1. 背景与问题
大模型(LLMs)配合网络搜索功能已经展现出在深度研究任务中的巨大潜力。然而,目前的方法主要依赖两种途径:
- 人工设计的提示工程(Prompt Engineering):这种方法依靠手动设计的工作流程,表现往往不稳定且难以适应复杂场景。
- 受控RAG环境中的强化学习:在受控检索增强生成(RAG)环境中进行训练,无法捕捉真实世界交互的复杂性。
这些方法存在的关键问题包括:
- 基于提示工程的方法遵循开发者设计的预定义工作流程,行为模式严格,难以适应复杂的研究场景。
- 基于RAG环境的强化学习方法假设所有必要信息都存在于固定语料库中,忽略了真实世界网络搜索的动态特性。
研究挑战:如何开发能够在真实网络环境中进行深度研究的AI系统,克服搜索引擎限制、网络延迟、反爬虫机制和多样化网页结构等实际挑战?
以下是关于DeepReseacher相关的两篇分享:
《Search-R1: 通过强化学习训练LLM推理与利⽤搜索引擎》
《R1-Searcher:通过强化学习激励llm的搜索能⼒》
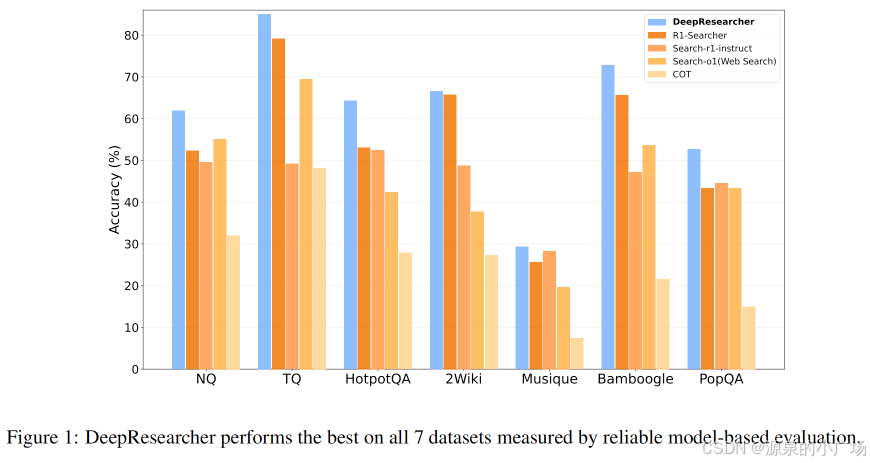
而DeepResearcher号称强于R1-Searcher以及Search-R1,如图所示:
2. DeepResearcher的工作流程
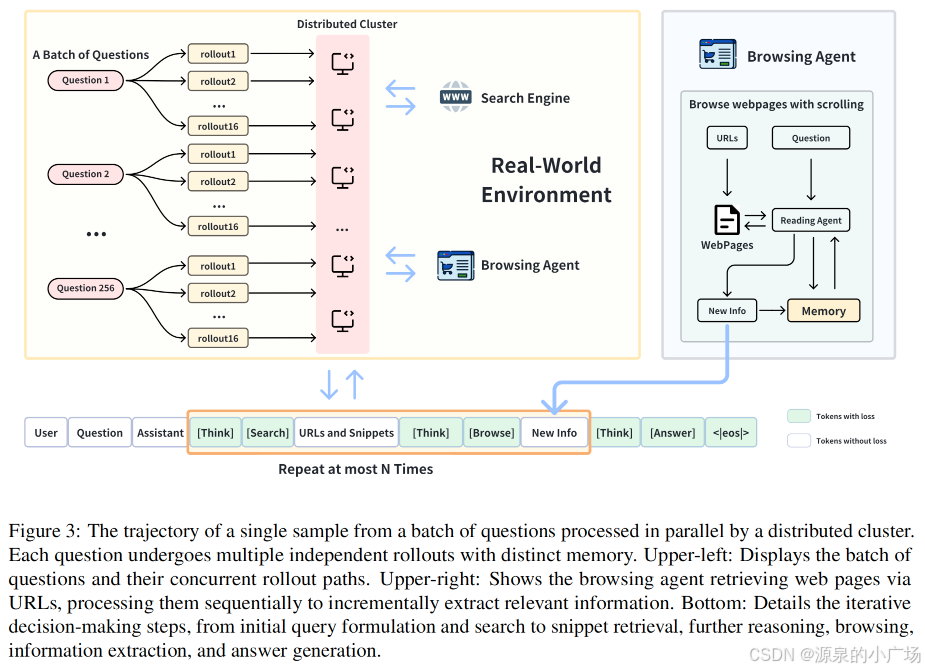
- 问题分析并生成初始搜索查询
- 执行网络搜索获取结果
- 浏览Agent从网页提取相关信息
- 主Agent分析信息,决定是否需要进一步搜索
- 迭代搜索-分析过程直至找到答案
- 生成最终答案
3. DeepResearcher方法论
DeepResearcher是通过在真实网络环境中进行端到端强化学习训练的深度研究框架,其核心特点包括:
3.1 端到端强化学习框架
- 采用GRPO(Group Relative Policy Optimization)算法,通过直接与真实网络搜索引擎交互来训练代理。
- 不依赖人类先验知识,让模型自主发现解决问题的策略。
- 使用F1分数作为主要奖励指标,引导代理持续提升性能。
2.2 多智能体架构
DeepResearcher采用专门的多智能体架构,包括:
- 主研究代理:处理问题分析和搜索策略。
- 专门的浏览代理:负责从整个网页提取相关信息。
- 智能体间协作:通过信息共享实现有效的知识提取和整合。
2.3 解决真实⽹络环境挑战

