2025 年 4 月,Meta 正式发布了 LLaMA 4 系列的首批两款模型。
这两款模型模型分别是:LLaMA 4 Scout 与 LLaMA 4 Maverick,均采用了 专家混合架构(Mixture-of-Experts, MoE)。
据 Meta 表示,这是首次有 LLaMA 模型实现 文字与图像的统一处理能力,具备真正意义上的多模态理解。
据悉,在训练过程中,系统最多可同时处理48 张图像 ;而在后续评估中,模型在处理多达8 张图像的输入时,亦展现出稳定而强劲的视觉理解性能。
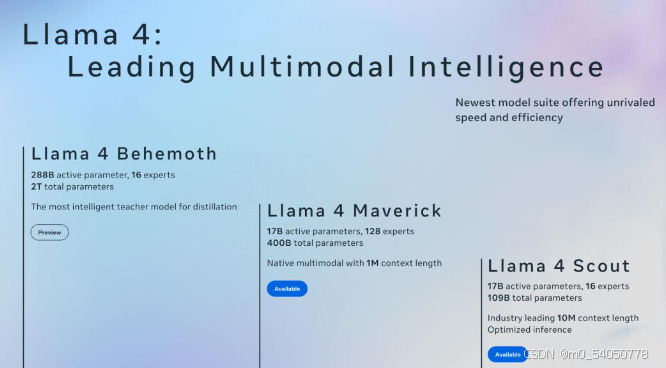
LLaMA 4 系列:有哪些新突破?
Meta 于本次 LLaMA 4 发布中亮相了两款全新模型:
1. LLaMA 4 Scout
这是一款轻量却不失强劲性能的模型,专为在单张 NVIDIA H100 GPU 上高效运行而优化,尤为适合科研人员与中小型企业应用。
拥有 1000 万词元(token)的超长上下文窗口,远远领先于多数现有开源大语言模型。
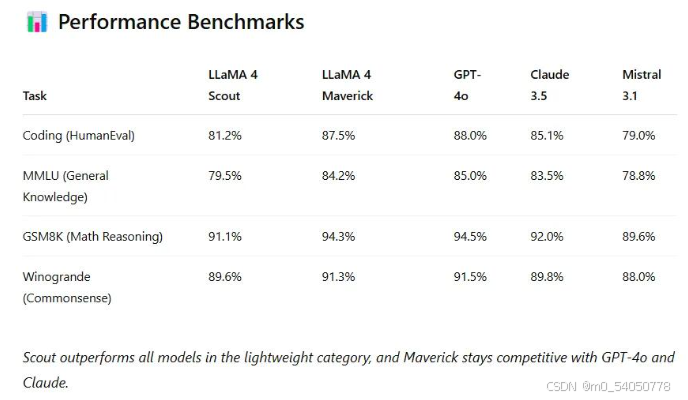
在推理、摘要生成与指令遵循等标准评测中,全面超越 Google 的 Gemma 3 与 Mistral 3.1。
2.LLaMA 4 Maverick
这款大型模型则剑指当前语言模型的重量级选手,如 GPT-4o、Claude 3.5 与 DeepSeek-V3。
精于代码生成、多跳推理与高级搜索任务。
采用 专家混合机制(Mixture-of-Experts, MoE),仅激活部分参数进行计算,在保持卓越表现的同时显著提升效率。
架构与创新亮点
两款模型皆构建于全新的 Transformer 2.0 架构之上,并在多个关键维度进行了深度优化:
- 专家混合机制(MoE):每次前向传播仅激活部分模型参数,有效降低计算开销,同时不牺牲性能。
- 词元流式处理与预测解码(Speculative Decoding):显著提升推理速度。
- 超长上下文窗口(Scout 模型支持高达 1000 万词元):可处理超大文档或多轮对话,效率倍增。
- 多语言支持全面升级:在阿拉伯语、乌尔都语、西班牙语与中文等语言上的表现有了飞跃性提升。