精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、视频展示
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
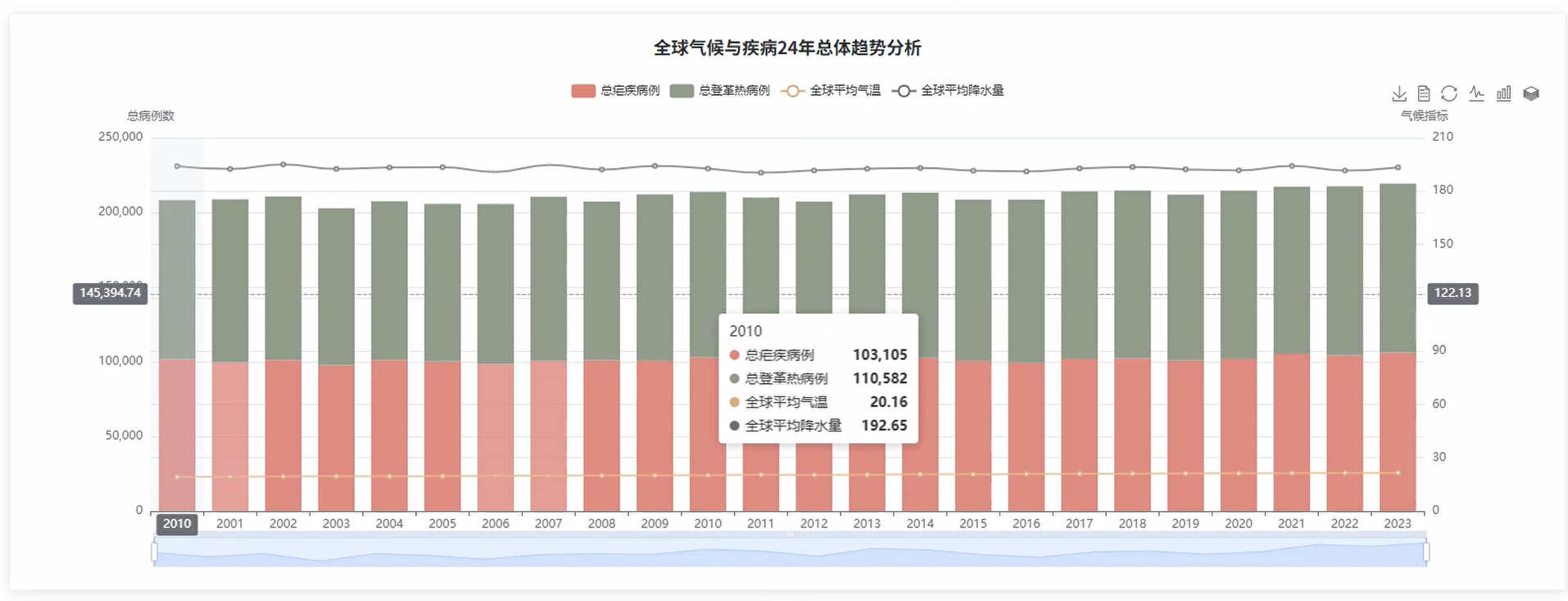
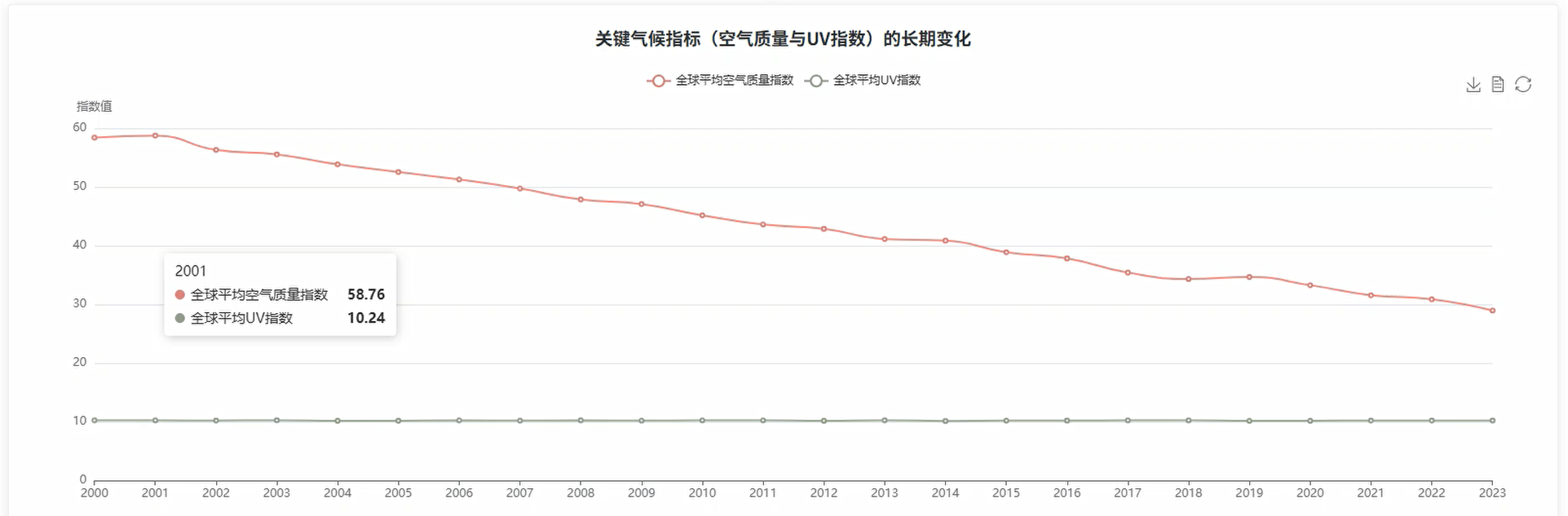
基于Spark的气候驱动的疾病传播可视化分析系统是一个专门针对全球气候变化与疾病传播关系的大数据分析平台。该系统采用Hadoop和Spark作为核心大数据处理引擎,通过Python Django框架构建后端服务,结合Vue前端技术和Echarts可视化工具,实现对全球24年气候数据与疟疾、登革热等疾病传播数据的深度挖掘分析。系统涵盖全局时序分析、地理空间分析、核心驱动因素分析和多指标复合风险评估四大分析维度,能够处理包含温度、降水量、空气质量指数、紫外线指数、人口密度、医疗预算等多元化指标的海量数据集。通过相关性分析、区间分析、象限分析等统计方法,系统可以识别气候因素与疾病传播之间的潜在规律,生成直观的可视化图表包括折线图、柱状图、热力图、散点图和地图等多种形式,为公共卫生决策提供科学的数据支撑和可视化展示平台。
选题背景
当前全球气候变化日益加剧,极端天气事件频发,这种环境变化对人类健康产生了深远影响,特别是在传染病传播方面表现得尤为突出。气温升高、降水模式改变、空气质量恶化等气候因素直接影响着病媒生物的生存环境和繁殖周期,进而改变疾病的传播规律。疟疾和登革热作为典型的气候敏感性疾病,其传播媒介蚊虫的生长发育与温度、湿度等气象条件密切相关,当气候条件适宜时,病媒数量激增,疾病传播风险随之上升。传统的疾病监测和预警系统往往缺乏对大规模历史数据的深度挖掘能力,难以准确识别气候变化与疾病传播之间的复杂关联模式。随着大数据技术的快速发展,利用Spark等分布式计算框架处理海量时空数据成为可能,这为构建更加精准的气候-疾病关联分析模型提供了技术基础。因此,开发一个能够整合多源异构数据、实现大规模数据处理和可视化分析的系统显得十分必要。
选题意义
本研究的实际意义主要体现在为公共卫生部门提供一个实用的决策辅助工具,帮助相关机构更好地理解气候变化对疾病传播的影响机制。通过对历史数据的深度分析,系统能够识别出疾病高发的时间节点和地理区域,为制定针对性的防控策略提供数据依据。从技术角度来看,该系统展示了大数据技术在公共卫生领域的应用潜力,验证了Spark分布式计算在处理大规模时空数据方面的有效性,为类似应用场景提供了可参考的技术方案。对于学术研究而言,系统集成了多种数据分析方法,包括相关性分析、时序分析、空间分析等,形成了相对完整的分析框架,可以为后续相关研究提供方法论参考。同时,系统的可视化功能使得复杂的数据分析结果能够以直观的方式呈现,降低了专业知识门槛,便于非技术人员理解和使用。当然,作为一个毕业设计项目,该系统在数据完整性、算法复杂度等方面还存在一定局限性,但它为探索气候与健康交叉领域的数据分析提供了一个基础平台,具有一定的实践价值和教育意义。
二、视频展示
计算机大数据毕业设计推荐:基于Spark的气候疾病传播可视化分析系统【Hadoop、python、spark】
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
