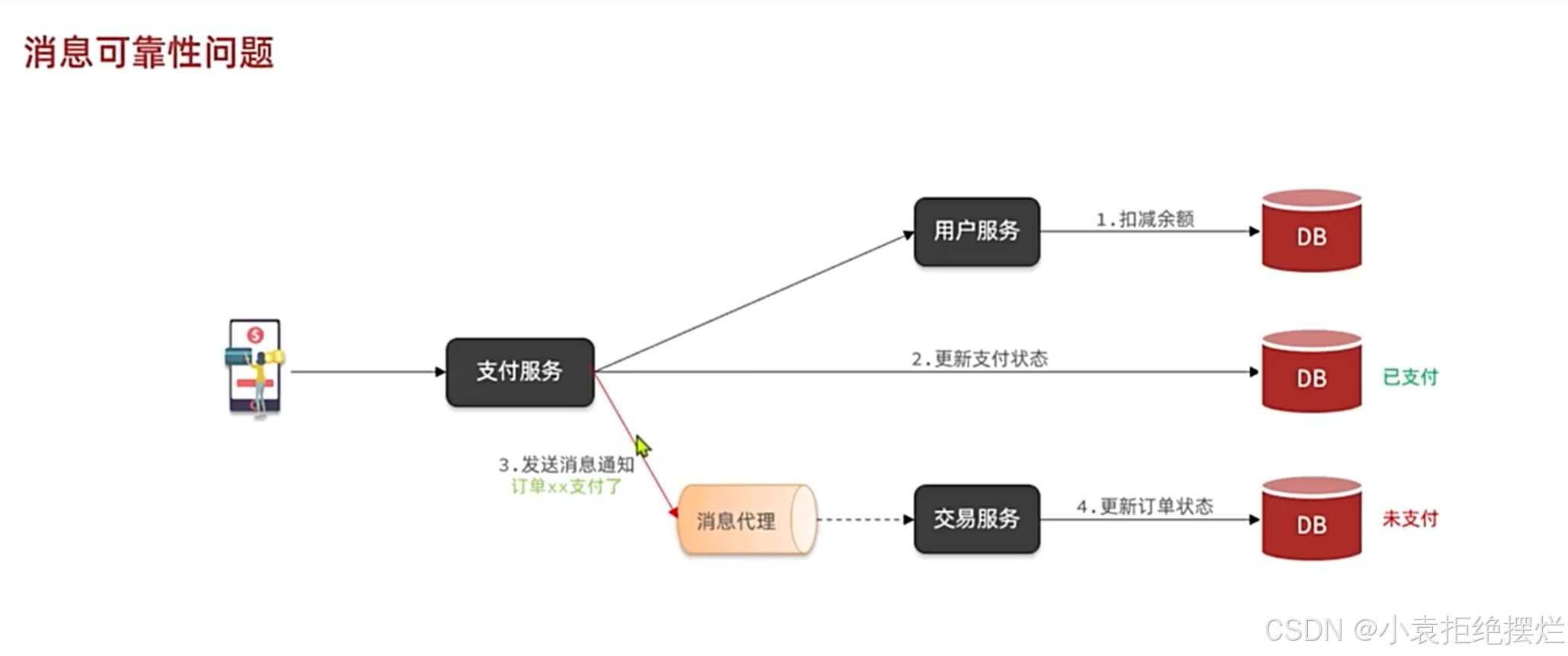
MQ消息达不到数据库有三种可能
1.发送消息的支付服务因为网络波动等原因消息为发出去2.mq挂了,消息没转发出去3.交易服务挂了,没有收到信息
下面解决方案也是主要针对这三种情况进行解决
但就算解决也不能保证100%不丢失,所以会有一些二兜底方案-延迟消息

发送者可靠性
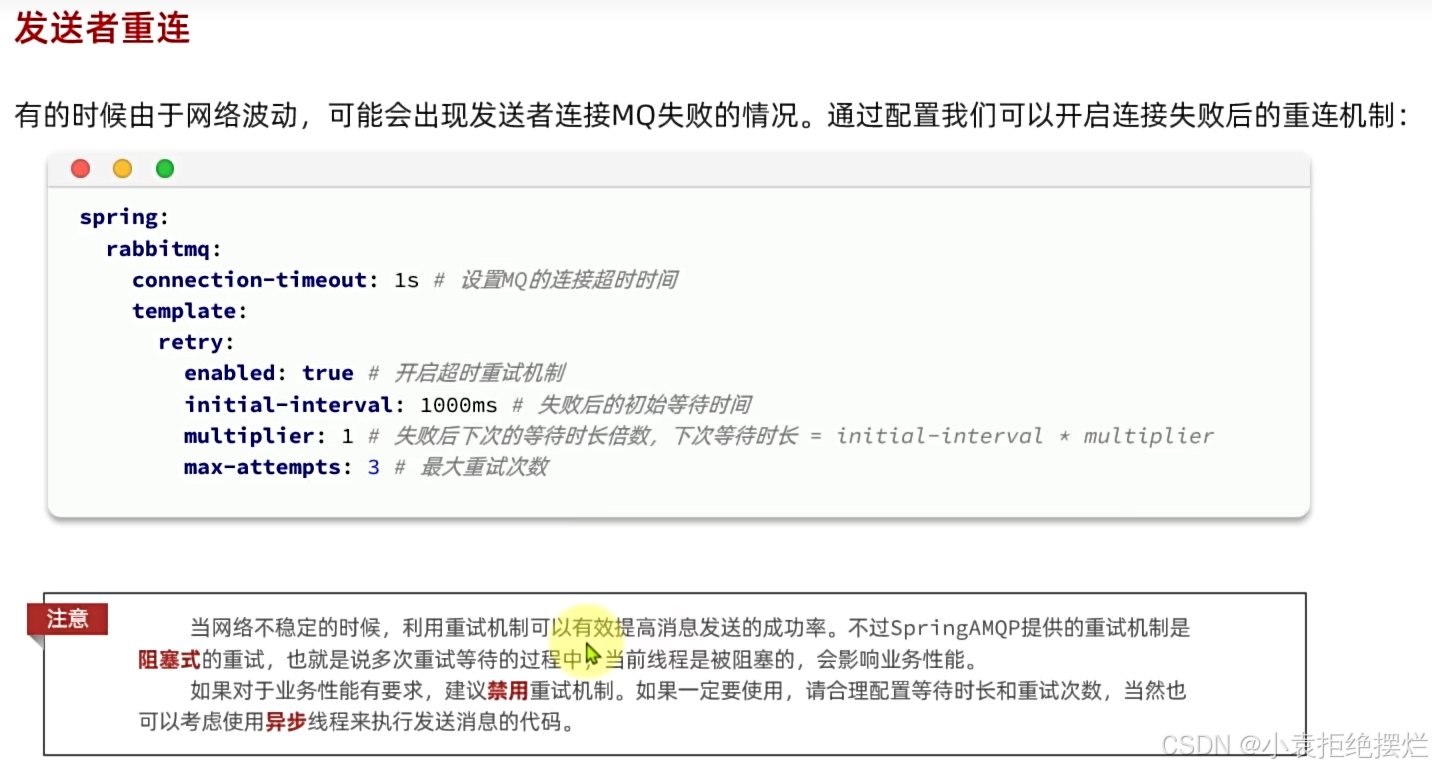
发送者重连
下面是发送者重连的配置,只需要在配置文件中配置即可(默认是不开启的)
很好理解
就是生产者和mq之间建立连接超时就算发送失败
等待时长就是你网络波动可能是一会,所以你等待一段时间再发的话成功概率更大
注意:阻塞等待充实会影响性能
发送者确认(一般不会开启)
发送者确认机制,就是发送者给RabbitMQ发消息,然后rabbitmq收到/没收到消息给予回应

发送者确认三种返回ACK情况
路由异常一般是我们没配队列queue或者说我们传入了错误的rounting key导致找不到queue,是由我们程序员自己导致的,但是消息确实发到交换机了所以会返回ACK
临时消息就是不需要持久化的,入队就会返回ack
持久化消息是入队且完成持久化才会返回ack
如何开启确认机制?