2.4 数据集构建
为确保训练过程中模型真正学会利⽤⽹络搜索⼯具,研究者采取了综合数据处理策略:
- 利⽤开放域问答数据集,包括单跳问题(NaturalQuestions、TriviaQA)和多跳问题(HotpotQA、2WikiMultiHopQA)。
- 实施严格的数据清洗和污染检测,剔除时间敏感问题、⾼度主观查询和潜在有害内容。
- 通过随机抽样检测确保模型没有记忆答案,⽽是真正学习搜索策略。
最终构建了80,000个训练样例,刻意强调多跳场景(75%的样例),更好地反映复杂信息搜索⾏为。
3. DeepResearcher与其他框架对⽐
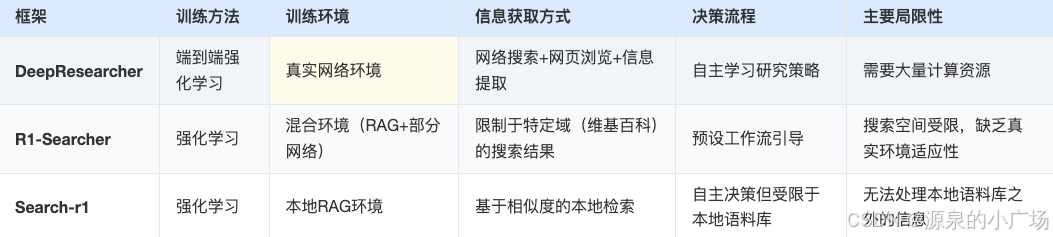
核心区别总结

4. DeepResearcher的主要优势
4.1 技术优势
- 真实环境训练:在真实⽹络环境中进⾏RL训练,能够处理复杂、动态的信息源。
- 端到端学习:不依赖⼈⼯设计的⼯作流,⽽是通过端到端训练发现⾼效策略。
- 多智能体协作:专⻔的浏览代理提取⽹⻚信息,提⾼信息获取质量。
- 分布式架构:克服API限制和⽹络延迟等技术挑战。
- 强⼤的泛化能⼒:能够适应训练领域之外的新问题。