四、系统展示
登录模块:
管理模块展示:
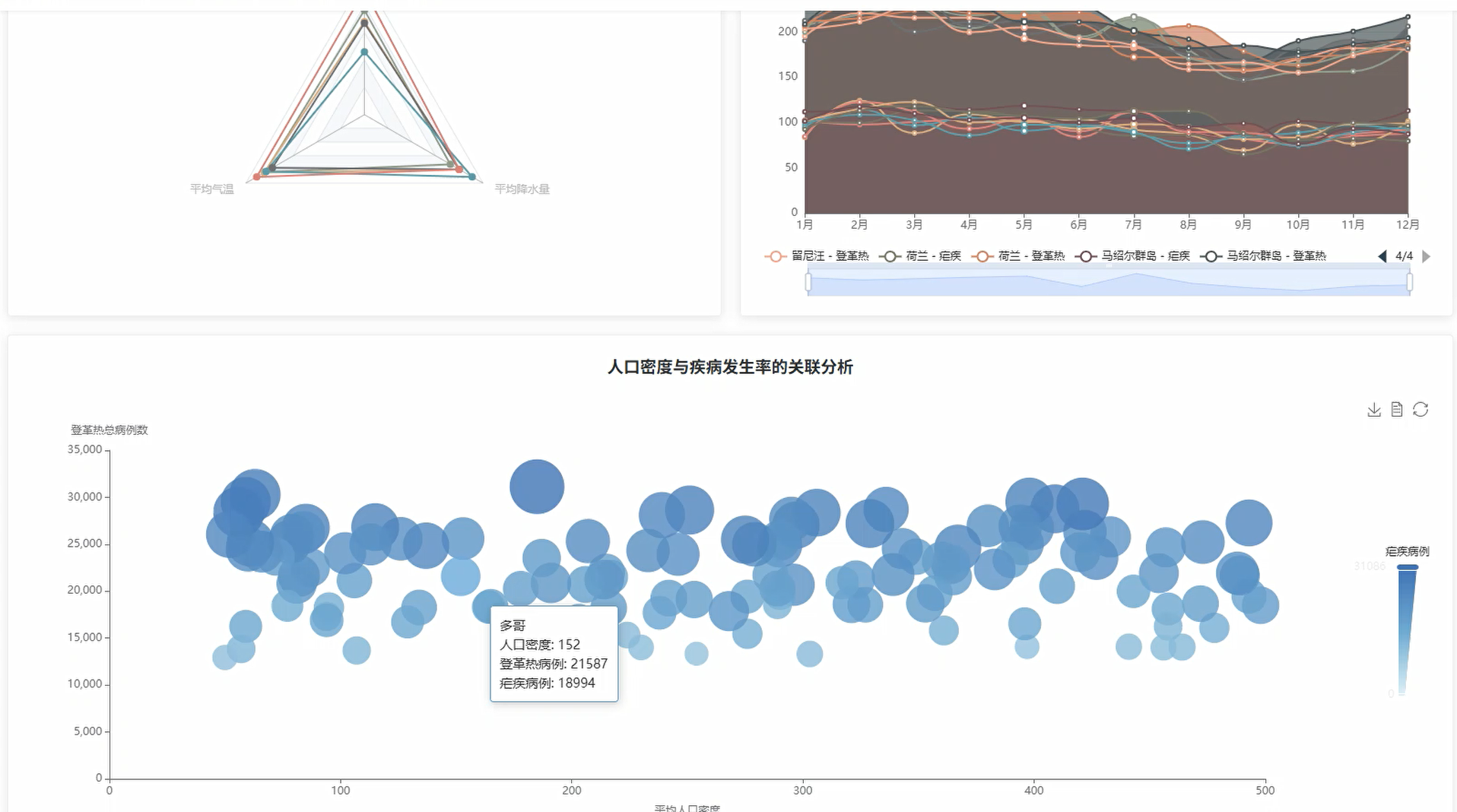
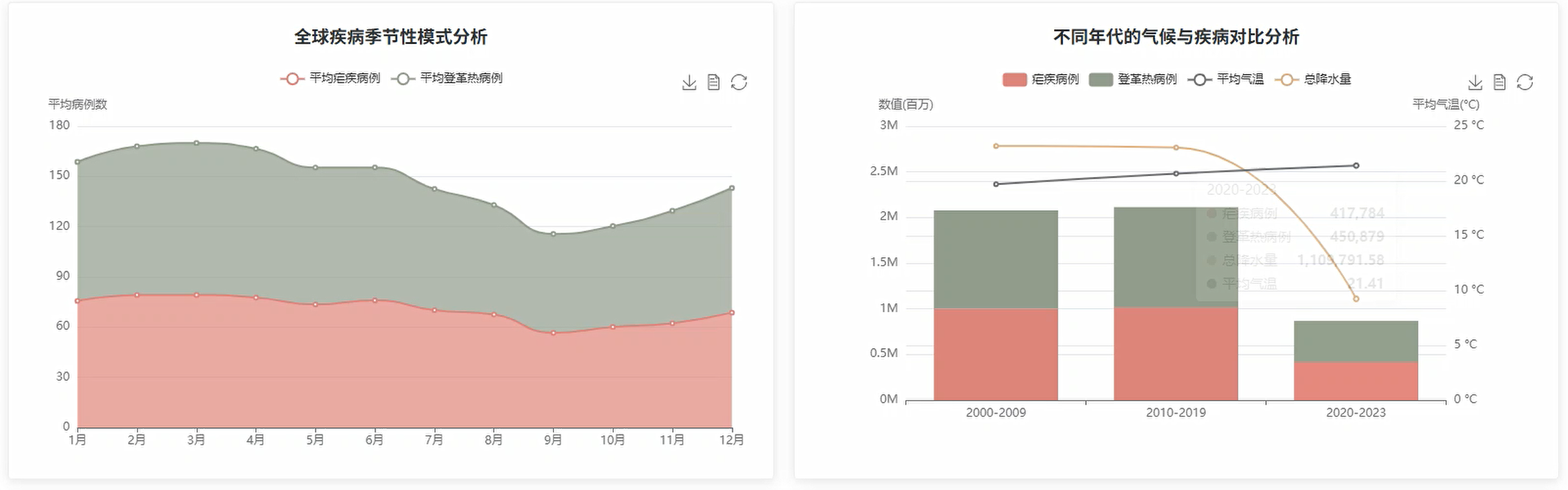
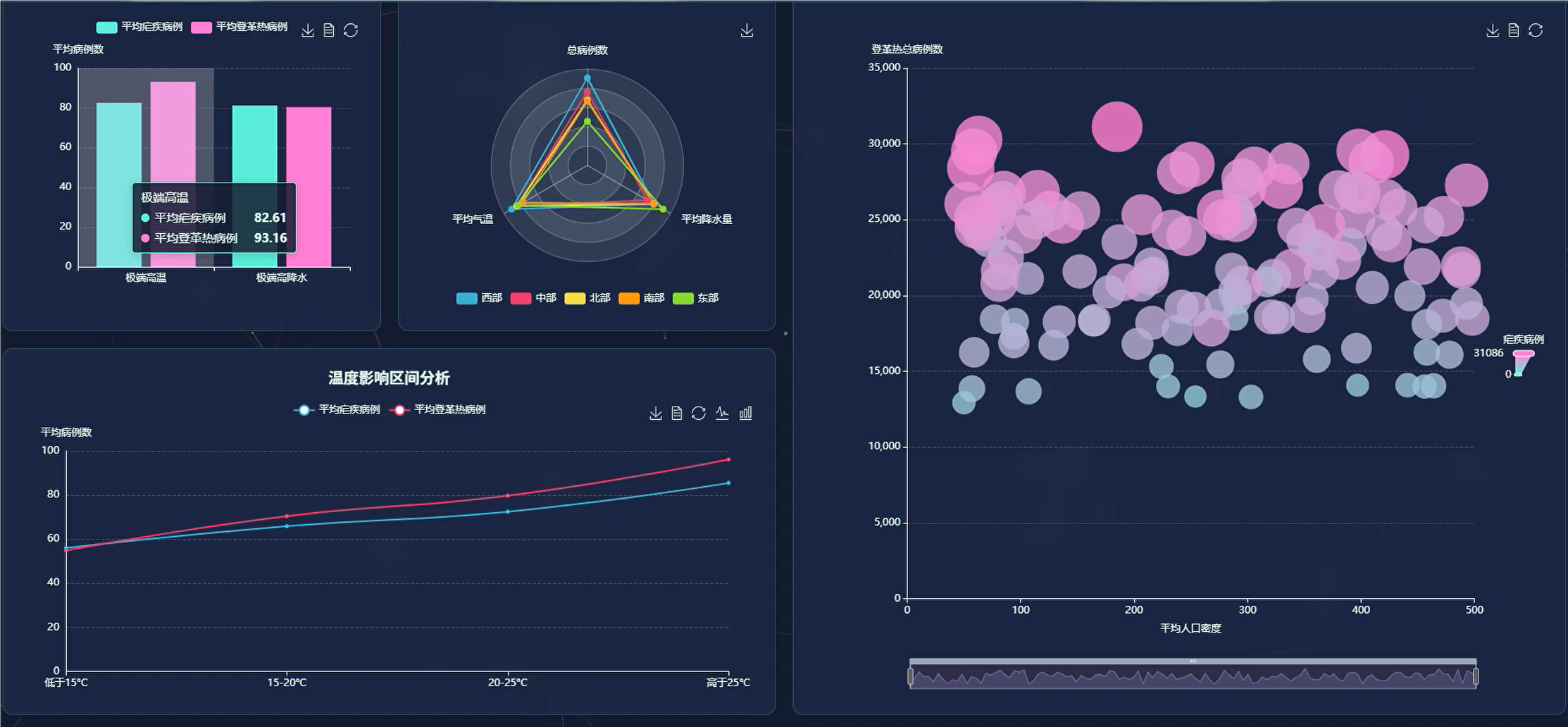
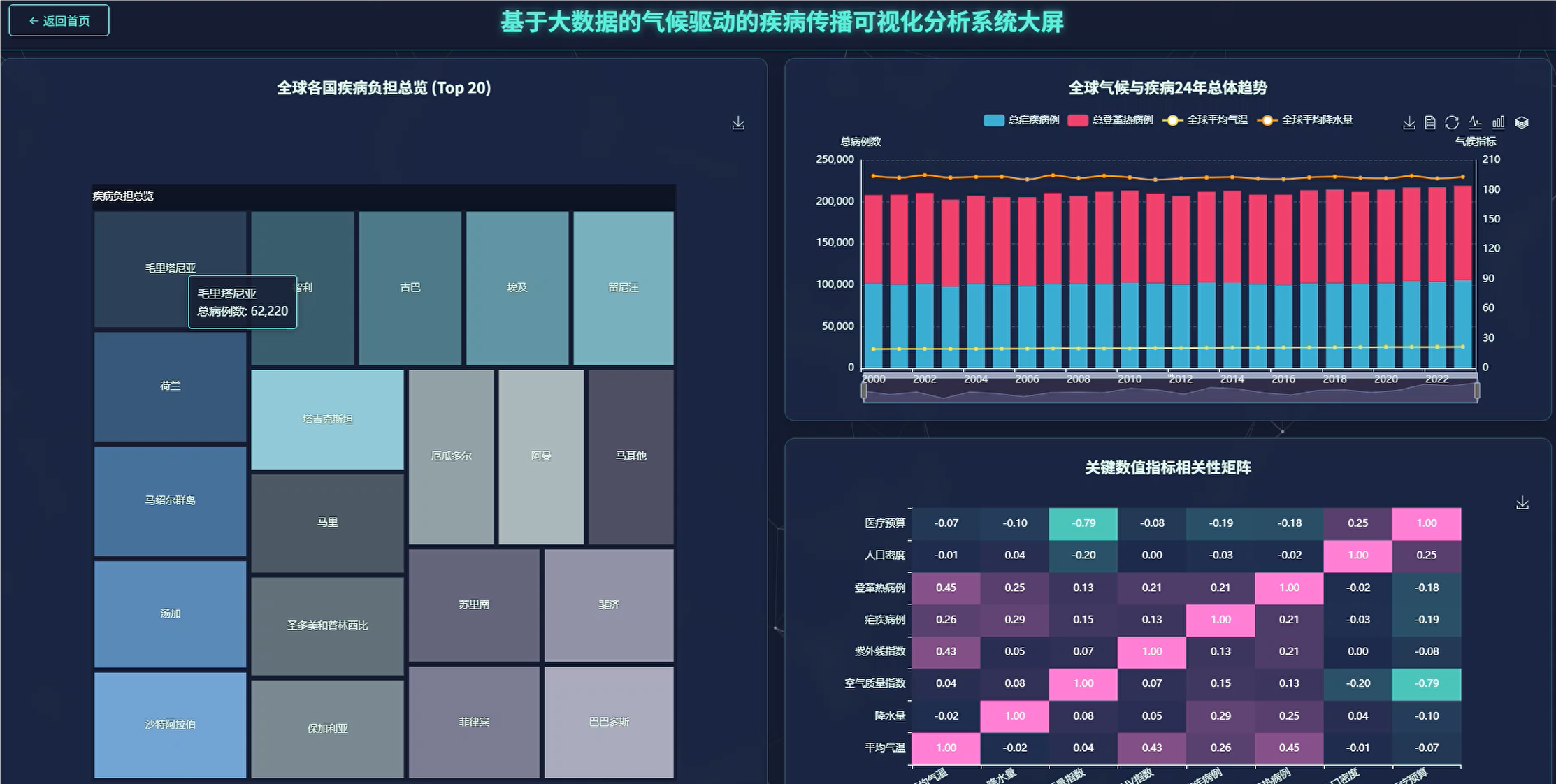
五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import pandas as pd
from django.http import JsonResponse
import json
spark = SparkSession.builder.appName("ClimateDisease").config("spark.sql.adaptive.enabled", "true").getOrCreate()
def global_climate_disease_trend_analysis(request):
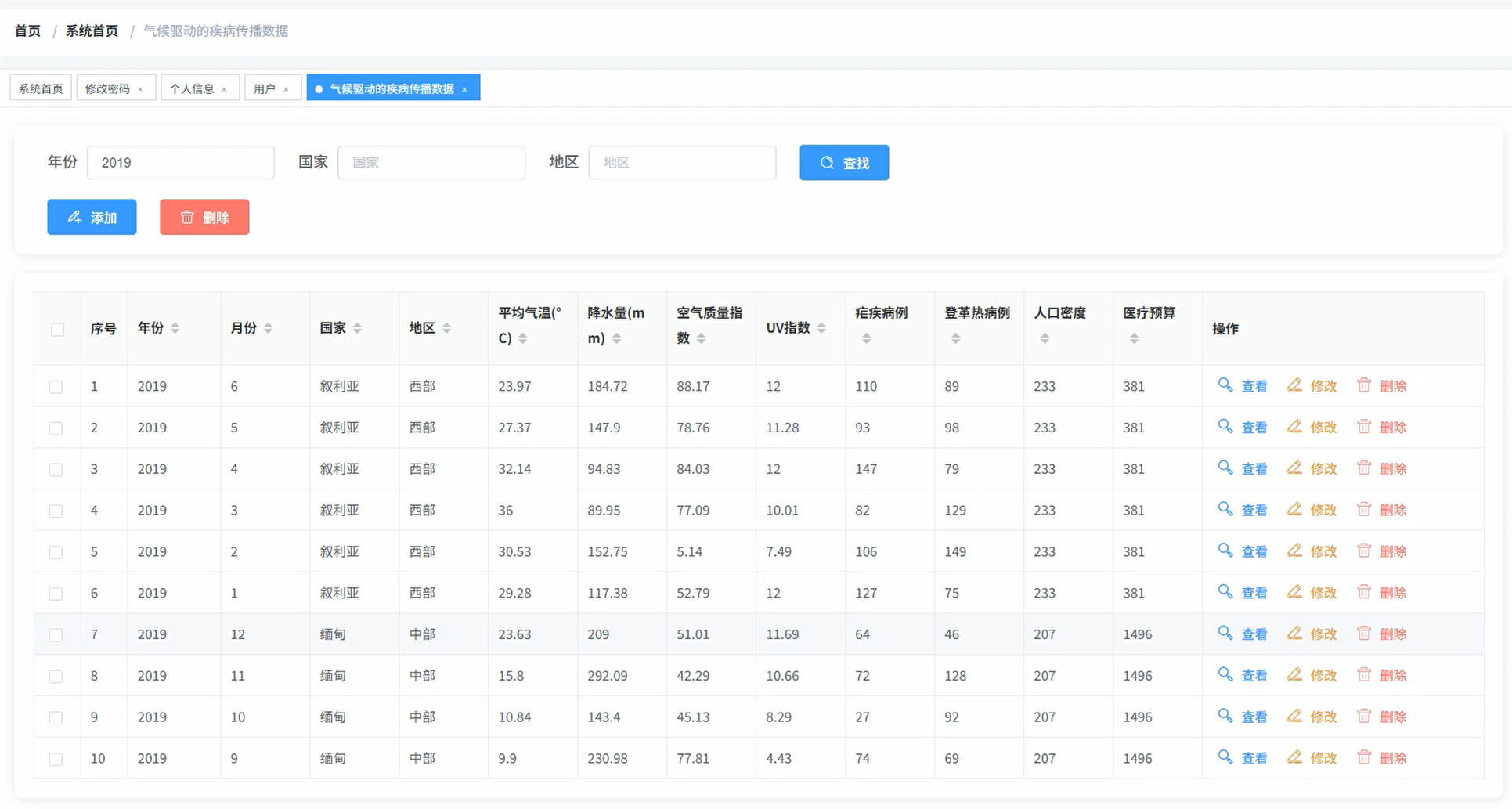
df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/climate_disease_data.csv")
df.createOrReplaceTempView("climate_disease")
yearly_trend = spark.sql("""
SELECT
year,
ROUND(AVG(avg_temp_c), 2) as avg_temperature,
ROUND(AVG(precipitation_mm), 2) as avg_precipitation,
SUM(malaria_cases) as total_malaria_cases,
SUM(dengue_cases) as total_dengue_cases,
ROUND(AVG(air_quality_index), 2) as avg_air_quality,
ROUND(AVG(uv_index), 2) as avg_uv_index
FROM climate_disease
WHERE year >= 2000 AND year <= 2023
GROUP BY year
ORDER BY year
""")
seasonal_pattern = spark.sql("""
SELECT
month,
ROUND(AVG(malaria_cases), 0) as avg_monthly_malaria,
ROUND(AVG(dengue_cases), 0) as avg_monthly_dengue,
COUNT(*) as record_count
FROM climate_disease
GROUP BY month
ORDER BY month
""")
decade_comparison = spark.sql("""
SELECT
CASE
WHEN year BETWEEN 2000 AND 2009 THEN '2000-2009'
WHEN year BETWEEN 2010 AND 2019 THEN '2010-2019'
ELSE '2020-2023'
END as decade,
