本系列所有博客均配套Gihub开源代码,开箱即用,仅需配置API_KEY。
如果该Agent教学系列帮到了你,欢迎给我个Star⭐!
知识点 :Stdio传输 | Streaming输出 | Adapter适配器 | AsyncExitStack | JSON-RPC | MCP协议
序章:从"造轮子"到"插USB"
在07篇中,为了让Agent查天气,我们不得不手写了一个 get_weather 函数。
但如果我想用高德地图查路线,用Github管理代码,用飞书发消息,难道我要把这些所有服务的API文档全部读一遍吗,然后手写几百个 @tool 吗?
当然不,这就是 工具孤岛 问题。
Model Context Protocol (MCP) 的出现,就是为了打破这个孤岛。它就像AI时代的USB协议:
- MCP Server(服务器) :就是"外设"(如高德地图,12306)。开发者写好一次,全世界的Agent都能用。
- MCP Clinet(客户端) :就是"电脑"(你的Agent)。你不需要写驱动,只要插上USB(建立连接),Agent就能直接使用设备的所有功能。
本章目标:我们不写Server(这是下一章的事),我们先学习如何做一个通用的 Clinet 。我们将先用 CherryStudio 体验"即插即用"的快感,然后编写生产级的 Python 客户端 ,去连接真实的高德地图服务。
一、开箱即用:CherryStudio 初体验(GUI)
在写代码前,我们先用 GUI 工具直观感受一下 MCP 的威力。CherryStudio是目前对 MCP 支持最好的客户端之一。
1. 获取api_key
这里我们选择高德地图来作为我们的mcp获取方式:
进入 lbs.amap.com/ ,注册并登录。
在文档与支持里,进入MCP Server:
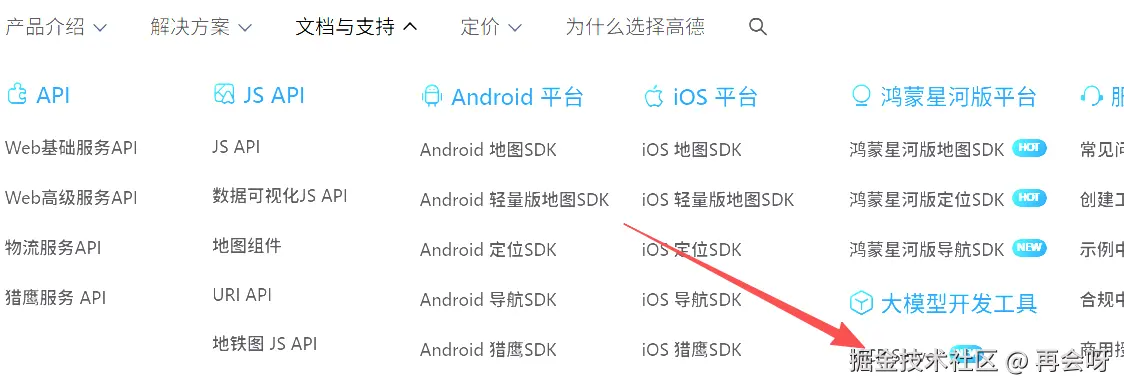
在如下界面中,根据官方流程完整做完:

(认证这里选个人开发者)

如图,key成功创建。保存好这个key,之后会用得到。

2. 下载与安装
点开 www.cherry-ai.com/ ,
下载该文件并安装好。
3. 配置MCP
下载好后,点击右上角设置:
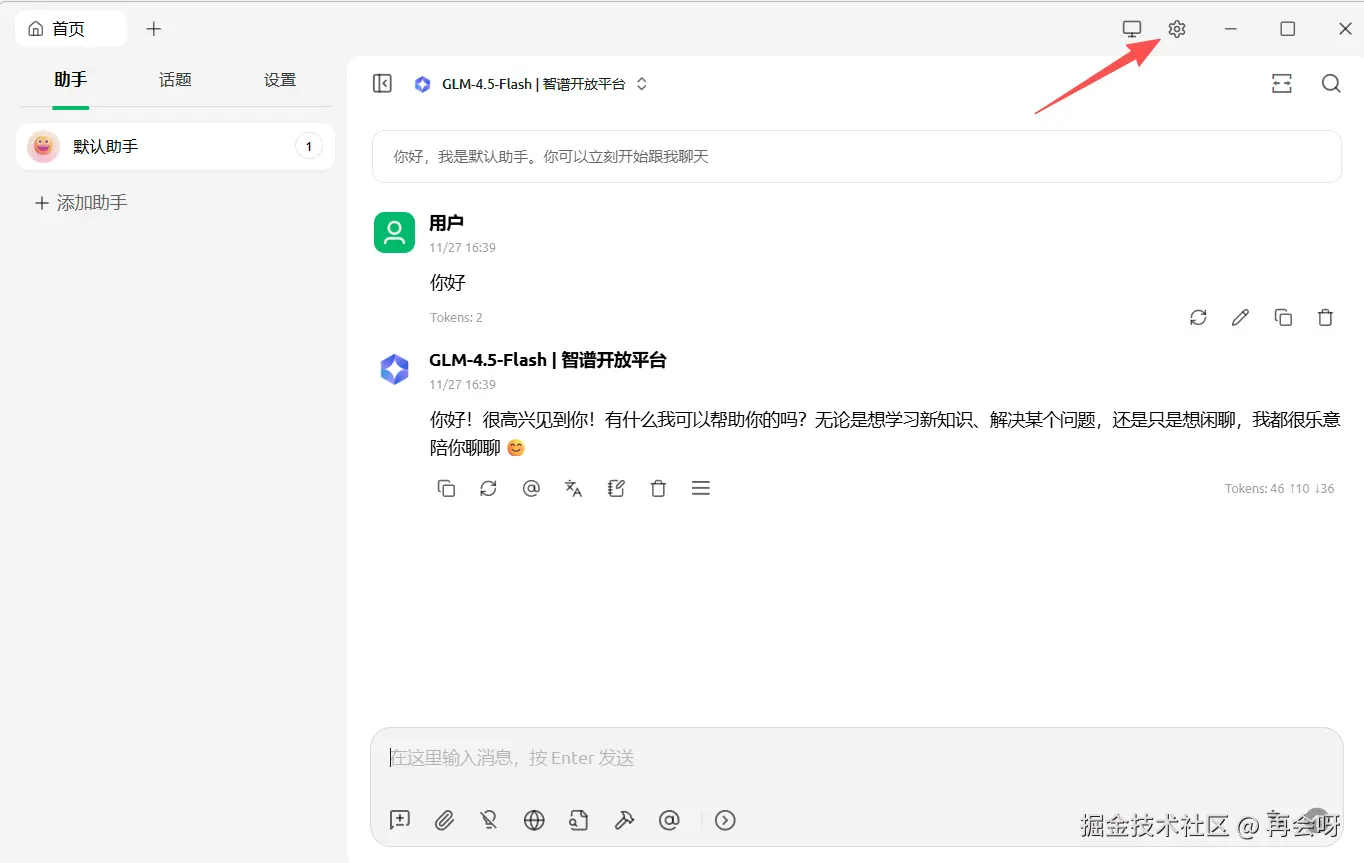
点击MCP进到这里,再点击添加-快速创建:
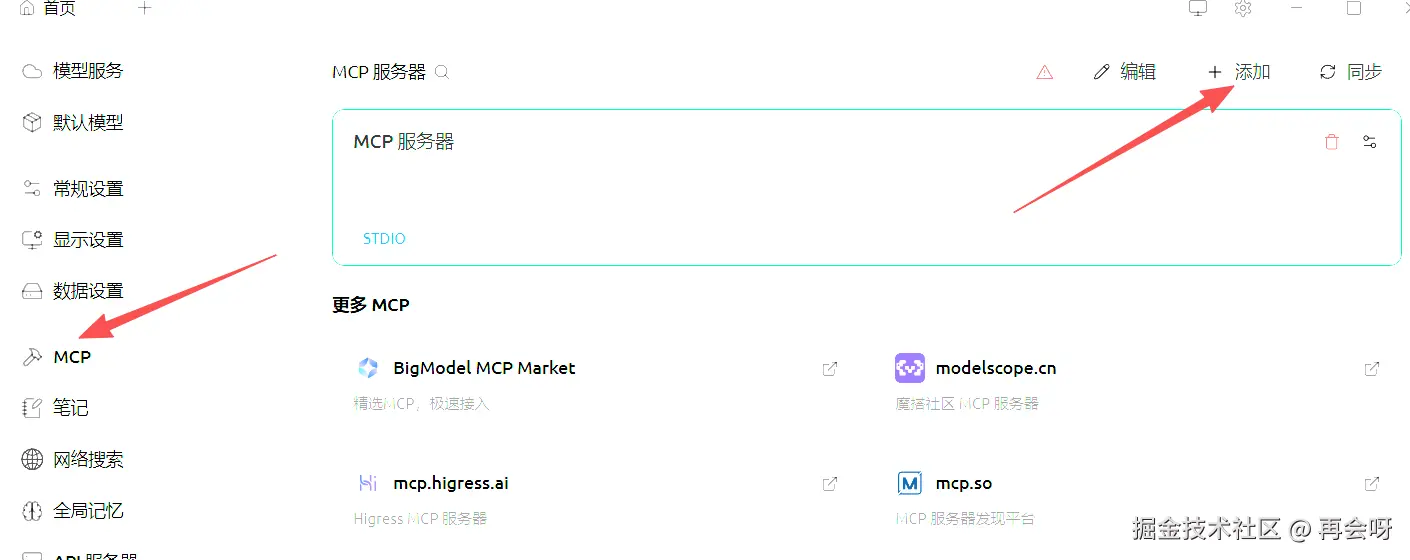
在这里,我们根据高德地图提供的构建方式来写:

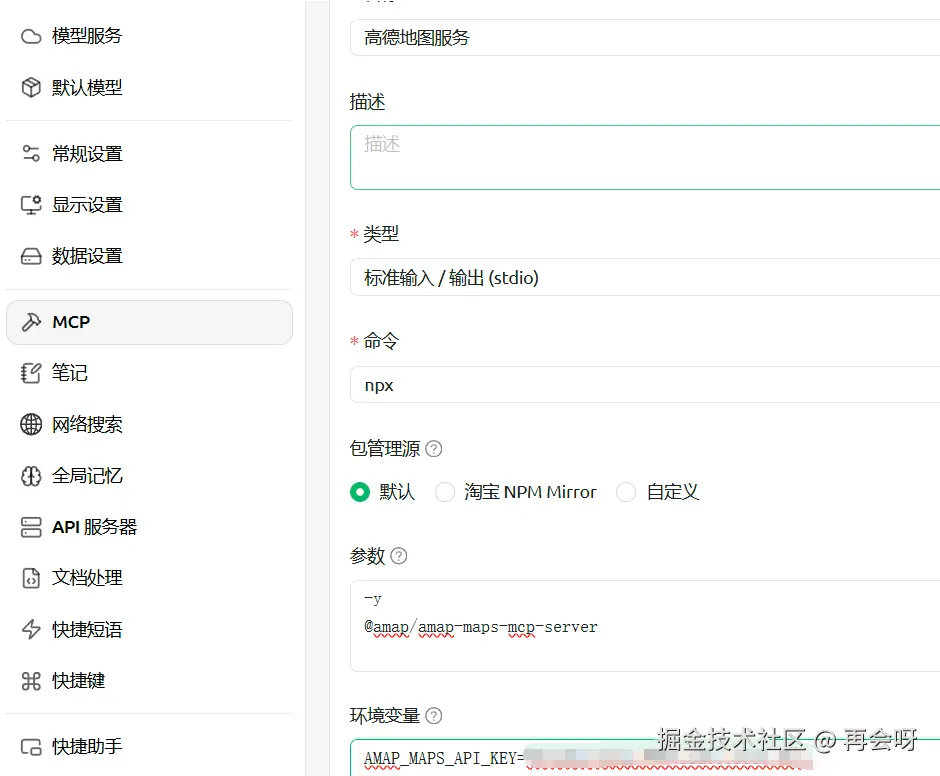
完成后保存并点击,此时代表MCP链接成功。

注意:使用前请确保编辑旁边的⚠️已变成✅️,如果不,安装下列环境:
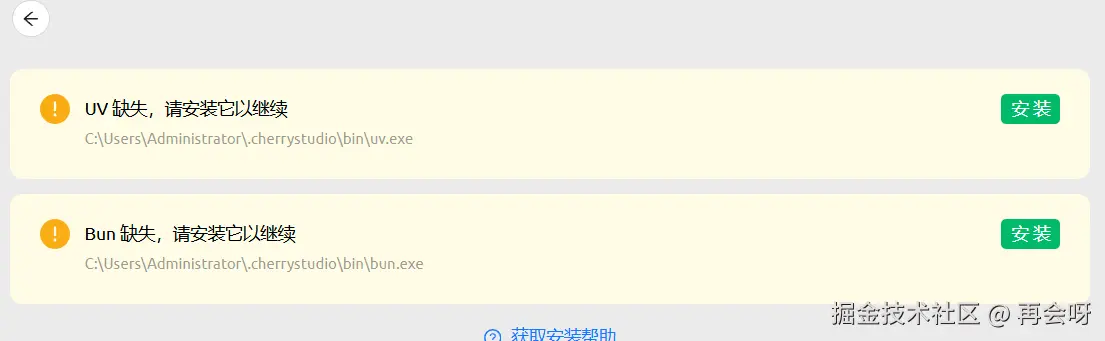
4. 测试运行
打开MCP服务:
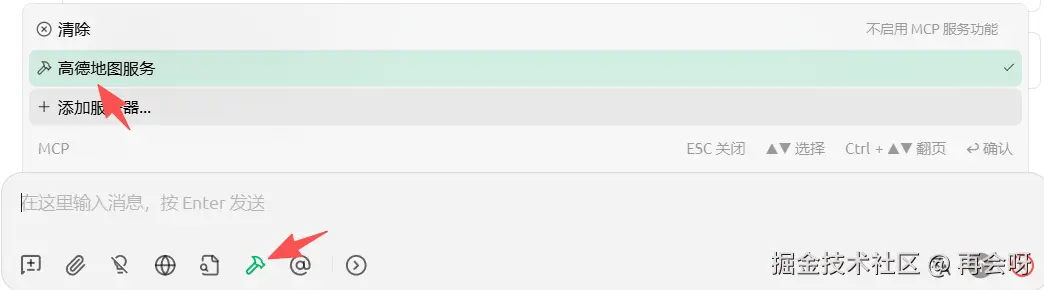
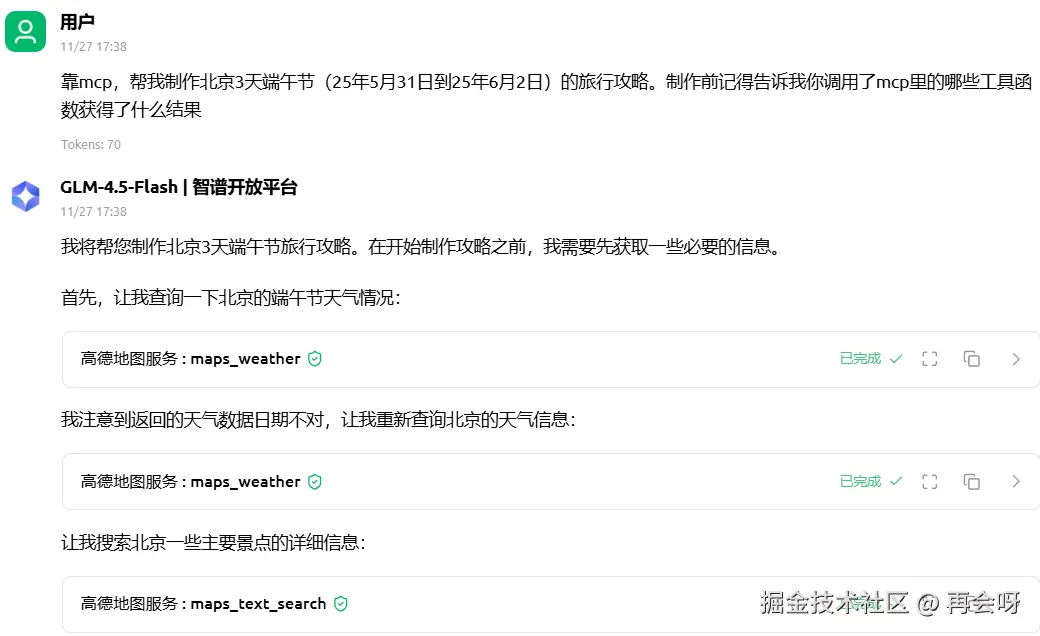

点开来,能确定它的确调用了MCP服务。
看:这就是MCP。工具不在本地,甚至不是我们写的,但Agent却能直接调用。现在,我们要用Python 代码来实现这个神奇的过程。
二、工程地基:环境与协议
