spark安装
1.上传并解压
tar -zxvf spark-3.5.0-bin-hadoop3.tgz -C /opt/module/
2.配置环境变量
vim /etc/profile.d/my_env.sh
#spark环境变量
export SPARK_HOME=/opt/module/spark-3.5.0
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
刷新环境变量生效
source /etc/profile3.修改配置文件
进入conf目录下
cd /opt/module/spark-3.5.0/conf/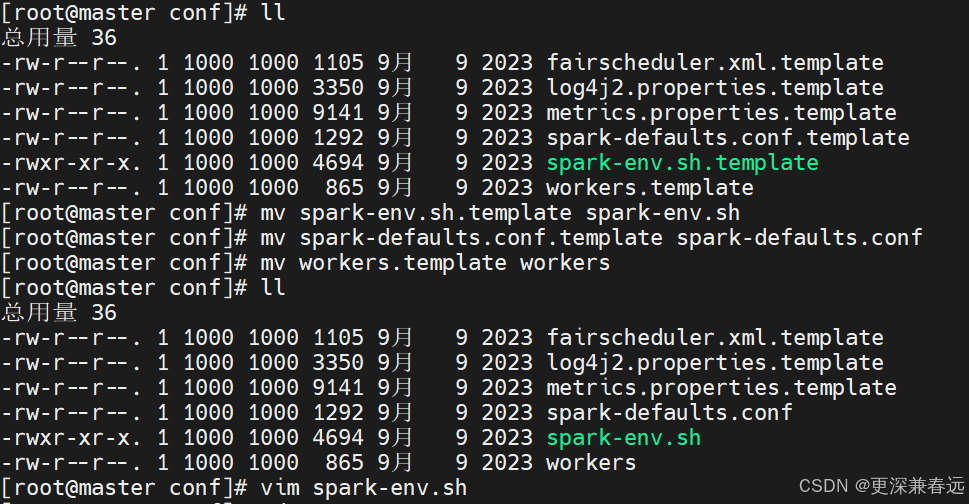
export JAVA_HOME=/opt/module/jdk1.8.0_161