ROUND(AVG(avg_temp_c), 2) as decade_avg_temp,
ROUND(SUM(precipitation_mm), 2) as decade_total_precipitation,
SUM(malaria_cases + dengue_cases) as decade_total_cases
FROM climate_disease
GROUP BY CASE
WHEN year BETWEEN 2000 AND 2009 THEN '2000-2009'
WHEN year BETWEEN 2010 AND 2019 THEN '2010-2019'
ELSE '2020-2023'
END
ORDER BY decade
""")
yearly_data = yearly_trend.toPandas().to_dict('records')
seasonal_data = seasonal_pattern.toPandas().to_dict('records')
decade_data = decade_comparison.toPandas().to_dict('records')
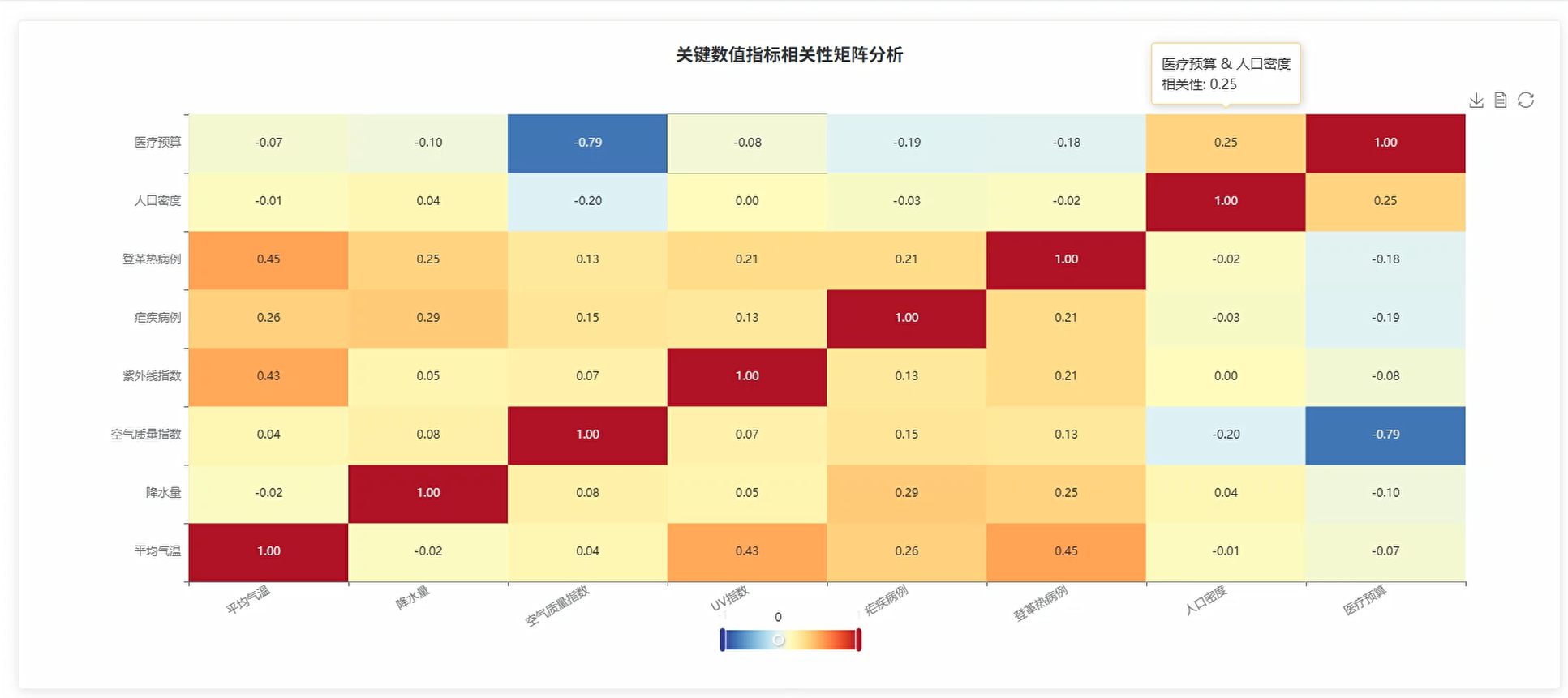
correlation_data = df.select("avg_temp_c", "precipitation_mm", "malaria_cases", "dengue_cases").toPandas().corr().round(3).to_dict()
result = {
'yearly_trend': yearly_data,
'seasonal_pattern': seasonal_data,
'decade_comparison': decade_data,
'correlation_matrix': correlation_data,
'status': 'success'
}
return JsonResponse(result)
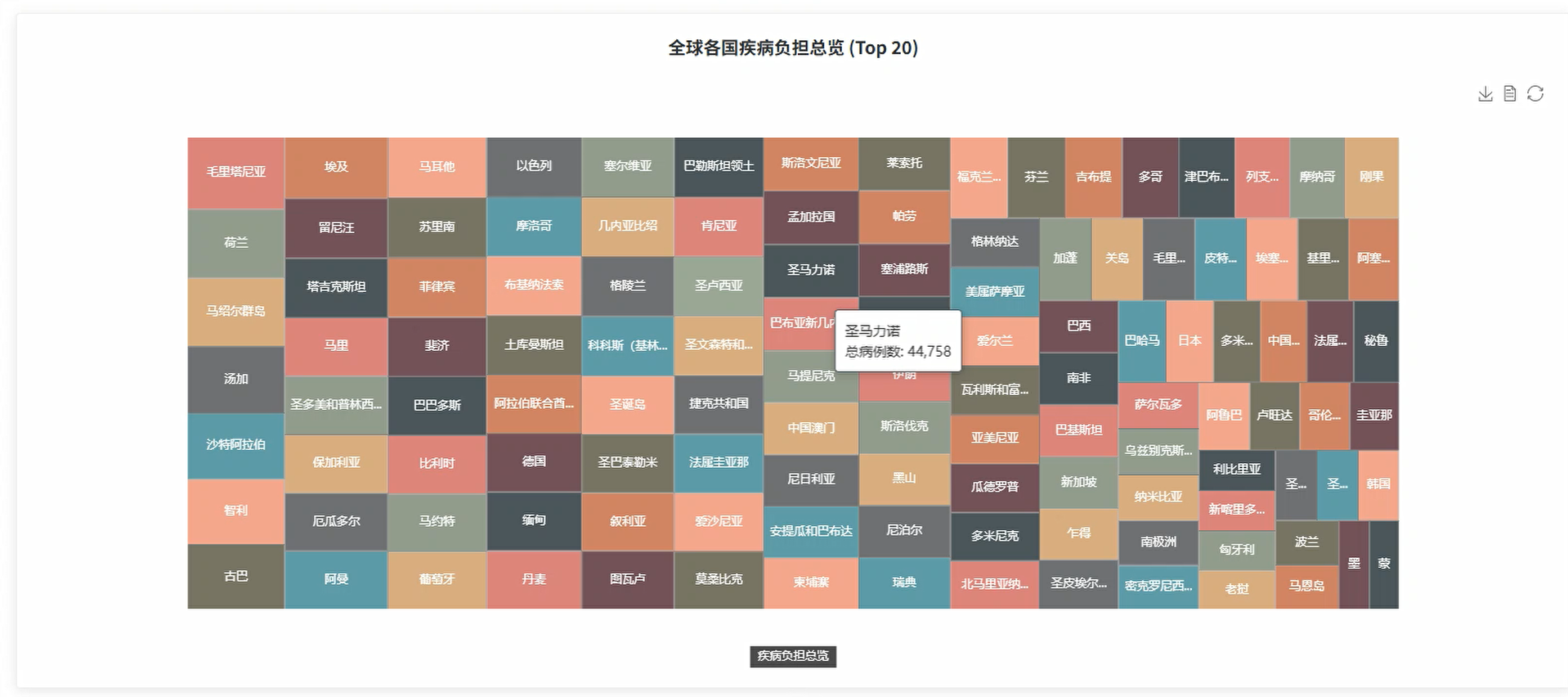
def geographic_spatial_analysis(request):
df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/climate_disease_data.csv")
df.createOrReplaceTempView("climate_disease")
country_disease_burden = spark.sql("""
SELECT
country,
region,
SUM(malaria_cases + dengue_cases) as total_disease_burden,
ROUND(AVG(avg_temp_c), 2) as avg_temperature,
ROUND(AVG(precipitation_mm), 2) as avg_precipitation,
ROUND(AVG(population_density), 0) as avg_population_density,
ROUND(AVG(healthcare_budget), 0) as avg_healthcare_budget,