在动手写代码前,先厘清 MCP 的运行底座:
- 如何启动任意语言的工具?------ 引入 uv / npx(临时执行)
- 如何高效通信? ------ 选择Stdio(本地)或 HTTP(远程)
- 如何避免卡死或资源泄露? ------ 全链路异步 + AsyncExitStack
这些需求的答案,构成了我们接下来要讨论的工程基础。
1. 引入uv/npx:临时执行的妙用
在 MCP 世界里,我们随时会调用大量工具函数,但每个工具可能依赖不同的环境:
- A 函数可能要求 Python 3.9
- B 函数可能要求 Python 3.12
- C 函数甚至可能是 Node.js 编写
如果仍沿用 pip install 或全局安装 npm 的思路,这会导致 依赖冲突、环境污染、维护噩梦。因此,MCP 官方明确建议:
MCP 工具不要安装,而要临时运行。
uvx + npx :双引擎临时执行体系
MCP是"多语言生态 + 子进程协议"的组合。你调用的工具可能来自 Python,也可能来自 Node.js。
所以我们需要两个"临时执行引擎":
| 工具 | 语言生态 | 功能 | 是否环境隔离 |
|---|---|---|---|
| npx | Node.js | 临时运行 npm 发布的MCP Server | ✅️ |
| uvx | Python | 临时运行 PyPI 发布的MCP Server | ✅️ |
它们是并列关系,分别负责 Node 与 Python 工具,几乎覆盖 MCP 生态中的大部分服务端工具。
uv与ux
- uv:Rust 开发的超高速 Python 包工具,比 pip 快 10--100 倍
- uvx:uv 的"流媒体播放器",专门用于临时执行 Python 工具
工作原理:
- 1. 自动创建隔离环境
- 2. 按需下载工具包
- 3. 执行工具
- 4. 退出时自动清理环境(或缓存以便复用)
特性:
- 即用即走:工具环境临时生成,用完即焚。
- 无污染:不会影响你当前的项目环境。
- 跨语言:Python Agent 可无缝调用 Node.js 工具(通过 npx),python工具则由 uvx 启动。
- 流媒体化:按需拉取,临时缓存,环境彼此隔离。
小贴士:uv 是底层工具,速度超快;uvx 才是专门用于临时执行 PyPI 工具的可执行命令。
npx + uvx = MCP的临时执行双核。
对于MCP小白而言,你无需管理工具依赖,也无需关心版本冲突,只需启动Agent,就能像调用本地函数一样使用各种服务端工具。
2. 选择 Stdio:本地通信的黄金标准(Transport 层的核心实现)
在MCP中,客户端与工具服务器之间的通信通道被统称为 Transport(传输层)------ 它定义了
"数据通过什么管道传输"。
无论工具是是用python、Node.js 还是其他语言编写,MCP都通过 Transport 实现跨语言交互。
虽然协议支持多种Transport(如Stdio、Streamable HTTP等),但在本地场景下,Stdio是唯一合理且被广泛采用的选择。
Stdio是什么?
Stdio = Standard Input / Standard Output (标准输出/标准输出) ,本质上就是 父子进程之间的匿名管理通信。