export HADOOP_HOME=/opt/module/hadoop-3.1.4
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.4/etc/hadoop
export SPARK_MASTER_HOST=master
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=1
export SPARK_MASTER_WEBUI_PORT=8080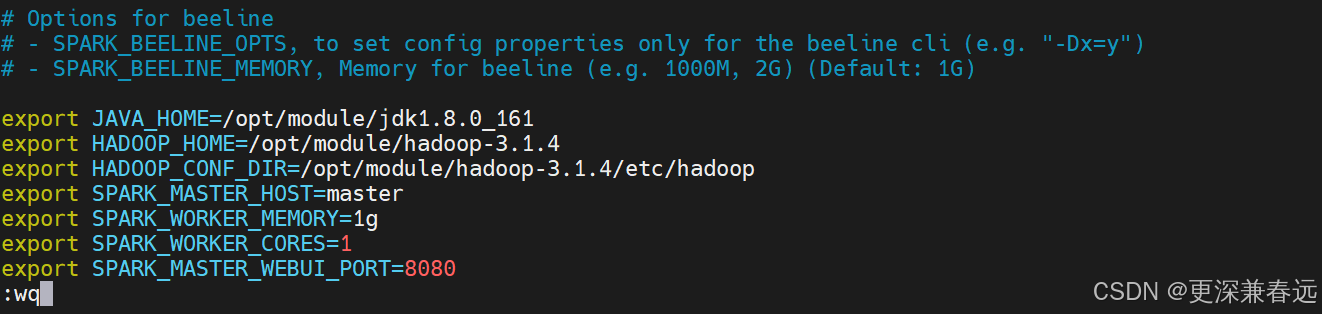
vim workers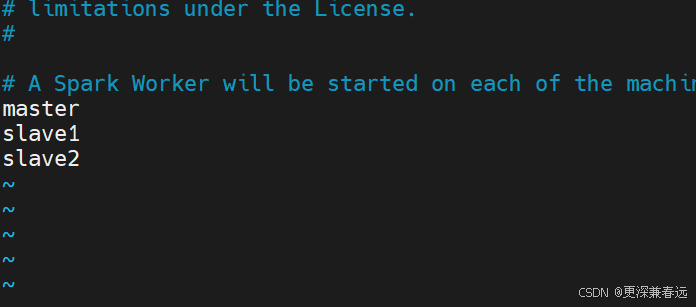
vim spark-defaults.conf
4.分发文件
scp -r /opt/module/spark-3.5.0/ slave1:/opt/module/