COUNT(*) as data_points
FROM climate_disease
GROUP BY country, region
ORDER BY total_disease_burden DESC
LIMIT 50
""")
regional_comparison = spark.sql("""
SELECT
region,
SUM(malaria_cases) as total_malaria,
SUM(dengue_cases) as total_dengue,
ROUND(AVG(avg_temp_c), 2) as region_avg_temp,
ROUND(AVG(precipitation_mm), 2) as region_avg_precipitation,
COUNT(DISTINCT country) as countries_in_region
FROM climate_disease
GROUP BY region
ORDER BY (SUM(malaria_cases) + SUM(dengue_cases)) DESC
""")
top10_countries = spark.sql("""
WITH country_totals AS (
SELECT country, SUM(malaria_cases + dengue_cases) as total_cases
FROM climate_disease
GROUP BY country
ORDER BY total_cases DESC
LIMIT 10
)
SELECT
cd.country,
cd.month,
ROUND(AVG(cd.malaria_cases), 0) as avg_malaria_monthly,
ROUND(AVG(cd.dengue_cases), 0) as avg_dengue_monthly
FROM climate_disease cd
INNER JOIN country_totals ct ON cd.country = ct.country
GROUP BY cd.country, cd.month
ORDER BY cd.country, cd.month
""")
population_disease_correlation = spark.sql("""
SELECT
country,
ROUND(AVG(population_density), 0) as avg_pop_density,
SUM(malaria_cases) as total_malaria,
SUM(dengue_cases) as total_dengue,
CASE
WHEN AVG(population_density) < 50 THEN 'Low Density'
WHEN AVG(population_density) < 200 THEN 'Medium Density'
ELSE 'High Density'
END as density_category
FROM climate_disease
GROUP BY country
HAVING AVG(population_density) IS NOT NULL
ORDER BY avg_pop_density DESC
""")
