Key-Value类型:
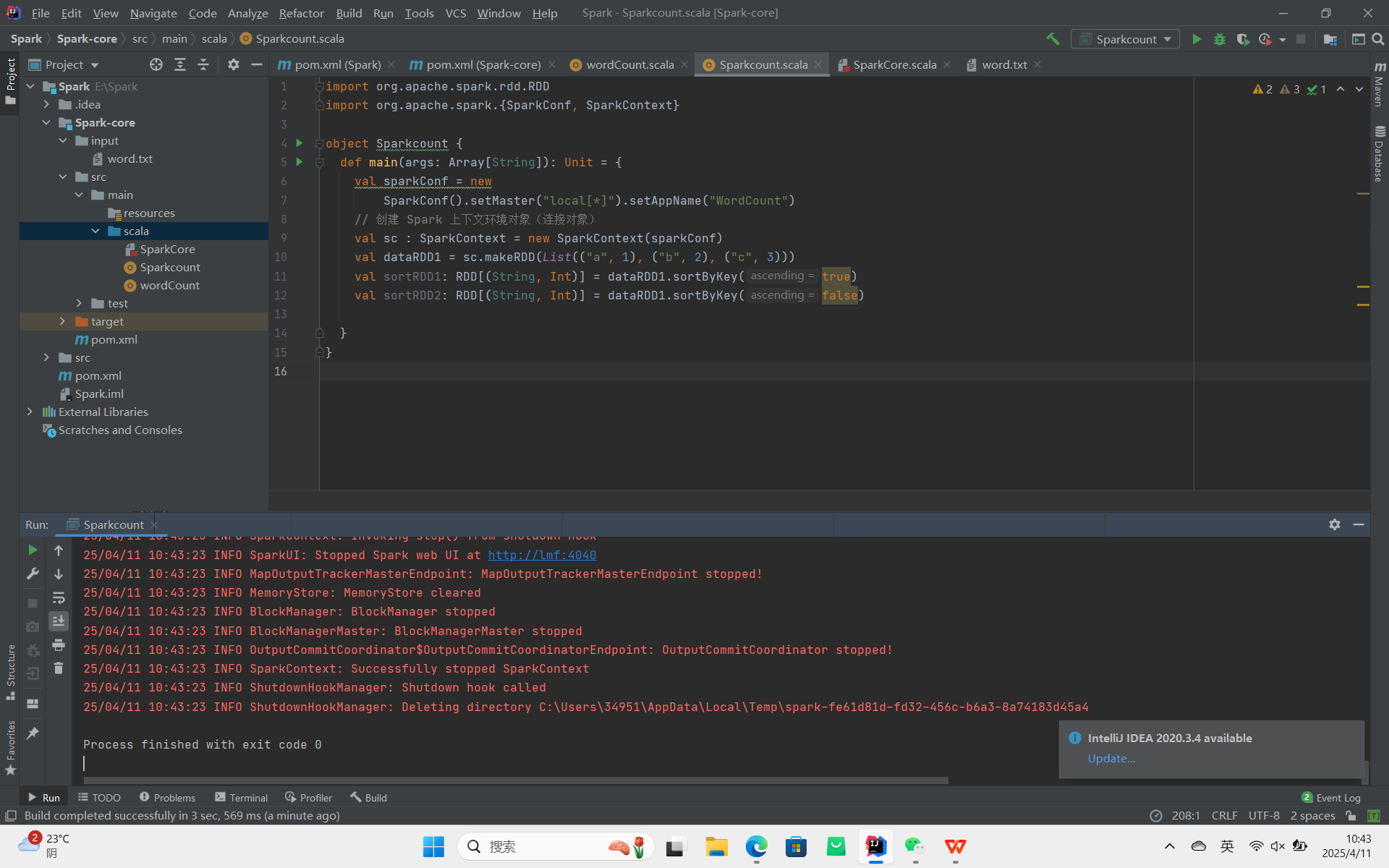
sortByKey:根据键值对中的键进行排序,支持开和降序。
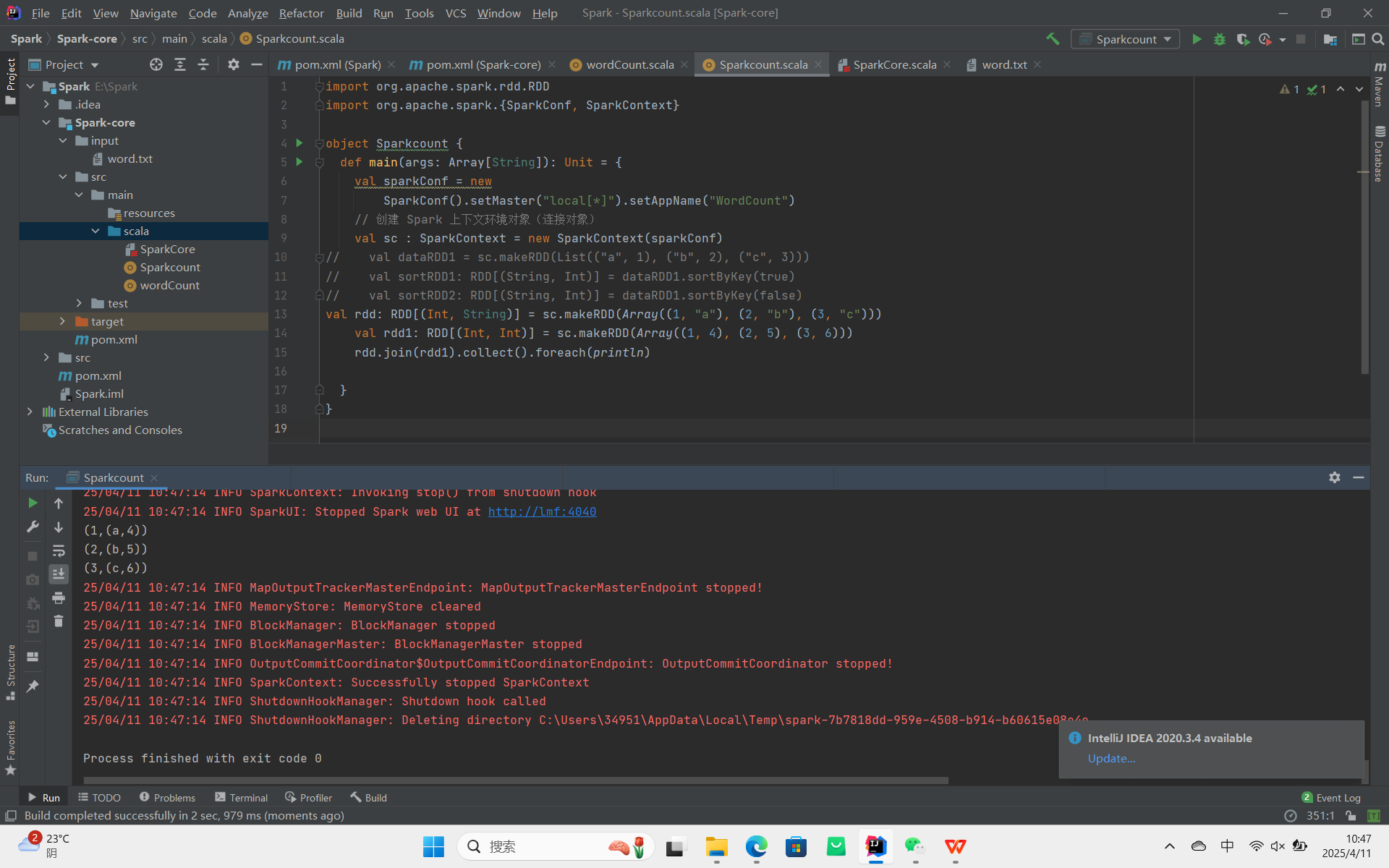
join:返回两个 RDD 中相同键对应的所有元素,结果以键开头,值为嵌套形式。
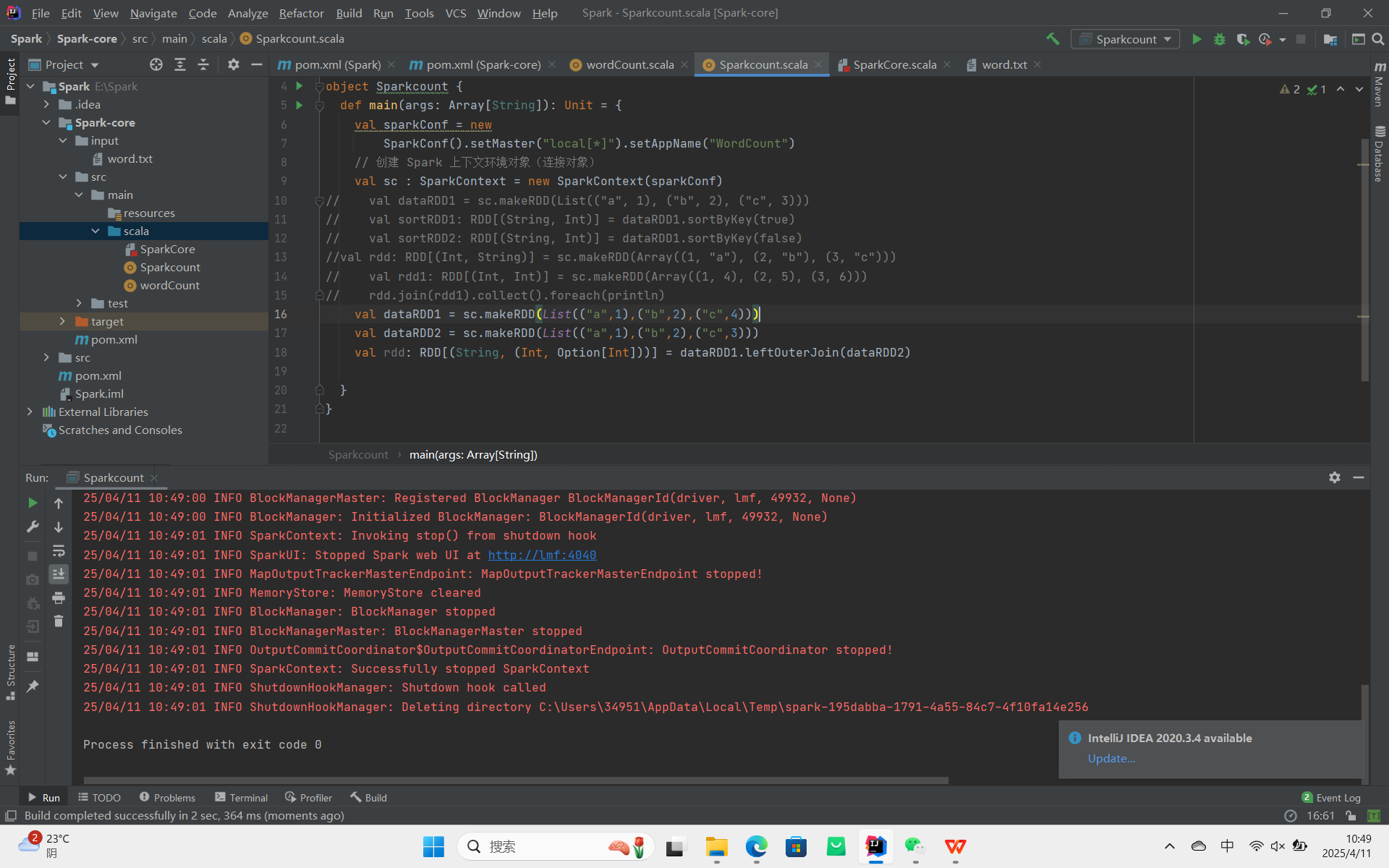
leftOuterJoin:类似于 SQL 语句的左外连接,,以源RDD 为主。
Right outer Join:类似于 SQL 中的右外连接,以参数 RDD 为主。
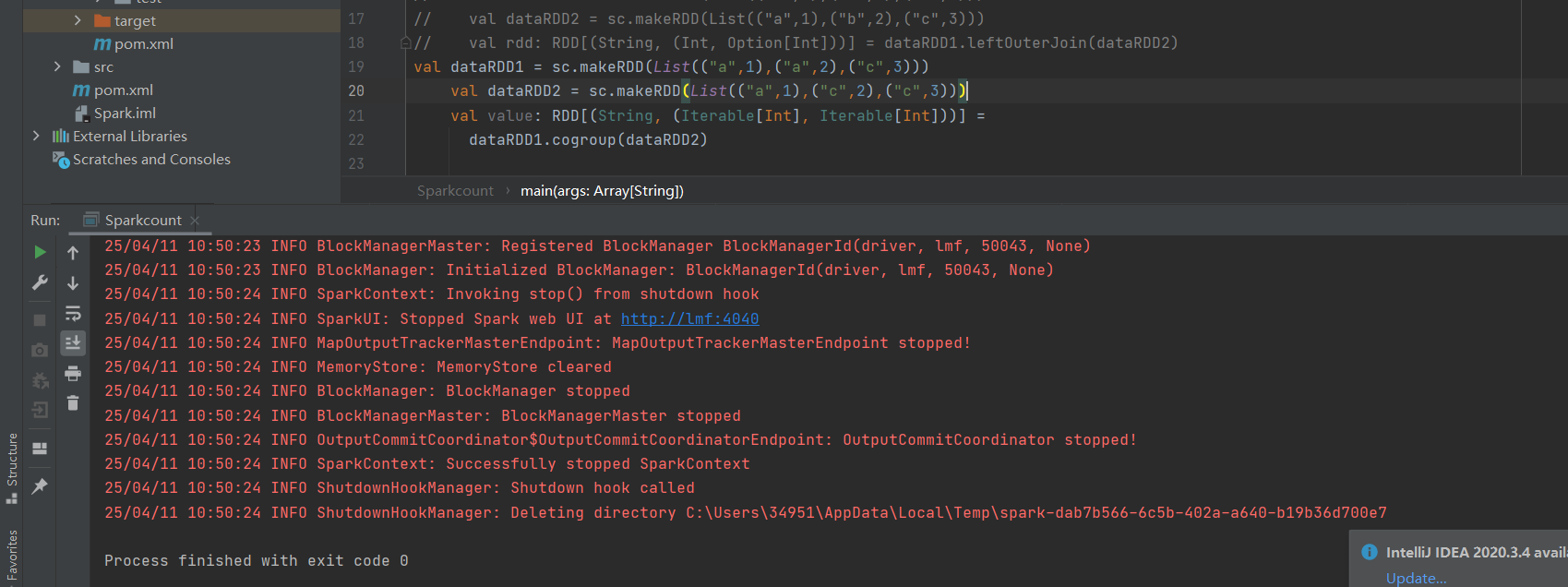
cogroup:将相同键的值组合在一起,返回可变集合类型。
累加器
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
RDD行动算子:
行动算子就是会触发action的算子,触发action的含义就是真正的计算数据。
reduce:聚合 RDD 中所有元素,返回一个具体值。
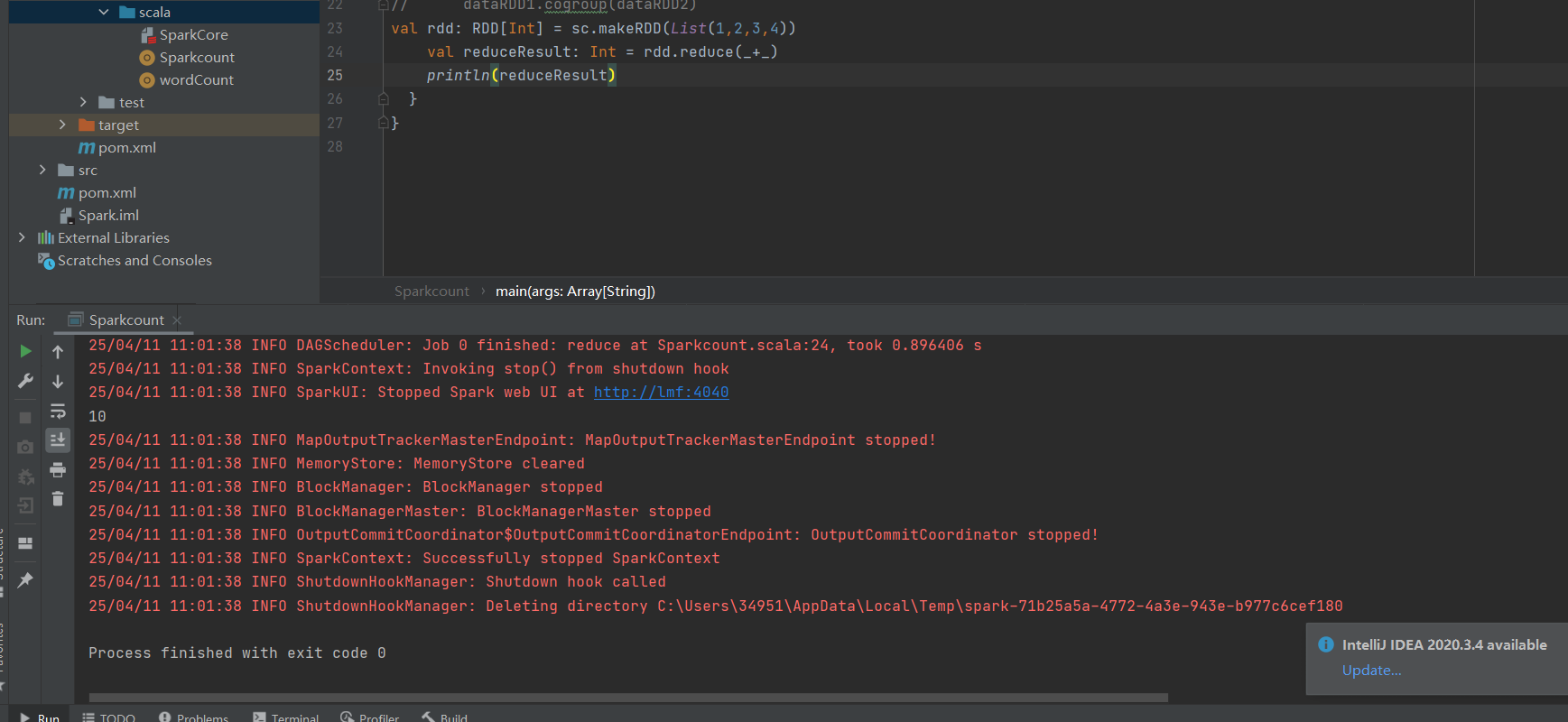
collect:在驱动程序中,以数组 Array 的形式返回数据集的所有元素。
foreach:分布式遍历 RDD 中的每一个元素,调用指定函数。
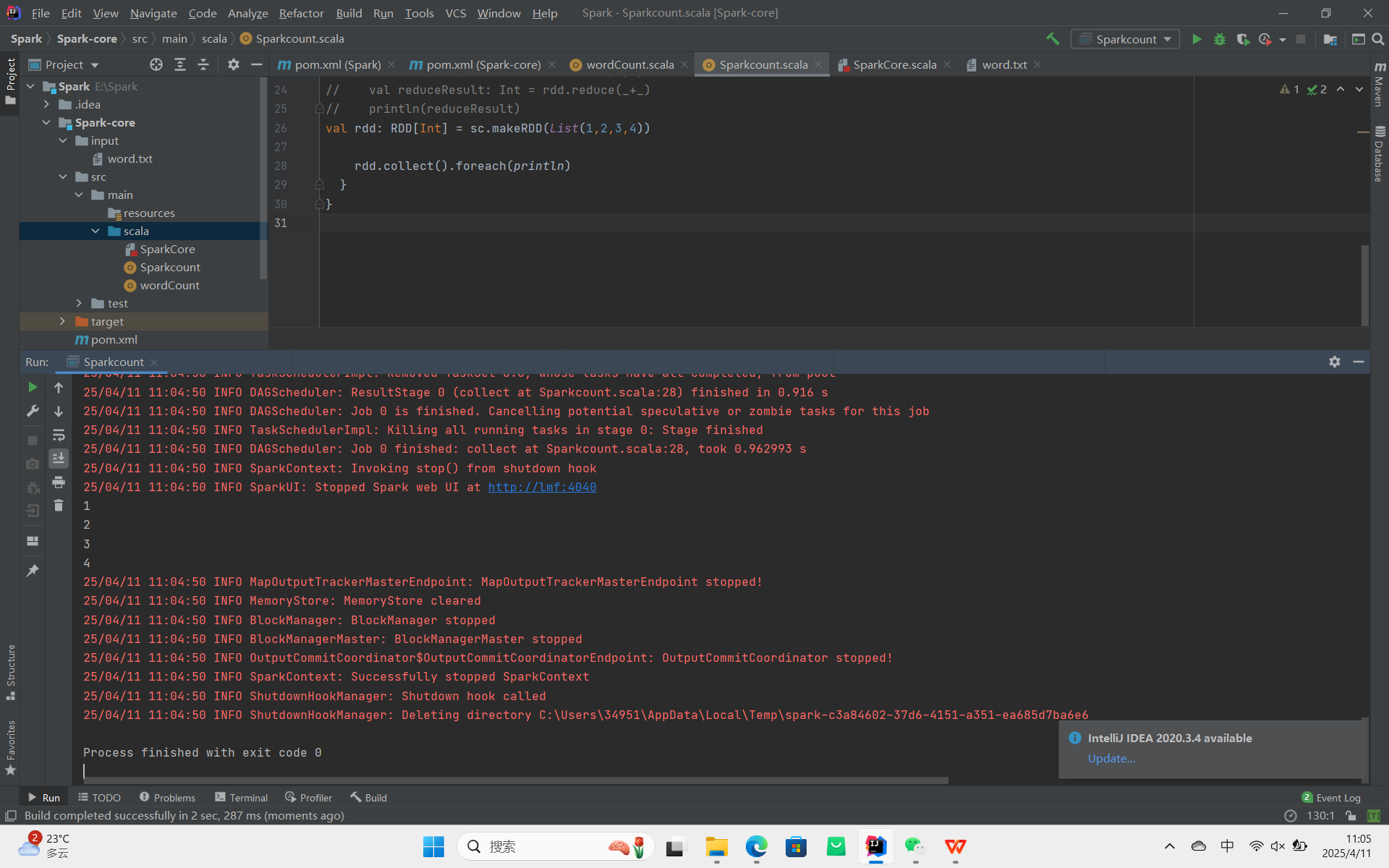
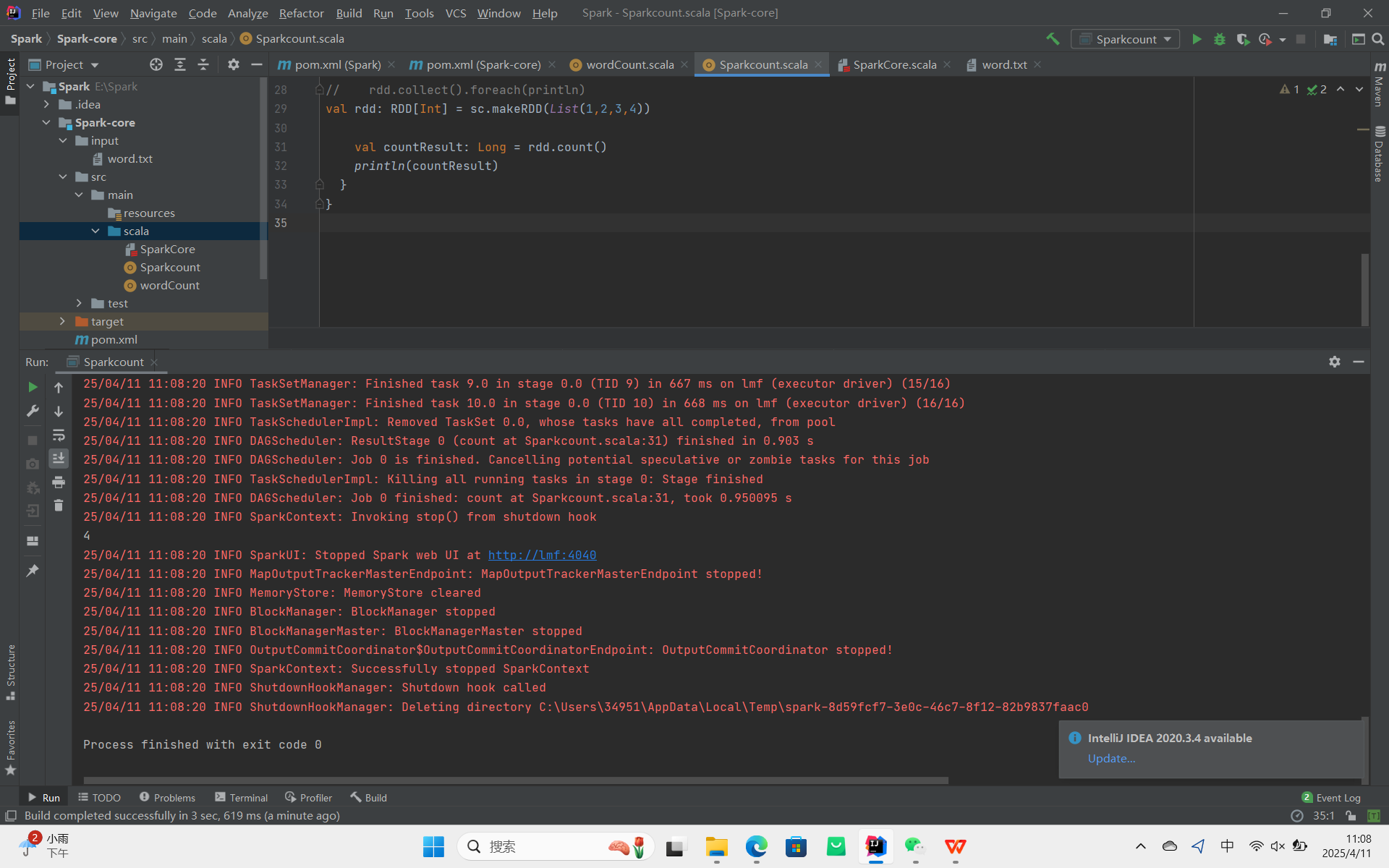
count:返回 RDD 中元素的个数。
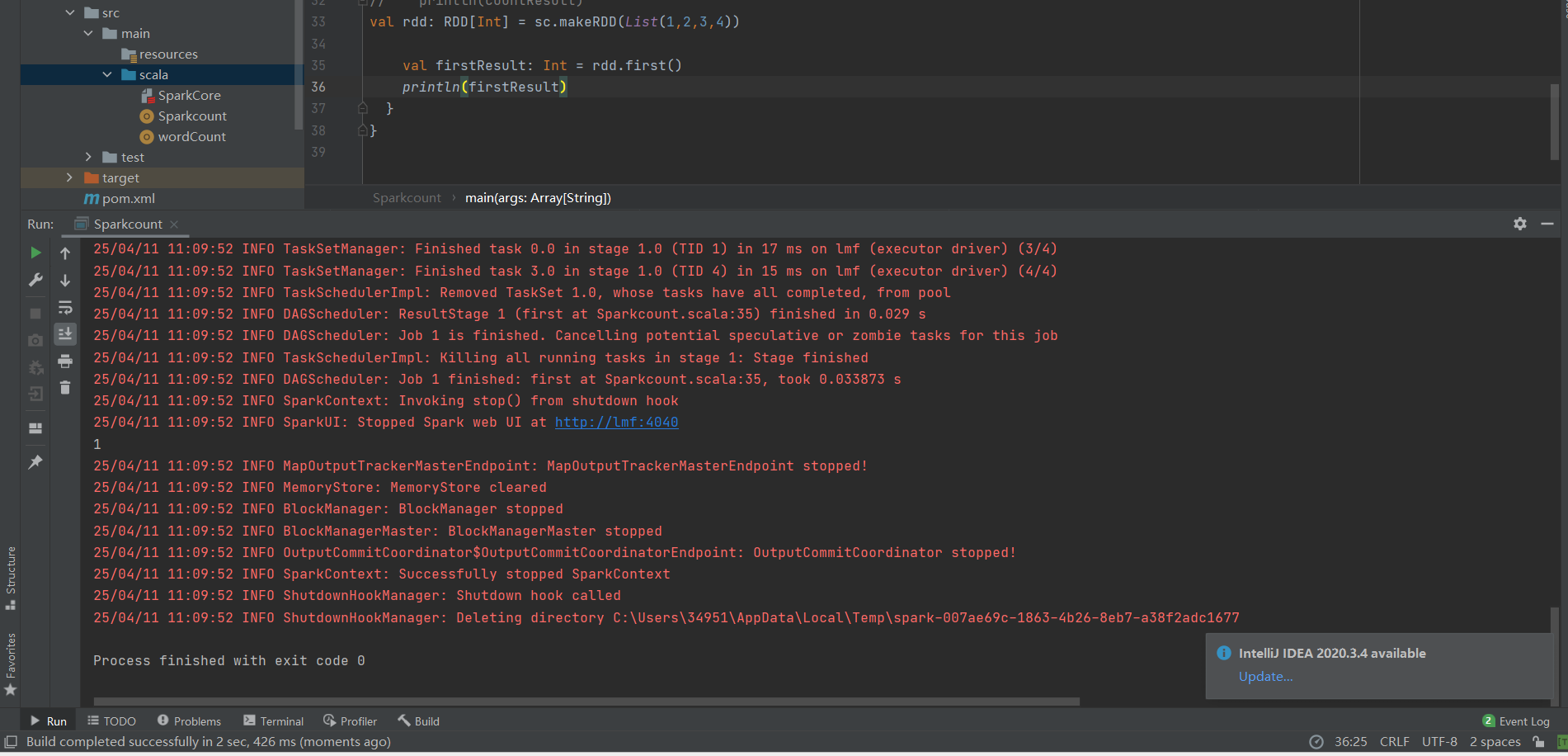
first:返回 RDD 中的第一个元素。
take:返回一个由 RDD 的前 n 个元素组成的数组。

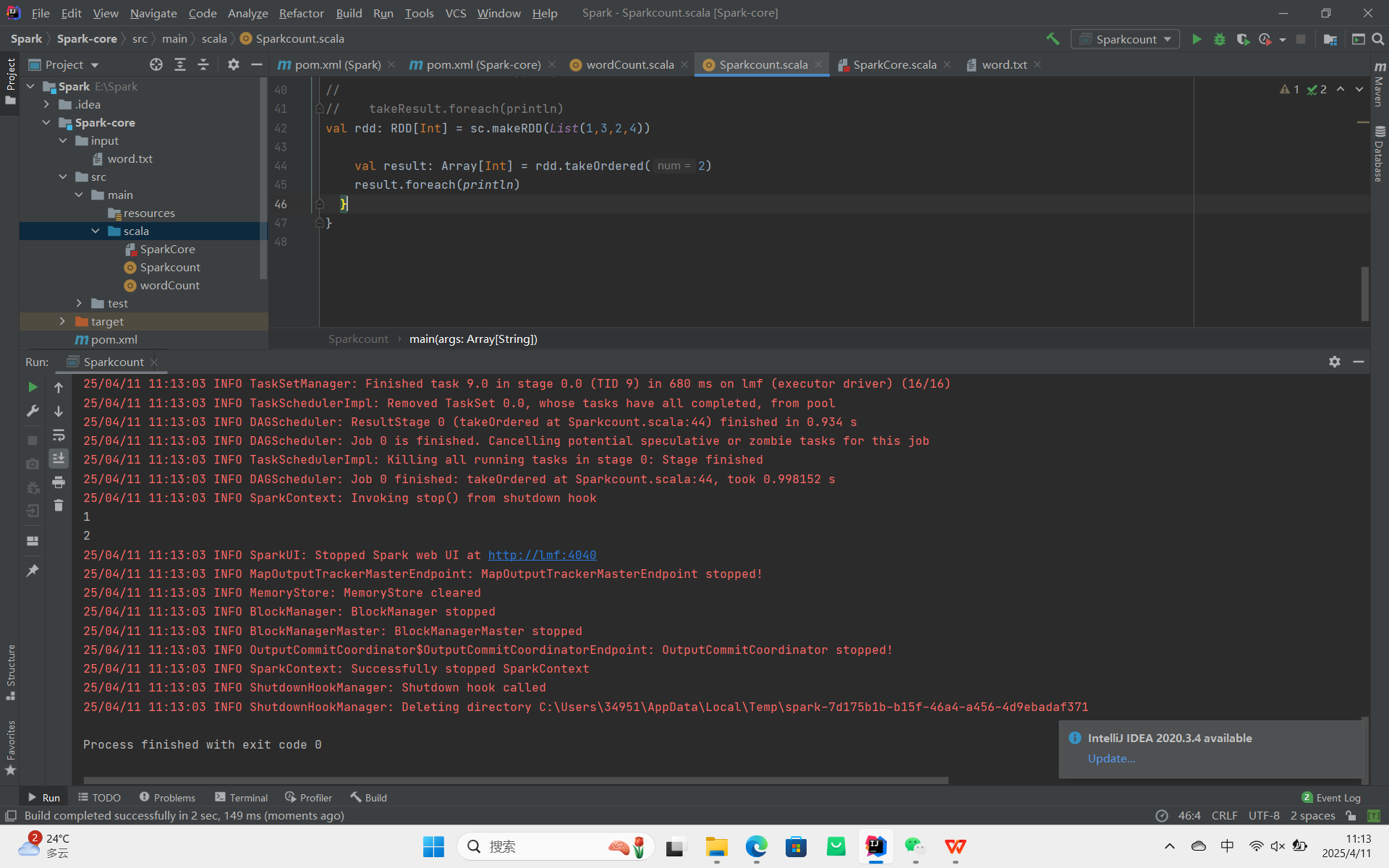
takeOrdered:返回该 RDD 排序后的前 n 个元素组成的数组。
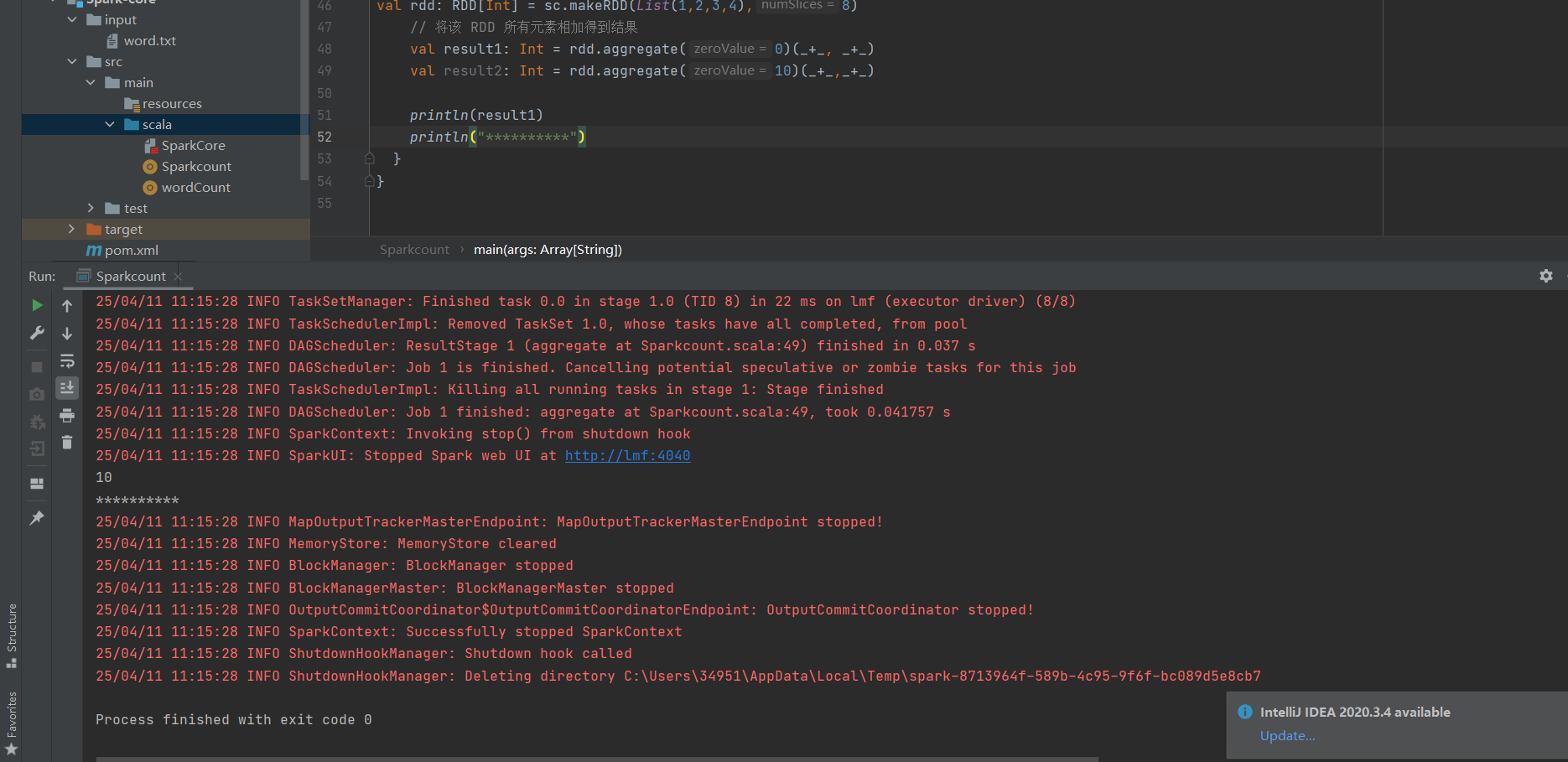