scp -r /opt/module/spark-3.5.0/ slave2:/opt/module/
scp -r /etc/profile.d/my_env.sh slave1:/etc/profile.d/
scp -r /etc/profile.d/my_env.sh slave2:/etc/profile.d/传完记得分别source刷新
5.启动spark
启动master进程,jps查看

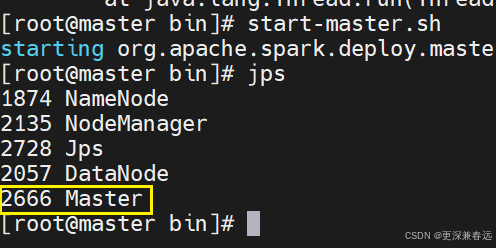
启动worker节点
./sbin/start-worker.sh spark://master:7077
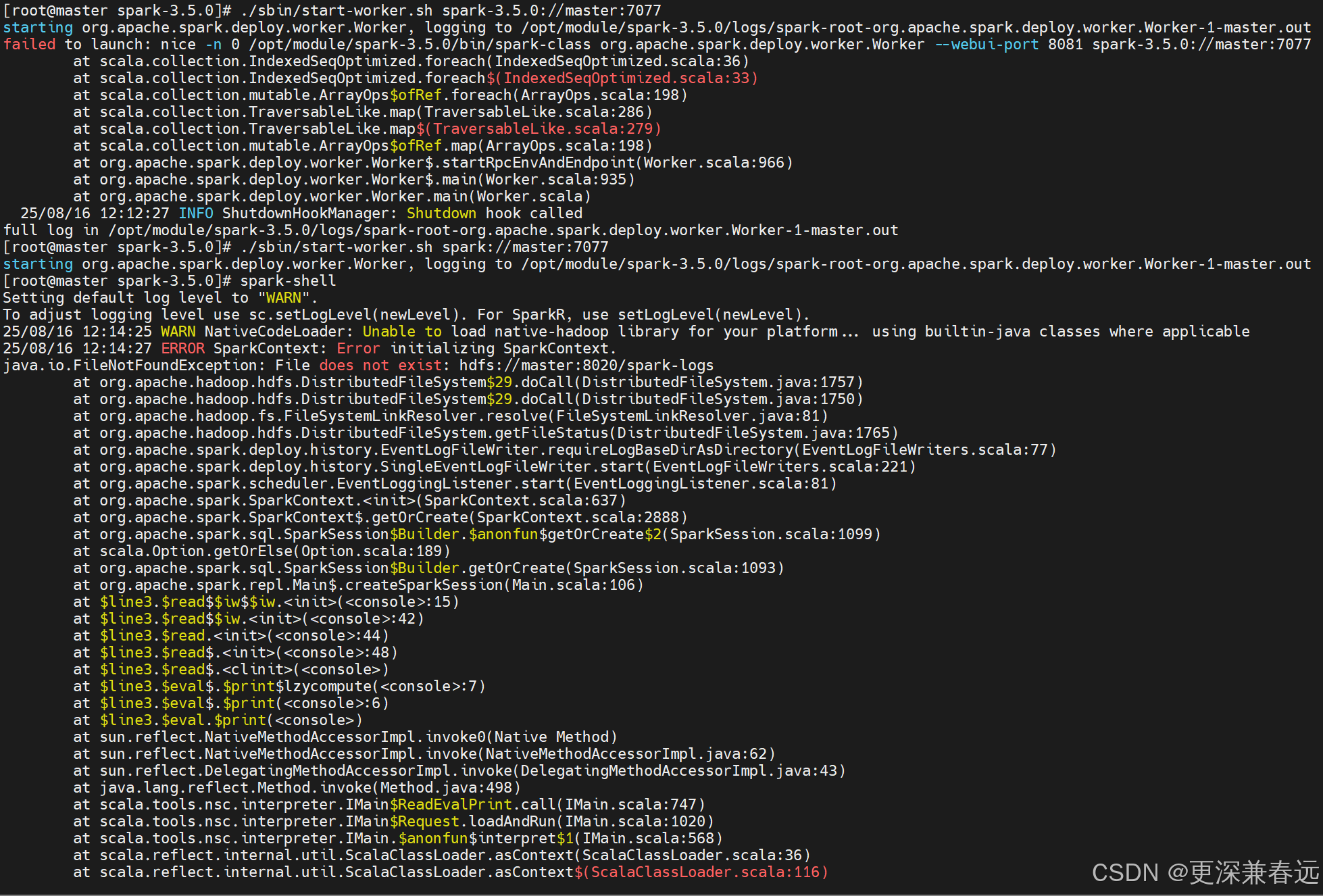
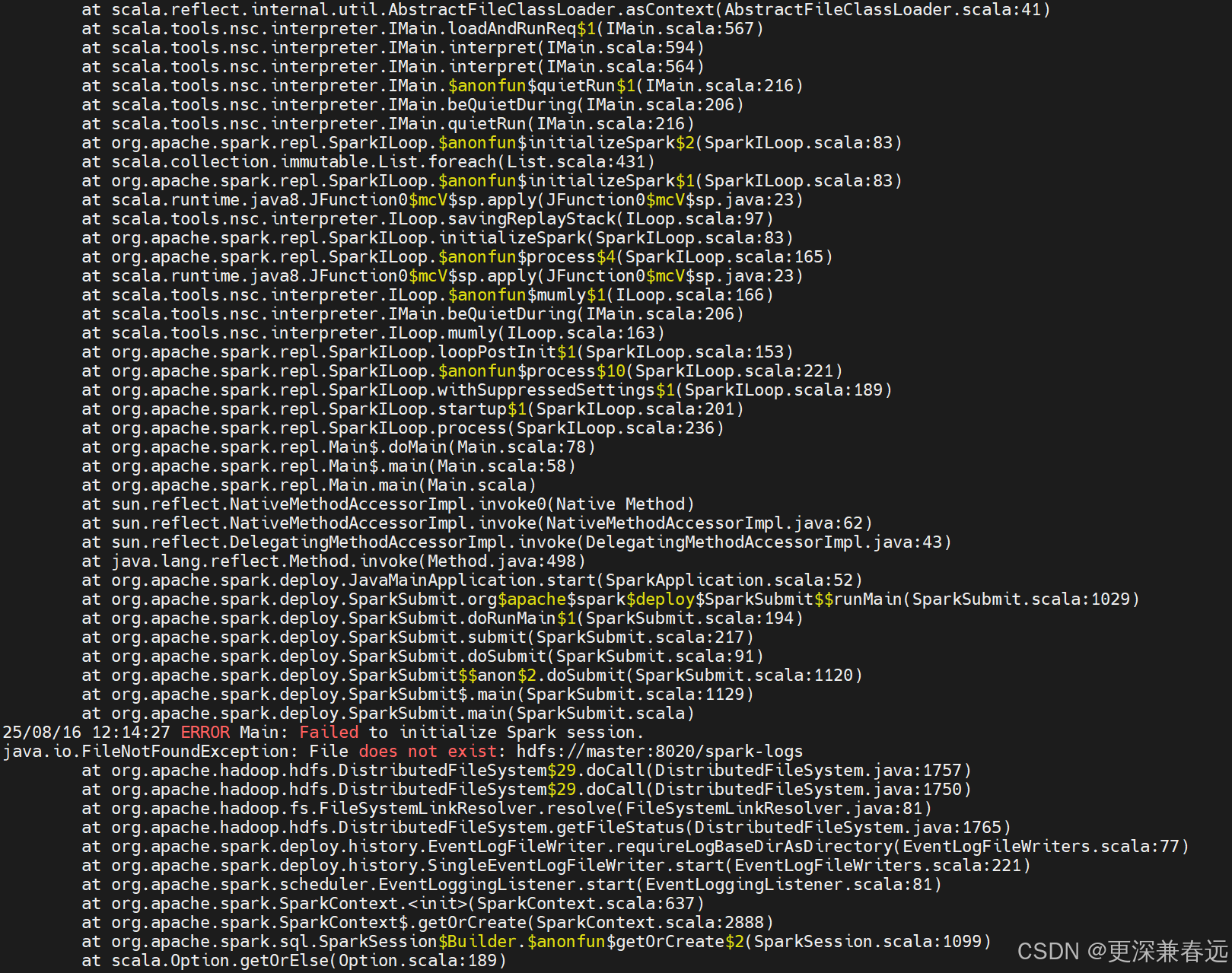
报错:问题出在 Spark 无法找到 HDFS 上的/spark-logs目录,这是由于 Spark 的事件日志(Event Log)功能配置了 HDFS 路径,但该路径不存在导致的。
因此在hdfs上创建目录,为了方便赋予权限
# 在HDFS上创建spark-logs目录
hdfs dfs -mkdir -p /spark-logs
# 赋予读写权限(根据实际需求调整权限,这里开放所有权限方便测试)
hdfs dfs -chmod 777 /spark-logs重新启动
spark-shell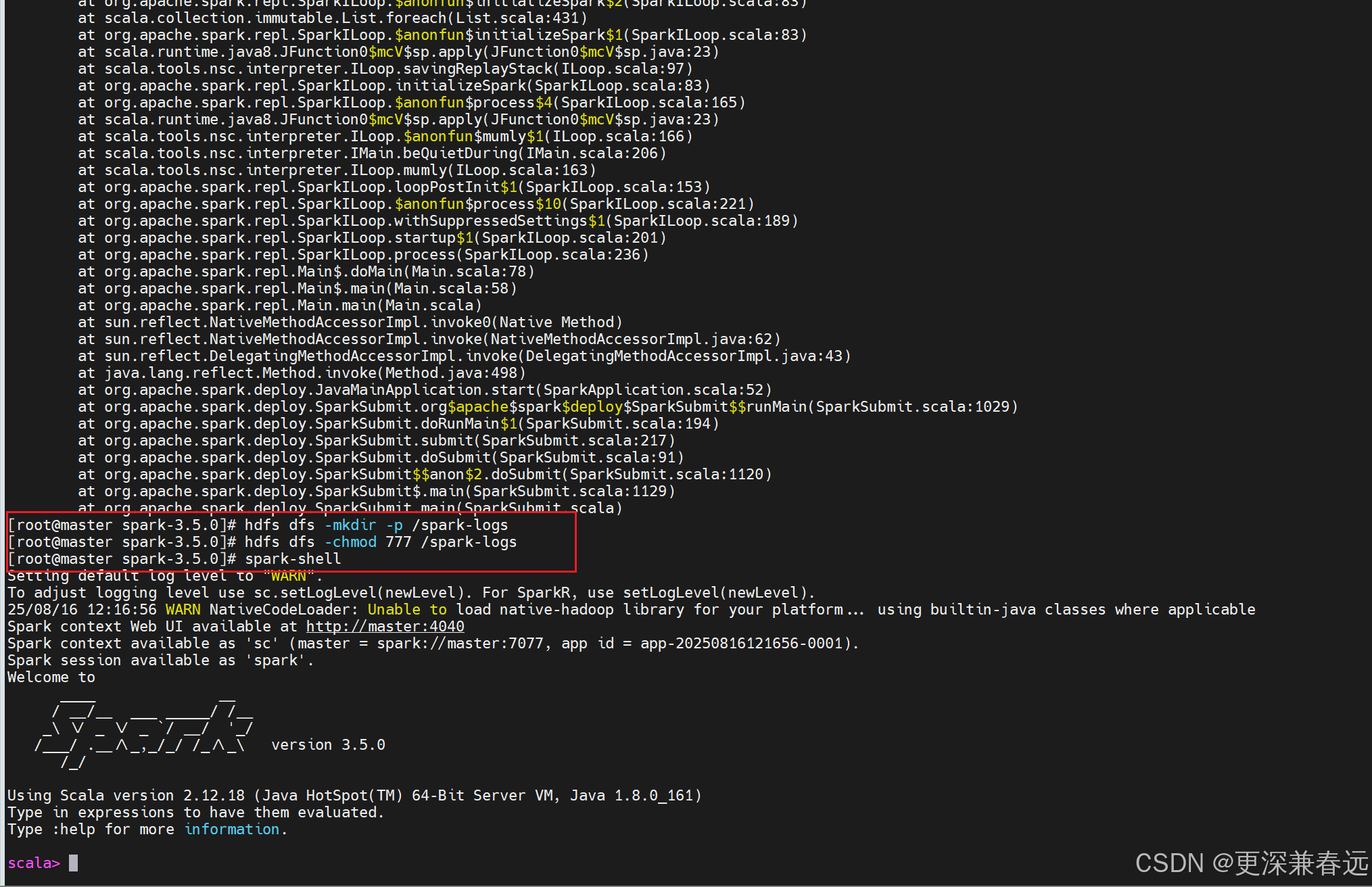
ctrl+c退出
scala安装
1.上传并解压
tar -zxvf scala-2.12.0.tgz -C /opt/module/
2.启动zookeeper