country_data = country_disease_burden.toPandas().to_dict('records')
regional_data = regional_comparison.toPandas().to_dict('records')
top10_seasonal = top10_countries.toPandas().to_dict('records')
population_correlation = population_disease_correlation.toPandas().to_dict('records')
result = {
'country_disease_burden': country_data,
'regional_comparison': regional_data,
'top10_seasonal_patterns': top10_seasonal,
'population_disease_correlation': population_correlation,
'status': 'success'
}
return JsonResponse(result)
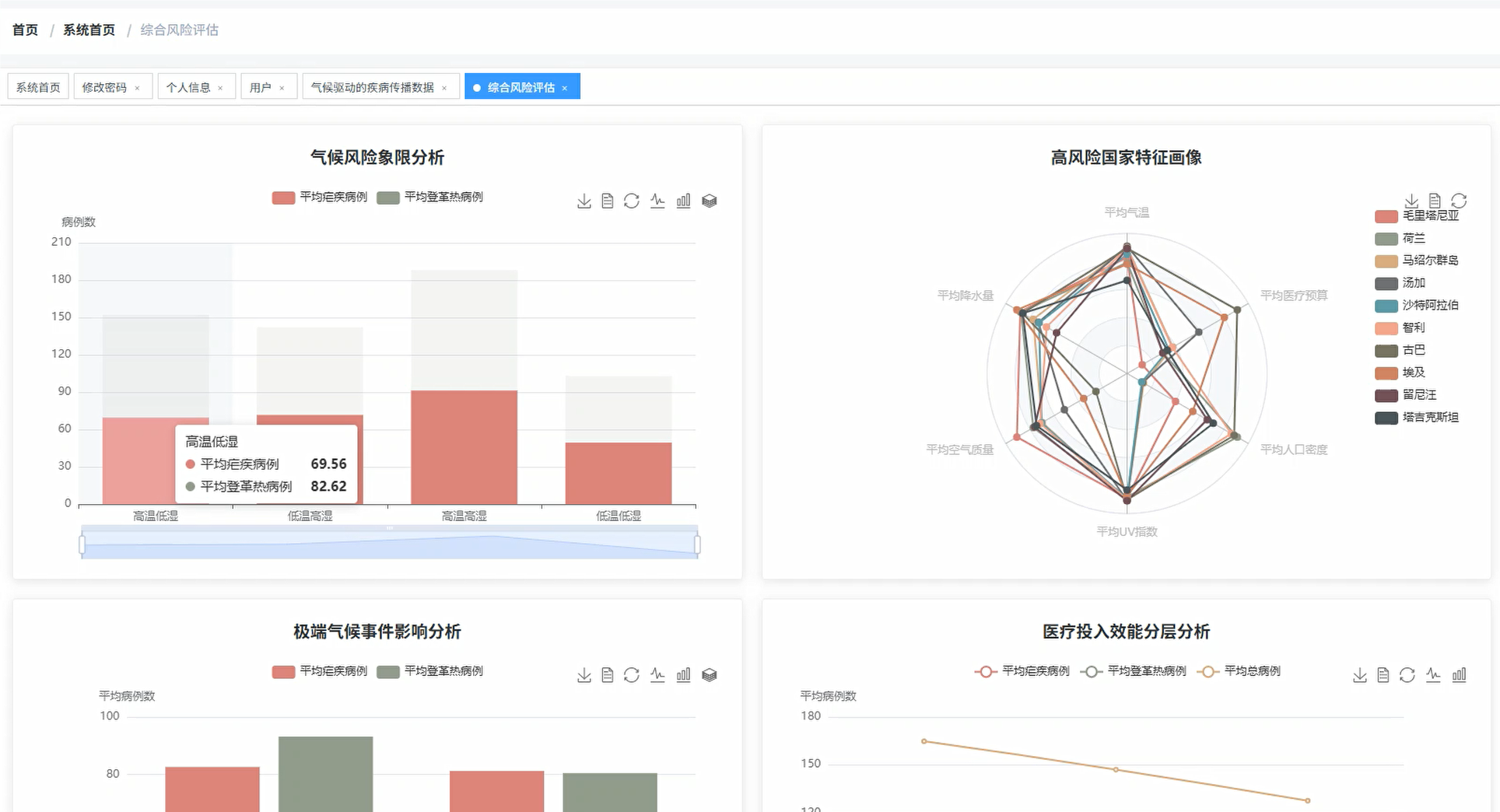
def climate_risk_assessment(request):
df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/climate_disease_data.csv")
df.createOrReplaceTempView("climate_disease")
temp_median = df.approxQuantile("avg_temp_c", [0.5], 0.01)[0]
precipitation_median = df.approxQuantile("precipitation_mm", [0.5], 0.01)[0]
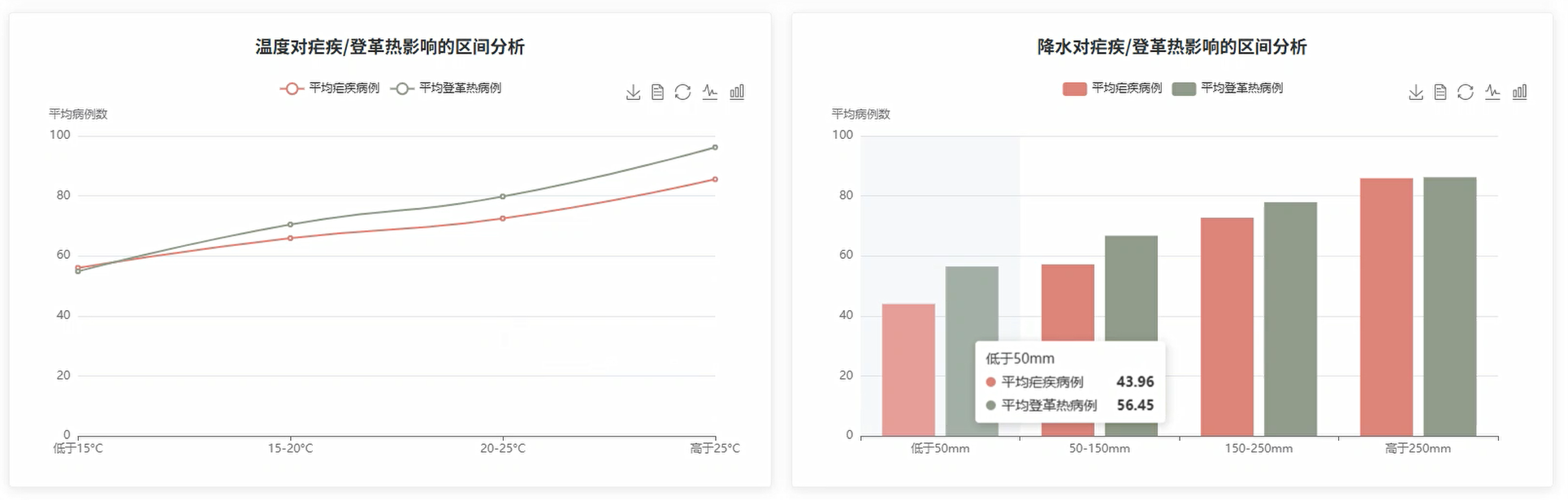
climate_quadrant_analysis = spark.sql(f"""
SELECT
CASE
WHEN avg_temp_c > {temp_median} AND precipitation_mm > {precipitation_median} THEN 'High Temp High Precipitation'
WHEN avg_temp_c > {temp_median} AND precipitation_mm <= {precipitation_median} THEN 'High Temp Low Precipitation'
WHEN avg_temp_c <= {temp_median} AND precipitation_mm > {precipitation_median} THEN 'Low Temp High Precipitation'
ELSE 'Low Temp Low Precipitation'
END as climate_quadrant,
ROUND(AVG(malaria_cases), 0) as avg_malaria_cases,
ROUND(AVG(dengue_cases), 0) as avg_dengue_cases,
COUNT(*) as record_count,
ROUND(AVG(air_quality_index), 2) as avg_air_quality
FROM climate_disease
WHERE avg_temp_c IS NOT NULL AND precipitation_mm IS NOT NULL
GROUP BY CASE
WHEN avg_temp_c > {temp_median} AND precipitation_mm > {precipitation_median} THEN 'High Temp High Precipitation'
WHEN avg_temp_c > {temp_median} AND precipitation_mm <= {precipitation_median} THEN 'High Temp Low Precipitation'
WHEN avg_temp_c <= {temp_median} AND precipitation_mm > {precipitation_median} THEN 'Low Temp High Precipitation'
ELSE 'Low Temp Low Precipitation'
END
""")
high_risk_countries = spark.sql("""
WITH country_rankings AS (
SELECT
country,
SUM(malaria_cases + dengue_cases) as total_cases,
ROW_NUMBER() OVER (ORDER BY SUM(malaria_cases + dengue_cases) DESC) as risk_rank
FROM climate_disease
GROUP BY country
)
SELECT
cd.country,
cr.risk_rank,
ROUND(AVG(cd.avg_temp_c), 2) as profile_avg_temp,
ROUND(AVG(cd.precipitation_mm), 2) as profile_avg_precipitation,
ROUND(AVG(cd.air_quality_index), 2) as profile_avg_air_quality,
ROUND(AVG(cd.population_density), 0) as profile_avg_pop_density,
ROUND(AVG(cd.healthcare_budget), 0) as profile_avg_healthcare_budget
FROM climate_disease cd
INNER JOIN country_rankings cr ON cd.country = cr.country
WHERE cr.risk_rank <= 10
GROUP BY cd.country, cr.risk_rank
ORDER BY cr.risk_rank
""")
healthcare_budget_analysis = spark.sql("""
WITH budget_percentiles AS (
SELECT
PERCENTILE_APPROX(healthcare_budget, 0.33) as low_threshold,