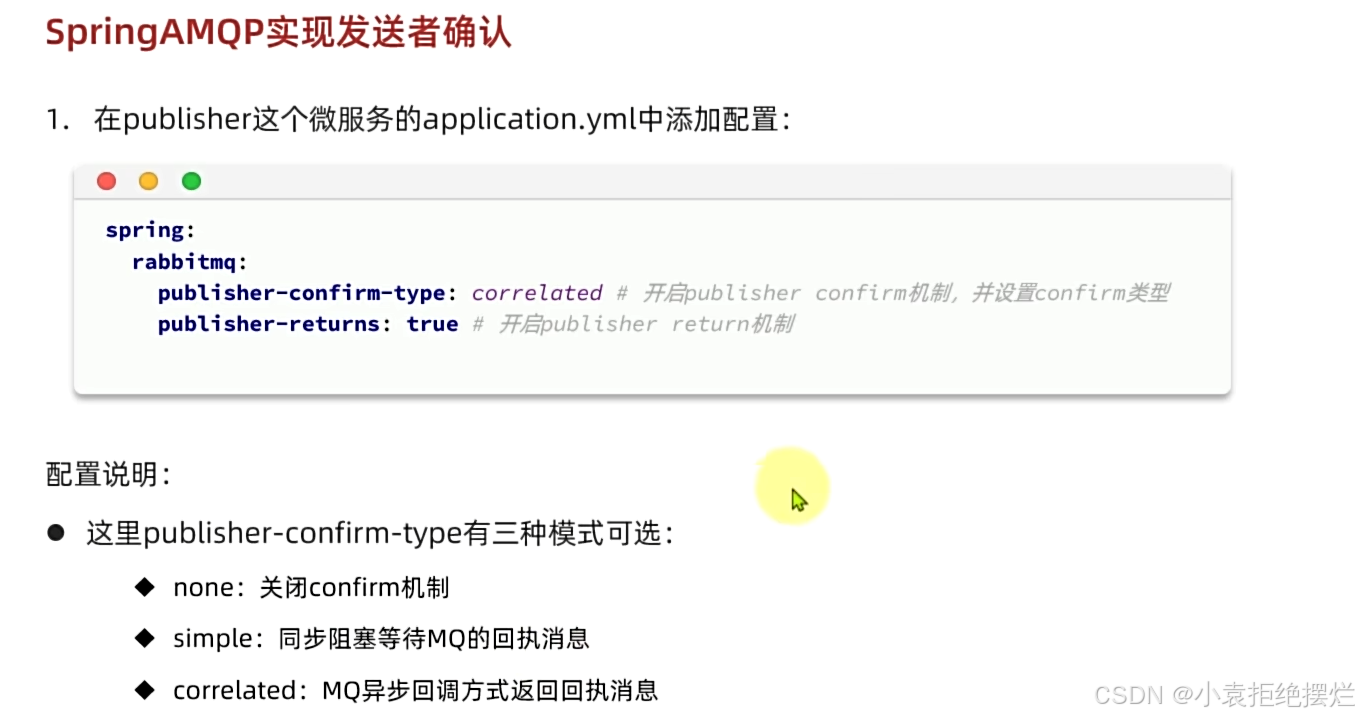
这里我们一般会选择none或者correlated
指定returncallback和confrimfallback
returncallback用来定义返回信息的格式,而且多次配置无效
所以我们在配置类时候配置一次即可,到时候注入进去用就行

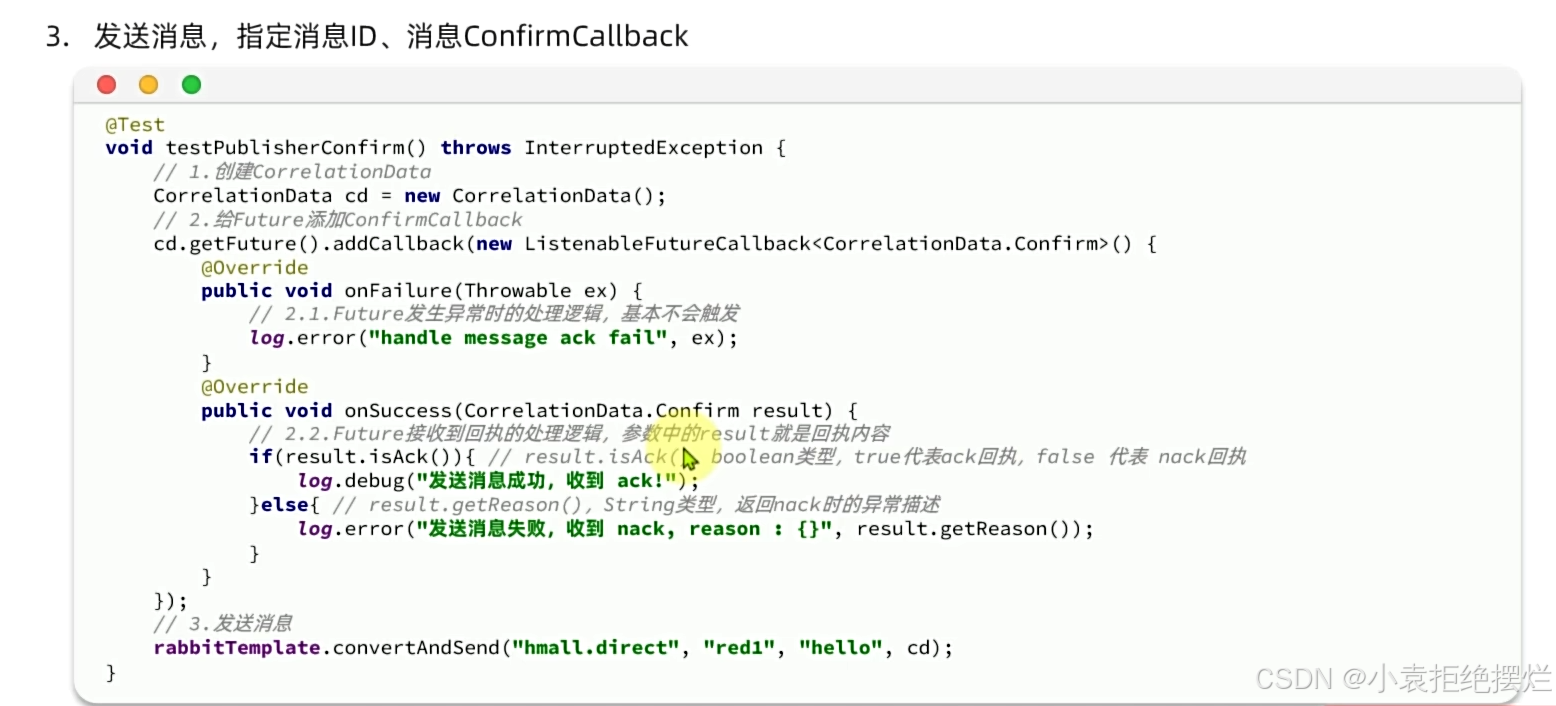
ConfrimCallBack
是在我们发送消息的时候去指定的,每一次发消息前都要指定
correlationData(ConfrimCallBack实体类)作为参数传入,有两个重要属性
1.id 不同confirm消息不同id
2.future 是再mq返回确认信息后会赋值到future内,而我们要做的是拿到future,添加一个回调函数(当future赋值完会自动调用)
addCallback传入一个ListenableFutureCallback对象
实现两个方法onFailure(没用)-代码处理future有异常执行的逻辑不是mq通知你失败了
onSuccess才是接收到mq返回消息执行的逻辑
这里mq返回信息可能为NACK也可能为ACK