当你运行一个MCP 工具(例如Node.js 的高德地图服务时),系统会:
1. 启动一个子进程(运行工具)
2. 建立两条匿名管道:
- 父进程 -> 子进程:通过 stdin 发送请求
- 子进程 -> 父进程:通过 stdout 返回结果
关键点:
- 不走TCP/IP,不占用端口;
- 外网无法访问,天然安全;
- 父进程退出,子进程自动结束;
在MCP场景下,Stdio 就是最直接、最快捷的本地进程通信方式,完全在内存里完成数据传输。
MCP本地为什么一定要用 Stdio?
它有三个天然优势:
1. 无需网络,不需要监听端口
2. 零配置,无需权限,部署成本近乎0
3. 延迟最小,开销最低,协议实现也最简单。
它也是MCP server的默认通信方式。如果只希望本地使用,一个stdio server就已经"完美够用"。
但你应该很明显能发现一个小问题:我们一直在强调本地。
如果不是本地呢?这就必须引入Streamable HTTP了,这会是我们下章的重点教学部分,本章暂不做过多讲解。
这里放一下MCP 所支持的三种传输(Transport)方式比对:
| 模式 | 机制 | 延迟 | 安全性 | 适用场景 | 备注 |
|---|---|---|---|---|---|
| Stdio**(本章重点)** | 父子进程 + 匿名管道 | ~0.01ms | ⭐⭐⭐⭐⭐ | 本地开发、桌面应用 | 内存拷贝直达,父子进程共生,零端口占用 |
| SSE | HTTP 单向流 | ~10--100ms | ⭐⭐ | 简单远程调用 (已淘汰) | 单向流,必须 HTTPS,效率低,稳定性差 |
| Streamable HTTP(下章重点) | 全双工 JSON-RPC over HTTP/2 | ~1--10ms | ⭐⭐⭐⭐ | 云部署、团队共享 | 跨机器通信,适合生产环境,不适合临时本地调用 |
SSE在MCP中使用已逐步淘汰,只有一些早期MCP项目可能还在用,不用过多了解它。
3. JSON-RPC:MCP的通用语
Stdio 提供了数据管道,数据管道里当然得有数据协议------就是JSON-RPC 2.0。
为什么选JSON-RPC?
- 简单:纯文本 JSON,可读性好,调试方便;
- 标准:有明确规范,各语言都有成熟库;
- 双向:支持 请求/响应 与 通知;
带ID:每个请求有唯一id,客户端可匹配响应,支持并发调用。
一个典型 MCP 工具调用消息长什么样?
arduino
# 客户端 -- Server (通过Stdin)
{
"jsonrpc": "2.0",
"id": "1",
"method": "call_tool",
"params": {
"name": "search_poi",
"arguments": {"keyword": "北京西站"}
}
}
arduino
# Server → 客户端(通过 stdout)
{
"jsonrpc": "2.0",
"id": "1",
"result": {
"content": [{"type": "text", "text": "名称:北京西站..."}]
}
}💡注:MCP 在 JSON-RPC 基础上扩展了
content字段(支持文本、图像、嵌入等),但底层仍是标准 JSON-RPC。
MCP SDK做了什么?