PERCENTILE_APPROX(healthcare_budget, 0.66) as high_threshold
FROM climate_disease
WHERE healthcare_budget IS NOT NULL
)
SELECT
CASE
WHEN cd.healthcare_budget < bp.low_threshold THEN 'Low Budget'
WHEN cd.healthcare_budget < bp.high_threshold THEN 'Medium Budget'
ELSE 'High Budget'
END as budget_category,
ROUND(AVG(cd.malaria_cases + cd.dengue_cases), 0) as avg_total_cases,
COUNT(DISTINCT cd.country) as countries_count,
ROUND(AVG(cd.healthcare_budget), 0) as avg_budget_value
FROM climate_disease cd, budget_percentiles bp
WHERE cd.healthcare_budget IS NOT NULL
GROUP BY CASE
WHEN cd.healthcare_budget < bp.low_threshold THEN 'Low Budget'
WHEN cd.healthcare_budget < bp.high_threshold THEN 'Medium Budget'
ELSE 'High Budget'
END
ORDER BY avg_budget_value
""")
extreme_weather_impact = spark.sql("""
WITH country_stats AS (
SELECT
country,
PERCENTILE_APPROX(avg_temp_c, 0.9) as temp_90th,
PERCENTILE_APPROX(precipitation_mm, 0.9) as precip_90th
FROM climate_disease
GROUP BY country
)
SELECT
cd.country,
SUM(CASE WHEN cd.avg_temp_c > cs.temp_90th OR cd.precipitation_mm > cs.precip_90th THEN cd.malaria_cases + cd.dengue_cases ELSE 0 END) as extreme_weather_cases,
SUM(CASE WHEN cd.avg_temp_c <= cs.temp_90th AND cd.precipitation_mm <= cs.precip_90th THEN cd.malaria_cases + cd.dengue_cases ELSE 0 END) as normal_weather_cases,
COUNT(CASE WHEN cd.avg_temp_c > cs.temp_90th OR cd.precipitation_mm > cs.precip_90th THEN 1 END) as extreme_months,
