使用私有化DeepSeek
作为白嫖党,通过部署本地的DeepSeek提供服务,既可以训练模型,也可以节省开支,并且因为有些资料是不适合互联网上传的,所以使用私有化比较合适。 本次使用基于开源跨平台大模型工具Ollama,提供多种开箱即用的预训练模型,选取DeepSeek-R1,需要去ollama官方网站ollama.com/download 选择适合的系统下载即可,之后傻瓜式安装。

点击左上角的models选择合适的模型ollama.com/library/dee... ,在控制台输入
shell
ollama run deepseek-r1:32b等待安装完成即可。
需要注意的是,让ollama可以访问需要设置环境变量,设置完成后,重启ollama即可。
shell
launchctl setenv OLLAMA_HOST "0.0.0.0"
launchctl setenv OLLAMA_ORIGINS "*"这样就可以通过默认端口访问到了,http://localhost:11434, 如果需要在RAG_Flow等成熟的框架中配置,则需要在控制台中输入ifconfig,查找en0对应的inet,即为IP地址。
langchain
官网地址:python.langchain.com/docs/introd... 主要用于开发由大语言模型驱动的应用程序和框架,作为中介,可以使LLM在更广泛的应用环境操作和响应,扩大应用范围和有效性。也可以理解为提升LLMs的功能框架。
核心组件:
Components:为LLMs提供接口封装、模版提示、信息检索索引
Chains:将不同的组件组合起来解决特定问题,如多文本处理
Agents: LLMs与外部环境互动,通过API请求执行操作
开发核心
模型:各种LLMs
PromptTemplate:问答模板,支持用户动态输入模板中
Agents:语言模型与外部API交互,比如Tavily等,类似于支持联网查询
Chains:多个组件组合,解决特定的任务,构建完整语言模型应用
Embeddings嵌入和vectorStore向量存储:数据表示和检索的手段,为模型提供必要的语言理解基础。
Indexs: 索引,帮助从模型中提取相关信息
底层原理
将相关的相关的知识,通过加载、分割、嵌入到向量数据库、实现增强,并在用户提出问题的时候,为LLMs提供上下文和输入数据,帮助模型生成增强信息。
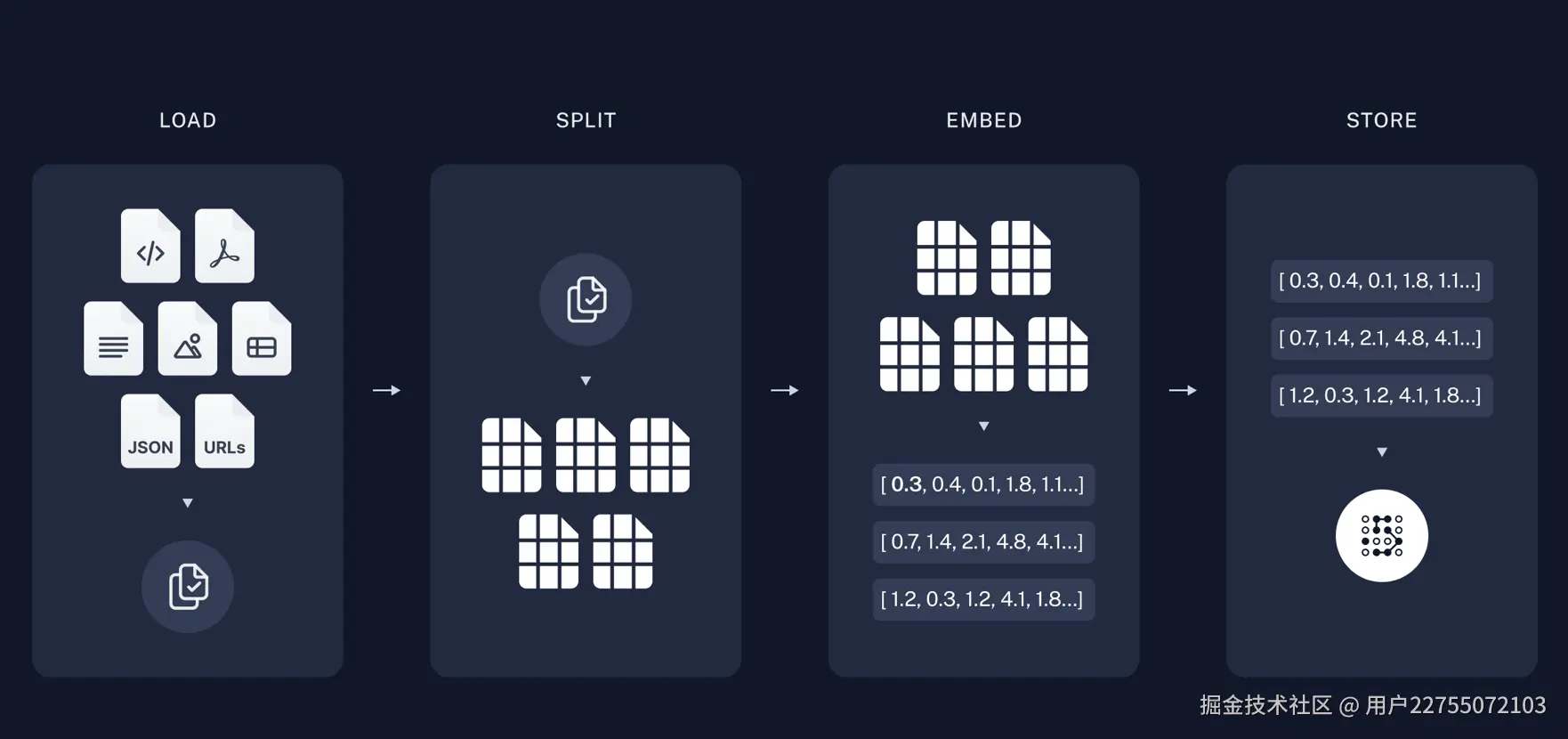
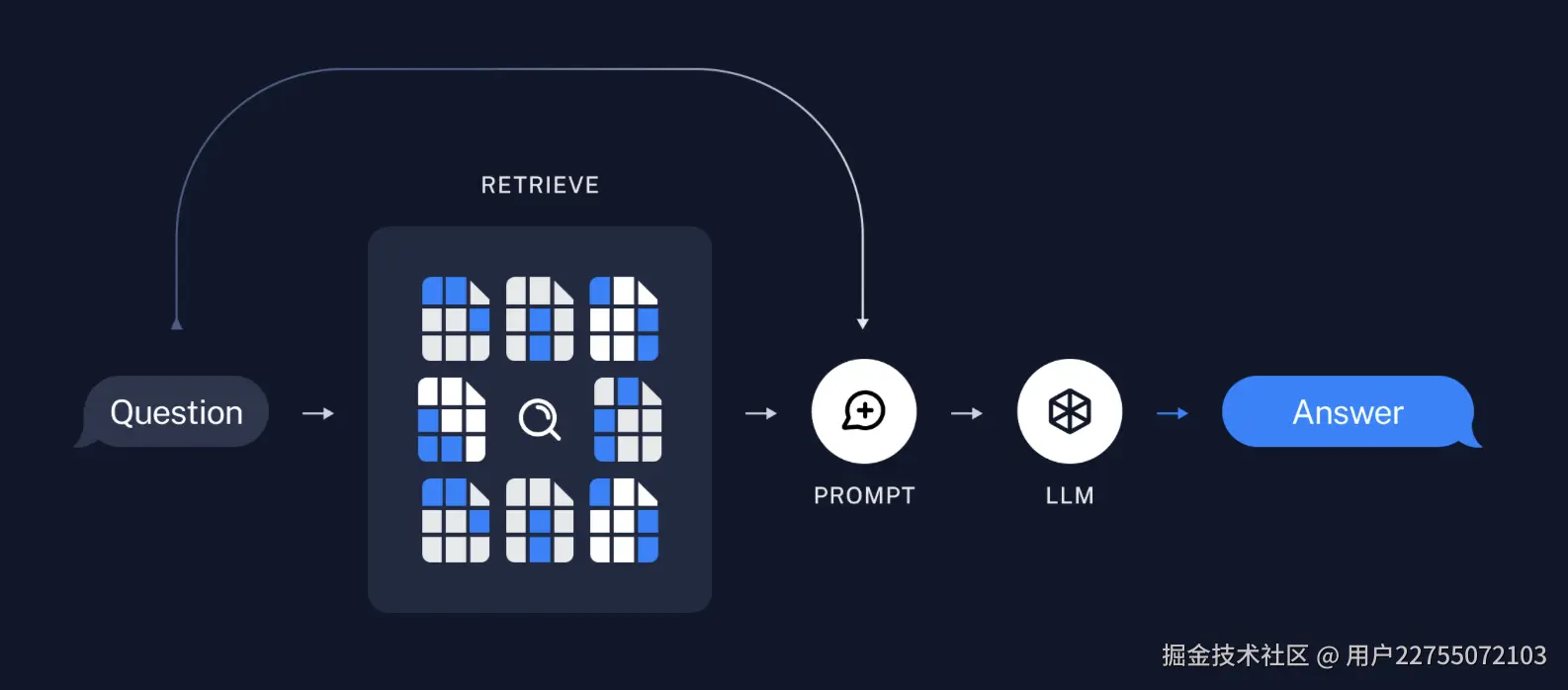
数据驱动决策过程,实现信息检索到处理再到最终行动的自动化步骤。
RAG知识库搭建
依赖包
shell
python 3.10
pip install langchain
pip install langchain_ollama
pip install "langserve[all]"
pip install langchain-chroma
pip install langgraph基本处理步骤
- 1 加载文档,使用pdf导入知识库,使用了PDFPlumberLoader
- 2 文档分割,使用RecursiveCharacterTextSplitter设置chunk大小,以及重叠的字符数
- 3 向量存储和嵌入设置,使用Chroma创建向量及对应的嵌入配置
- 4 创建检索器,根据向量存储设置检索器
- 5 创建问答链
- 6 创建提示链
- 7 组合两个链,并使用RunnableWithMessageHistory创建带上下文的chain
- 8 创建对外开放api
完整代码
python
import os
from langchain_ollama import OllamaLLM, OllamaEmbeddings
from langchain_community.document_loaders import PDFPlumberLoader
from fastapi import FastAPI
from langserve import add_routes
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain.chains.retrieval import create_retrieval_chain
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.chat_message_histories import ChatMessageHistory
# 导入pdf,进行问答分析
# 使用自行构建的deepseek-R1-32b
# 解决 Intel OpenMP 库(如 MKL、TBB)的运行时冲突
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 设置Ollama的主机和端口(可选,如果已在环境变量中设置则不需要)
os.environ["OLLAMA_HOST"] = "127.0.0.1"
os.environ["OLLAMA_PORT"] = "11434"
# 初始化ollama
def get_chat_llm() -> OllamaLLM:
chat_llm = OllamaLLM(
model="deepseek-r1:32b"
)
return chat_llm
# 加载pdf文档
loader = PDFPlumberLoader('test.pdf')
docs = loader.load()
# 文档分割
splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200)
splits = splitter.split_documents(docs)
# 向量存储
vector_store = Chroma.from_documents(documents=splits,
embedding=OllamaEmbeddings(model="nomic-embed-text"))
# 创建检索器
retriever = vector_store.as_retriever()
# 创建一个问题的模板
system_prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer
the question. If you don't know the answer, say that you
don't know. Use three sentences maximum and keep the answer concise.\n
{context}
"""
prompt = ChatPromptTemplate.from_messages( # 提问和回答的 历史记录 模板
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
model = get_chat_llm()