aggregate:分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合。
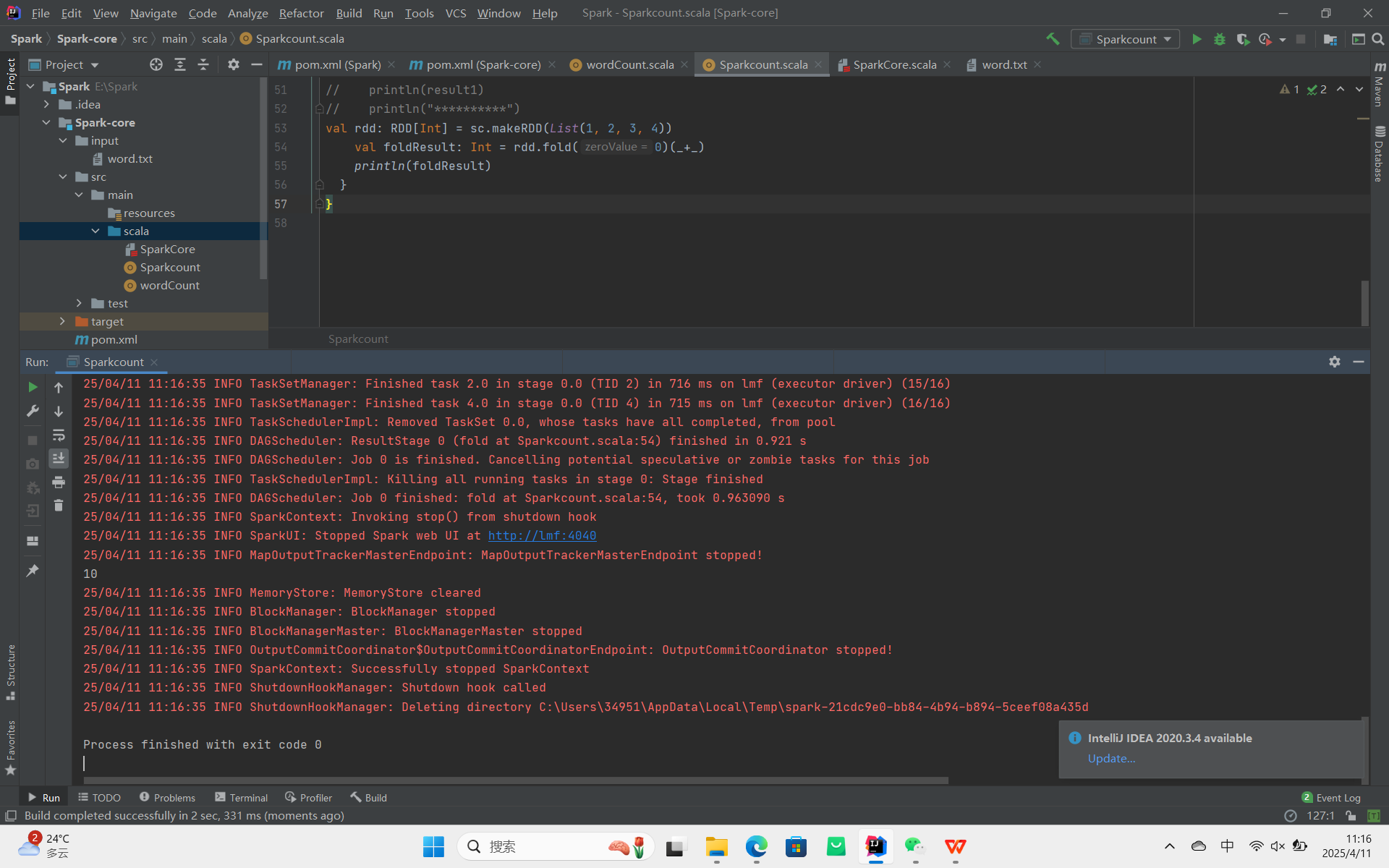
fold:折叠操作,aggregate 的简化版操作。