COUNT(*) as total_months
FROM climate_disease cd
INNER JOIN country_stats cs ON cd.country = cs.country
GROUP BY cd.country
HAVING COUNT(*) > 12
ORDER BY extreme_weather_cases DESC
LIMIT 20
""")
quadrant_data = climate_quadrant_analysis.toPandas().to_dict('records')
high_risk_data = high_risk_countries.toPandas().to_dict('records')
budget_analysis_data = healthcare_budget_analysis.toPandas().to_dict('records')
extreme_weather_data = extreme_weather_impact.toPandas().to_dict('records')
result = {
'climate_quadrant_analysis': quadrant_data,
'high_risk_country_profiles': high_risk_data,
'healthcare_budget_effectiveness': budget_analysis_data,
'extreme_weather_impact': extreme_weather_data,
'analysis_parameters': {
'temperature_median': temp_median,
'precipitation_median': precipitation_median
},
'status': 'success'
}
return JsonResponse(result)六、项目文档展示

七、项目总结
基于Spark的气候驱动的疾病传播可视化分析系统是一个综合性的大数据分析平台,成功实现了对全球气候变化与疾病传播关系的深度挖掘和可视化展示。该系统通过Hadoop和Spark分布式计算框架处理海量的24年全球气候与疾病数据,结合Python Django后端服务和Vue前端技术,构建了完整的数据分析和可视化解决方案。
从技术实现角度来看,系统采用了成熟的大数据技术栈,通过SparkSQL实现复杂的数据查询和统计分析,包括时序趋势分析、地理空间分析、相关性分析和风险评估等核心功能。系统能够处理温度、降水量、疾病病例、人口密度、医疗预算等多维度指标,通过相关性矩阵、象限分析、分组统计等方法揭示气候因素与疾病传播之间的潜在规律。
从应用价值方面,该系统为公共卫生领域提供了一个实用的数据分析工具,能够识别疾病高发的时间节点和地理区域,支持制定针对性的防控策略。同时,系统的可视化功能通过Echarts生成直观的图表,使得复杂的分析结果能够以易于理解的方式呈现,降低了专业门槛。
作为毕业设计项目,该系统展示了大数据技术在交叉学科应用中的潜力,虽然在数据完整性和算法复杂度方面还有提升空间,但为探索气候与健康交叉领域的数据分析提供了有价值的实践案例和技术参考。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