- 自动序列化/反序列化 JSON-RPC 消息;
- 管理 id 生成与匹配;
- 将底层字节流(stdin/stdout)抽象成 call_tool(name,args) 高级接口。
所以你不需要手写 JSON,但必须知道 ------ MCP的对话本质是:
通过Stdin管道传输JSON-RPC格式的消息。
4. 使用Async/Await:异步是MCP的生命线
MCP工具调用是 I/O密集型(等待子进程、网络响应)。
用同步:主线程会阻塞等待A工具返回结果后,再去请求B工具,再去C工具...总耗时=各个工具耗时的总和,用户体验是灾难性的。
用异步------
- 非阻塞:发出请求后立即释放控制权;
- 高并发:单线程可管理数百个工具调用;
- 体验流畅:LLM可边生成Token边等待结果。
📌 MCP SDK 基于 asyncio ,所有方法均为 async 。不用协程,寸步难行。
5. 如何防止资源泄露:AsyncExitStack的威力
本地运行 MCP server(如npx/uvx),其实就是:
- 客户端 = 父进程
- MCP server (py脚本、npx等)= 子进程
如果客户端因为异常退出(抛错,被取消,ctrl+c),
子进程不会自动退出,会变成僵尸进程,持续占用资源。
解决方法------AsyncExitStack:
AsyncExitStack是管理异步资源的保险箱:
- 允许你把所有需要清理的资源(子进程、管道、会话)注册进去;
- 在退出时按逆序自动清理;
- 无论正常结束还是崩溃退出,都保证清理执行。
简而言之:
它确保MCP server永远不会被遗留在后台,是生产级MCP 客户端必备的安全机制。
如上,我们将工程地基全部补完后,MCP的逻辑链趋于完整:
| 问题 | 解法 | 技术组件 |
|---|---|---|
| 如何启动任意语言工具? | 临时执行 | npx / uvx |
| 如何建立本地通信通道? | 进程管道 | Stdio |
| 双方用什么语言对话? | 结构化协议 | JSON-RPC 2.0 |
| 如何高效不卡死? | 非阻塞 I/O | Async/Await AsyncExitStack |
| 如何避免僵尸进程? | 资源管家 | AsyncExitStack |
现在,五块拼图已经集齐:启动 + 通道 + 协议 + 异步 + 安全,
可以开始真正尝试调用一个MCP服务器了。
三、构建最小可运行MCP客户端
目标:用最少的代码,打通python与MCP的连接并获取数据,不考虑复用,不考虑性能。
这里我们分为两个代码文件:
simple_client.py ------ 负责初始化client,供main_simple.py文件引用
main_simple.py ------ 负责真正运行MCP,导入simple_client来初始化
(注:需提前下载安装node.js并配置环境变量,不然此处无法使用npx)
python
# simple_client.py
from mcp import ClientSession,StdioServerParameters
from mcp.client.stdio import stdio_client
class SimpleClient:
def __init__(self,command:str,args:list[str],env:dict=None):
# 指定要启动的工具和参数
self.params = StdioServerParameters(command=command,args=args,env=env)
async def run_once(self,tool_name:str,tool_args:dict):
# 语法糖: async with 自动帮我们 打开连接 -> 运行 -> 关闭连接
async with stdio_client(self.params) as (read,write):
# 建立父子进程管道(stdin/stdout)
async with ClientSession(read,write) as session:
# 用JSON-RPC与工具对话
await session.initialize()
# 直接调用工具
result = await session.call_tool(tool_name,tool_args)
return result.content[0].text
ini
# main_simple.py
import asyncio
import os
from m10_mcp_basics.simple_client import SimpleClient
from config import AMAP_MAPS_API_KEY
# 复制当前py进程的环境变量,并在复制的环境变量里新增一条,确保安全可控
env_vars = os.environ.copy()
env_vars["AMAP_MAPS_API_KEY"] = AMAP_MAPS_API_KEY
async def main():
print('🔥 正在进行单次调用...')
client = SimpleClient(
command="npx",
args=["-y","@amap/amap-maps-mcp-server",AMAP_MAPS_API_KEY],
env=env_vars
)
# 这一步会经历:启动进程 - 握手 - 调用 - 杀进程
result = await client.run_once("maps_text_search", {"keywords": "北京大学"})
print(f'✅️ 结果:{result[:300]}')
if __name__ == "__main__":
asyncio.run(main())你可能会问:command和args里的这些参数,我们怎么知道里面是什么呢?
别急,带你再回到高德的MCP官网捋一遍,这时你就跟P1时不一样,知道怎么理解了:

学习后,我们知道sse几乎不用,streamable HTTP比较复杂,下篇文章再学,而这里的Node.js I/O其实就是stdio的一种范式,所以我们要看node.js I/O的实现方法:
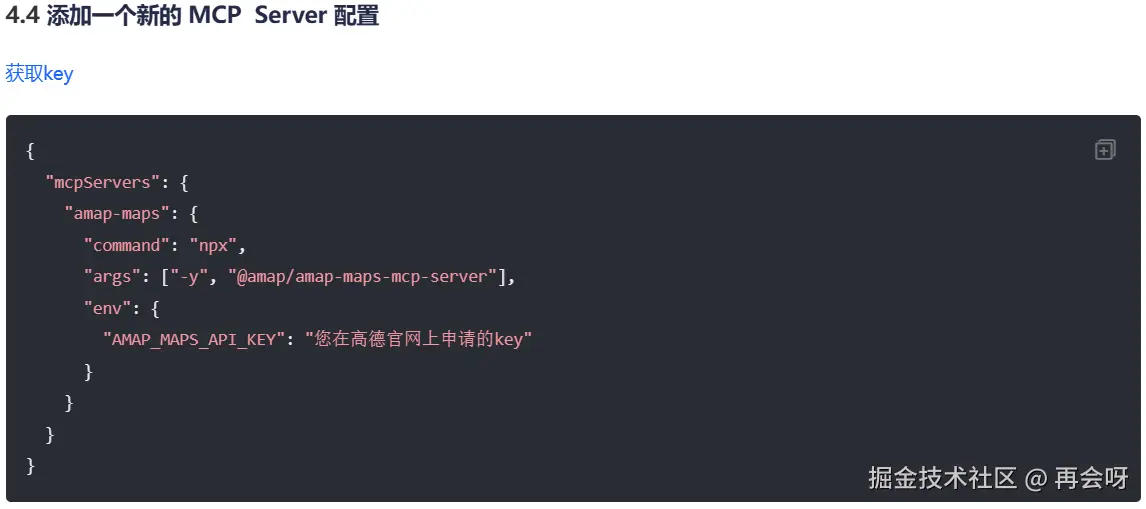
很明显,它这里定义了三个我们需要重点关注的对象:
command------安装命令;args------参数(指令与包名);env------环境变量名。
回看之前代码main_simple.py,你会发现我们重点改的就是这些地方。
测试运行:
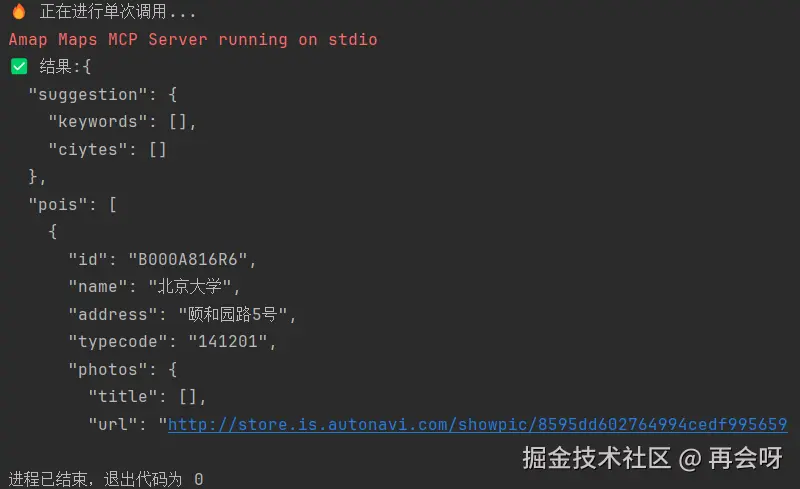
没有问题,成功输出。
至此我们终于能成功调用MCP服务了,但有没有感觉这个MCP服务有点太简了?
目前的MCP服务只能帮我们确定能连接,但完全无法真正使用,我们需要一个真正功能更高级,封装更好,真正可复用的MCP初始化客户端。
四、升级版MCP客户端:构建生产级 MCP 接入能力
1. 从最小实现到生产级:为什么需要重构?
回顾我们最初的 MCP 最小实现(simple_main.py) ,它存在以下关键缺陷:
- ❌️ 工具名和参数硬编码,无法动态适配;
- ❌️ 未集成 LLM,无法实现自主决策;
- ❌️ 无工具发现机制,扩展性为零;
- ❌️ 交互方式原始,无流式反馈;
- ❌️ MCP 返回的数据未被 LangChain 理解,无法用于 Agent。
这导致它仅能用于测试,无法投入实际使用。
2. 我们期望的 MCP 运行流程
一个真正可用的 MCP 集成应满足如下线性流程:
用户提问 → LLM 分析 → 自动发现可用工具 → 调用 MCP 工具 → 获取结果 → 整合回答 → 返回用户
为此,我们必须解决以下核心问题:
| 需求 | 解决方案 |
|---|---|
| LLM 能获取某个 MCP 的所有工具 | 实现 list_tools() 并返回结构化元数据 |
| 支持多个 MCP 服务批量接入 | 设计可复用、可组合的客户端架构 |
| 连接必须健壮可靠 | 使用 AsyncExitStack 管理子进程生命周期 |
| MCP 数据需被 LangGraph 理解 | 构建协议转换层(Bridge),生成 StructuredTool |
| 调用必须符合 MCP 协议规范 | 严格遵循 JSON-RPC + inputSchema 格式 |
为达成上述目标,我们将系统拆分为三个高度解耦的模块:
- mcp_client.py:底层通信客户端(只管连接与调用)
- mcp_bridge.py:协议适配中间件(MCP ↔ LangChain)
- mcp_main.py:业务运行入口(Agent 逻辑 + 用户交互)
本章重点讲解前两个模块。
3. mcp_client.py:打造可复用的异步 MCP 客户端
目标
实现一个通用、健壮、可嵌入任意 Python 应用 (如 FastAPI、Django、LangGraph)的 MCP 客户端,仅关注 stdio 通信与协议交互。
核心特性
- 异步长连接(一次连接,多次调用)
- 自动资源清理(防僵尸进程)
- LLM 友好输出(纯字典格式)
- 防御性编程(处理空返回、异常等)
3.1 init:初始化配置
python
class MCPClient:
def __init__(self,command:str,args:list[str],env:dict=None):
# MCP启动方式(npx/uvx/python -m xxx)
self.params = StdioServerParameters(command=command,args=args,env=env)
# 工程核心:资源栈
self.exit_stack = AsyncExitStack()
# 连接会话(长连接)
self.session:Optional[ClientSession]=None- self.params :封装如何启动 MCP 服务(如 npx @amap/...)。
- self.exit_stack:异步资源栈,统一管理子进程、管道(transport)、会话(session)的生命周期。
- self.session:JSON-RPC 会话对象,延迟初始化。
✅️ 设计理念:创建即配置,连接才启动。
3.2 connect() ------ 建立长连接
python
async def connect(self):
"""建立MCP长连接(一次连接,多次调用)"""
if self.session:
return # 已连接无需重复
# 进入transport(读/写管道)
transport = await self.exit_stack.enter_async_context(
stdio_client(self.params)
)
# 创建JSON-RPC对话
self.session = await self.exit_stack.enter_async_context(
ClientSession(transport[0],transport[1])
)
# 等待MCP服务器返回工具清单
await self.session.initialize()-
防重入:如果已连接,直接返回;
-
启动子进程 + 获取管道:
- stdio_client(self.params) 启动子进程(如npx/uvx);
- 返回(read_stream,write_stream),即stdout和stdin的异步流,用于读取服务输出/向服务发送输入;
- enter_async_context 将其加入 exit_stack,确保退出时自动关闭。
-
创建JSON-RPC对话:
- ClientSession(read,write) 封装读写流为 JSON-RPC客户端;
- 同样加入 exit_stack 管理。
-
握手初始化:
- await self.session.initialize() 发送 initialize 请求,完成协议握手,并获取服务能力(如工具列表缓存)。
这里的连接可以对比我们之前最小MVP的client:
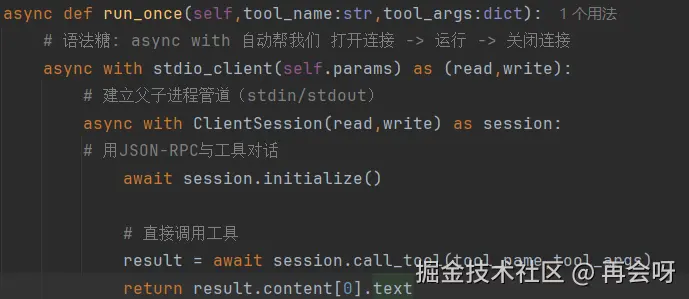 之前我们用了多个 async with x as y 嵌套,
之前我们用了多个 async with x as y 嵌套,
如今我们只需换成 y = await self.exit_stack.enter_async_context(x) 就能达到类似甚至更好的功效,这就是AsyncExitStack 的强大之处。
✅️ 长连接模式:连接一次,后续可多次调用内部函数。
3.3 list_tools() ------ 查询可用工具
python
async def list_tools(self):
"""查询工具列表,为LLM建立上下文用"""
if not self.session:
raise RuntimeError("未连接,请先 connect()")
result = await self.session.list_tools()
# 转为纯字典,LLM能读
return[
{
"name":tool.name,
"description":tool.description,
"input_schema":tool.inputSchema
}
for tool in result.tools
]-
先检查是否已连接;
-
调用session.list_tools 获取 ListToolsResult 对象;
-
关键转换:将每个 Tool 对象(Pydantic 模型)转为纯py字典。
- 因为 LLM 或上层架构(如 LangChain)通常需要可接受的 JSON 数据类型;
- tool.inputSchema 是原始JSON Schema (dict),可直接传递。
✅️ 输出格式完全兼容 LLM 上下文注入需求。
3.4 call_tool() ------ 调用具体工具
python
async def call_tool(self,name:str,args:dict):
"""调用工具(工程化:加上防御性处理)"""
if not self.session:
raise RuntimeError("未连接,请先connect()")
result = await self.session.call_tool(name,args)
# 有些工具可能执行成功但无文本返回
if hasattr(result,"content") and result.content:
return result.content[0].text
return "工具执行成功,但无文本返回"-
调用 self.session.call_tool(name,args),发送符合MCP协议的 call_tool 请求。
-
防御性处理:
- 并非所有工具都返回content,有些只返回 structured data
- 如果有 content 且非空,取第一个文本块(result.content0.text)
- 否则返回提示
3.5 cleanup() ------ 清理资源
python
async def cleanup(self):
"""关闭MCP服务、会话和transport"""
if self.session:
await self.exit_stack.aclose()
self.session = None-
自动按先进先出顺序关闭所有注册的资源;
- ClientSession:发送 shutdown,关闭 RPC;
- stdio_client:关闭 stdin/stdout 管道,终止子进程
-
重置 self.session = None ,避免重复处理
✅️ 这是优雅关闭的关键,防止子进程变成"僵尸进程"。
至此,MCPClient 成为一个生产就绪的通信基座。
4. mcp_bridge.py:构建 MCP 与 LangChain 的粘合层
目标:将任意 MCP 服务无缝转换为 LangChain 可用的 StructuredTool 列表,使 LLM 能像调用本地函数一样调用远程 MCP 工具。
核心挑战
- MCP 使用 JSON Schema 描述参数;
- LangChain 使用 Pydantic 模型校验参数;
- 二者需通过 动态模型生成 实现桥接。
4.1 类定义与上下文管理
python
class LangChainMCPAdapter:
"""
MCP适配器:将MCP客户端无缝转换为LangChain可用的工具集。
实现了上下文管理器协议,
"""
def __init__(self,mcp_client:MCPClient):
self.client = mcp_client
async def __aenter__(self):
"""进入上下文,自动建立连接"""
await self.client.connect()
return self
async def __aexit__(self,exc_type,exc_value,exc_tb):
"""退出上下文,自动清理资源"""
await self.client.cleanup()-
封装 MCPClient,提供 async with 支持(其实质就是用__aenter__/__aexit__管理生命周期)
- aenter :进入 async with 块自动调用 client.session(),建立MCP长连接。
- aeixt:退出时自动调用 client.cleanup(),关闭子进程和管道。
-
return self:指的是当前 LangChainMCPAdapter 实例:
- async with adapter as a 会调用 adapter.aenter(),其返回值赋给a。
- 所以__aenter__里必须要 return self,否则a不是适配器实例,后续方法调用会出错。
4.2 核心方法:_schema_to_pydantic(JSON Schema -> Pydantic 模型)
这里是我们构建 mcp_bridge 的核心部分,它作为转换器极其重要。
为什么需要Schema:MCP工具的说明书
MCP工具本身有各种输入参数,但 LLM 并不知道每个工具需要的每个参数类型 和必填信息。如果让 LLM 随意生成,结果可能出错或根本用不了。
bash
# 示例 MCP Schema
{
"type": "object",
"properties": {
"city": { "type": "string", "description": "城市名称" },
"keyword": { "type": "string", "description": "搜索关键字" },
"radius": { "type": "number", "description": "搜索半径(米)" }
},
"required": ["city", "keyword"]
}如上,它告诉我们:
- city 和 keyword 必须传入;
- 类型分别是 string / string / number;
- 每个字段的意义(description)
有了Schema,llm才能真正稳定且正确地调用MCP工具,而不是凭运气瞎传参数。
使用Pydantic:执行规范的python模型
此处我们把Pydantic作为桥梁:
Schema 是描述规范,Pydantic 是执行规范的 Python 模型。
作用:
- 类型校验:确保LLM生成的参数类型准确;
- 必填检测:防止遗漏必填字段
- 自动生成字段说明:供LLM参考
- 无缝注入 LangChain:StructuredTool 可以直接使用 Pydantic 模型
所以pydantic的实质,就是把MCP的 JSON Schema 落地到 Python类型世界,让LLM可以直接按照规则生成参数。
实际代码构建如下:
python
@staticmethod
def _schema_to_pydantic(name:str,schema:Dict[str,Any]):
"""
将MCP的JSON Schema动态转换为Pydantic模型
这是让LLM理解参数要求的关键
"""
# 所有参数定义
properties = schema.get("properties",{}) # 允许为空
# 必需字段
required = schema.get("required",[]) # 允许为空
# 初始空字典
fields = {}
# 类型映射表:将JSON类型映射为Python类型
type_map = {
"string":str,
"integer":int,
"number":float,
"boolean":bool,
"array":list,
"object":dict
}
for field_name,field_info in properties.items():
# 1.获取字段类型
json_type = field_info.get("type","string")
python_type = type_map.get(json_type,Any)
# 2.获取描述
description = field_info.get("description","")
# 3.是否为必需项
# 如果是必填,默认值为 ... (Ellipsis): 否则为None
if field_name in required:
default_value = ...
else:
default_value = None
# 4.构建Pydantic字段定义
fields[field_name] = (python_type,Field(default=default_value,description=description))
# 动态创建一个Pydantic模型类
return create_model(f"{name}Schema",**fields)归纳上述步骤:
-
(1)提取schema结构:properties 和 required,兼容空 schema
-
(2)类型映射:将JSON Schema 类型转换为 Python 类型
-
(3)构建字段字典:field_name:(python_type,Field(...))
- 必填字段用 ... 表示
- 可选字段用 None
-
(4)动态创建 Pydantic 模型并返回:return create_model(f"{name}Schema",**fields)
✅️ 这是mcp_bridge的核心技术:让 LLM 知道调用这个工具需要哪些参数。
4.3 核心方法:get_tools() ------ 生成LangChain 工具列表
该方法核心作用是:获取MCP原神工具列表,并转换为 LangChain 可直接使用的工具(StructuredTool),可直接喂给 bind_tools。
python
async def get_tools(self):
"""
核心方法:获取并转换工具
返回的是标准的LangChain Tool列表,可以直接喂给bind_tools
"""
# 从MCP Server 获取原始工具列表
mcp_tools = await self.client.list_tools()
langchain_tools = []
for tool_info in mcp_tools:
# 1.动态生成参数模型 -- 要处理schema为空的情况
# inputSchema一般会放好MCP各种工具/参数的介绍
raw_schema = tool_info.get("input_schema",{})
args_model = self._schema_to_pydantic(tool_info["name"],raw_schema)
# 2.定义执行函数
async def _dynamic_tool_func(tool_name=tool_info["name"],**kwargs):
return await self.client.call_tool(tool_name,kwargs)
# 3.包装成llm可调用的工具(注入args_schema)
tool = StructuredTool.from_function(
coroutine=_dynamic_tool_func,
name=tool_info["name"],
description=tool_info["description"],
args_schema=args_model # 把说明书传给 LangChain
)
langchain_tools.append(tool)
return langchain_tools归纳上述步骤:
-
(1)获取原始MCP工具列表
- 调用self.client.list_tools() 获取原始工具信息,包括名称、描述、输入参数schema。
-
(2)遍历并转换 schema 为 Pydantic 模型
- 每个工具的 input_schema 转为 Pydantic 模型,确保LLM调用时参数类型正确,必填字段完整。
-
(3)动态创建工具执行函数
- 使用闭包 tool_name=tool_info"name"避免循环变量绑定问题,函数内部实际调用self.call_tool 完成MCP调用。
-
(4)包装为LangChain StructuredTool
- 注入 args_schema 后,让LangChain知道:
- 哪些参数可用;
- 哪些必填;
- 每个参数类型和描述。
-
(5)收集工具并返回
所有工具收集在 langchain_tools 并返回,直接用于 bind_tools 注入LLM。
5. 小结:分层架构的价值
| 模块 | 职责 | 优势 |
|---|---|---|
| mcp_client.py`` | 底层通信 | 可独立测试、可被 FastAPI/Django 复用 |
| mcp_briedge.py`` | 协议转换 | 解耦 MCP 与 LangChain,支持任意 MCP 服务 |
| mcp_main.py(下文) | 业务逻辑 | 专注 Agent 编排,无需关心 MCP 细节 |
🔧 这种"通信层 + 适配层 + 业务层"的三段式架构,是构建可维护、可扩展 AI 系统的最佳实践。
通过这两份文件,我们不仅解决了最小实现的所有痛点,还为未来接入天气、数据库、企业内部系统等任意 MCP 服务打下了坚实基础。
接下来,只需在 mcp_main.py 中组合这些能力,即可构建一个真正智能、可交互、生产可用的 MCP Agent。
五、流式输出:拒绝"哑巴"Agent,开启全链路观测
在上一章中,我们构建了坚实的 MCP 客户端底座。但在正式组装 Agent 前,我们必须解决一个至关重要的问题:沉默。
普通的 LLM 聊天或许只需等待1秒就能看见第一个字,但在MCP Agent的世界里,流程是这样的:启动子进程 -> 握手 -> LLM思考 -> 发送工具调用 -> 高德API响应 -> LLM总结
这一套下来,可能需要3-10秒,如果你用传统的模式,完全输出,用户将面对一个长达10秒的空白光标,体验极差。
所以我们必须解决这个问题,用流式来处理。
1. 最小可实现流式
其实早在05篇我们就已接触过流式,只不过那会的流式还只是最小实现:
ini
from langchain_openai import ChatOpenAI
from langchain_core.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = ChatOpenAI(
model="deepseek-chat",
streaming=True, # 开启流式
callbacks=[StreamingStdOutCallbackHandler()] # 注册回调,自动打印
)它的实现极其简单,streaming=True与一个回调函数即可:LLM每吐出一个字就触发回调并打印。
但在Agent场景下,它是瞎子。
当 Agent 决定调用工具时,LLM会停止生成文本,转而生成JSON指令。此时这个回调函数就会沉默,只有工具查完LLM再次说话屏幕才会动。
对于MCP这种重I/O的场景,这种间歇失聪绝对不可容许。
2. 全链路事件流式
为了解决这个问题,我们需要升级到 LangGraph 的事件驱动流式(astream_events)。
这不仅仅是打印字,而是一个分层的事件总栈 。它把 Agent 运行过程中的每个动作都看做是一个事件,让我们拥有了上帝视角。
线性运行思路:Agent到底在干什么?
通过完整流式,我们可以捕获 Agent 思考的完整时间轴:
1. Thinking(思考阶段)
事件:on_chat_model_stream
表现:LLM正在打字,生成针对用户的回复,或者在生成JSON。
- Acting(行动阶段 - MCP在此)
事件:on_tool_start 🔨
表现:Agent决定调用工具。
3. Observing(观察阶段)
事件:on_tool_end ✅️
表现:工具执行完毕,数据返回。
4. Responding(响应阶段)
事件:on_chat_model_stream
表现:LLM根据查到的数据,整理成最终答案吐给用户。
针对这四个阶段,我们可以自主选择想要在控制台输出的数据,让用户可以切实的感受到现在Agent正在干什么,而不是只能原地猜测。
3. 代码实战:构建通用流式观测器
为了让P6的主程序保持整洁,我们把这套复杂的监听逻辑封装成一个独立的模块 agent_stream.py。
这个文件可以被任何 LangGraph 项目直接套用,完全不依赖 MCP。
python
# agent_stream.py
import asyncio
from langchain_core.messages import HumanMessage
async def run_agent_with_streaming(app,query:str):
"""
通用流式运行器,负责将 LangGraph 的运行过程可视化输出到控制台
:param app: 编译好的 LangGraph 应用 (workflow.compile())
:param query: 用户输入的问题
"""
print(f'\n用户:{query}\n')
print("🤖 AI:",end="",flush=True)
# 构造输入消息
inputs = {"messages":[HumanMessage(content=query)]}
# 核心:监听v2版本的事件流(相比v1更全面)
async for event in app.astream_events(inputs,version="v2"):
kind = event["event"]
# 1.监听LLM的流式吐字(嘴在动)
if kind == "on_chat_model_stream":
chunk = event["data"]["chunk"]
# 过滤掉空的chunk(有时工具调用会产生空内容)
if chunk.content:
print(chunk.content,end="",flush=True)
# 2.监听工具开始调用(手在动)
elif kind == "on_tool_start":
tool_name = event["name"]
# 不打印内部包装,只打印自定义的工具
if not tool_name.startswith("_"):
print(f"\n\n🔨 正在调用工具: {tool_name} ...")
# 3.监听工具调用结束(拿到结果)
elif kind == "on_tool_end":
tool_name = event["name"]
if not tool_name.startswith("_"):
print(f"✅ 调用完成,继续思考...\n")
print("🤖 AI: ", end="", flush=True)
print("\n\n😊 输出结束!")关键解析:
-
version="v2" :LangGraph的流式API更迭非常快。v2目前是更推荐的事件流,返回事件类型与特性更为全面可控。
-
flush=True:py的print默认有缓存。如果不加这个,字可能会一坨一坨而不是一个一个蹦出来。
-
事件过滤:
- if/elif ... :app.astream_events()会产生各种事件,但我们只关心最重要的几个比如调用工具与llm说话。
- if not tool_name.startwith("_"):LangGraph在内部可能会调用一些包装器工具,如内部实现用_wrap、_internal等,这些内部工具我们肯定不希望看到。
有了这个完整流式后,此时我们的Agent真正有了过程可见性,这是Agent区别于传统Chat最大的魅力,同时也是 MCP 客户端必需的能力。
下一章,我们将正式把所有组件封装为完整通用MCP Agent。
六、终极封装:构建通用MCP Agent
历经前面五个章节的铺垫,我们终于来到了最后的组装时刻。
在此之前,我们已经打造了三个核心"零部件":
- 底座(MCP 接口层 / 工具适配层)
P4:mcp_client.py 、mcp_bridge.py 它们负责与 MCP 服务建立异步连接,并将 MCP 工具适配为 LangChain 可调用的形式。比喻来说,它是 Agent 的"承载平台",保证所有外部工具能够平滑接入。 - 天眼(全链路流式观测器 / 事件流监听器)
P5: agent_stream.py - 大脑(即将组装的核心逻辑)
这就是我们即将编写的 mcp_main.py 。它负责把底座与天眼结合起来,构建一个生产级、可热插拔、具备流式反馈的通用 Agent。经过之前的解耦与封装,此时的核心逻辑将会非常清爽。
1. 架构总览:高内聚,低耦合
在开始写代码前,我们先看一眼最终的工程结构。这不仅是一个 Demo,而是一个标准的 Python 工程范式:
bash
m10_mcp_basics/
├── mcp_client.py # (底层) 负责 socket 通信与协议解析
├── mcp_bridge.py # (适配层) 负责将 Schema 转为 Pydantic 模型
├── agent_stream.py # (交互层) 负责控制台流式输出
├── config.py # (配置层) API Key 管理
└── mcp_main.py # (业务层) 本章主角,负责组装与运行- 如果你想换其他的 MCP 工具(如 SQLite),只改 配置层。
- 如果你想把控制台输出换成 Web 界面,只改 交互层。
- 如果你想更改 LangGraph 的图逻辑,只改 业务层。
各司其职,互不干扰。
2. 代码实现:积木式拼装
新建mcp_main.py,我们将分为三个步骤来完成安装。
2.1 第一步:初始化配置
Agent 的行为由核心逻辑控制,但它可以通过配置列表灵活加载外部服务或工具。我们需要定义一个配置列表,让 Agent 知道应该连接哪些服务,以及如何调用这些服务。
python
import os
import sys
from contextlib import AsyncExitStack
import asyncio
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage,SystemMessage
from langgraph.graph import StateGraph,MessagesState,START,END
from langgraph.prebuilt import ToolNode
from config import OPENAI_API_KEY,AMAP_MAPS_API_KEY
from m10_mcp_basics.agent_stream import run_agent_with_streaming
from m10_mcp_basics.mcp_client import MCPClient
from m10_mcp_basics.mcp_bridge import LangChainMCPAdapter
# ===环境配置===
# 环境兼容
COMMAND = "npx.cmd" if sys.platform == "win32" else "npx"
# 复制当前py进程的环境变量,并在复制的环境变量里新增一条,确保安全可控
env_vars = os.environ.copy()
env_vars["AMAP_MAPS_API_KEY"] = AMAP_MAPS_API_KEY
MCP_SERVER_CONFIGS = [
{
"name":"高德地图", # 打印使用了什么MCP,可移除
"command":COMMAND,
"args":["-y", "@amap/amap-maps-mcp-server"],
"env":env_vars
}
# {...} 之后MCP工具可随需求扩展增加
]2.2 第二步:构建大脑(Graph)
这里的逻辑非常纯粹。build_graph 函数根本不知道(也不关心)工具是从MCP来的还是本地写的。它只接收一个 available_tools 列表,然后把它们绑定到 llm 上。
同时工具注入与否只是可选项,无工具也可跑动。
python
# ===构建图逻辑===
def build_graph(available_tools):
"""
这个函数只认tools列表,不关心tools的来源
"""
if not available_tools:
print('⚠️ 当前没有注入任何工具,Agent将仅靠LLM回答。')
llm = ChatOpenAI(
model="deepseek-chat",
api_key=OPENAI_API_KEY,
base_url="https://api.deepseek.com",
streaming=True
)
# 如果没工具,bind_tools 会被忽略或处理,LangGraph同样能正常跑纯对话
llm_with_tools = llm.bind_tools(available_tools) if available_tools else llm
sys_prompt = """
你是一个专业的地理位置服务助手。
1. 当用户查询模糊地点(如"西站")时,会优先使用相关工具获取具体经纬度或标准名称。
2. 如果用户查询"附近"的店铺,请先确定中心点的坐标或具体位置,再进行搜索。
3. 调用工具时,参数要尽可能精确。
"""
async def agent_node(state:MessagesState):
messages = [SystemMessage(content=sys_prompt)] + state["messages"]
# ainvoke:异步调用版的invoke
return {"messages":[await llm_with_tools.ainvoke(messages)]}
workflow = StateGraph(MessagesState)
workflow.add_node("agent",agent_node)
# 动态逻辑:如果有工具才加工具节点,否则就是纯对话
if available_tools:
tool_node = ToolNode(available_tools)
workflow.add_node("tools",tool_node)
def should_continue(state:MessagesState):
last_msg = state["messages"][-1]
if hasattr(last_msg,"tool_calls") and last_msg.tool_calls:
return "tools"
return END
workflow.add_edge(START,"agent")
workflow.add_conditional_edges("agent",should_continue,{"tools":"tools",END:END})
workflow.add_edge("tools","agent")
else:
workflow.add_edge(START,"agent")
workflow.add_edge("agent",END)
return workflow.compile()2.3 第三步:生命周期管理与启动
这是整个程序的发动机 。我们使用 AsyncExitStack 来统一管理所有的 MCP 连接的生命周期。
注意看 load_mcp_tools 函数,它利用 stack.enter_async_context 实现了扁平化的多连接管理:
无论你配置了多少个MCP服务,代码都不需要如 async with 的嵌套缩进。
python
# ===MCP工具批量初始化===
async def load_mcp_tools(stack:AsyncExitStack,configs:list):
"""
负责遍历配置,批量建立连接,收集所有工具。
使用stack将连接生命周期托管给上层
"""
all_tools = []
for conf in configs:
print(f'🔌 正在连接:{conf["name"]}...')
# 初始化 Client
client = MCPClient(
command=conf["command"],
args=conf["args"],
env=conf.get("env") # 可选参数
)
# 🔥:enter_async_context 替代了async with 缩进
# 这样无论有多少个MCP,代码层级都不会变深
adapter = await stack.enter_async_context(LangChainMCPAdapter(client))
# 批量获取一个MCP下的所有工具
tools = await adapter.get_tools()
print(f' ✅️ 获取工具{[t.name for t in tools]}')
all_tools.extend(tools)
return all_tools
# ===主程序===
async def main():
# 使用ExitStack统一管理所有资源的关闭
async with AsyncExitStack() as stack:
# A.插件(MCP)注入阶段 -- 允许为空
dynamic_tools = await load_mcp_tools(stack,MCP_SERVER_CONFIGS)
# B.图构建阶段
app = build_graph(available_tools=dynamic_tools)
# C.运行阶段(流式)
query = "帮我查一下杭州西湖附近的酒店"
await run_agent_with_streaming(app,query)
if __name__ == '__main__':
asyncio.run(main())3. 运行效果
当你运行 mcp_main.py时,你会看见控制台输出了我们预想的完美交互:
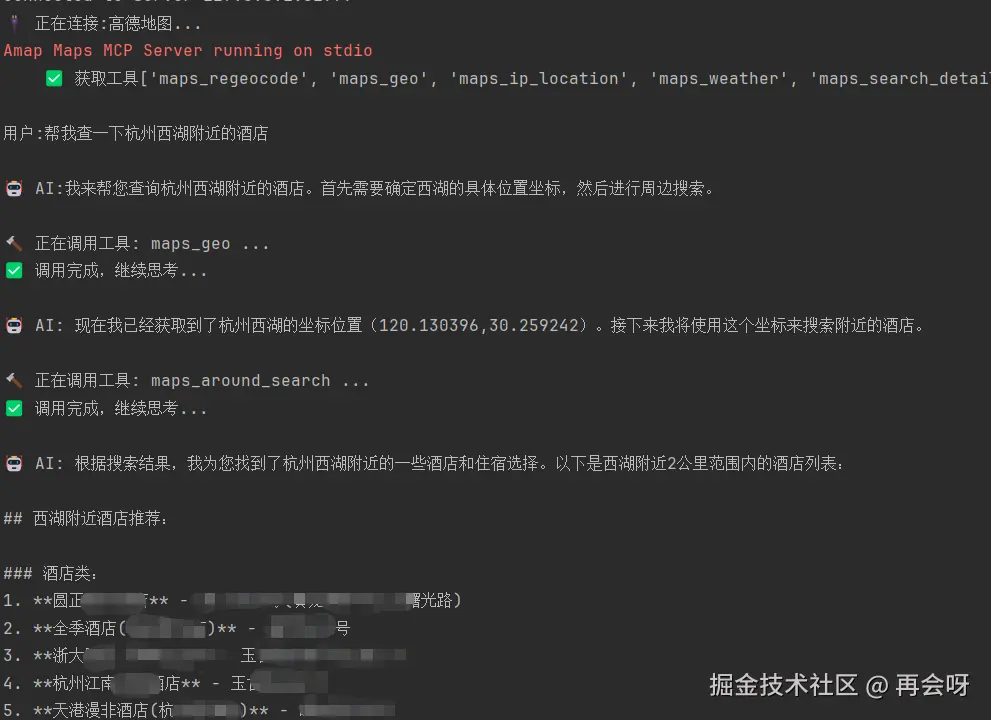
运行成功。
总结、
至此,我们的 MCP 客户端基础篇正式完结,让我们回顾一下这段旅程:
P1:用GUI首次连通一个MCP服务器
P2:讲明五大工程地基
P3:完成MCP连通的最小实现
P4:构建Client与Bridge,实现底层链接与 Schema 的自动转换
P5:引入全链路流式,解决了 IO 延迟带来的体验问题
P6:将所有组件组装成了一个通用的 Agent 架构。
现在,你手中不仅仅是一段代码,而是一个MCP驱动的Agent框架,通过修改 MCP_SERVER_CONFIGS ,你可以让Agent无缝接入数据库、文件系统、地图服务等,轻松扩展你的 Agent 能力。
预告 :11 篇 《MCP 进阶篇》
Stdio 虽好,但只能本地单机 运行。如果我想构建一个给全团队使用 的共享工具库,或者我的Agent部署在Vercel这种无状态云环境------也就是每次请求都是全新实例,无法启动子进程------就会遇到问题。
下一篇我们将从"使用者"升级为"开发者",学习如何构建支持Streamable HTTP的企业级 MCP Server,实现跨机器、跨团队的通用 Agent。