Value类型:
1)map
➢ 函数签名
def mapU: ClassTag(f: T => U): RDDU
➢ 函数说明
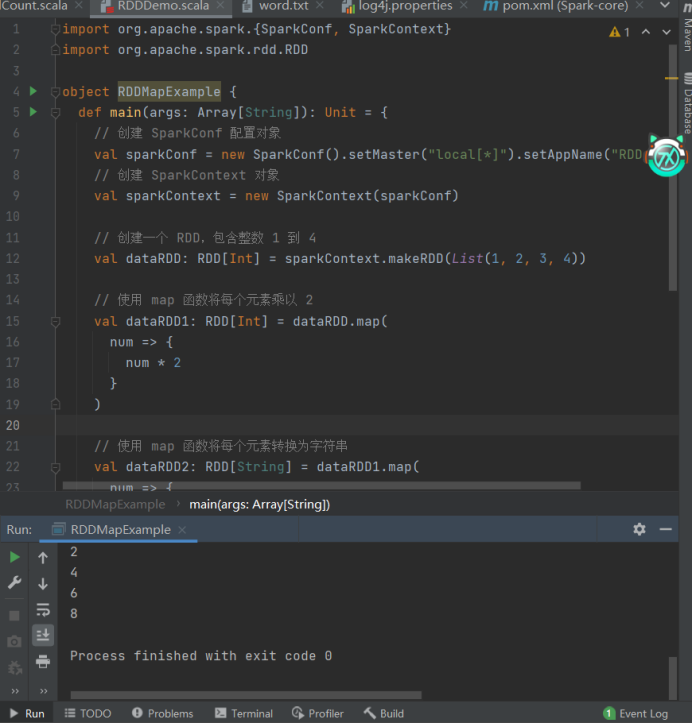
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object RDDMapExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 配置对象
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个 RDD,包含整数 1 到 4
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4))
// 使用 map 函数将每个元素乘以 2
val dataRDD1: RDDInt = dataRDD.map(
num => {
num * 2
}
)
// 使用 map 函数将每个元素转换为字符串
val dataRDD2: RDDString = dataRDD1.map(
num => {
"" + num
}
)
// 收集 RDD2 的元素并打印
val result = dataRDD2.collect()
result.foreach(println)
// 停止 SparkContext
sparkContext.stop()
}
}
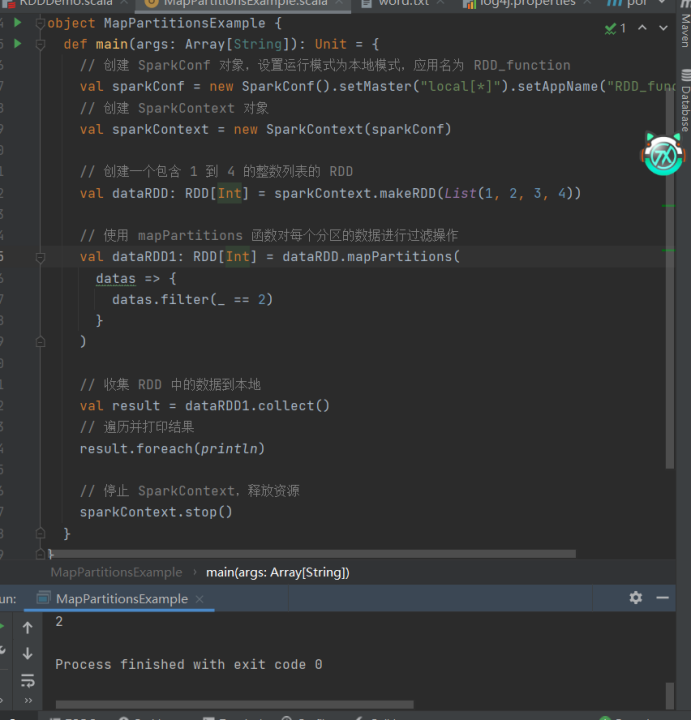
2)mapPartitions
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object MapPartitionsExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含 1 到 4 的整数列表的 RDD
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4))
// 使用 mapPartitions 函数对每个分区的数据进行过滤操作
val dataRDD1: RDDInt = dataRDD.mapPartitions(
datas => {
datas.filter(_ == 2)
}
)
// 收集 RDD 中的数据到本地
val result = dataRDD1.collect()
// 遍历并打印结果
result.foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
)
3)mapPartitionsWithIndex
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object RDDGlomExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象
val conf = new SparkConf().setAppName("RDDGlomExample").setMaster("local\*")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(conf)
// 创建一个初始的 RDD
val dataRDD = sparkContext.makeRDD(List(
1, 2, 3, 4
), 1)
// 使用 glom 操作将每个分区中的元素转换为一个数组
val dataRDD1: RDDArray\[Int] = dataRDD.glom()
// 收集结果并打印
val result = dataRDD1.collect()
result.foreach(arr => println(arr.mkString(", ")))
// 停止 SparkContext
sparkContext.stop()
}
}
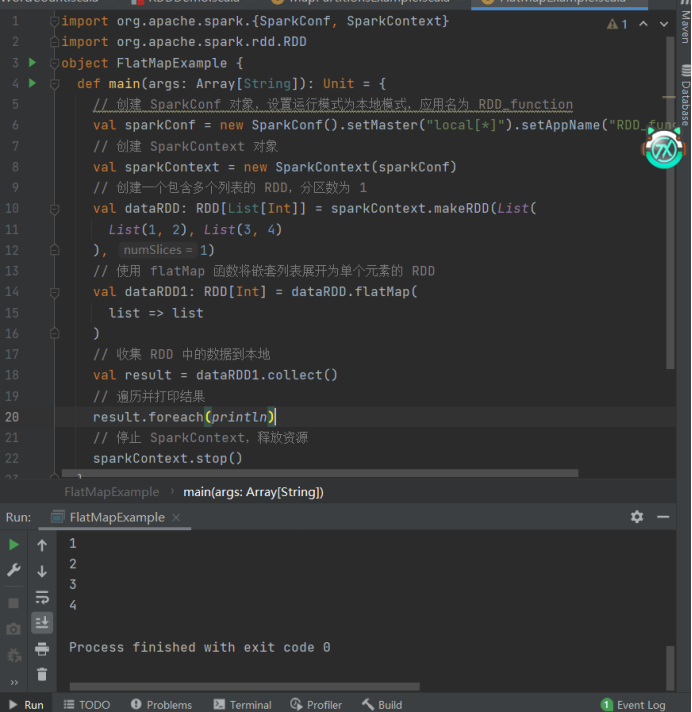
4)flatMap
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object FlatMapExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含多个列表的 RDD,分区数为 1
val dataRDD: RDDList\[Int] = sparkContext.makeRDD(List(
List(1, 2), List(3, 4)
), 1)
// 使用 flatMap 函数将嵌套列表展开为单个元素的 RDD
val dataRDD1: RDDInt = dataRDD.flatMap(
list => list
)
// 收集 RDD 中的数据到本地
val result = dataRDD1.collect()
// 遍历并打印结果
result.foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
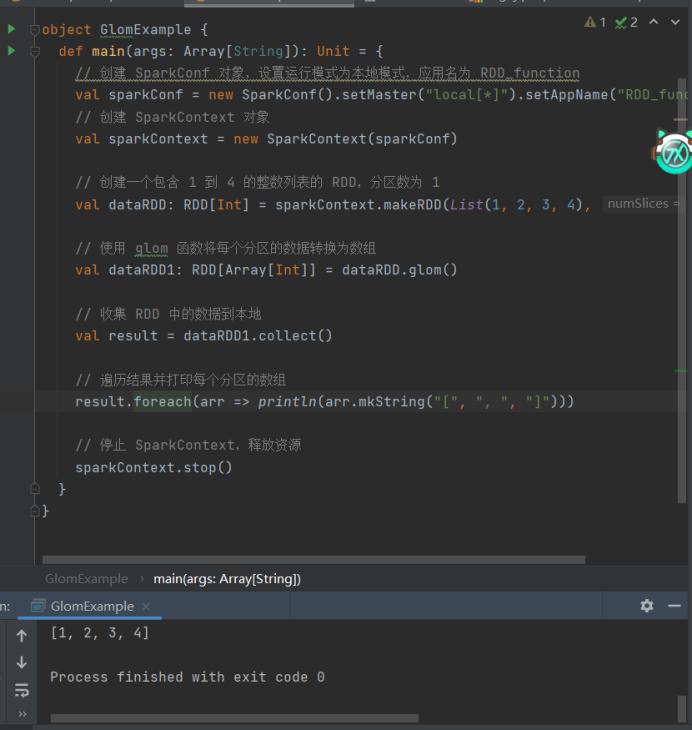
5)Glom
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object GlomExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含 1 到 4 的整数列表的 RDD,分区数为 1
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4), 1)
// 使用 glom 函数将每个分区的数据转换为数组
val dataRDD1: RDDArray\[Int] = dataRDD.glom()
// 收集 RDD 中的数据到本地
val result = dataRDD1.collect()
// 遍历结果并打印每个分区的数组
result.foreach(arr => println(arr.mkString("", ", ", "")))
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
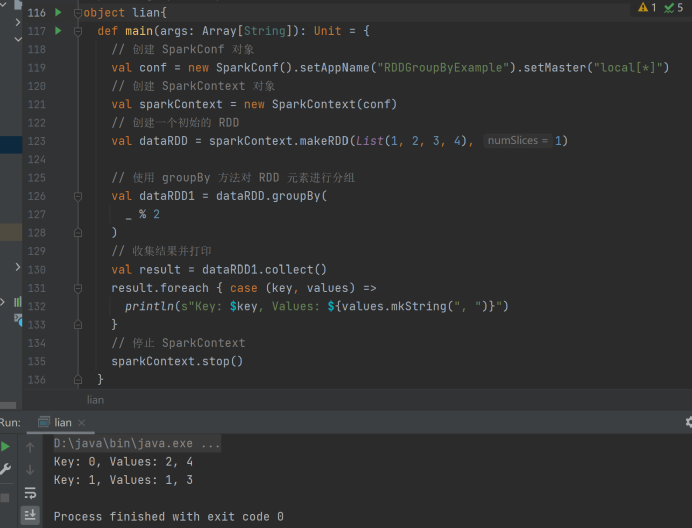
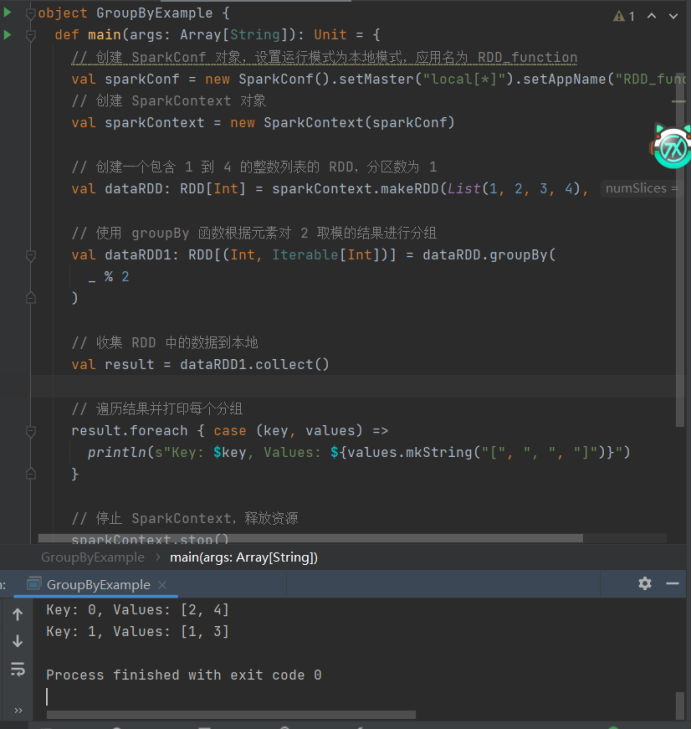
6)groupBy
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object GroupByExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含 1 到 4 的整数列表的 RDD,分区数为 1
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4), 1)
// 使用 groupBy 函数根据元素对 2 取模的结果进行分组
val dataRDD1: RDD(Int, Iterable\[Int)] = dataRDD.groupBy(
_ % 2
)
// 收集 RDD 中的数据到本地
val result = dataRDD1.collect()
// 遍历结果并打印每个分组
result.foreach { case (key, values) =>
println(s"Key: key, Values: {values.mkString("", ", ", "")}")
}
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
)
7)Filter
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object FilterExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含 1 到 4 的整数列表的 RDD,分区数为 1
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4), 1)
// 使用 filter 函数筛选出偶数
val dataRDD1: RDDInt = dataRDD.filter(_ % 2 == 0)
// 使用 filter 函数筛选出奇数
val dataRDD2: RDDInt = dataRDD.filter(_ % 2 == 1)
// 收集偶数筛选结果到本地
val result1 = dataRDD1.collect()
// 收集奇数筛选结果到本地
val result2 = dataRDD2.collect()
// 打印偶数筛选结果
println("偶数结果:")
result1.foreach(println)
// 打印奇数筛选结果
println("奇数结果:")
result2.foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}

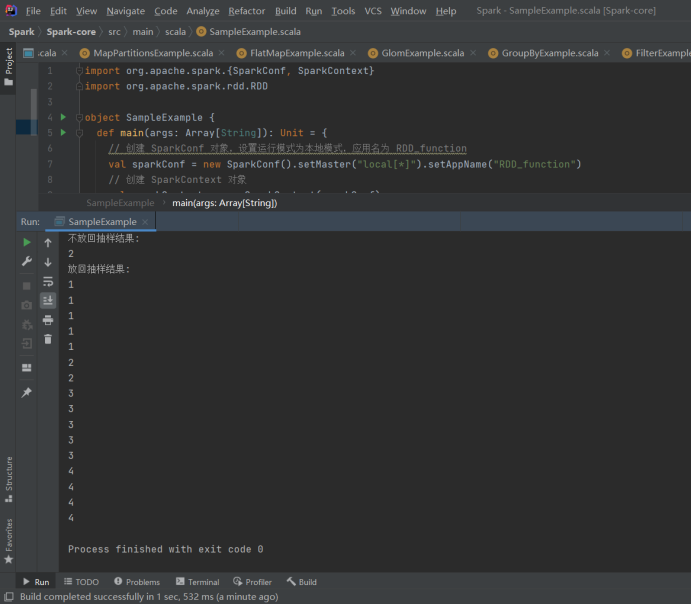
8)sample
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object SampleExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含 1 到 4 的整数列表的 RDD,分区数为 1
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4), 1)
// 抽取数据不放回(伯努利算法)
// 第一个参数:抽取的数据是否放回,false:不放回
// 第二个参数:抽取的几率,范围在0,1之间,0:全不取;1:全取;
// 第三个参数:随机数种子,这里使用默认值
val dataRDD1: RDDInt = dataRDD.sample(false, 0.5)
// 抽取数据放回(泊松算法)
// 第一个参数:抽取的数据是否放回,true:放回;false:不放回
// 第二个参数:重复数据的几率,范围大于等于 0,表示每一个元素被期望抽取到的次数
// 第三个参数:随机数种子,这里使用默认值
val dataRDD2: RDDInt = dataRDD.sample(true, 2)
// 收集不放回抽样的结果
val result1 = dataRDD1.collect()
// 收集放回抽样的结果
val result2 = dataRDD2.collect()
// 打印不放回抽样的结果
println("不放回抽样结果:")
result1.foreach(println)
// 打印放回抽样的结果
println("放回抽样结果:")
result2.foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
Value类型:
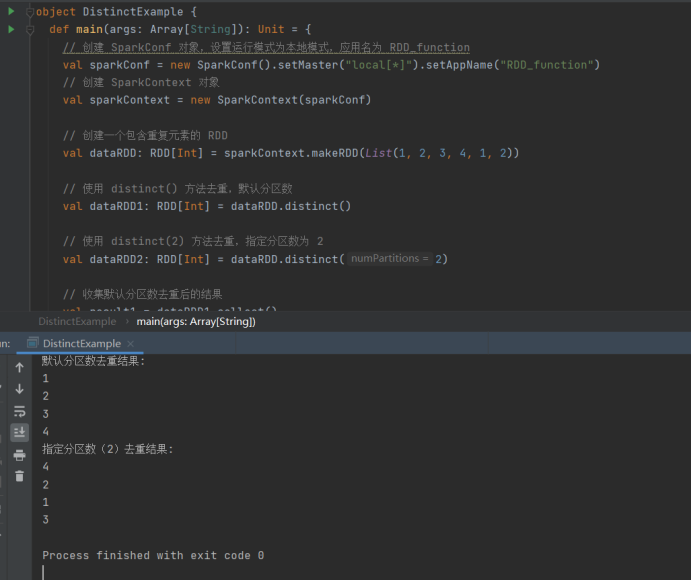
9)Distinct
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object DistinctExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含重复元素的 RDD
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4, 1, 2))
// 使用 distinct() 方法去重,默认分区数
val dataRDD1: RDDInt = dataRDD.distinct()
// 使用 distinct(2) 方法去重,指定分区数为 2
val dataRDD2: RDDInt = dataRDD.distinct(2)
// 收集默认分区数去重后的结果
val result1 = dataRDD1.collect()
// 收集指定分区数去重后的结果
val result2 = dataRDD2.collect()
// 打印默认分区数去重后的结果
println("默认分区数去重结果:")
result1.foreach(println)
// 打印指定分区数去重后的结果
println("指定分区数(2)去重结果:")
result2.foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
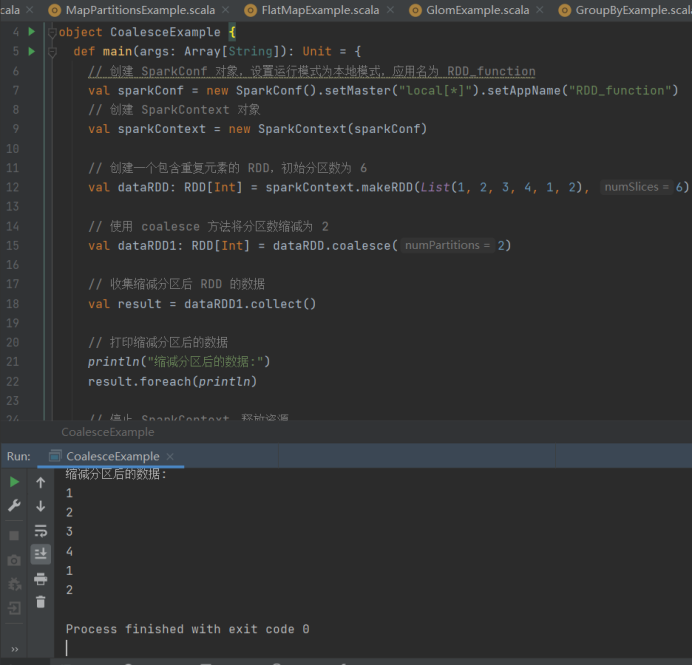
10、Coalesce
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object CoalesceExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含重复元素的 RDD,初始分区数为 6
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4, 1, 2), 6)
// 使用 coalesce 方法将分区数缩减为 2
val dataRDD1: RDDInt = dataRDD.coalesce(2)
// 收集缩减分区后 RDD 的数据
val result = dataRDD1.collect()
// 打印缩减分区后的数据
println("缩减分区后的数据:")
result.foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
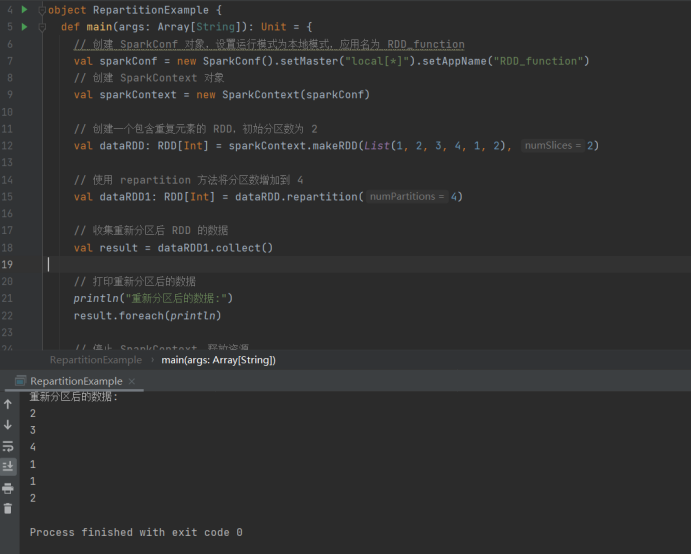
11、Repartition
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object RepartitionExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式为本地模式,应用名为 RDD_function
val sparkConf = new SparkConf().setMaster("local\*").setAppName("RDD_function")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(sparkConf)
// 创建一个包含重复元素的 RDD,初始分区数为 2
val dataRDD: RDDInt = sparkContext.makeRDD(List(1, 2, 3, 4, 1, 2), 2)
// 使用 repartition 方法将分区数增加到 4
val dataRDD1: RDDInt = dataRDD.repartition(4)
// 收集重新分区后 RDD 的数据
val result = dataRDD1.collect()
// 打印重新分区后的数据
println("重新分区后的数据:")
result.foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
12)sortBy
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object SortByExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("SortByExample").setMaster("local\*")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(conf)
// 创建一个包含数据的 RDD,并指定分区数为 2
val dataRDD = sparkContext.makeRDD(List(1, 2, 3, 4, 1, 2), 2)
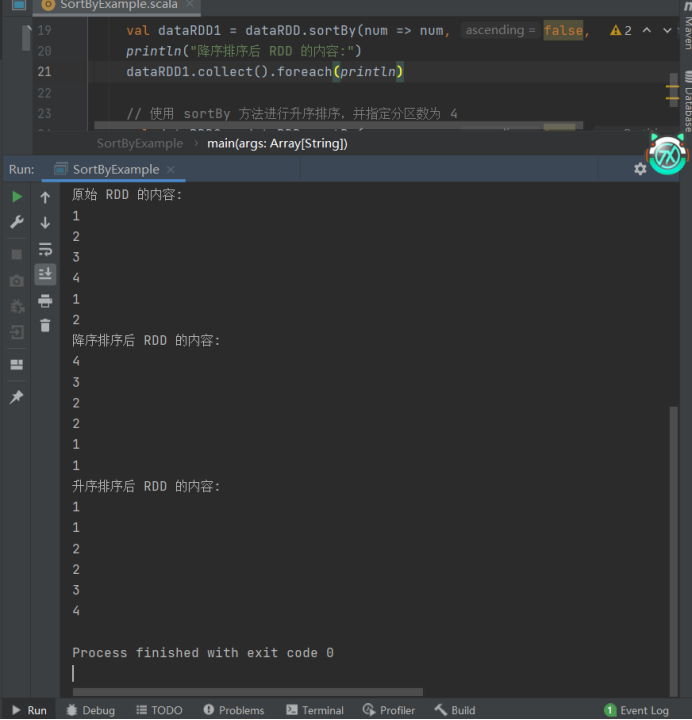
// 打印原始 RDD 的内容
println("原始 RDD 的内容:")
dataRDD.collect().foreach(println)
// 使用 sortBy 方法进行降序排序,并指定分区数为 4
val dataRDD1 = dataRDD.sortBy(num => num, false, 4)
println("降序排序后 RDD 的内容:")
dataRDD1.collect().foreach(println)
// 使用 sortBy 方法进行升序排序,并指定分区数为 4
val dataRDD2 = dataRDD.sortBy(num => num, true, 4)
println("升序排序后 RDD 的内容:")
dataRDD2.collect().foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
双Value类型:
- intersection
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object IntersectionExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("IntersectionExample").setMaster("local\*")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(conf)
// 创建第一个 RDD
val dataRDD1 = sparkContext.makeRDD(List(1, 2, 3, 4))
// 创建第二个 RDD
val dataRDD2 = sparkContext.makeRDD(List(3, 4, 5, 6))
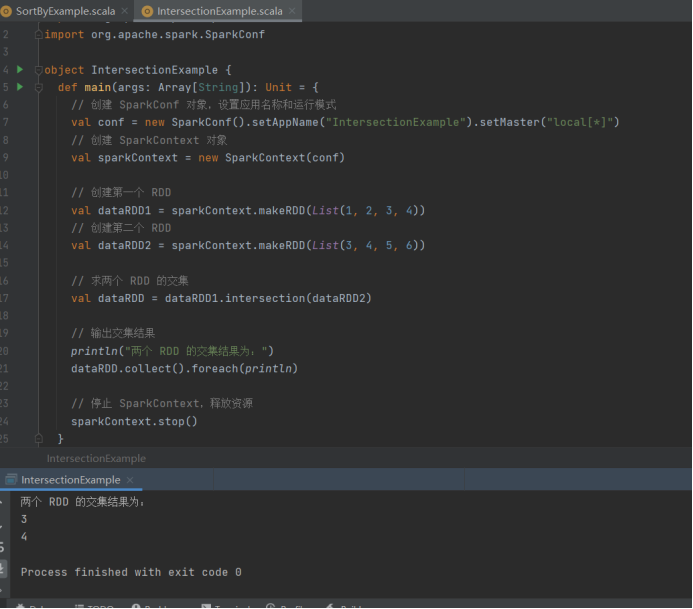
// 求两个 RDD 的交集
val dataRDD = dataRDD1.intersection(dataRDD2)
// 输出交集结果
println("两个 RDD 的交集结果为:")
dataRDD.collect().foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
- union
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object UnionExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("UnionExample").setMaster("local\*")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(conf)
// 创建第一个 RDD
val dataRDD1 = sparkContext.makeRDD(List(1, 2, 3, 4))
// 创建第二个 RDD
val dataRDD2 = sparkContext.makeRDD(List(3, 4, 5, 6))
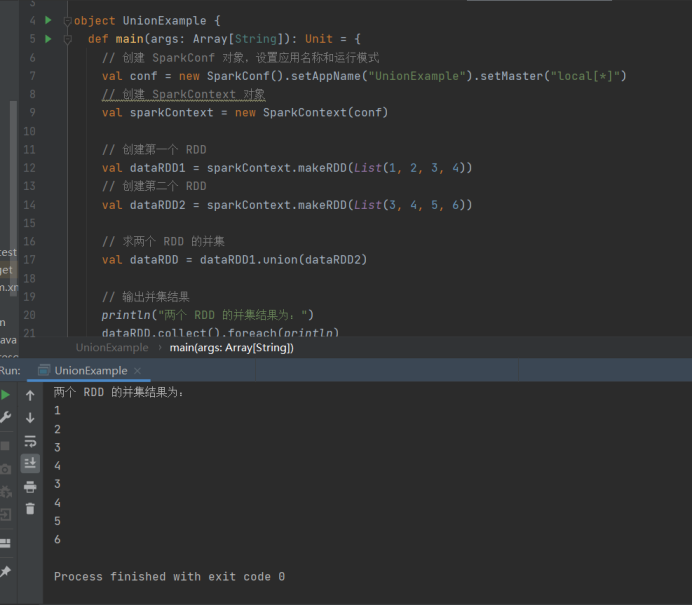
// 求两个 RDD 的并集
val dataRDD = dataRDD1.union(dataRDD2)
// 输出并集结果
println("两个 RDD 的并集结果为:")
dataRDD.collect().foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
15)Subtract
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object SubtractExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("SubtractExample").setMaster("local\*")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(conf)
// 创建第一个 RDD
val dataRDD1 = sparkContext.makeRDD(List(1, 2, 3, 4))
// 创建第二个 RDD
val dataRDD2 = sparkContext.makeRDD(List(3, 4, 5, 6))
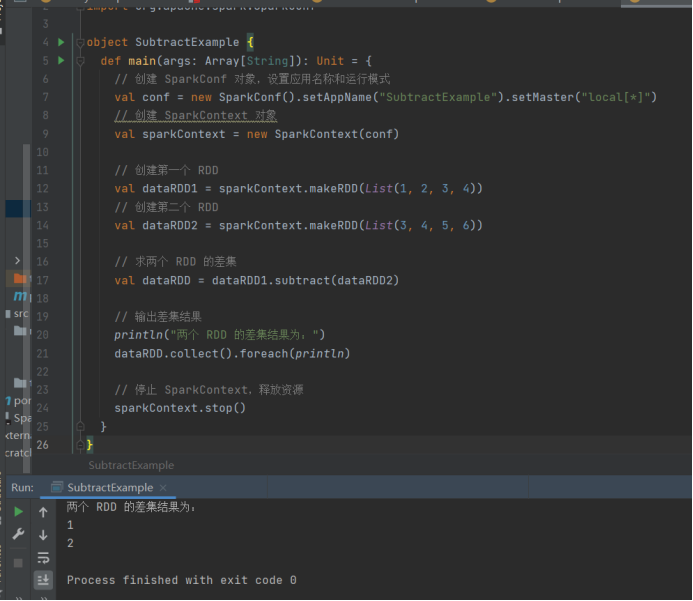
// 求两个 RDD 的差集
val dataRDD = dataRDD1.subtract(dataRDD2)
// 输出差集结果
println("两个 RDD 的差集结果为:")
dataRDD.collect().foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
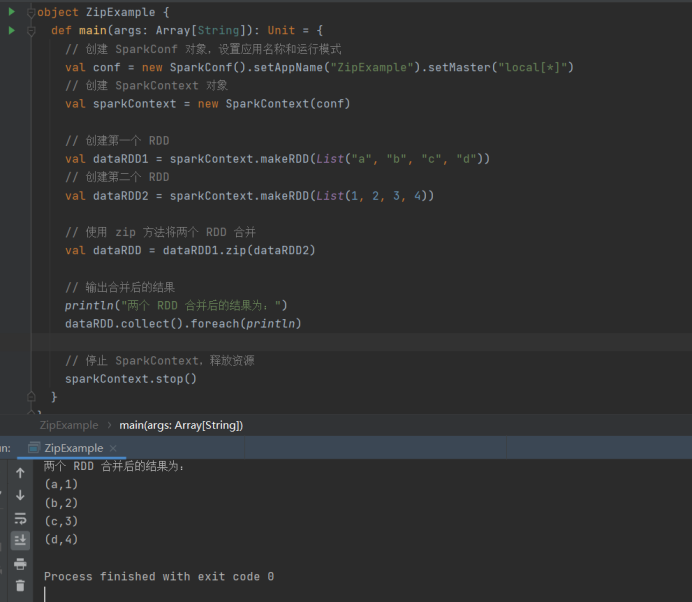
- zip
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object ZipExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("ZipExample").setMaster("local\*")
// 创建 SparkContext 对象
val sparkContext = new SparkContext(conf)
// 创建第一个 RDD
val dataRDD1 = sparkContext.makeRDD(List("a", "b", "c", "d"))
// 创建第二个 RDD
val dataRDD2 = sparkContext.makeRDD(List(1, 2, 3, 4))
// 使用 zip 方法将两个 RDD 合并
val dataRDD = dataRDD1.zip(dataRDD2)
// 输出合并后的结果
println("两个 RDD 合并后的结果为:")
dataRDD.collect().foreach(println)
// 停止 SparkContext,释放资源
sparkContext.stop()
}
}
Key-Value类型:
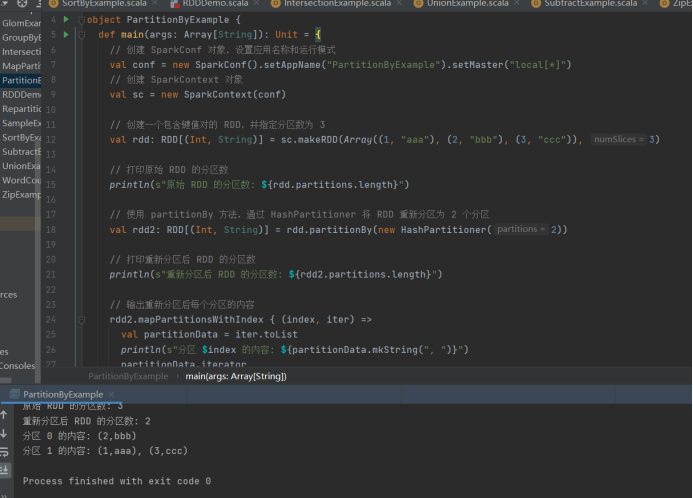
- partitionBy
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object PartitionByExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("PartitionByExample").setMaster("local\*")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 创建一个包含键值对的 RDD,并指定分区数为 3
val rdd: RDD(Int, String) = sc.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)
// 打印原始 RDD 的分区数
println(s"原始 RDD 的分区数: ${rdd.partitions.length}")
// 使用 partitionBy 方法,通过 HashPartitioner 将 RDD 重新分区为 2 个分区
val rdd2: RDD(Int, String) = rdd.partitionBy(new HashPartitioner(2))
// 打印重新分区后 RDD 的分区数
println(s"重新分区后 RDD 的分区数: ${rdd2.partitions.length}")
// 输出重新分区后每个分区的内容
rdd2.mapPartitionsWithIndex { (index, iter) =>
val partitionData = iter.toList
println(s"分区 index 的内容: {partitionData.mkString(", ")}")
partitionData.iterator
}.collect()
// 停止 SparkContext,释放资源
sc.stop()
}
}
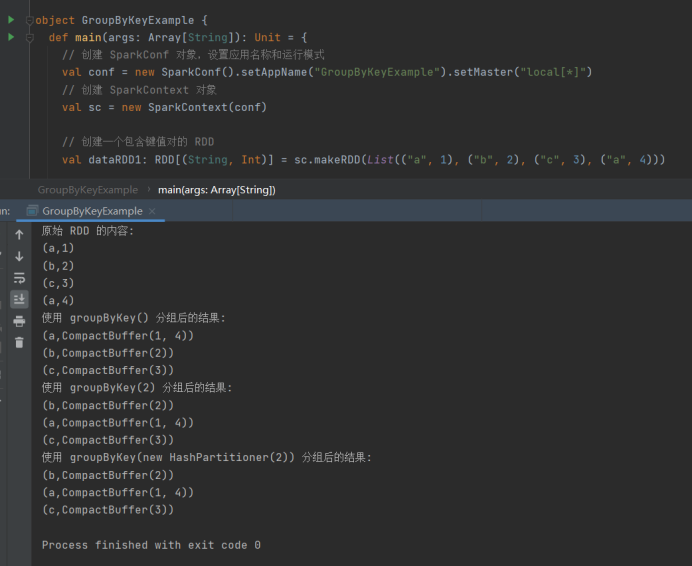
- groupByKey
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object GroupByKeyExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("GroupByKeyExample").setMaster("local\*")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 创建一个包含键值对的 RDD
val dataRDD1: RDD(String, Int) = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 4)))
// 打印原始 RDD 的内容
println("原始 RDD 的内容:")
dataRDD1.collect().foreach(println)
// 使用 groupByKey() 进行分组
val dataRDD2 = dataRDD1.groupByKey()
println("使用 groupByKey() 分组后的结果:")
dataRDD2.collect().foreach(println)
// 使用 groupByKey(2) 进行分组,指定分区数为 2
val dataRDD3 = dataRDD1.groupByKey(2)
println("使用 groupByKey(2) 分组后的结果:")
dataRDD3.collect().foreach(println)
// 使用 groupByKey(new HashPartitioner(2)) 进行分组,指定分区器
val dataRDD4 = dataRDD1.groupByKey(new HashPartitioner(2))
println("使用 groupByKey(new HashPartitioner(2)) 分组后的结果:")
dataRDD4.collect().foreach(println)
// 停止 SparkContext,释放资源
sc.stop()
}
}
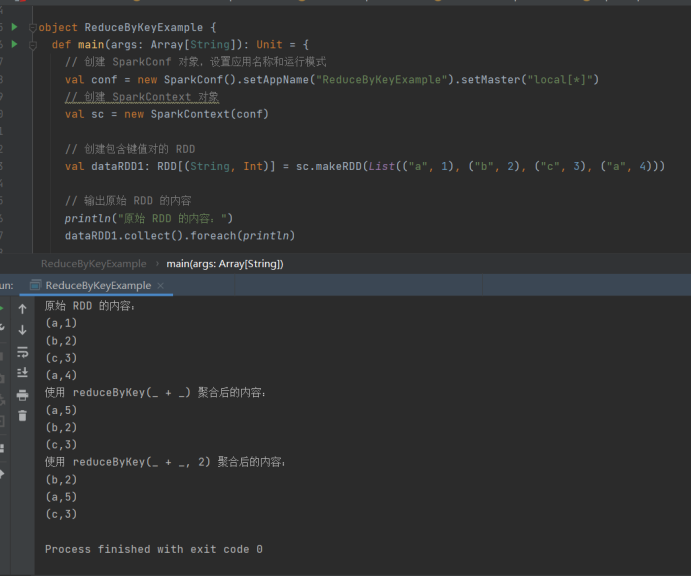
- reduceByKey
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object ReduceByKeyExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("ReduceByKeyExample").setMaster("local\*")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 创建包含键值对的 RDD
val dataRDD1: RDD(String, Int) = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 4)))
// 输出原始 RDD 的内容
println("原始 RDD 的内容:")
dataRDD1.collect().foreach(println)
// 使用 reduceByKey(_ + _) 进行聚合操作
val dataRDD2: RDD(String, Int) = dataRDD1.reduceByKey(_ + _)
println("使用 reduceByKey(_ + _) 聚合后的内容:")
dataRDD2.collect().foreach(println)
// 使用 reduceByKey(_ + _, 2) 进行聚合操作,并指定分区数为 2
val dataRDD3: RDD(String, Int) = dataRDD1.reduceByKey(_ + _, 2)
println("使用 reduceByKey(_ + _, 2) 聚合后的内容:")
dataRDD3.collect().foreach(println)
// 停止 SparkContext,释放资源
sc.stop()
}
}
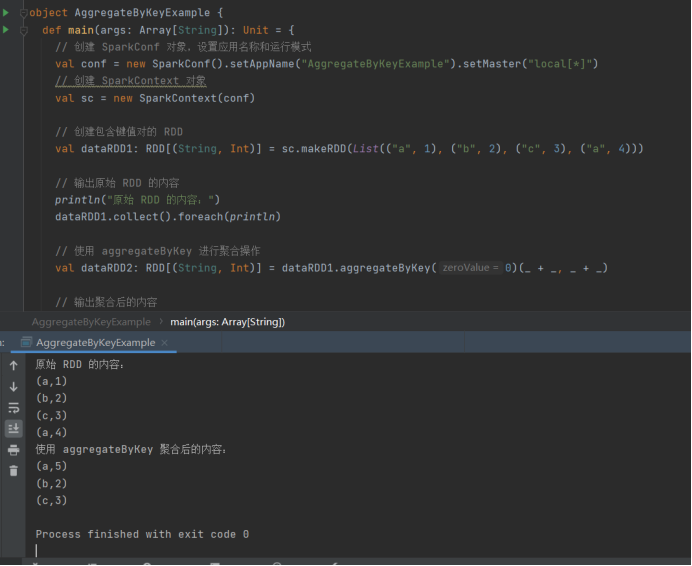
20)aggregateByKey
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object AggregateByKeyExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("AggregateByKeyExample").setMaster("local\*")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 创建包含键值对的 RDD
val dataRDD1: RDD(String, Int) = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 4)))
// 输出原始 RDD 的内容
println("原始 RDD 的内容:")
dataRDD1.collect().foreach(println)
// 使用 aggregateByKey 进行聚合操作
val dataRDD2: RDD(String, Int) = dataRDD1.aggregateByKey(0)(_ + _, _ + _)
// 输出聚合后的内容
println("使用 aggregateByKey 聚合后的内容:")
dataRDD2.collect().foreach(println)
// 停止 SparkContext,释放资源
sc.stop()
}
}
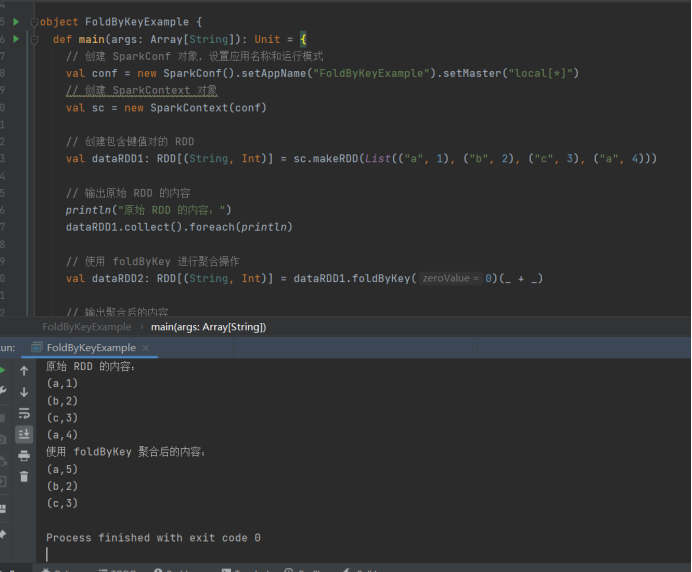
- foldByKey
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object FoldByKeyExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("FoldByKeyExample").setMaster("local\*")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 创建包含键值对的 RDD
val dataRDD1: RDD(String, Int) = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 4)))
// 输出原始 RDD 的内容
println("原始 RDD 的内容:")
dataRDD1.collect().foreach(println)
// 使用 foldByKey 进行聚合操作
val dataRDD2: RDD(String, Int) = dataRDD1.foldByKey(0)(_ + _)
// 输出聚合后的内容
println("使用 foldByKey 聚合后的内容:")
dataRDD2.collect().foreach(println)
// 停止 SparkContext,释放资源
sc.stop()
}
}
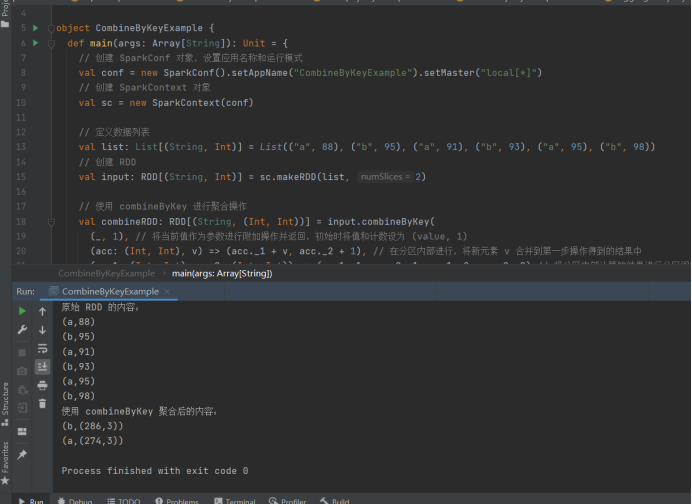
22)combineByKey
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object CombineByKeyExample {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("CombineByKeyExample").setMaster("local\*")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 定义数据列表
val list: List(String, Int) = List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
// 创建 RDD
val input: RDD(String, Int) = sc.makeRDD(list, 2)
// 使用 combineByKey 进行聚合操作
val combineRDD: RDD(String, (Int, Int)) = input.combineByKey(
(_, 1), // 将当前值作为参数进行附加操作并返回,初始时将值和计数设为 (value, 1)
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1), // 在分区内部进行,将新元素 v 合并到第一步操作得到的结果中
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) // 将分区内部计算的结果进行分区间的汇总计算
)
// 输出原始 RDD 的内容
println("原始 RDD 的内容:")
input.collect().foreach(println)
// 输出聚合后的内容
println("使用 combineByKey 聚合后的内容:")
combineRDD.collect().foreach(println)
// 停止 SparkContext,释放资源
sc.stop()
}
}