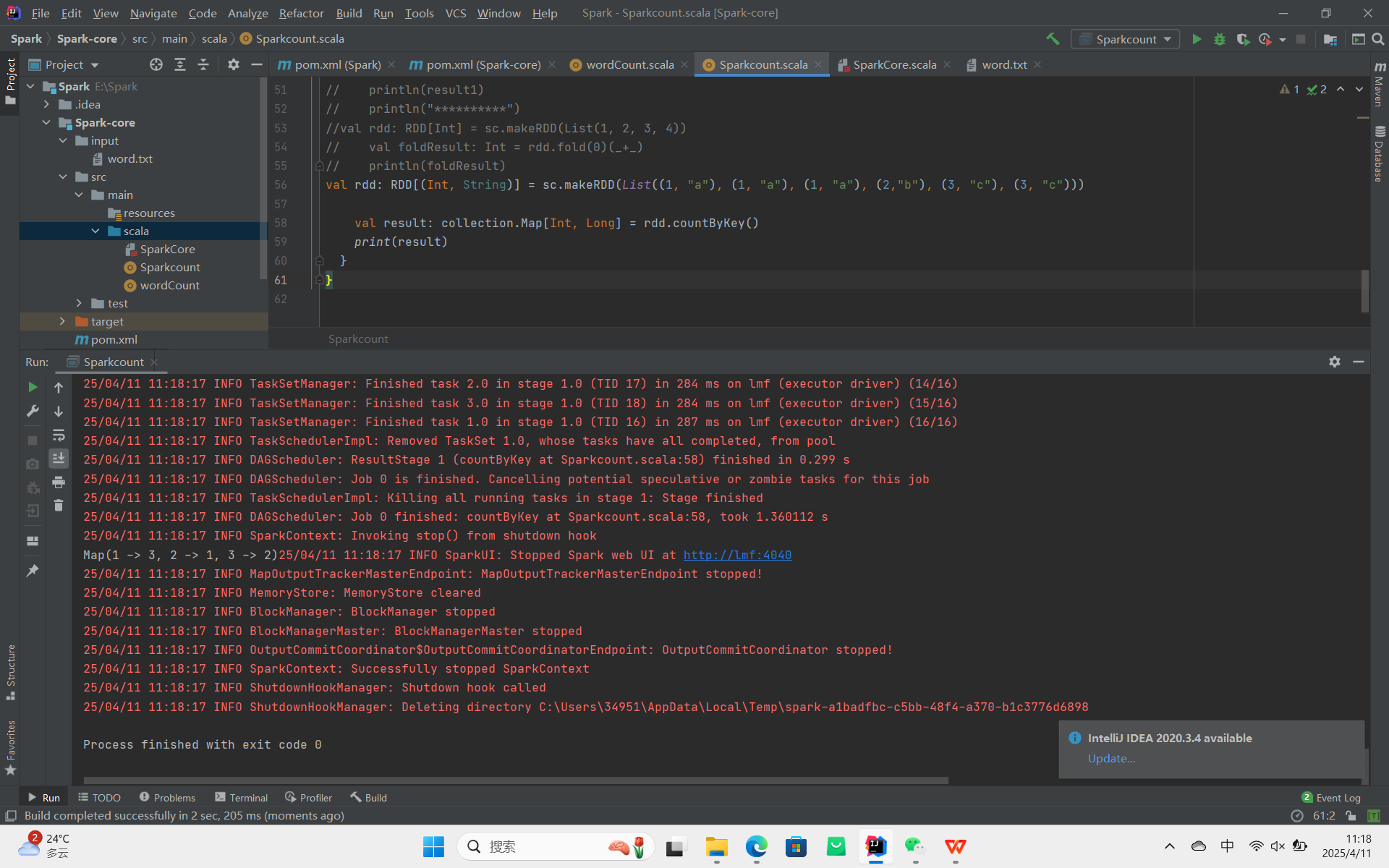
countByKey:统计每种 key 的个数。
save 相关算子:将数据保存到不同格式的文件中。
分区计算
分区内计算:在每个分区内进行计算。
分区间计算:在所有分区之间进行计算。
指定分区:可以手动指定分区数量,影响计算结果。