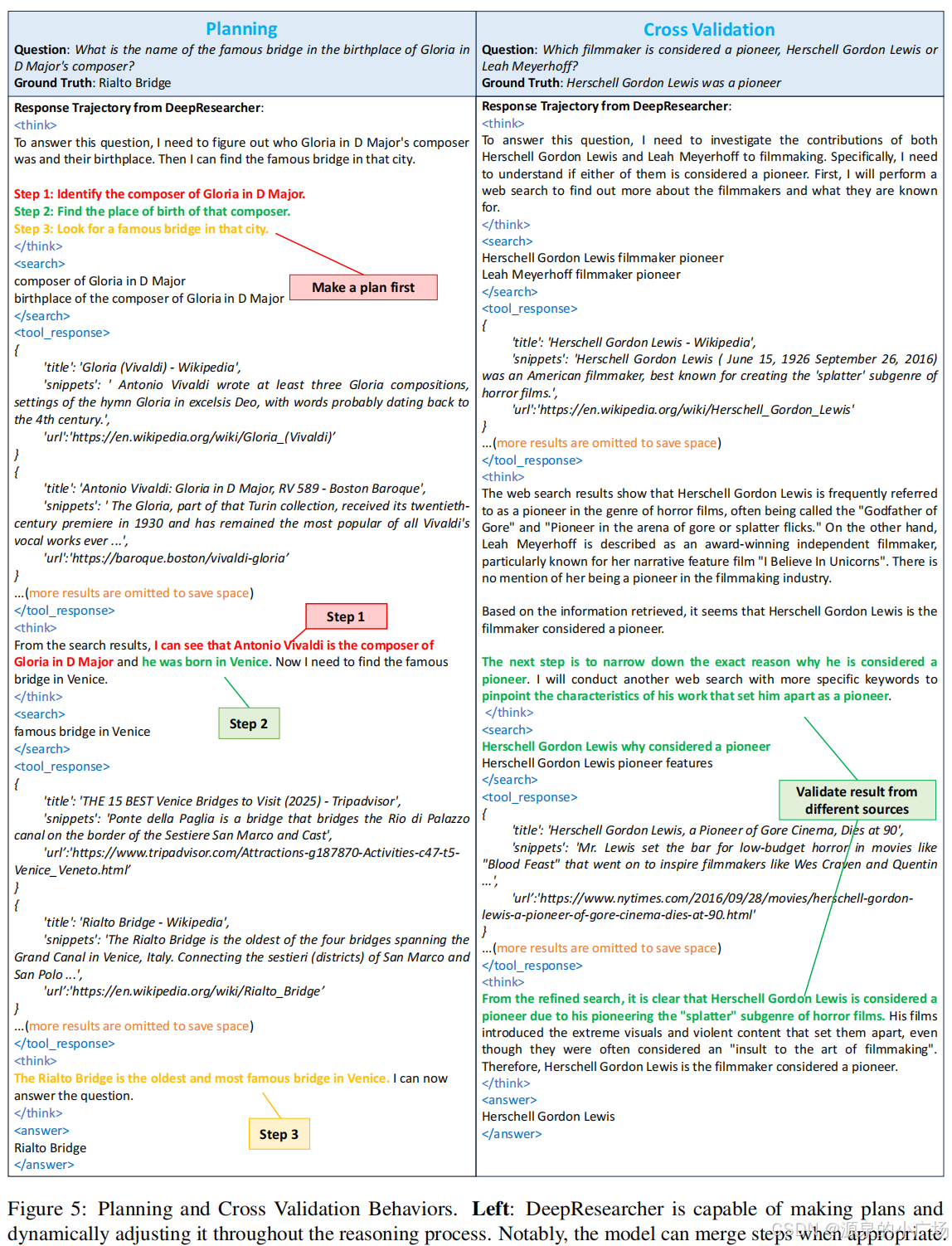
4.2 涌现的认知⾏为
通过端到端强化学习,DeepResearcher展现了多种涌现的智能⾏为:
- 规划能⼒:能够在解决多跳问题时制定初始计划并动态调整。
- 交叉验证:不⽴即采纳⾸次搜索结果,⽽是通过后续步骤验证其准确性。
- ⾃我反思:当检索信息与预期不符时,能够反思并重定向研究⽅向。
- 诚实度:当⽆法找到确定答案时能够承认局限性。
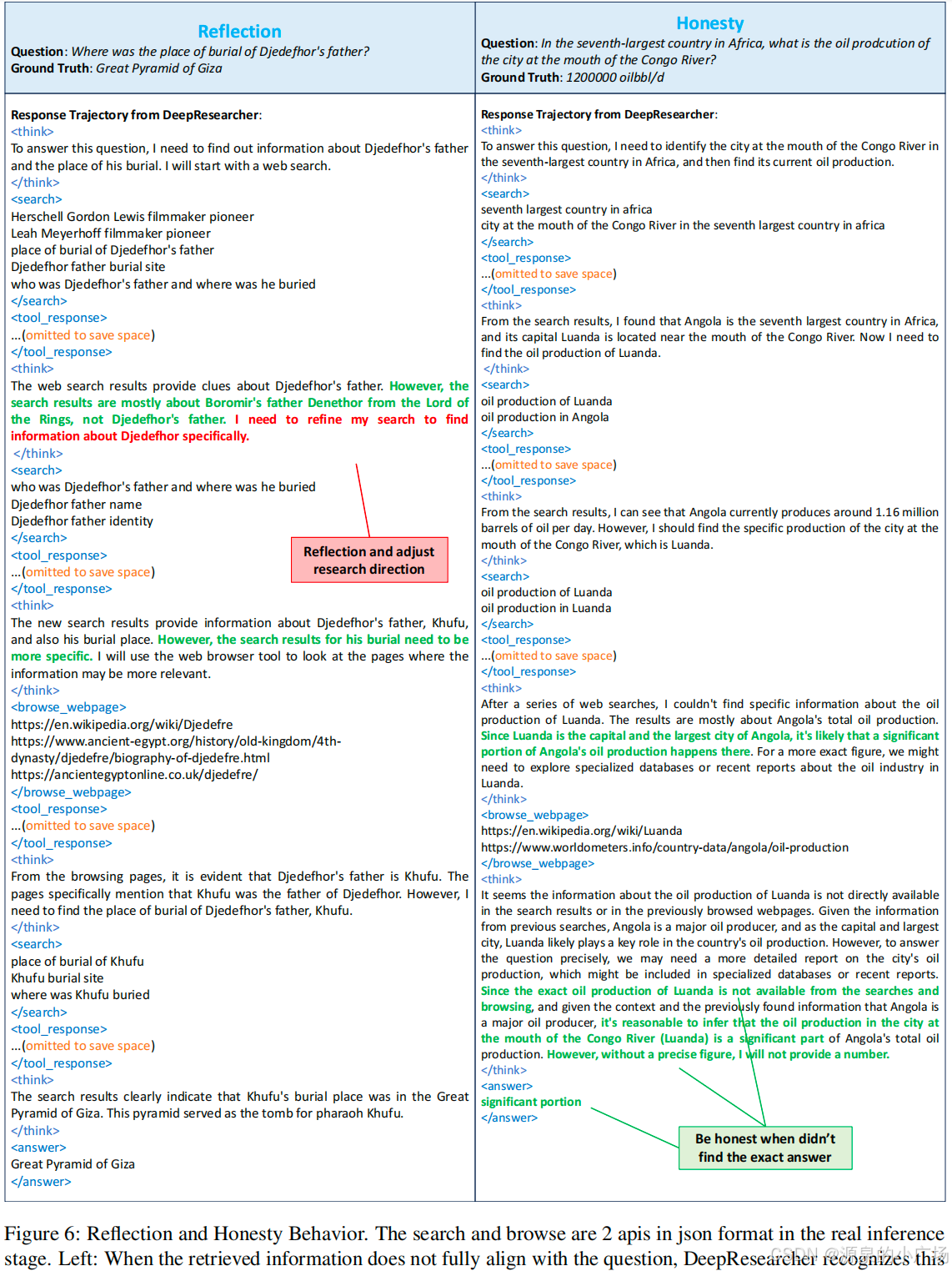
4.3 性能优势
相⽐基于提⽰⼯程的代理,DeepResearcher在研究任务完成⽅⾯提⾼了⾼达 28.9 个百分点。 相⽐基于RAG 的强化学习代理,性能提升⾼达 7.2 个百分点。 在领域内(ID )和领域外( OOD )数据集上均展现出⾊表现,证明其强⼤的泛化能⼒。 特别在需要Wikipedia 覆盖范围之外知识的 Bamboogle 基准测试中表现突出,验证了在真实世界环境训练的重要性。
5. 参考材料
【1】DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments