🌟引言 :
欢迎来到Python星球🪐的第20天!今天我们将踏入数据分析 的世界,学习如何使用pandas 处理数据并提取有价值的信息。无论你是想分析商业销售数据、股票市场趋势还是科学实验结果,pandas都是你必不可少的工具!
上一篇:Python星球日记 - 第19天:Web开发基础
名人说:路漫漫其修远兮,吾将上下而求索。------ 屈原《离骚》
创作者:Code_流苏(CSDN) (一个喜欢古诗词和编程的Coder😊)目录
- 一、Pandas简介:数据分析的瑞士军刀
- [1. Pandas的两大核心数据结构](#1. Pandas的两大核心数据结构)
- [2. 安装并导入pandas](#2. 安装并导入pandas)
- 二、数据处理基础
- [1. 创建DataFrame](#1. 创建DataFrame)
- [2. 基本数据查看](#2. 基本数据查看)
- [3. 数据选择与索引](#3. 数据选择与索引)
- 三、数据清洗与处理
- [1. 处理缺失值](#1. 处理缺失值)
- [2. 数据转换](#2. 数据转换)
- [3. 数据聚合](#3. 数据聚合)
- 四、数据分析与可视化
- [1. 基本统计分析](#1. 基本统计分析)
- [2. 简单可视化](#2. 简单可视化)
- 五、实战练习:销售数据分析
- [1. 读取CSV文件](#1. 读取CSV文件)
- [2. 数据清洗](#2. 数据清洗)
- [3. 数据分析](#3. 数据分析)
- [4. 数据可视化](#4. 数据可视化)
- [5. 高级分析:RFM客户分析](#5. 高级分析:RFM客户分析)
- 6.完整代码
- 详细图表清单
- 六、总结与进阶学习路径
- [1. 今日要点](#1. 今日要点)
- [2. 进阶学习方向](#2. 进阶学习方向)
- [3. 实践建议](#3. 实践建议)
- 七、练习题
专栏介绍: Python星球日记专栏介绍(持续更新ing)
更多Python知识,请关注我、订阅专栏《 Python星球日记》,内容持续更新中...

一、Pandas简介:数据分析的瑞士军刀
Pandas 是Python数据分析的核心库,它提供了高效的数据结构和数据分析工具。如果你想在Python中进行数据分析,pandas是必不可少的库。
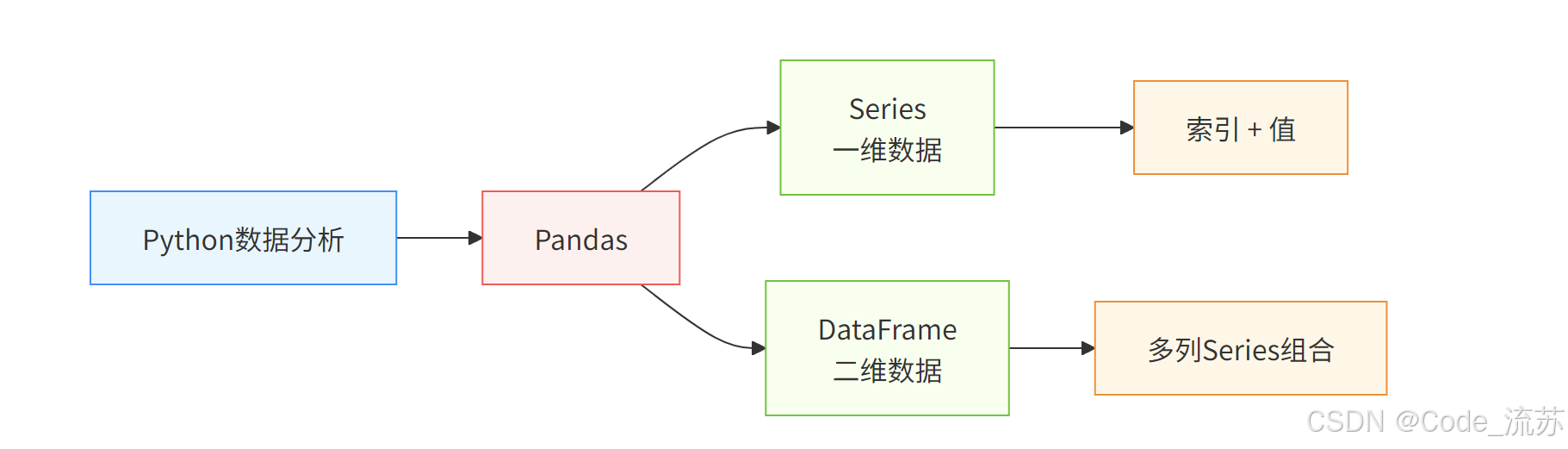
1. Pandas的两大核心数据结构
Pandas有两个基本的数据结构:Series和DataFrame。
- Series :一维数组结构,类似于Python的列表,但具有标签索引
- DataFrame :二维表格数据结构,可以看作是多个Series组成的表格
2. 安装并导入pandas
在开始学习之前,我们需要安装pandas库并导入它:
1️⃣使用 pip 安装pandas
python
pip install pandas2️⃣通过import导入pandas库
python
# 导入pandas
import pandas as pd # pd是pandas的常用缩写二、数据处理基础
1. 创建DataFrame
DataFrame是pandas最常用的数据结构,类似于Excel表格或SQL表。让我们看看如何创建一个DataFrame:
python
import pandas as pd
import numpy as np
# 从字典创建DataFrame
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 35, 40],
'城市': ['北京', '上海', '广州', '深圳'],
'工资': [10000, 20000, 15000, 25000]
}
df = pd.DataFrame(data)
print(df)输出结果:
python
姓名 年龄 城市 工资
0 张三 25 北京 10000
1 李四 30 上海 20000
2 王五 35 广州 15000
3 赵六 40 深圳 250002. 基本数据查看
拿到数据后,首先需要对数据有个基本了解:
python
# 查看前几行数据
print(df.head()) # 默认显示前5行
python
# 查看数据基本信息
print(df.info())
python
# 查看数据统计摘要
print(df.describe())
python
# 查看数据维度
print(df.shape) # 输出: (行数, 列数)完整代码:
python
import pandas as pd
import numpy as np
# 从字典创建DataFrame
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 35, 40],
'城市': ['北京', '上海', '广州', '深圳'],
'工资': [10000, 20000, 15000, 25000]
}
df = pd.DataFrame(data)
# 查看前几行数据
print(df.head()) # 默认显示前5行
# 查看数据基本信息
print(df.info())
# 查看数据统计摘要
print(df.describe())
# 查看数据维度
print(df.shape) # 输出: (行数, 列数)输出结果:
python
姓名 年龄 城市 工资
0 张三 25 北京 10000
1 李四 30 上海 20000
2 王五 35 广州 15000
3 赵六 40 深圳 25000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 姓名 4 non-null object
1 年龄 4 non-null int64
2 城市 4 non-null object
3 工资 4 non-null int64
dtypes: int64(2), object(2)
memory usage: 260.0+ bytes
None
年龄 工资
count 4.000000 4.000000
mean 32.500000 17500.000000
std 6.454972 6454.972244
min 25.000000 10000.000000
25% 28.750000 13750.000000
50% 32.500000 17500.000000
75% 36.250000 21250.000000
max 40.000000 25000.000000
(4, 4)3. 数据选择与索引
pandas提供了多种方式来选择数据:
python
# 选择单列
print(df['姓名']) # 返回Series
python
# 选择多列
print(df[['姓名', '工资']]) # 返回DataFrame
python
# 通过位置选择行
print(df.iloc[0]) # 选择第一行
print(df.iloc[0:2]) # 选择前两行
python
# 通过标签选择行
print(df.loc[0]) # 选择索引为0的行
python
# 条件选择
print(df[df['年龄'] > 30]) # 选择年龄大于30的行完整代码:
python
import pandas as pd
import numpy as np
# 从字典创建DataFrame
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 35, 40],
'城市': ['北京', '上海', '广州', '深圳'],
'工资': [10000, 20000, 15000, 25000]
}
df = pd.DataFrame(data)
# 选择单列
print(df['姓名']) # 返回Series
# 选择多列
print(df[['姓名', '工资']]) # 返回DataFrame
# 通过位置选择行
print(df.iloc[0]) # 选择第一行
print(df.iloc[0:2]) # 选择前两行
# 通过标签选择行
print(df.loc[0]) # 选择索引为0的行
# 条件选择
print(df[df['年龄'] > 30]) # 选择年龄大于30的行输出结果:
python
0 张三
1 李四
2 王五
3 赵六
Name: 姓名, dtype: object
姓名 工资
0 张三 10000
1 李四 20000
2 王五 15000
3 赵六 25000
姓名 张三
年龄 25
城市 北京
工资 10000
Name: 0, dtype: object
姓名 年龄 城市 工资
0 张三 25 北京 10000
1 李四 30 上海 20000
姓名 张三
年龄 25
城市 北京
工资 10000
Name: 0, dtype: object
姓名 年龄 城市 工资
2 王五 35 广州 15000
3 赵六 40 深圳 25000三、数据清洗与处理
在实际工作中,数据 往往不是完美 的,需要进行清洗和处理。
清洗流程如下:

1. 处理缺失值
缺失值是数据分析中常见的问题。pandas使用NaN(Not a Number)表示缺失值:
python
# 创建包含缺失值的DataFrame
df_missing = pd.DataFrame({
'姓名': ['张三', '李四', '王五', None],
'年龄': [25, None, 35, 40],
'城市': ['北京', '上海', None, '深圳'],
'工资': [10000, 20000, None, 25000]
})
# 检查缺失值
print(df_missing.isnull().sum()) # 统计每列的缺失值数量
# 处理缺失值的方法
# 1. 删除包含缺失值的行
df_drop = df_missing.dropna()
# 2. 填充缺失值
df_fill = df_missing.fillna({
'姓名': '未知',
'年龄': df_missing['年龄'].mean(), # 使用平均年龄填充
'城市': '未知',
'工资': df_missing['工资'].median() # 使用工资中位数填充
})2. 数据转换
数据转换是数据处理中的重要步骤:
python
# 将年龄转换为分类
df['年龄段'] = pd.cut(df['年龄'],
bins=[20, 30, 40, 50],
labels=['20-30岁', '30-40岁', '40-50岁'])
# 数值变换
df['工资_千元'] = df['工资'] / 1000
# 字符串操作
df['城市_省份'] = df['城市'] + '市'3. 数据聚合
聚合操作可以帮助我们了解数据的整体特征:
python
# 按城市分组计算平均工资
city_salary = df.groupby('城市')['工资'].mean()
print(city_salary)
# 多列聚合
summary = df.groupby('城市').agg({
'工资': ['mean', 'max', 'min'],
'年龄': ['mean', 'max', 'min']
})
print(summary)四、数据分析与可视化
pandas 与 matplotlib 和 seaborn结合,可以轻松实现数据可视化。
数据分析流程图:
1. 基本统计分析
python
# 描述性统计
print(df.describe())
# 相关性分析
print(df[['年龄', '工资']].corr())
# 唯一值计数
print(df['城市'].value_counts())2. 简单可视化
python
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 绘制柱状图
df.groupby('城市')['工资'].mean().plot(kind='bar', figsize=(10, 6))
plt.title('各城市平均工资')
plt.ylabel('平均工资(元)')
plt.xticks(rotation=0)
plt.show()
# 绘制散点图
plt.figure(figsize=(10, 6))
plt.scatter(df['年龄'], df['工资'])
plt.title('年龄与工资关系')
plt.xlabel('年龄')
plt.ylabel('工资(元)')
plt.grid(True)
plt.show()五、实战练习:销售数据分析
现在,让我们通过一个实际的例子来应用我们所学的知识。假设我们有一个名为sales_data.csv的销售数据文件,包含了商品的销售记录。
蓝奏云:https://www.lanzoum.com/icqEd2t4joti
密码:99ku

1. 读取CSV文件
python
# 读取CSV文件
sales_df = pd.read_csv('sales_data.csv')
# 查看前几行数据
print(sales_df.head())
# 查看数据信息
print(sales_df.info())假设我们的CSV文件包含以下列:
日期: 销售日期商品ID: 商品编号商品名称: 商品名称类别: 商品类别单价: 商品单价数量: 销售数量总金额: 单价 × 数量客户ID: 客户编号销售员: 销售员姓名
2. 数据清洗
python
# 检查缺失值
print(sales_df.isnull().sum())
# 处理缺失值
sales_df['单价'].fillna(sales_df['单价'].mean(), inplace=True)
sales_df['商品名称'].fillna('未知商品', inplace=True)
# 转换日期列为日期类型
sales_df['日期'] = pd.to_datetime(sales_df['日期'])
# 创建新的时间特征
sales_df['月份'] = sales_df['日期'].dt.month
sales_df['季度'] = sales_df['日期'].dt.quarter
sales_df['是否周末'] = sales_df['日期'].dt.dayofweek >= 53. 数据分析
让我们探索一些业务问题:
python
# 1. 各类别商品的销售总额
category_sales = sales_df.groupby('类别')['总金额'].sum().sort_values(ascending=False)
print("各类别商品销售总额:")
print(category_sales)
# 2. 月度销售趋势
monthly_sales = sales_df.groupby('月份')['总金额'].sum()
print("\n月度销售总额:")
print(monthly_sales)
# 3. 热销商品分析
top_products = sales_df.groupby('商品名称')['数量'].sum().sort_values(ascending=False).head(10)
print("\n销量前10的商品:")
print(top_products)
# 4. 销售员业绩分析
salesperson_performance = sales_df.groupby('销售员')['总金额'].sum().sort_values(ascending=False)
print("\n销售员业绩排名:")
print(salesperson_performance)
# 5. 周末与工作日销售对比
weekend_vs_weekday = sales_df.groupby('是否周末')['总金额'].sum()
print("\n周末与工作日销售对比:")
print(weekend_vs_weekday)4. 数据可视化
python
# 1. 类别销售总额柱状图
plt.figure(figsize=(12, 6))
category_sales.plot(kind='bar')
plt.title('各类别商品销售总额')
plt.xlabel('商品类别')
plt.ylabel('销售总额(元)')
plt.xticks(rotation=45)
plt.grid(axis='y')
plt.show()
# 2. 月度销售趋势折线图
plt.figure(figsize=(12, 6))
monthly_sales.plot(kind='line', marker='o')
plt.title('月度销售趋势')
plt.xlabel('月份')
plt.ylabel('销售总额(元)')
plt.grid(True)
plt.show()
# 3. 热销商品前10名
plt.figure(figsize=(14, 7))
top_products.plot(kind='barh')
plt.title('销量前10的商品')
plt.xlabel('销售数量')
plt.ylabel('商品名称')
plt.grid(axis='x')
plt.show()5. 高级分析:RFM客户分析
RFM分析是一种常用的客户价值分析模型,基于以下三个维度:
- Recency(最近购买时间):客户最近一次购买的时间
- Frequency(购买频率):客户购买的次数
- Monetary(购买金额):客户购买的金额
python
# 获取最大日期(数据集中的最后一天)
max_date = sales_df['日期'].max()
# 按客户ID分组计算RFM指标
rfm = sales_df.groupby('客户ID').agg({
'日期': lambda x: (max_date - x.max()).days, # 最近购买时间(天数)
'商品ID': 'count', # 购买频率(订单数)
'总金额': 'sum' # 购买金额
})
# 重命名列
rfm.columns = ['最近购买时间', '购买频率', '购买金额']
# 查看RFM分析结果
print(rfm.head())
# 对RFM指标进行分段
rfm['R_Score'] = pd.qcut(rfm['最近购买时间'], 5, labels=[5, 4, 3, 2, 1])
rfm['F_Score'] = pd.qcut(rfm['购买频率'], 5, labels=[1, 2, 3, 4, 5])
rfm['M_Score'] = pd.qcut(rfm['购买金额'], 5, labels=[1, 2, 3, 4, 5])
# 计算RFM总分
rfm['RFM_Score'] = rfm['R_Score'].astype(str) + rfm['F_Score'].astype(str) + rfm['M_Score'].astype(str)
# 识别高价值客户
high_value = rfm[rfm['RFM_Score'].str.startswith('5')]
print("\n高价值客户:")
print(high_value.head())6.完整代码
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 1. 读取CSV文件
print("1. 读取销售数据文件...")
sales_df = pd.read_csv('sales_data.csv')
# 查看前几行数据
print("\n数据预览:")
print(sales_df.head())
# 查看数据信息
print("\n数据基本信息:")
print(sales_df.info())
# 查看数据统计摘要
print("\n数据统计摘要:")
print(sales_df.describe())
# 2. 数据清洗
print("\n2. 进行数据清洗...")
# 检查缺失值
print("\n缺失值统计:")
print(sales_df.isnull().sum())
# 处理缺失值
# 对于缺失的单价,用同一商品的平均单价填充
print("\n处理缺失的单价...")
for product_id in sales_df['商品ID'].unique():
mask = (sales_df['商品ID'] == product_id) & (sales_df['单价'].isnull())
if mask.any():
avg_price = sales_df[sales_df['商品ID'] == product_id]['单价'].mean()
sales_df.loc[mask, '单价'] = avg_price
# 对于缺失的数量,用同一商品的中位数填充
print("处理缺失的数量...")
for product_id in sales_df['商品ID'].unique():
mask = (sales_df['商品ID'] == product_id) & (sales_df['数量'].isnull())
if mask.any():
median_quantity = sales_df[sales_df['商品ID'] == product_id]['数量'].median()
sales_df.loc[mask, '数量'] = median_quantity
# 重新计算总金额(针对缺失的总金额或者填充了单价/数量的记录)
print("更新总金额...")
mask = (sales_df['总金额'].isnull()) | (sales_df['单价'].isnull().shift(fill_value=False)) | (sales_df['数量'].isnull().shift(fill_value=False))
sales_df.loc[mask, '总金额'] = sales_df.loc[mask, '单价'] * sales_df.loc[mask, '数量']
# 转换日期列为日期类型
print("转换日期格式...")
sales_df['日期'] = pd.to_datetime(sales_df['日期'])
# 创建新的时间特征
print("创建时间特征...")
sales_df['月份'] = sales_df['日期'].dt.month
sales_df['季度'] = sales_df['日期'].dt.quarter
sales_df['是否周末'] = sales_df['日期'].dt.dayofweek >= 5 # 5和6代表周六和周日
# 查看清洗后的数据
print("\n清洗后的数据预览:")
print(sales_df.head())
print("\n清洗后的缺失值统计:")
print(sales_df.isnull().sum())
# 3. 数据分析
print("\n3. 进行数据分析...")
# 1. 各类别商品的销售总额
print("\n各类别商品销售总额:")
category_sales = sales_df.groupby('类别')['总金额'].sum().sort_values(ascending=False)
print(category_sales)
# 2. 月度销售趋势
print("\n月度销售总额:")
monthly_sales = sales_df.groupby('月份')['总金额'].sum()
print(monthly_sales)
# 3. 热销商品分析
print("\n销量前10的商品:")
top_products = sales_df.groupby('商品名称')['数量'].sum().sort_values(ascending=False).head(10)
print(top_products)
# 4. 销售员业绩分析
print("\n销售员业绩排名:")
salesperson_performance = sales_df.groupby('销售员')['总金额'].sum().sort_values(ascending=False)
print(salesperson_performance)
# 5. 周末与工作日销售对比
print("\n周末与工作日销售对比:")
weekend_vs_weekday = sales_df.groupby('是否周末')['总金额'].sum()
print(weekend_vs_weekday)
# 6. 客户消费分析
print("\n客户消费排名:")
customer_spending = sales_df.groupby('客户ID')['总金额'].sum().sort_values(ascending=False)
print(customer_spending)
# 7. 季度销售趋势
print("\n季度销售总额:")
quarterly_sales = sales_df.groupby('季度')['总金额'].sum()
print(quarterly_sales)
# 8. 商品均价分析
print("\n各类别商品均价:")
category_avg_price = sales_df.groupby('类别')['单价'].mean().sort_values(ascending=False)
print(category_avg_price)
# 4. 数据可视化
print("\n4. 创建数据可视化...")
# 设置图表风格
sns.set(style="whitegrid")
# 1. 类别销售总额柱状图
plt.figure(figsize=(12, 6))
category_sales.plot(kind='bar', color='skyblue')
plt.title('各类别商品销售总额', fontsize=14)
plt.xlabel('商品类别', fontsize=12)
plt.ylabel('销售总额(元)', fontsize=12)
plt.xticks(rotation=45)
plt.grid(axis='y', linestyle='--', alpha=0.7)
for i, v in enumerate(category_sales):
plt.text(i, v + 0.1, f'{v:.0f}', ha='center')
plt.tight_layout()
plt.savefig('category_sales.png')
plt.close()
print("已保存图表: category_sales.png")
# 2. 月度销售趋势折线图
plt.figure(figsize=(12, 6))
monthly_sales.plot(kind='line', marker='o', color='#FF7F0E', linewidth=2)
plt.title('月度销售趋势', fontsize=14)
plt.xlabel('月份', fontsize=12)
plt.ylabel('销售总额(元)', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.xticks(range(1, 13)) # 显示1-12月
for i, v in enumerate(monthly_sales):
plt.text(monthly_sales.index[i], v + 0.1, f'{v:.0f}', ha='center')
plt.tight_layout()
plt.savefig('monthly_sales.png')
plt.close()
print("已保存图表: monthly_sales.png")
# 3. 热销商品前10名
plt.figure(figsize=(14, 8))
ax = top_products.plot(kind='barh', color='#2CA02C')
plt.title('销量前10的商品', fontsize=14)
plt.xlabel('销售数量', fontsize=12)
plt.ylabel('商品名称', fontsize=12)
plt.grid(axis='x', linestyle='--', alpha=0.7)
# 在条形末端添加数值标签
for i, v in enumerate(top_products):
plt.text(v + 0.5, i, f'{v:.0f}', va='center')
plt.tight_layout()
plt.savefig('top_products.png')
plt.close()
print("已保存图表: top_products.png")
# 4. 销售员业绩饼图
plt.figure(figsize=(10, 8))
plt.pie(salesperson_performance, labels=salesperson_performance.index, autopct='%1.1f%%',
startangle=90, shadow=True, explode=[0.05]*len(salesperson_performance))
plt.title('销售员业绩占比', fontsize=14)
plt.axis('equal') # 保证饼图是圆的
plt.tight_layout()
plt.savefig('salesperson_performance.png')
plt.close()
print("已保存图表: salesperson_performance.png")
# 5. 周末与工作日销售对比条形图
plt.figure(figsize=(8, 6))
colors = ['#D62728' if x else '#1F77B4' for x in weekend_vs_weekday.index]
weekend_vs_weekday.plot(kind='bar', color=colors)
plt.title('周末与工作日销售对比', fontsize=14)
plt.xlabel('是否周末', fontsize=12)
plt.ylabel('销售总额(元)', fontsize=12)
plt.xticks(ticks=[0, 1], labels=['工作日', '周末'], rotation=0)
plt.grid(axis='y', linestyle='--', alpha=0.7)
for i, v in enumerate(weekend_vs_weekday):
plt.text(i, v + 0.1, f'{v:.0f}', ha='center')
plt.tight_layout()
plt.savefig('weekend_vs_weekday.png')
plt.close()
print("已保存图表: weekend_vs_weekday.png")
# 6. 季度销售趋势
plt.figure(figsize=(10, 6))
quarterly_sales.plot(kind='bar', color=['#1F77B4', '#FF7F0E', '#2CA02C', '#D62728'])
plt.title('季度销售趋势', fontsize=14)
plt.xlabel('季度', fontsize=12)
plt.ylabel('销售总额(元)', fontsize=12)
plt.xticks(rotation=0)
plt.grid(axis='y', linestyle='--', alpha=0.7)
for i, v in enumerate(quarterly_sales):
plt.text(i, v + 0.1, f'{v:.0f}', ha='center')
plt.tight_layout()
plt.savefig('quarterly_sales.png')
plt.close()
print("已保存图表: quarterly_sales.png")
# 5. 高级分析:RFM客户分析
print("\n5. 进行RFM客户分析...")
# 获取最大日期(数据集中的最后一天)
max_date = sales_df['日期'].max()
# 按客户ID分组计算RFM指标
rfm = sales_df.groupby('客户ID').agg({
'日期': lambda x: (max_date - x.max()).days, # 最近购买时间(天数)
'商品ID': 'count', # 购买频率(订单数)
'总金额': 'sum' # 购买金额
})
# 重命名列
rfm.columns = ['最近购买时间', '购买频率', '购买金额']
# 查看RFM分析结果
print("\nRFM分析结果:")
print(rfm.head())
# 对RFM指标进行分段
rfm['R分数'] = pd.qcut(rfm['最近购买时间'], 5, labels=[5, 4, 3, 2, 1])
rfm['F分数'] = pd.qcut(rfm['购买频率'].rank(method='first'), 5, labels=[1, 2, 3, 4, 5])
rfm['M分数'] = pd.qcut(rfm['购买金额'].rank(method='first'), 5, labels=[1, 2, 3, 4, 5])
# 计算RFM总分
rfm['RFM_Score'] = rfm['R分数'].astype(str) + rfm['F分数'].astype(str) + rfm['M分数'].astype(str)
# 识别客户类型
print("\n客户分类:")
# 定义客户类型
customer_segments = {
r'^5': '近期活跃客户',
r'^[45][45]': '高价值客户',
r'^[45][1-3]': '高潜力客户',
r'^3': '中等价值客户',
r'^[12][45]': '流失高价值客户',
r'^[12]': '流失低价值客户'
}
# 标记客户类型
for pattern, segment in customer_segments.items():
rfm[segment] = rfm['RFM_Score'].str.contains(pattern).astype(int)
# 统计各类型客户数量
segment_counts = rfm.iloc[:, 7:].sum().sort_values(ascending=False)
print(segment_counts)
# 可视化客户分类
plt.figure(figsize=(10, 6))
segment_counts.plot(kind='bar', color='purple')
plt.title('客户类型分布', fontsize=14)
plt.xlabel('客户类型', fontsize=12)
plt.ylabel('客户数量', fontsize=12)
plt.xticks(rotation=45)
plt.grid(axis='y', linestyle='--', alpha=0.7)
for i, v in enumerate(segment_counts):
plt.text(i, v + 0.05, str(v), ha='center')
plt.tight_layout()
plt.savefig('customer_segments.png')
plt.close()
print("已保存图表: customer_segments.png")
# 输出高价值客户
high_value = rfm[rfm['高价值客户'] == 1].sort_values(by='购买金额', ascending=False)
print("\n高价值客户名单:")
print(high_value[['最近购买时间', '购买频率', '购买金额', 'RFM_Score']])
print("\n分析完成! 所有结果都已保存.")运行结果如图:

在这段销售数据分析代码中,一共创建了7个可视化图表。这些图表系统地展示了销售数据的不同方面,让数据分析结果更加直观和易于理解。
详细图表清单
让我们逐一看看这些图表及其用途:
1.类别销售总额柱状图 (category_sales.png)
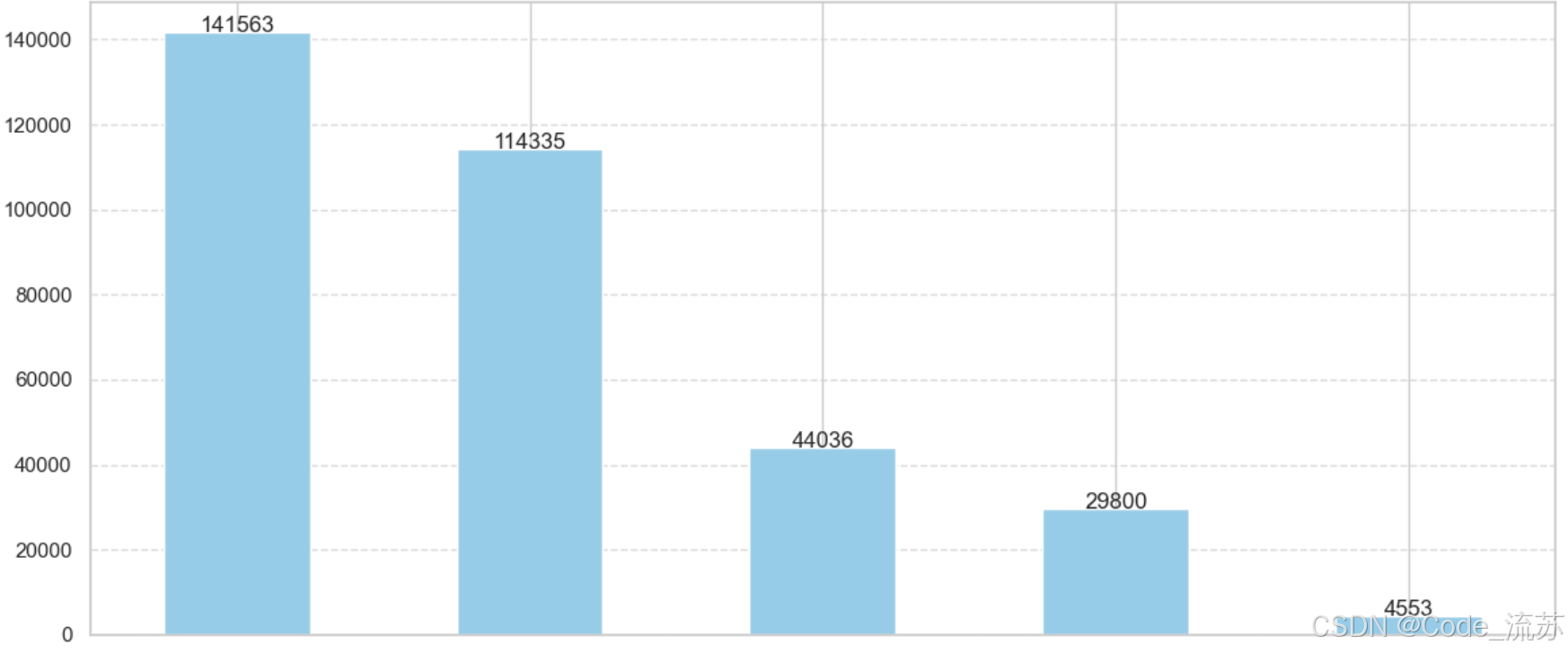
- 展示不同商品类别的总销售额
- 使用了蓝色柱状图并包含数值标签
2.月度销售趋势折线图 (monthly_sales.png)
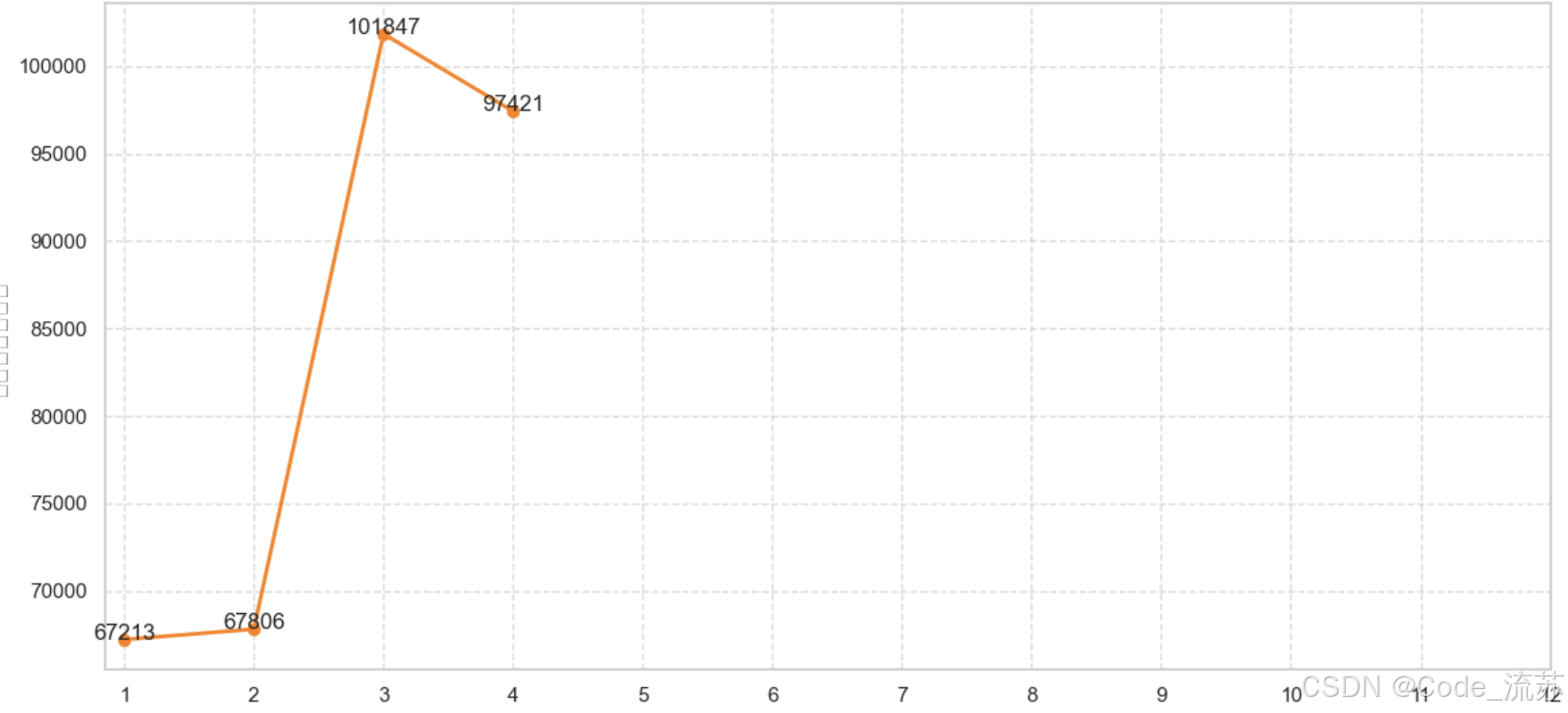
- 显示各月份销售额的变化趋势
- 使用了橙色线条和圆形标记点
3.热销商品前10名 (top_products.png)
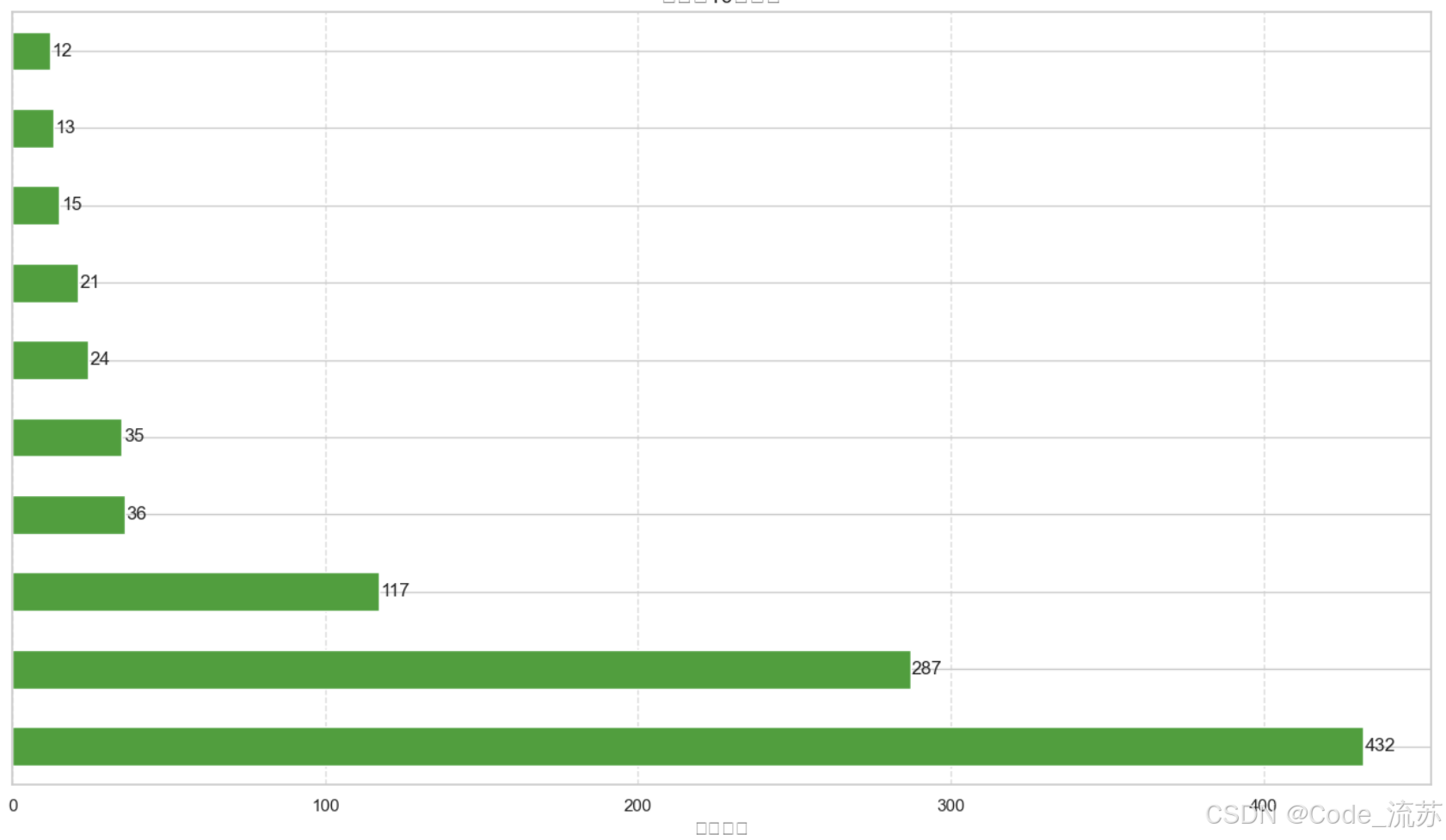
- 用水平条形图展示销量最高的10种商品
- 使用了绿色条形并在条形末端添加了数值标签
4.销售员业绩饼图 (salesperson_performance.png)
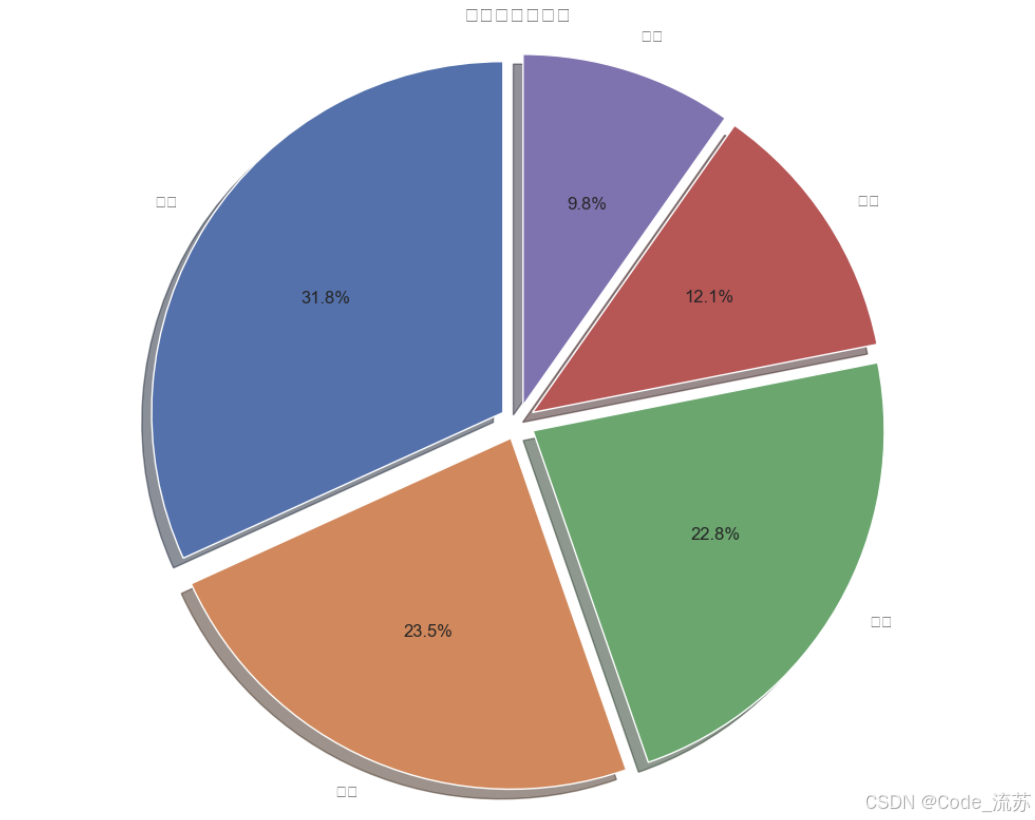
- 展示各销售员的销售额占比
- 使用了带阴影的饼图,各部分略微分离
5.周末与工作日销售对比条形图 (weekend_vs_weekday.png)
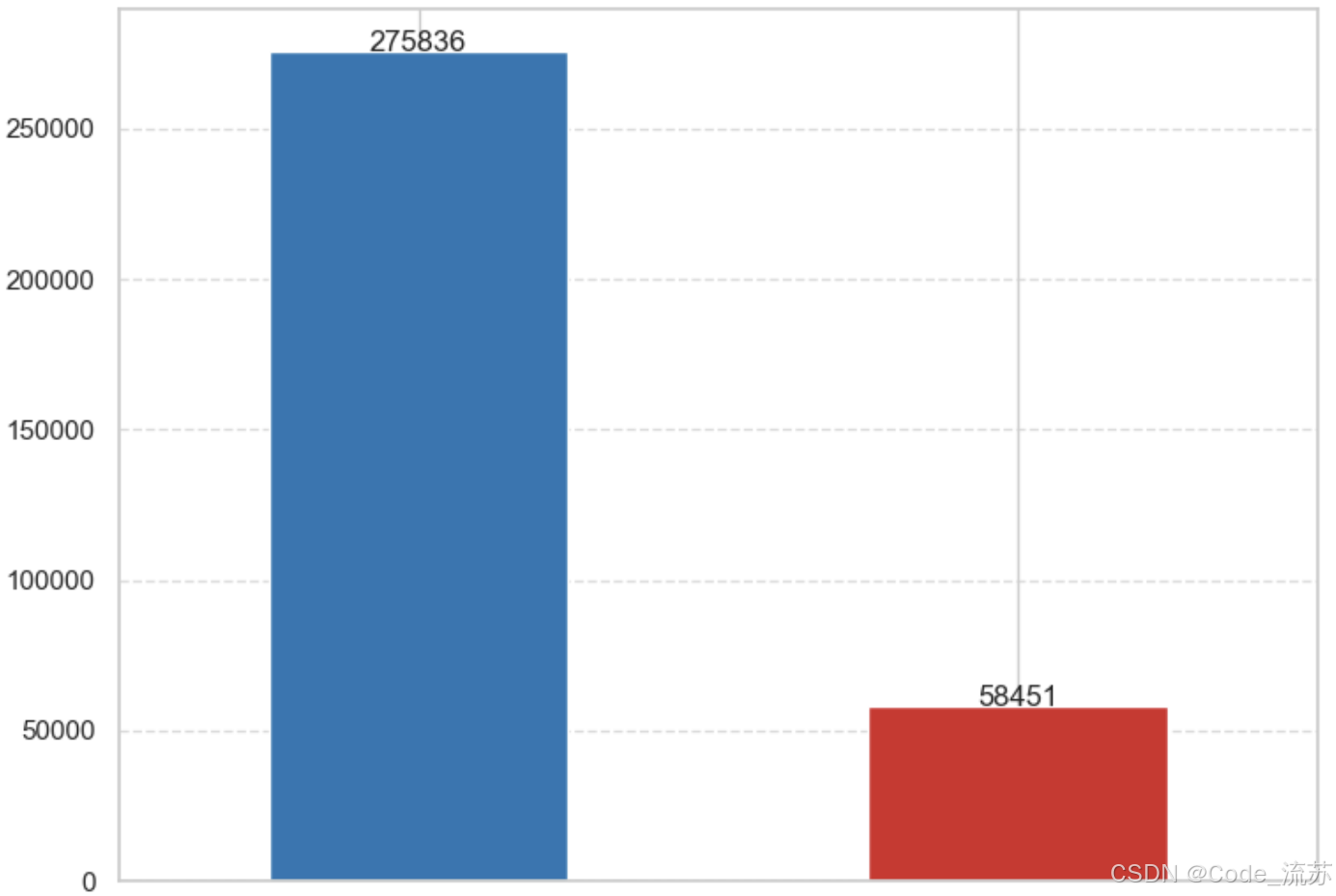
- 比较工作日和周末的销售总额
- 使用了不同颜色区分(蓝色表示工作日,红色表示周末)
6.季度销售趋势 (quarterly_sales.png)
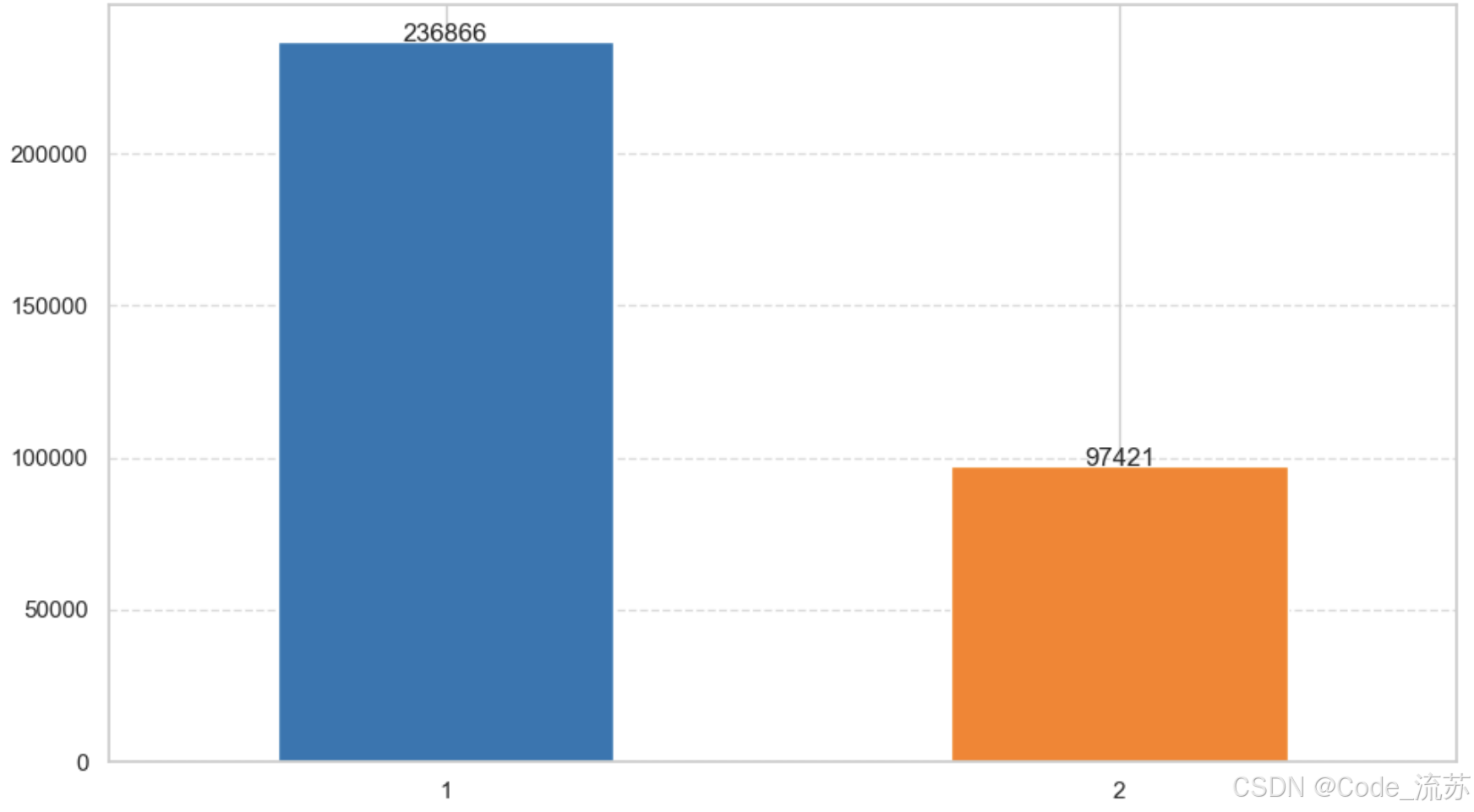
- 展示各季度的销售总额
- 使用了彩色条形图,每个季度用不同颜色表示
7.客户类型分布 (customer_segments.png)
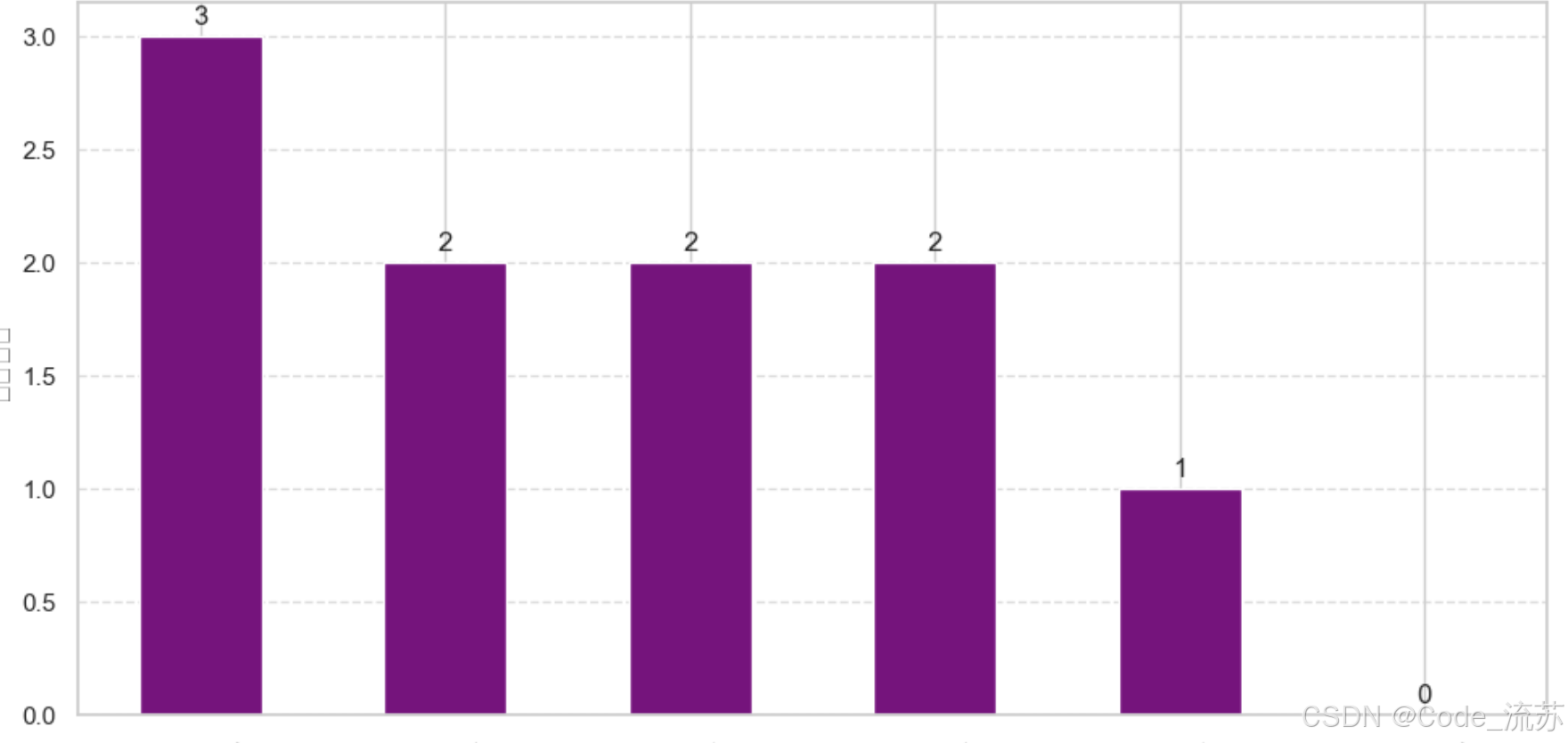
- 在RFM分析部分创建
- 展示不同类型客户的数量分布
- 使用了紫色条形图
这些可视化图表共同构成了一个全面的销售数据分析报告,涵盖了产品、时间、人员和客户多个维度的分析视角,帮助业务人员快速理解数据中的重要模式和趋势。
六、总结与进阶学习路径
在本文中,我们学习了pandas 的基础知识,包括数据结构、基本操作、数据清洗和分析方法。我们还通过销售数据分析的实例,将所学知识应用到实际问题中。
1. 今日要点
pandas是Python数据分析的核心库,提供了强大的数据处理功能DataFrame和Series是pandas的两个核心数据结构- 数据清洗是数据分析的关键步骤,包括处理缺失值、异常值和数据转换
- 数据分析涉及数据探索、统计分析和可视化
- 通过实际案例(销售数据分析)学习数据分析的流程和方法
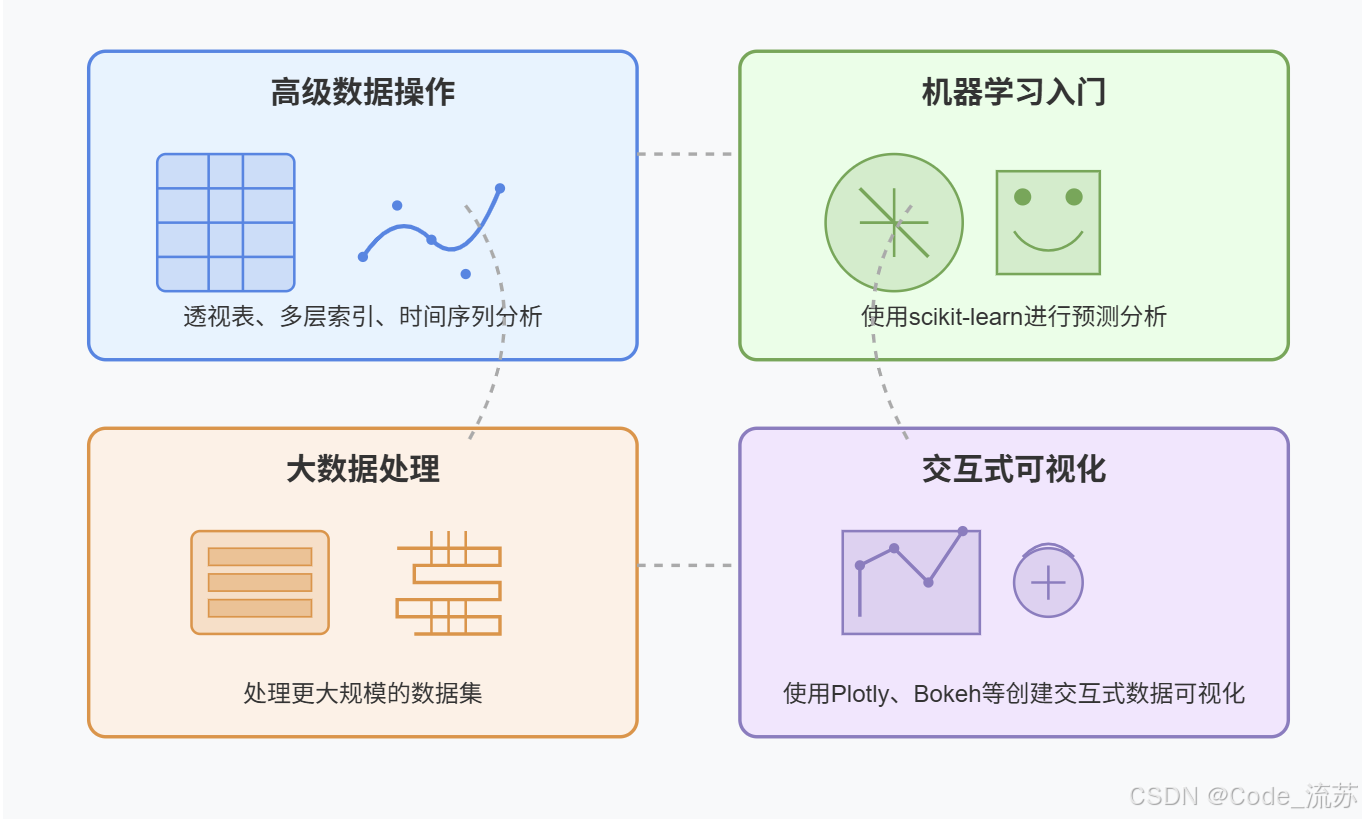
2. 进阶学习方向
随着对pandas的深入了解,你可以继续学习一下几个方向的内容:
3. 实践建议
数据分析是一项实践性很强的技能,建议:
- 寻找真实数据集进行练习(如 Kaggle平台 :https://www.kaggle.com/)
- 尝试解决实际业务问题
- 创建自己的分析项目并分享结果
- 学习他人的分析案例和方法
七、练习题
- 编写代码读取一个CSV文件,并显示其基本信息和统计摘要。
- 使用pandas处理缺失值,尝试不同的填充方法。
- 对数据进行分组聚合,计算不同类别的统计量。
- 创建一个简单的数据可视化,展示数据的某个特征。
- 尝试完成一个简单的销售数据分析项目,包括数据清洗、分析和可视化。
谢谢大家阅读《Python星球日记》第20天的内容!
在下一篇文章中,我们将对前20天所学内容进行总结,为基础阶段做一次收尾。如果有任何问题,欢迎在评论区留言!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!