# 得到chain
chain1 = create_stuff_documents_chain(model, prompt)
# 创建一个子链
# 子链的提示模板
contextualize_q_system_prompt = """Given a chat history and the latest user question
which might reference context in the chat history,
formulate a standalone question which can be understood
without the chat history. Do NOT answer the question,
just reformulate it if needed and otherwise return it as is."""
retriever_history_temp = ChatPromptTemplate.from_messages(
[
('system', contextualize_q_system_prompt),
MessagesPlaceholder('chat_history'),
("human", "{input}"),
]
)
# 创建一个子链
history_chain = create_history_aware_retriever(model, retriever, retriever_history_temp)
# 保持问答的历史记录
store = {}
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 创建父链chain: 把前两个链整合
chain = create_retrieval_chain(history_chain, chain1)
result_chain = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key='input',
history_messages_key='chat_history',
output_messages_key='answer'
)
# # 第一轮对话
# resp1 = result_chain.invoke(
# {'input': '你是什么产品?'},
# config={'configurable': {'session_id': 'zs123456'}}
# )
#
# print(resp1['answer'])
#
# # 第二轮对话
# resp2 = result_chain.invoke(
# {'input': '它能为我做什么'},
# config={'configurable': {'session_id': 'zs123456'}}
# )
#
# print(resp2['answer'])
app = FastAPI(title='我的Langchain服务', version='V1.0', description='使用Langchain翻译任何语句的服务器')
add_routes(
app,
result_chain,
path="/chainDemo",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8090)这样就搭建了一个可以通过api访问的问答库,问答可以基于文档分析进行回答,蛮强的,下一次说一下我用streamlit创建的简易的页面问答。