tips
发送者·确认需要和mq通信会影响消息发送效率,一般不会开启这个机制,一般消息发送出现异常概率很低,你用发送者重连其实就差不多
MQ可靠性
问题
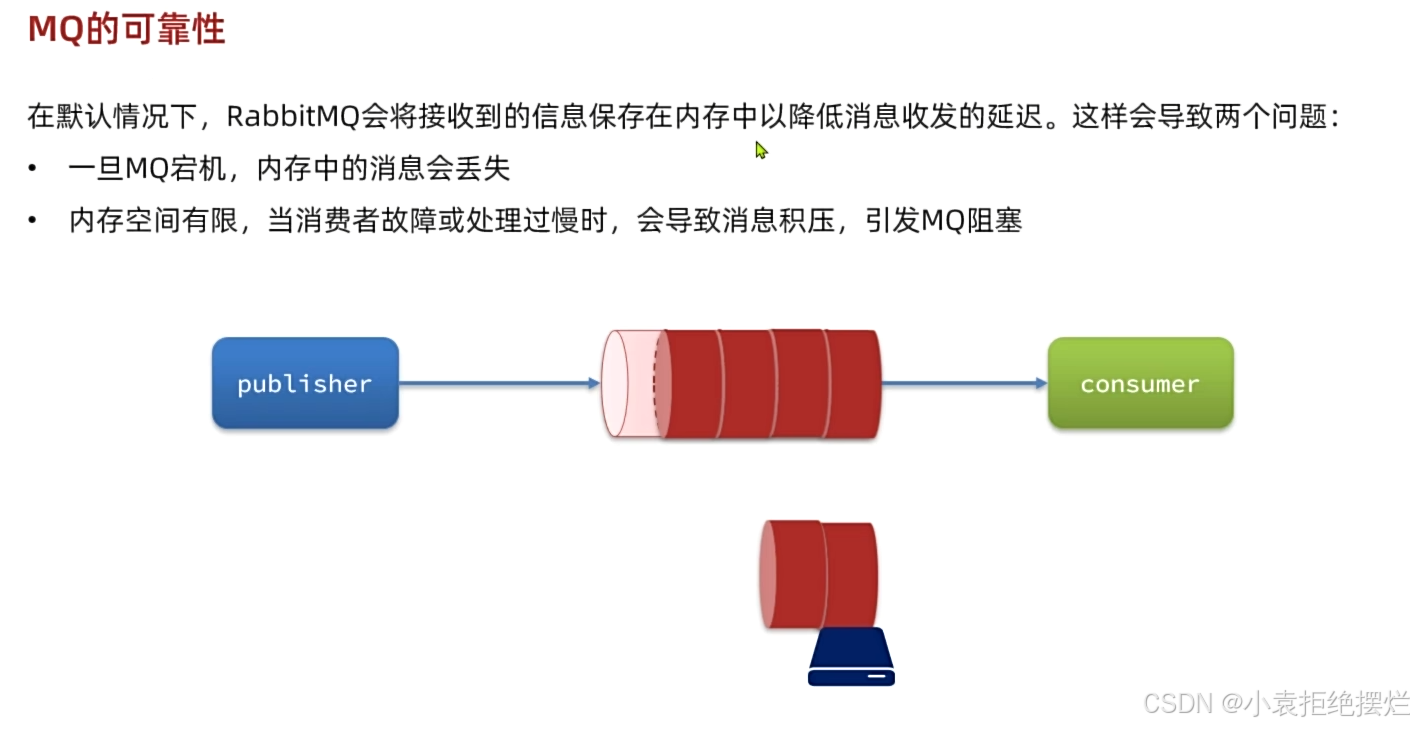
解决方案1.数据持久化2、Lazy Queue
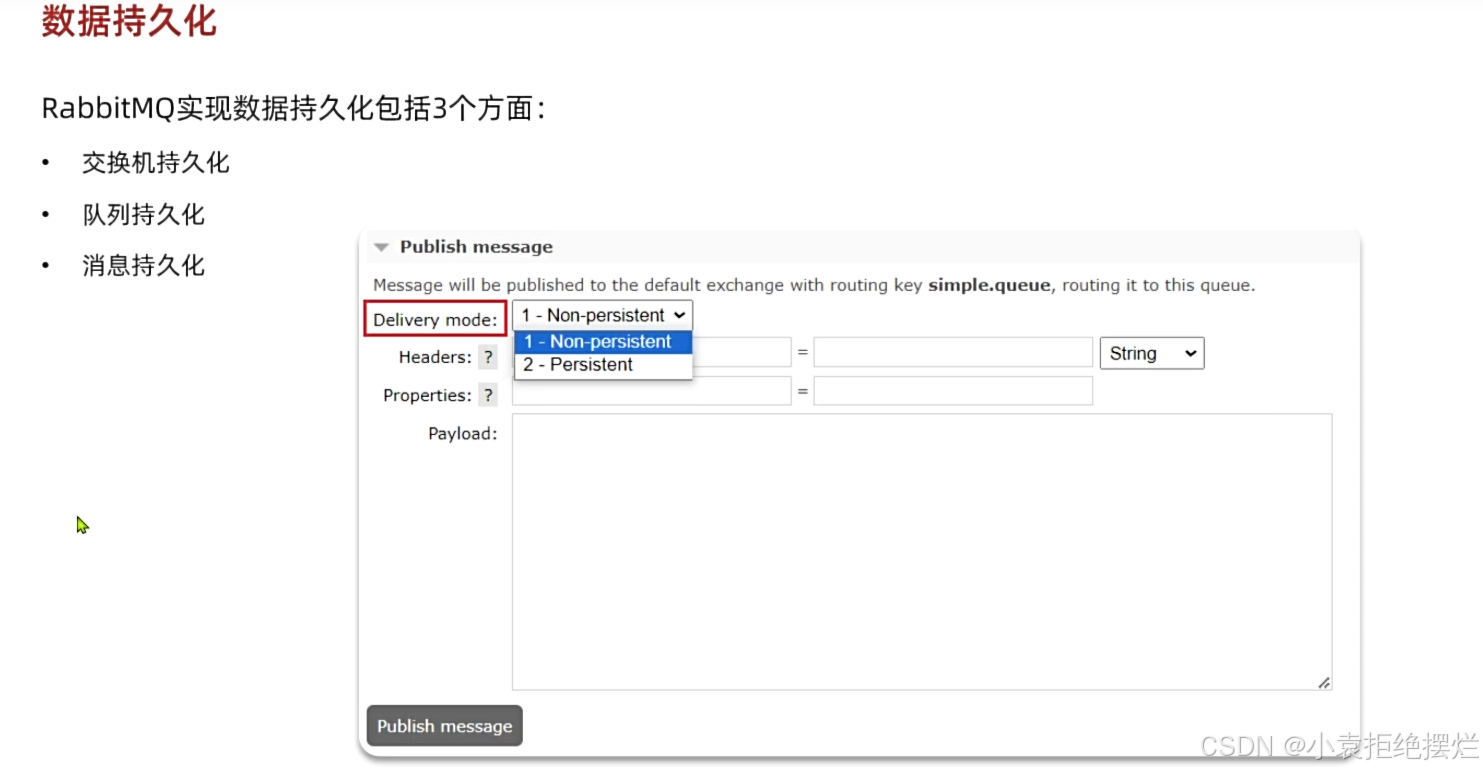
数据持久化
交换机和队列默认创建时候就是持久化的不用改
SpringAMQP默认发送的消息也都是持久化的(convertAndSend方法)
持久化就是你存入内存的同时也会存到磁盘中,重启mq后,会去磁盘中读出持久化数据达到持久化目的
其实你就算指定消息为非持久化,当你内存上限后也会去写入磁盘中,此时MQ会阻塞专门将我们的临时消息写入磁盘
非持久化消息是到达管道上限后才会写入磁盘,且会阻塞MQ读消息
持久化消息是一开始就写入磁盘,是双线程执行,不会阻塞MQ读消息
所以在数据量非常大的时候,持久化消息甚至比非持久化消息效率更高
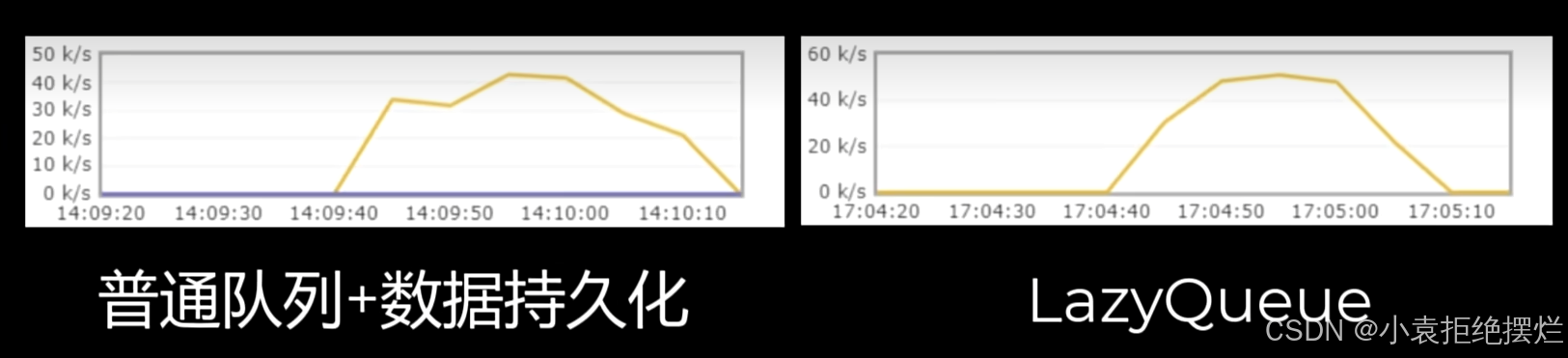
LazyQueue(默认模式且不可更改)
直接写入磁盘,消费者消费才弄到内存,防止IO过慢,会提前缓存一部分消息
注:3.12后所有队列但是Lazy Queue模式且无法更改
Lazy Queue正常情况下写的效率比普通数据持久化并发效率更高(只写磁盘了都)

消费者的可靠性
建议使用重试机制,会联合确认机制做到性能最高
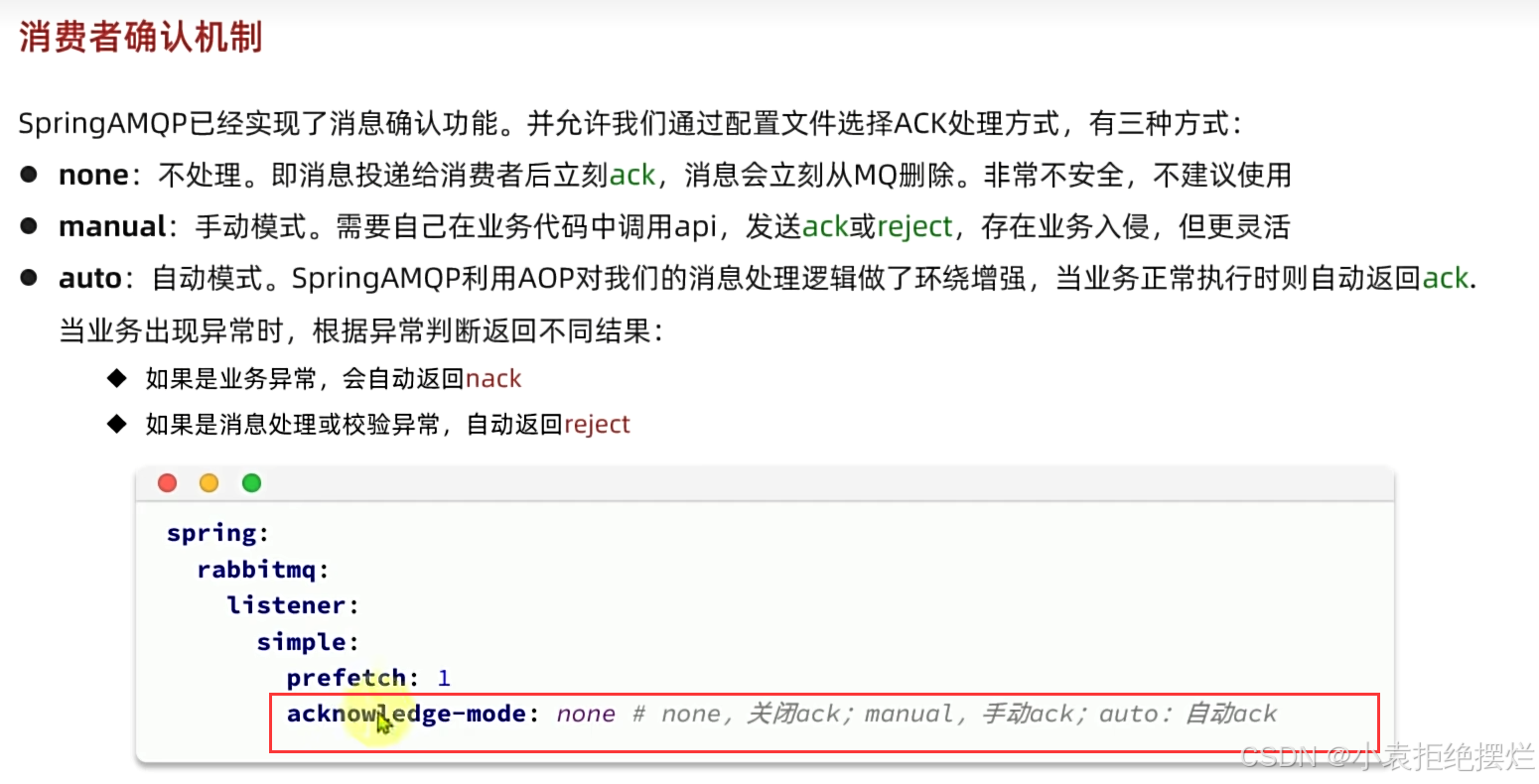
消费者确认机制
消费者和队列之间的沟通
消费者可能返回三种类型消息
1.ack:处理成功之后返回
2.nack:处理失败且想要Queue再次投递消息时候返回
3.reject:处理失败其不需要Queue再次投递消息(应用场景:比如处理过程中,消息内容本身有误的这种情况,json转换时候失败)

建议配置成AUTO
消息处理异常比如说MessageConversionException这种异常
就会返回reject给队列

消费者失败重试
上一种情况,可能消费者一直不能从故障中恢复,mq和我们程序之间会来回甩锅,浪费性能
而这个就是在消费者本地去重试,不去请求MQ了
类似于生产者充实,不过这个是配置在消费者端的
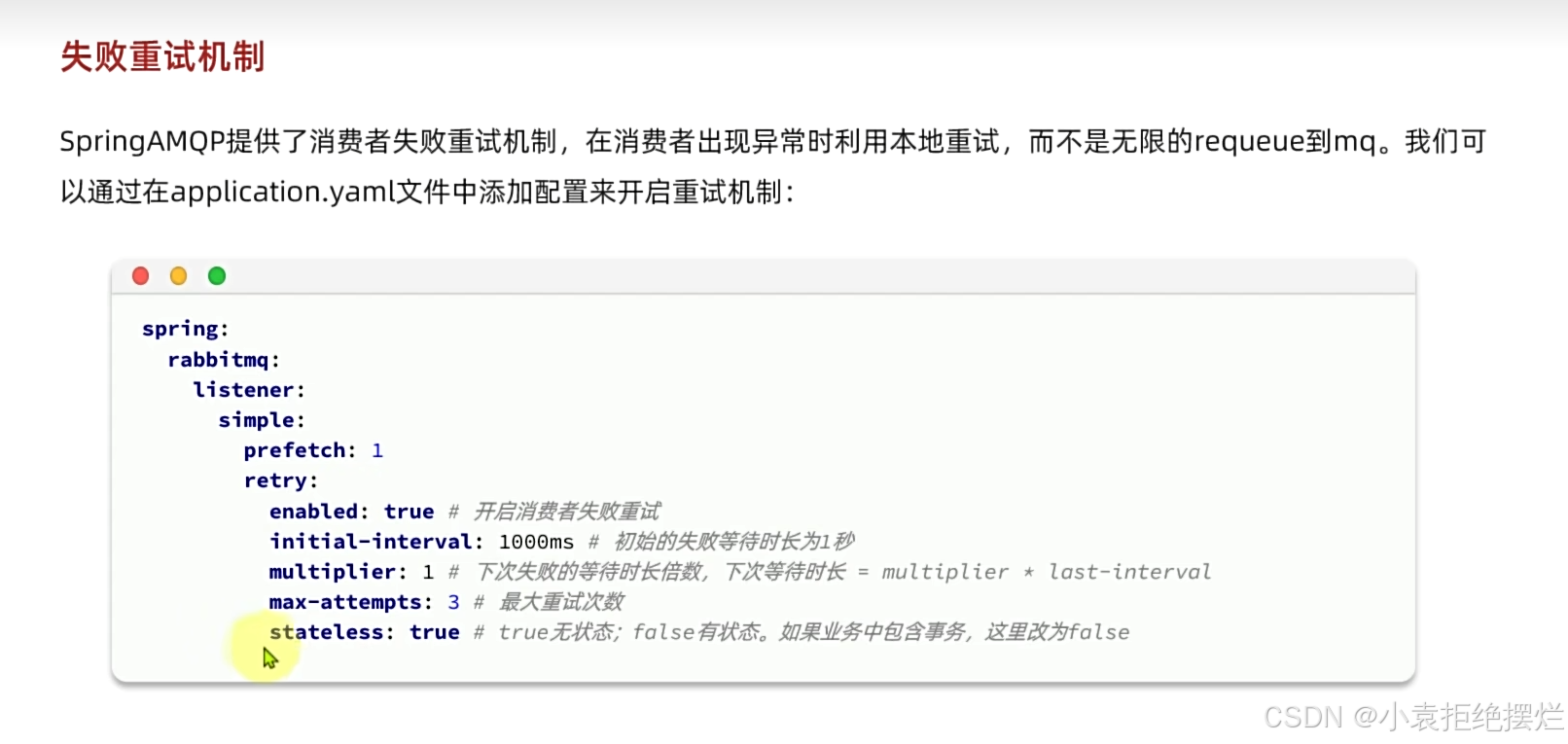
那到达最大重试次数之后会怎么样呢?
会有不同的处理策略
默认为第一种,三次后直接丢弃(不建议选择)
第二种的话相当于耗尽后返回nack,消息会重新入队
第三种相当于你定义了一个处理失败消息的路由和队列
第二种你搜一下怎么配置,下面展示第三种怎么配置

第三种配置方式
error为rountingkey

业务幂等性
业务幂等性就是保证一个消息一次处理和多次处理的结果一致
比如说你在消费者准备给MQ发送ack过程中发生了网络故障
这样的话,ack发送不成功,网络恢复后,MQ认为没有处理完,会再次发送该消息,造成多次消费的情况
如果这个消息处理的业务是要扣减库存,就会造成重复扣减,不符合正常业务逻辑

有些消息本来就是有幂等性的,做幂等性处理,而有些消息就需要做幂等性处理,防止业务逻辑的不正确处理
我们以消息多次投递导致业务被重复执行场景为例,思考解决方案
发送方需要配置好消息转换器,这样的话,相同消息会有相同的id
唯一消息id
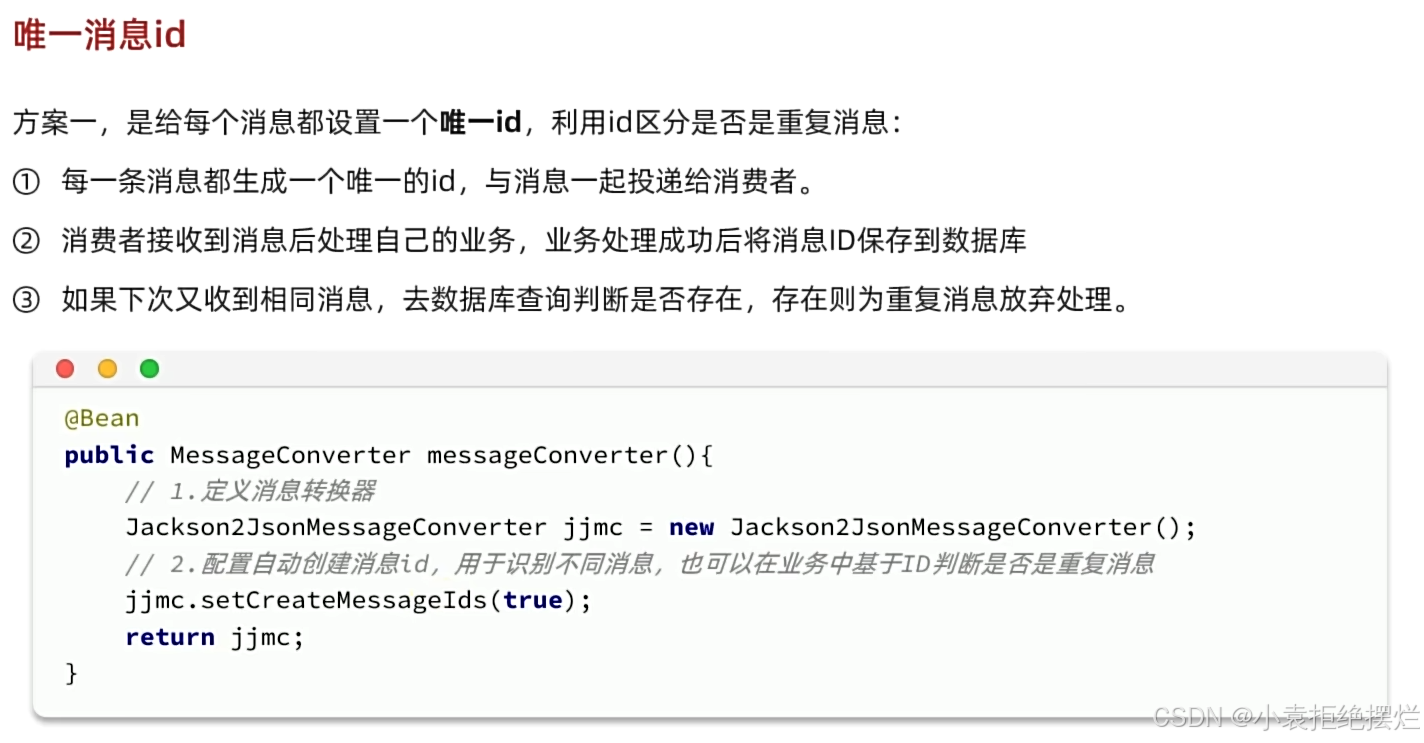
这个就是发送后生成的id

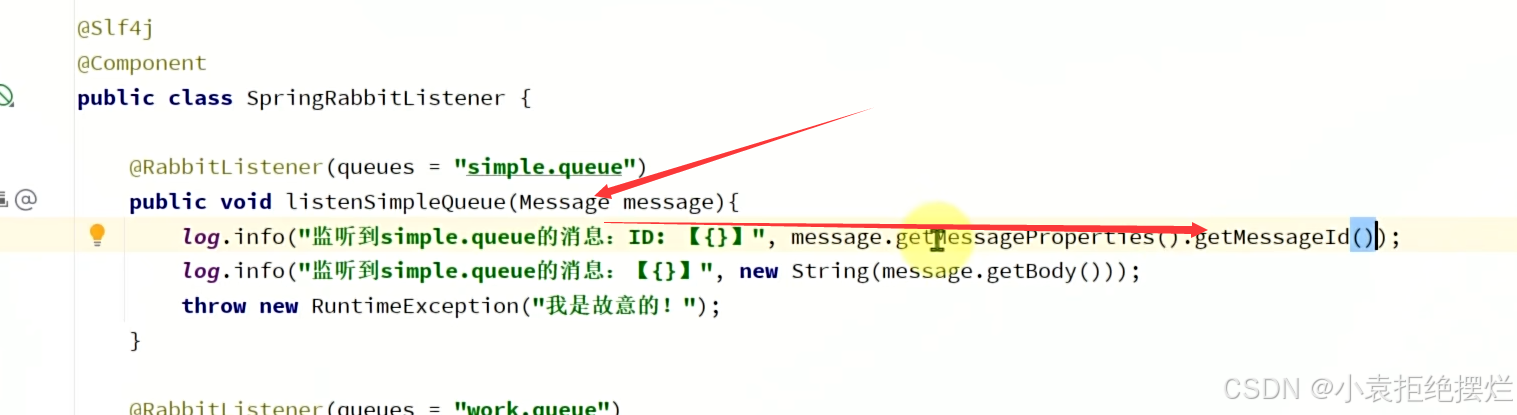
那么接收方怎么获取这个id呢?
之前是发什么,用什么类型接收
现在用Message接收,就可以获取对应的MessageId()
而Message的body就是我们的传送的信息
唯一消息id:性能较低,且有业务侵入,不太推荐,如果实在没办法可以去使用这种方式
业务判断
该方法,通过业务中本来存在的字段去判断,防止重复执行,有些业务适合,而有些不适合,如果不适合的话只能用第一种方式区处理
比如说该场景
如果说一个用户先支付,mq发消息,但是没接受到ack
然后用户退款不想买了,此时正好,mq要重发消息,又把我们的退款状态改为了支付完成状态
这样就不是幂等的了
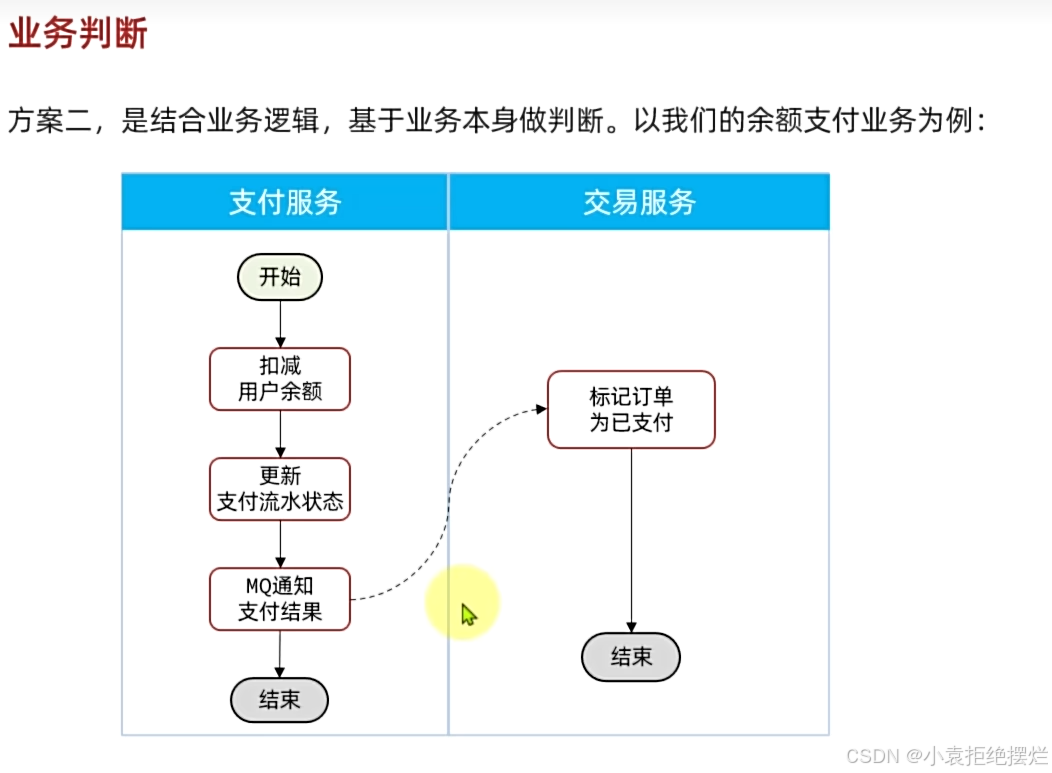
我们可以通过先查询订单状态,然后再进行更改实现业务逻辑的幂等性
只有订单为未支付的状态才看可以更改,其他状态都不行
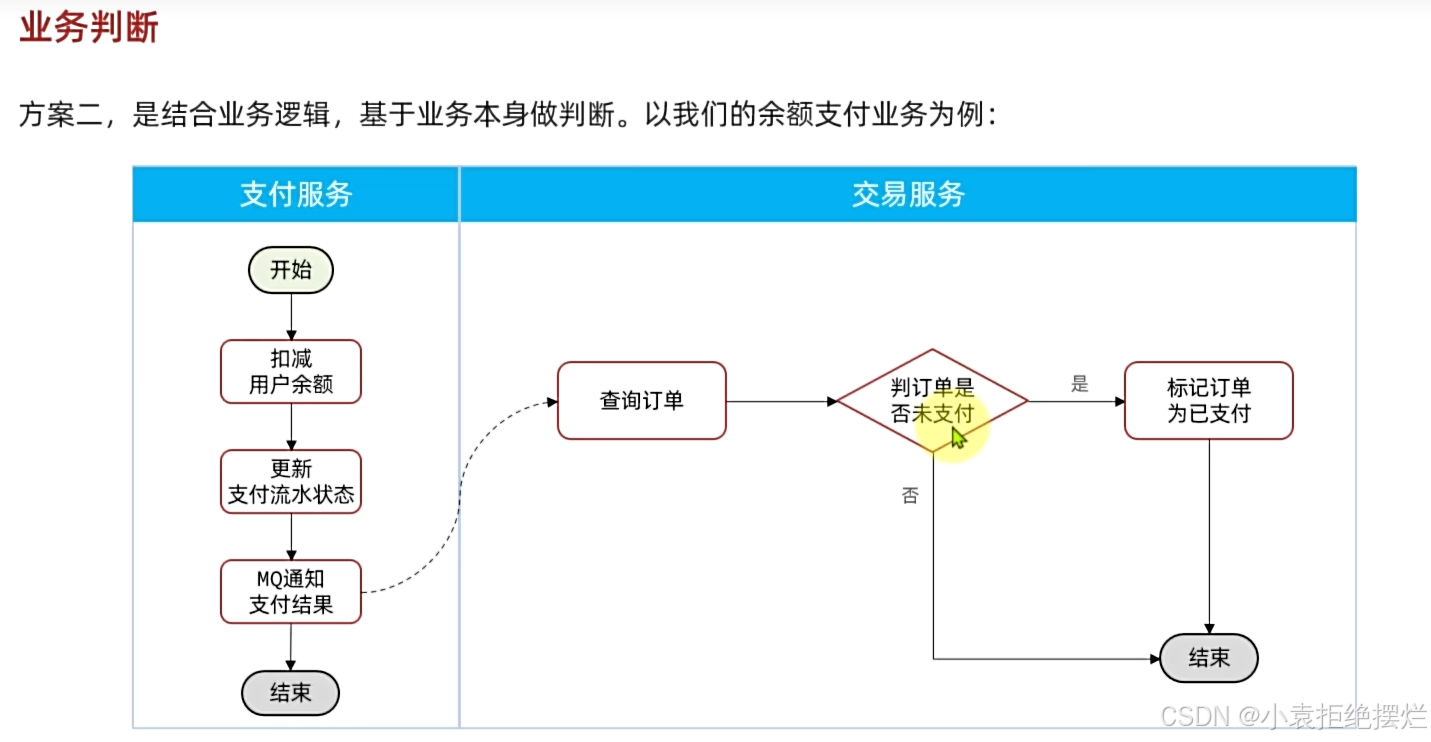
说实话这一小节需要结合具体业务来判断
视频
延迟消息
这个是上面方案之后的兜底的一个方案
正常情况下,我们的支付服务可以获得支付信息,然后将信息通过mq传给交易服务和商品服务
但是如果支付服务就是没办法将消息投递给交易服务,那样交易服务也获取不了支付状态,获取不了支付状态,会影响原本业务逻辑
假设支付了,但是交易服务状态还是未支付,不一致,假设没支付,但商品服务扣减了库存
我们需要设置一个超时取消的效果恢复我们的商品服务和交易服务,以防止MQ的消息没法正常到达交易服务
交易服务等待一段时间,过了这个时间后还没有收到mq消息,我们主动去查询支付服务状态(远程调用)
如果查询到没支付,就执行没支付的逻辑,已支付就执行已支付的状态
这种就需要使用延迟消息达到一个延迟任务的效果
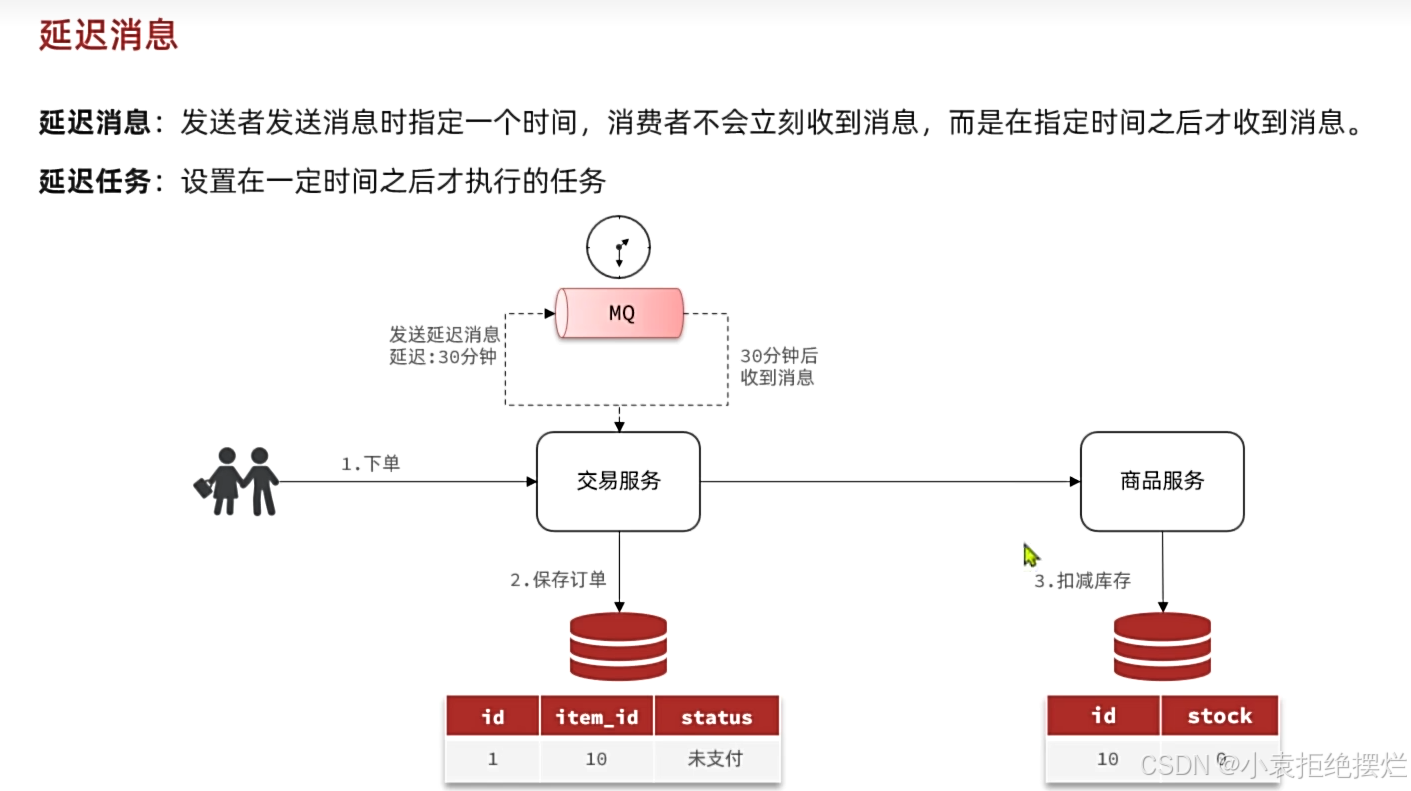
下面有两种实现方案
死信交换机
不写了,自己了解一下,属于上一代的视线延时消息的方式
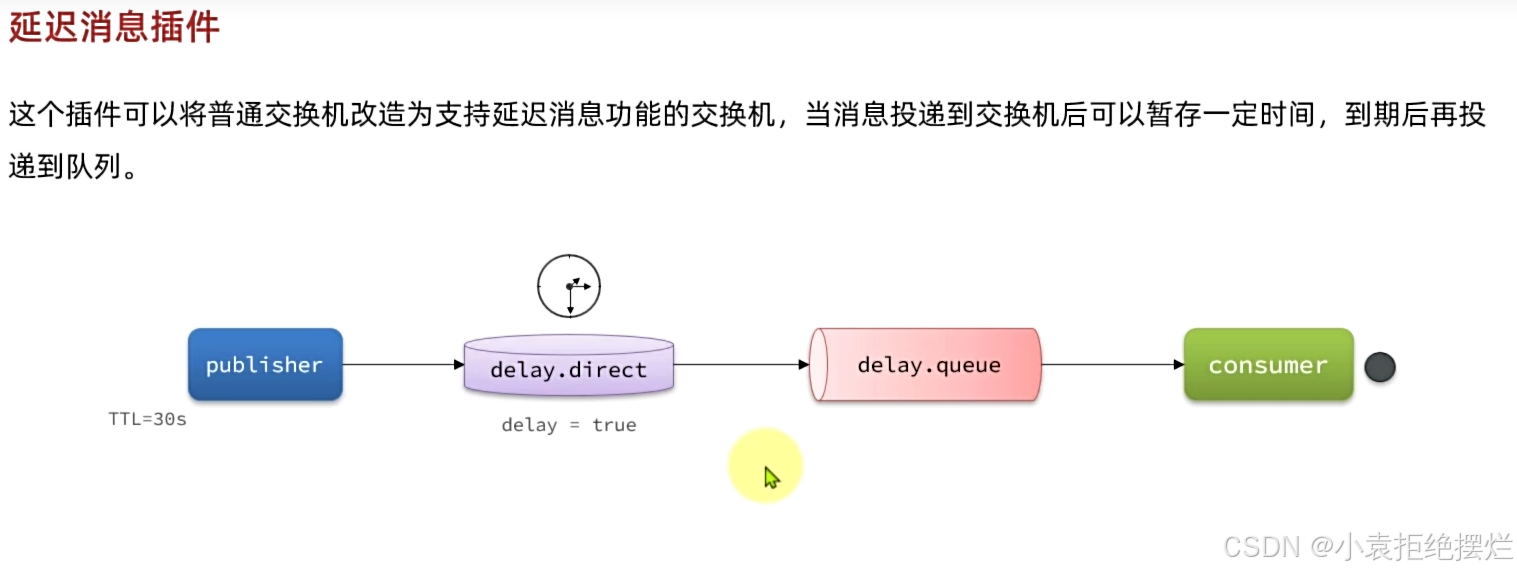
延迟消息插件
下载插件
原理就是就是生产者设置时间,将交换机的delay属性设置为true,交换机接收到消息后会在指定时间后转发给队列实现延迟消息的效果
插件名称
Dealayed Messaging for RabbitMQ
下载插件和对应MQ版本要一致
建议搜一下windows启动该插件的命令,也有linux用docker部署启动命令,这里我只演示怎么使用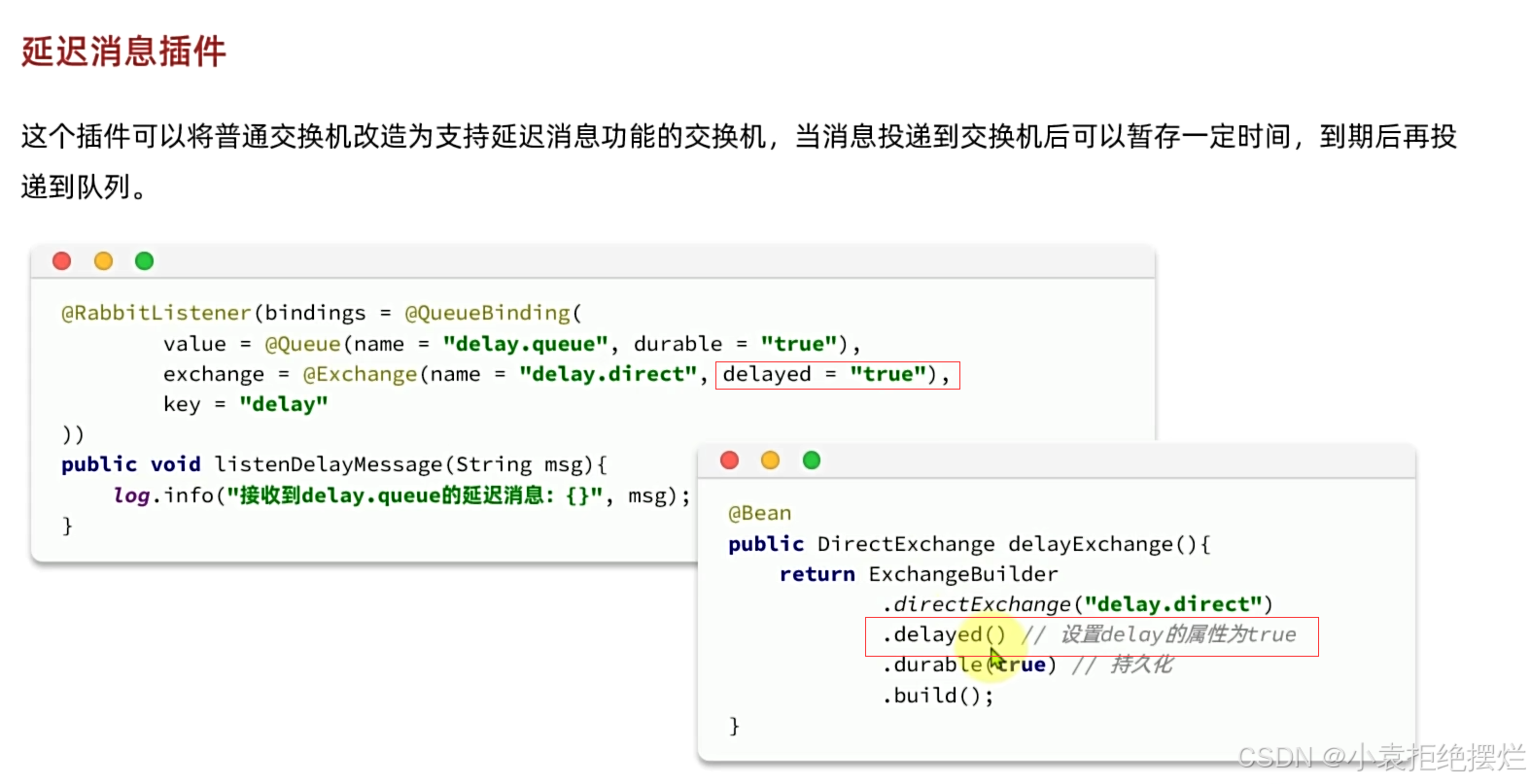
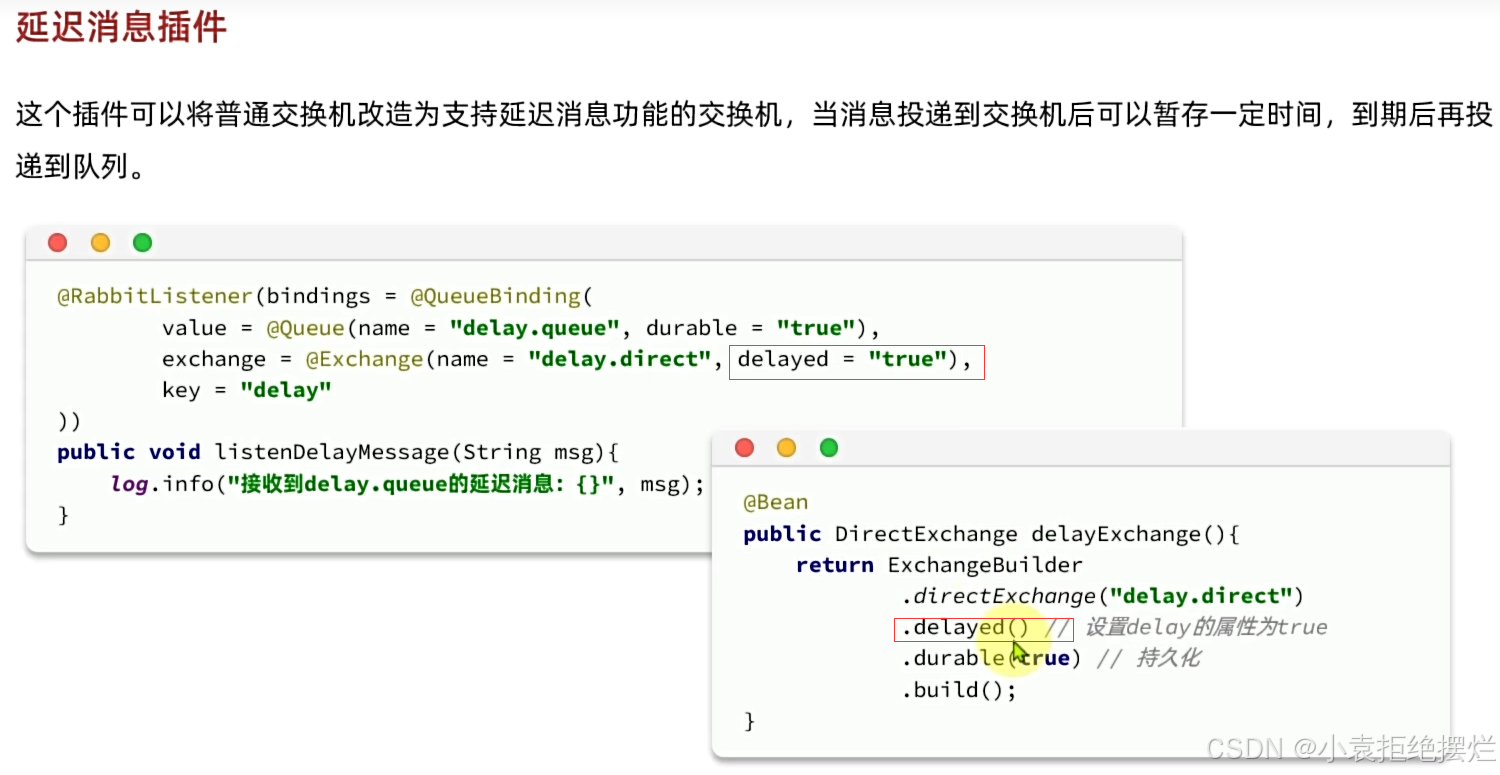
首先设置一个支持delayed延迟消息的交换机
两种方式bean或者注解都可以
在发送消息的时候多指定一个参数MessagePostProcessor
拿到消息本体去设置Delay对应过期时间,单位是毫秒
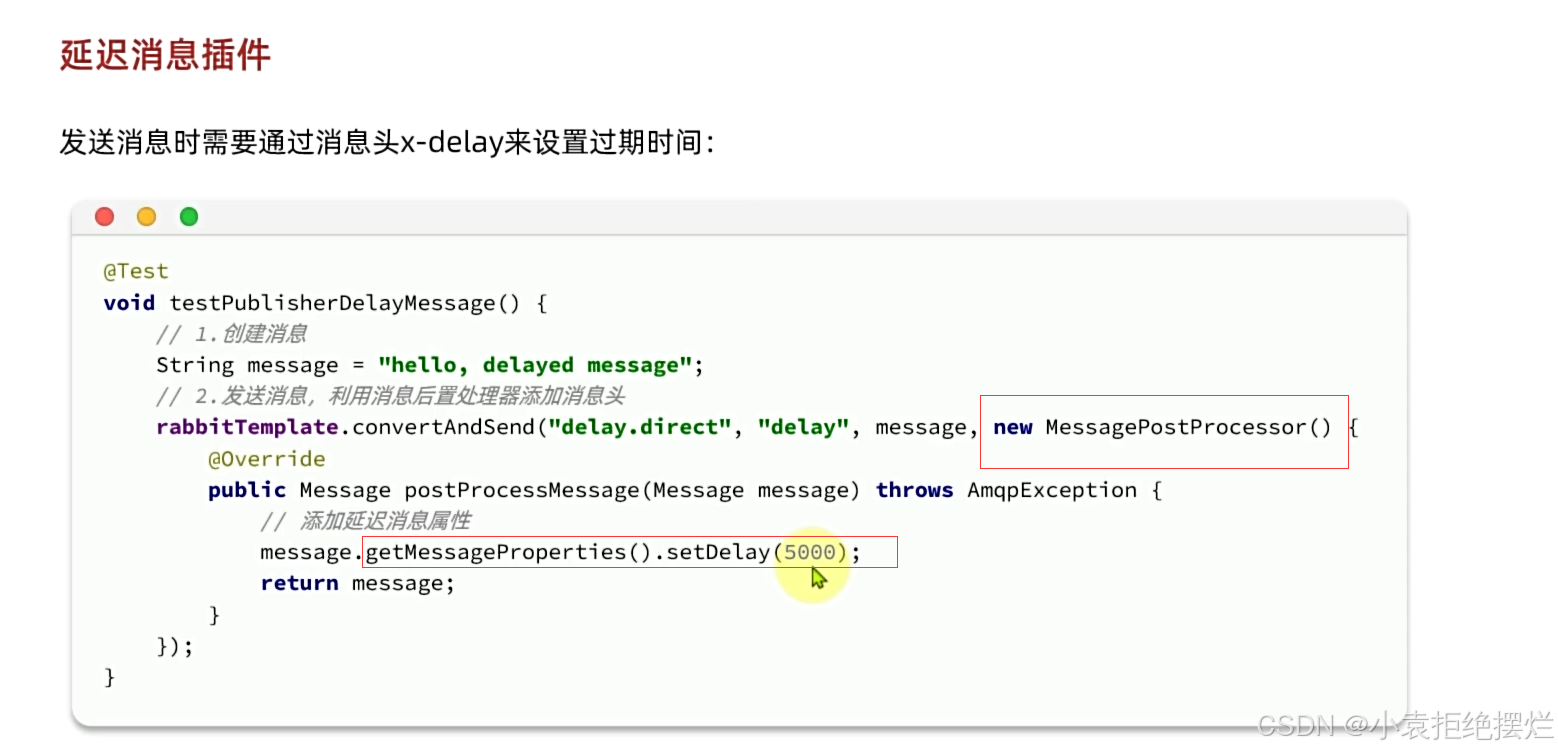
然后启动项目运行测试案例就可以看到效果了
视频的后半段演示延迟效果