cd /opt/module/zookeeper-3.5.7/bin/
./zkServer.sh start
3.启动journalnode(守护进程)

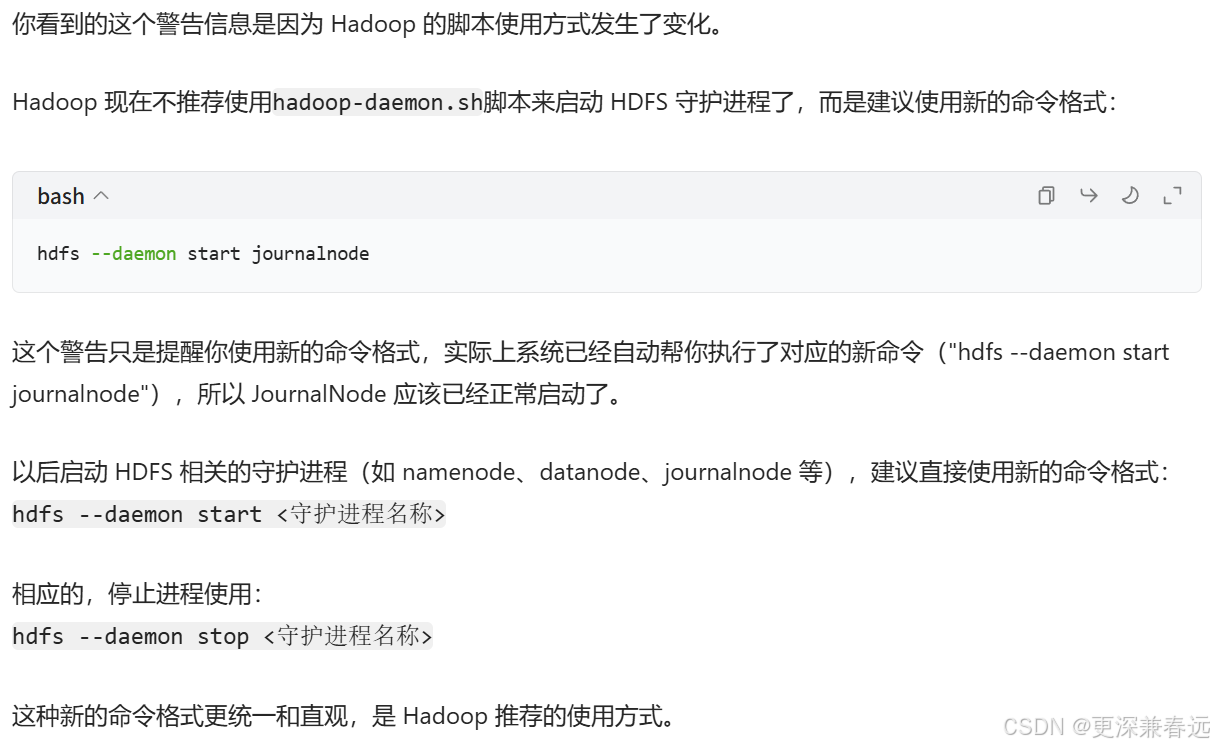
hdfs --daemon start journalnode
4.启动Hadoop
start-dfs.sh
start-yarn.sh5.配置环境变量
vim /etc/profile.d/my_env.sh
#scala环境变量
export SCALA_HOME=/opt/module/scala-2.12.0
export PATH=$SCALA_HOME/bin:$PATH
刷新环境变量生效
source /etc/profile6.测试scala
scala -version
7.进入并退出scala
scala:进入
:quit:退出
