一、背景
PAAS1220
CRM系统
系统版本: BC Linux For Euler release 21.10
二、故障现象
grafana上kafka指标:指标消费延迟过高
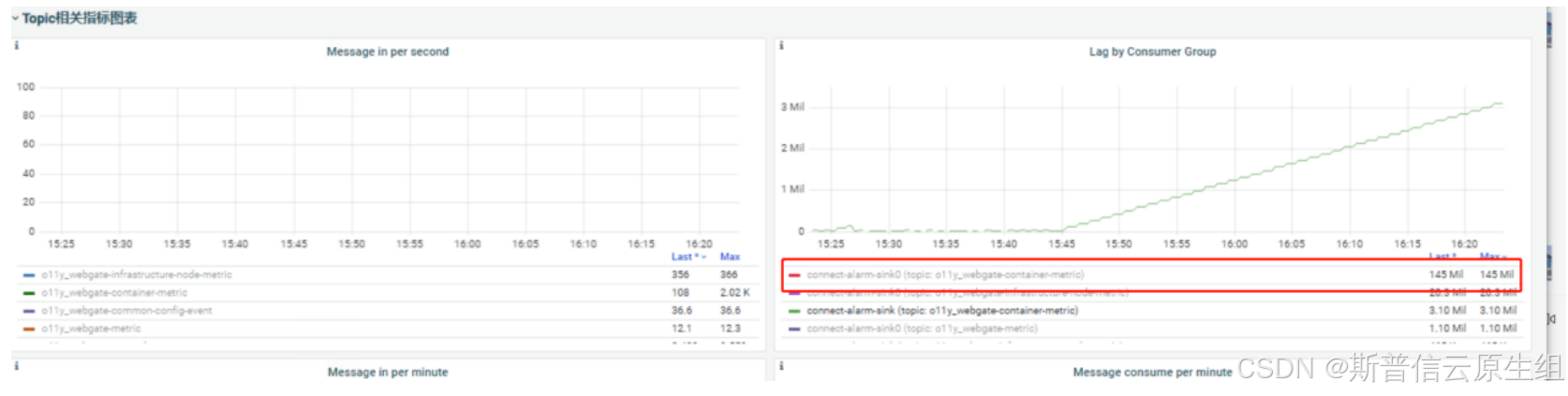
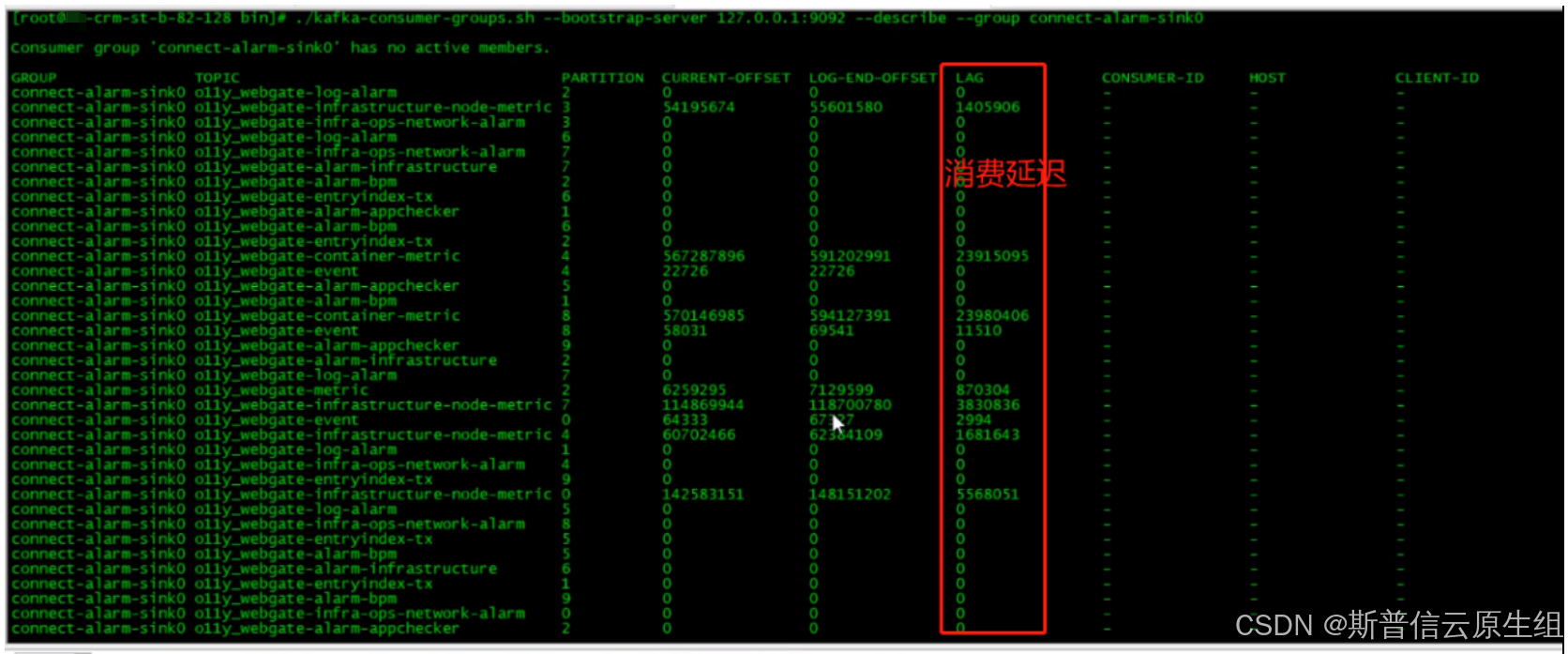
容器内部kafka消费情况:没有消费者进行消费

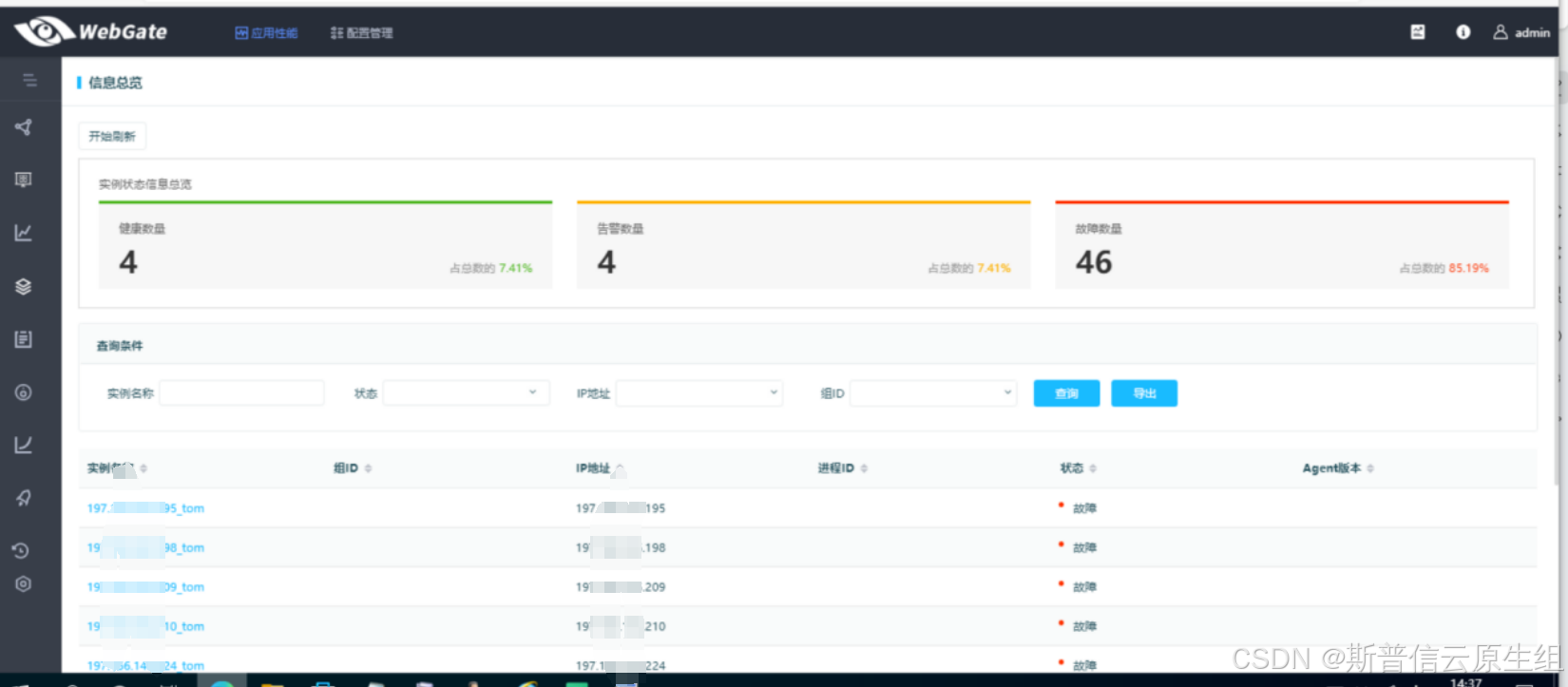
查看webgate页面:应用性能--信息总览,查看到实例全部为故障
三、处理过程
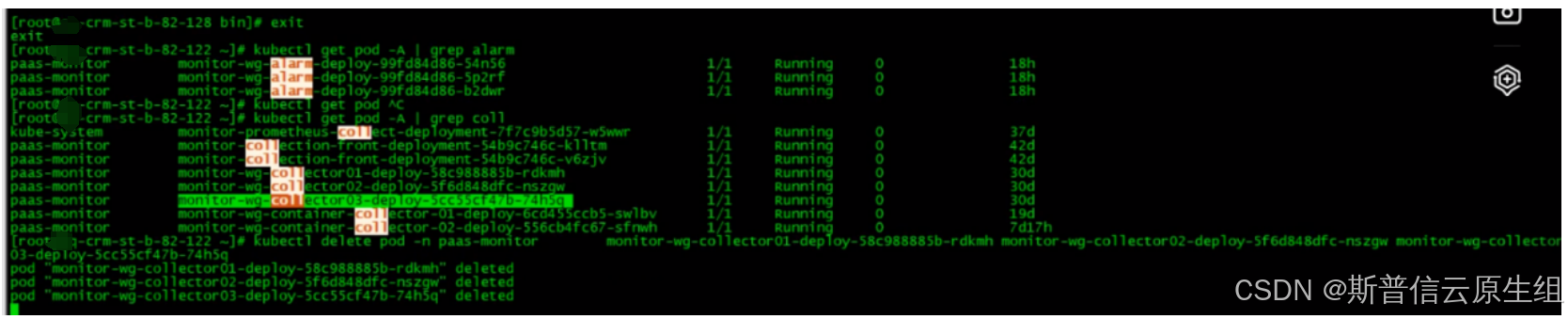
1、查看相关组件状态及日志
查看alarm,collector,并进行重启
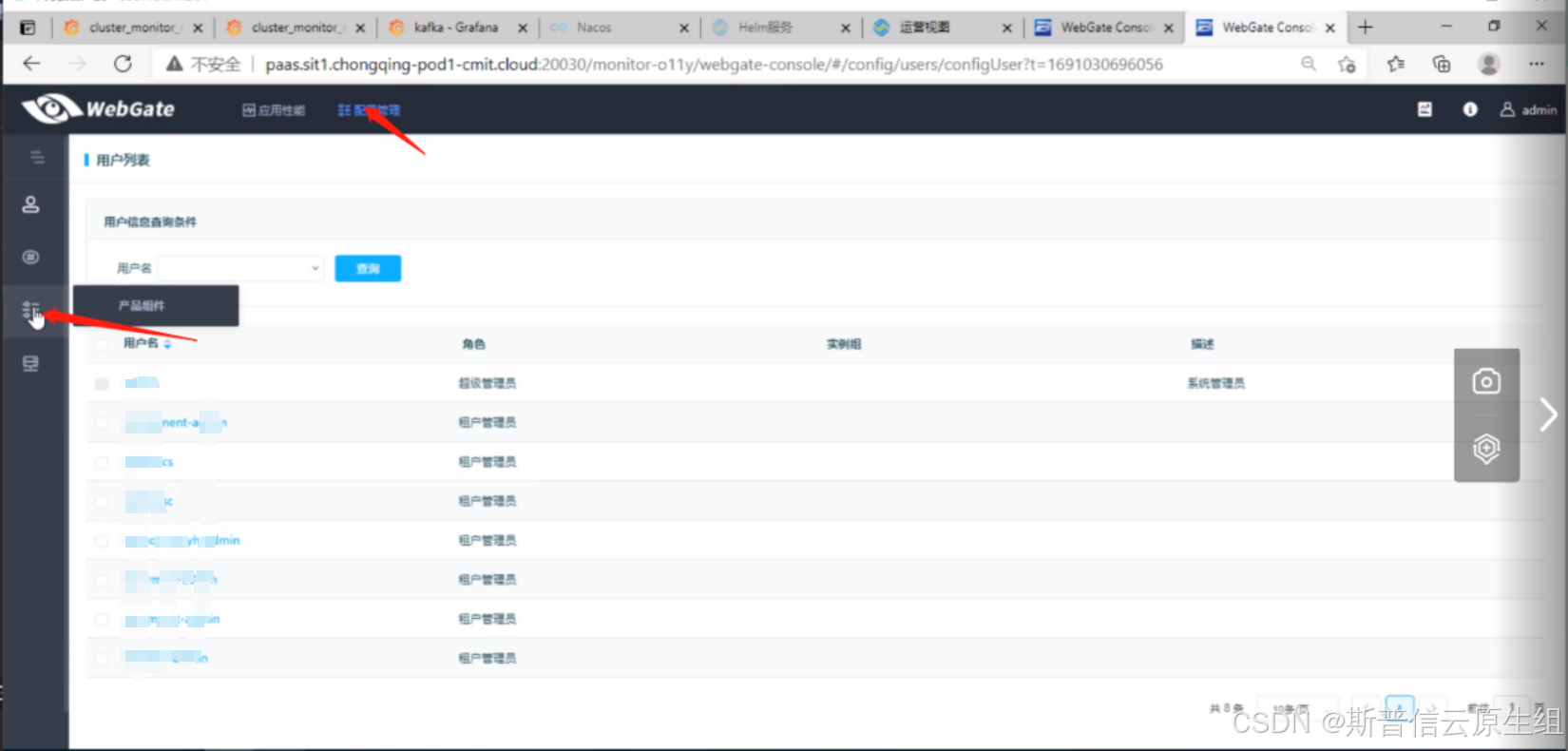
 2、查看webgate状态
2、查看webgate状态
目前此状态依旧处于故障
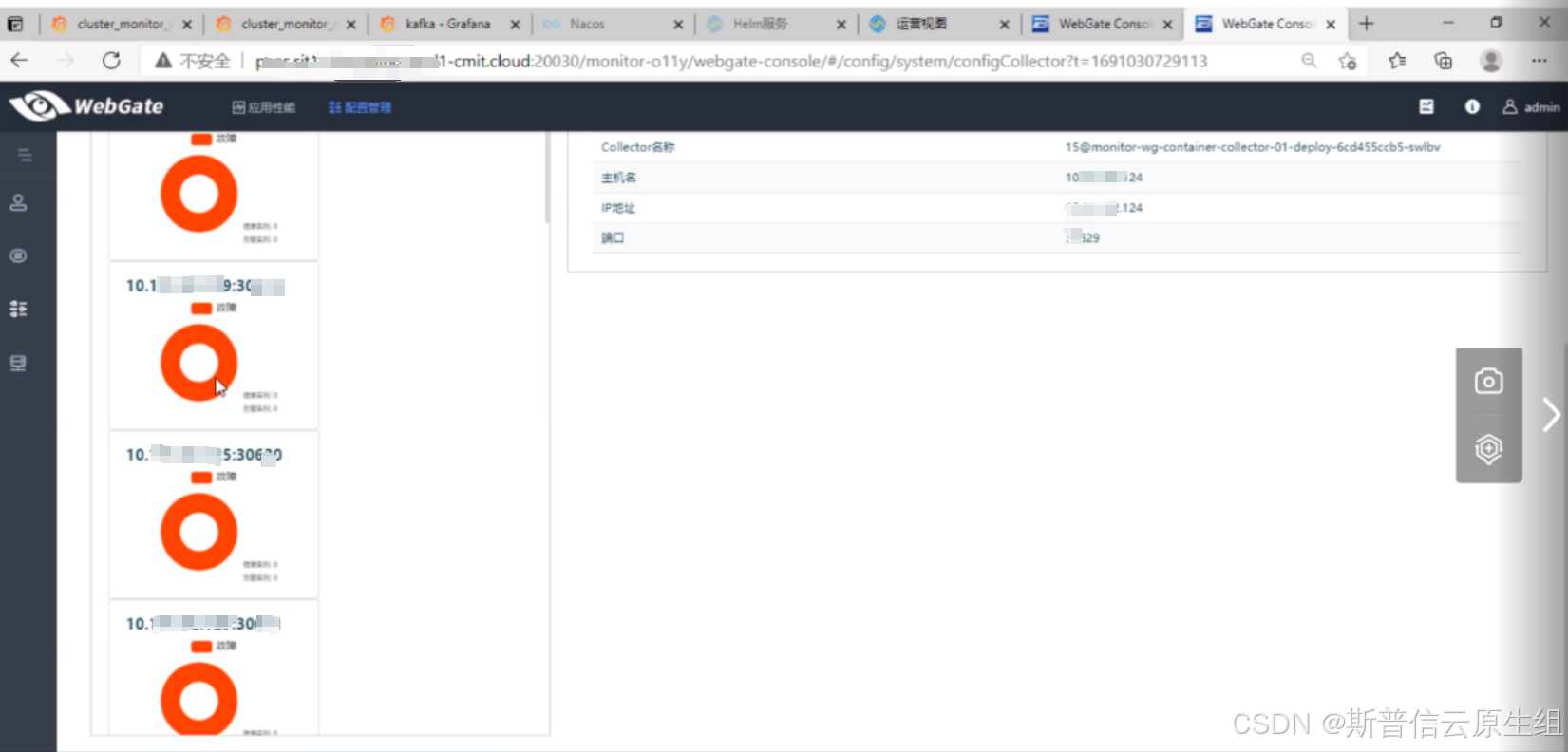 3、对比alarm配置****
3、对比alarm配置****
进入alarm容器内部查看配置文件
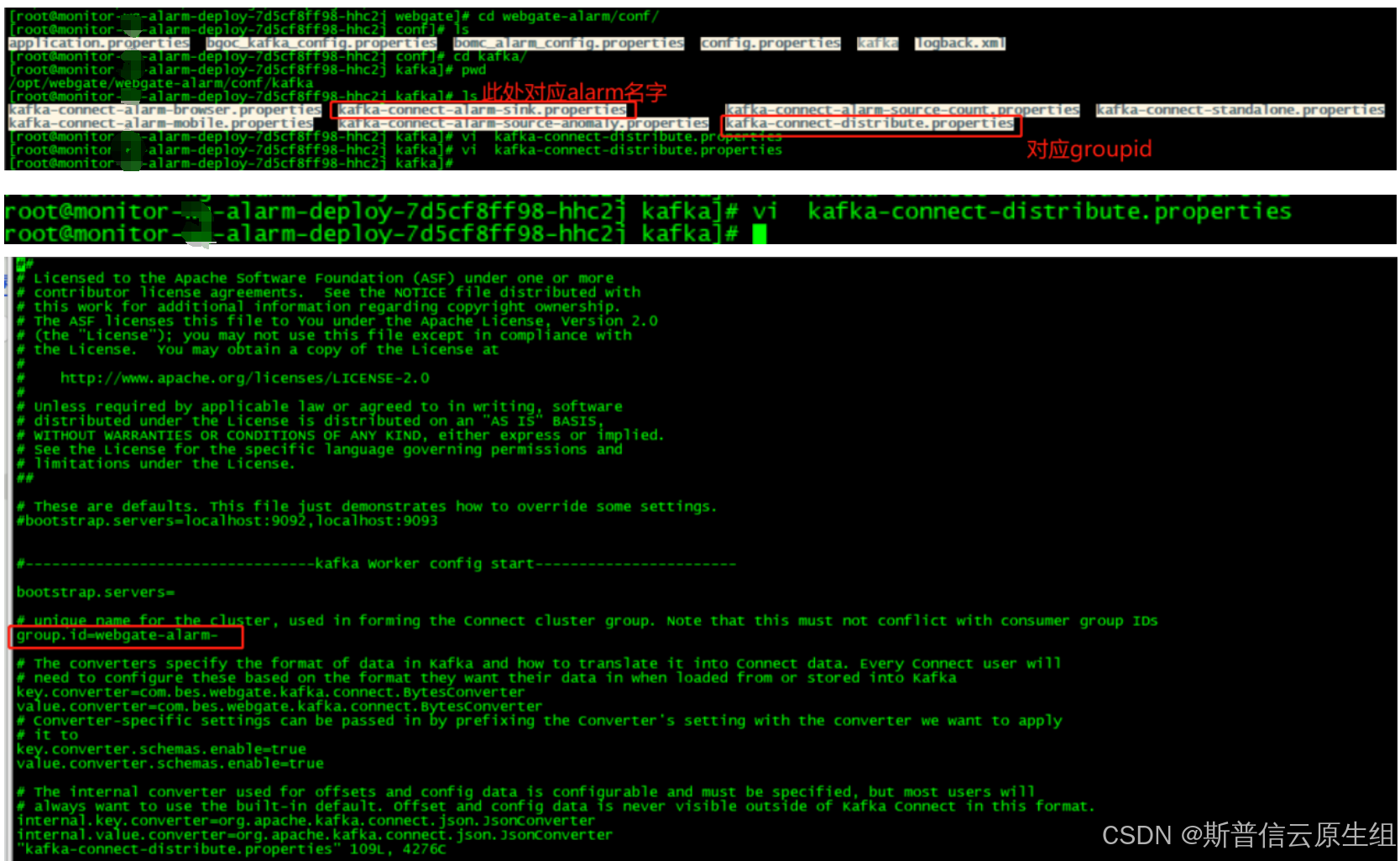
查看alarm 部署的yaml文件

* 部署的yaml str的变量无法注入容器内,alarm中,groupid不能以"-"结尾,导致以上故障,但是此变量在容器内部可以正常输出的,可以自行尝试
#此配置中name名字需要更改为其他名字,此处name=kafka 里alarm消费组名字
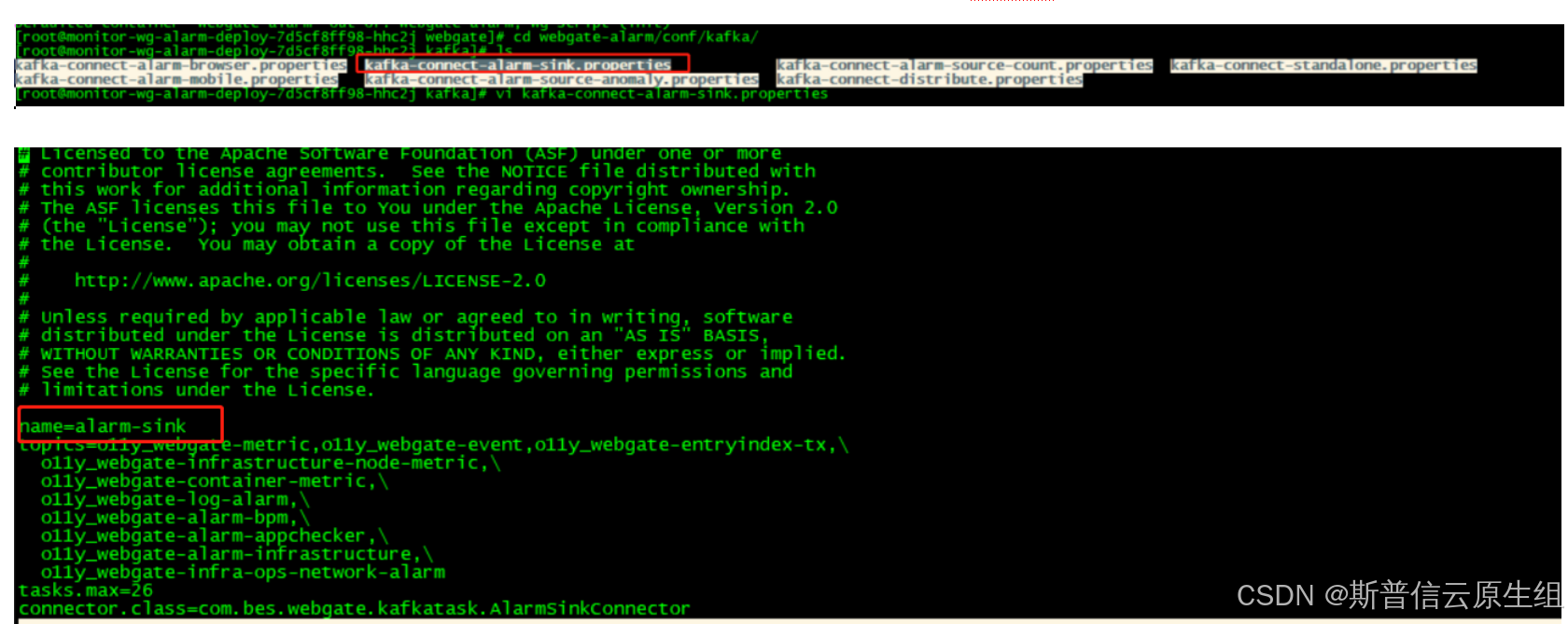
#自动提交:消费者第一次poll消息的时候会根据auto.offset.reset策略来决定从哪里开始消费,因为消费是个循环,就会不停的调用poll,至于什么时候提交呢?这是由auto.commit.interval.ms来决定的,它会定期去提交。如果出现Rebalance的情况,那么在Rebalance之后消费者则从上一次提交位移的地方继续消费。所以基于上面的特点,自动提交不会丢失消息(也就是消息都会被消费)但是会发生重复消费的情况。比如你已经消费了消息并执行了业务逻辑,但是还没有到达提交周期,这时候线程挂了,重启后还是从上次的位置消费这就出现了重复消费,当然也有可能出现消息丢失的情况。
此环境之前alarm故障过,auto.offset.reset策略是从之前开始消费,所以找不到之前数据,一直此处不会进行消费,导致消费延迟不断在增加
4、更改配置
A、使用yaml删除alarm
kubectl delete -f monitor-alarm.yaml
B、更改alarm yaml配置
按照图片位置指示将yaml复制两个副本
副本都调整为1,deployment名字后面加序号-1,-2,-3。名字不同即可
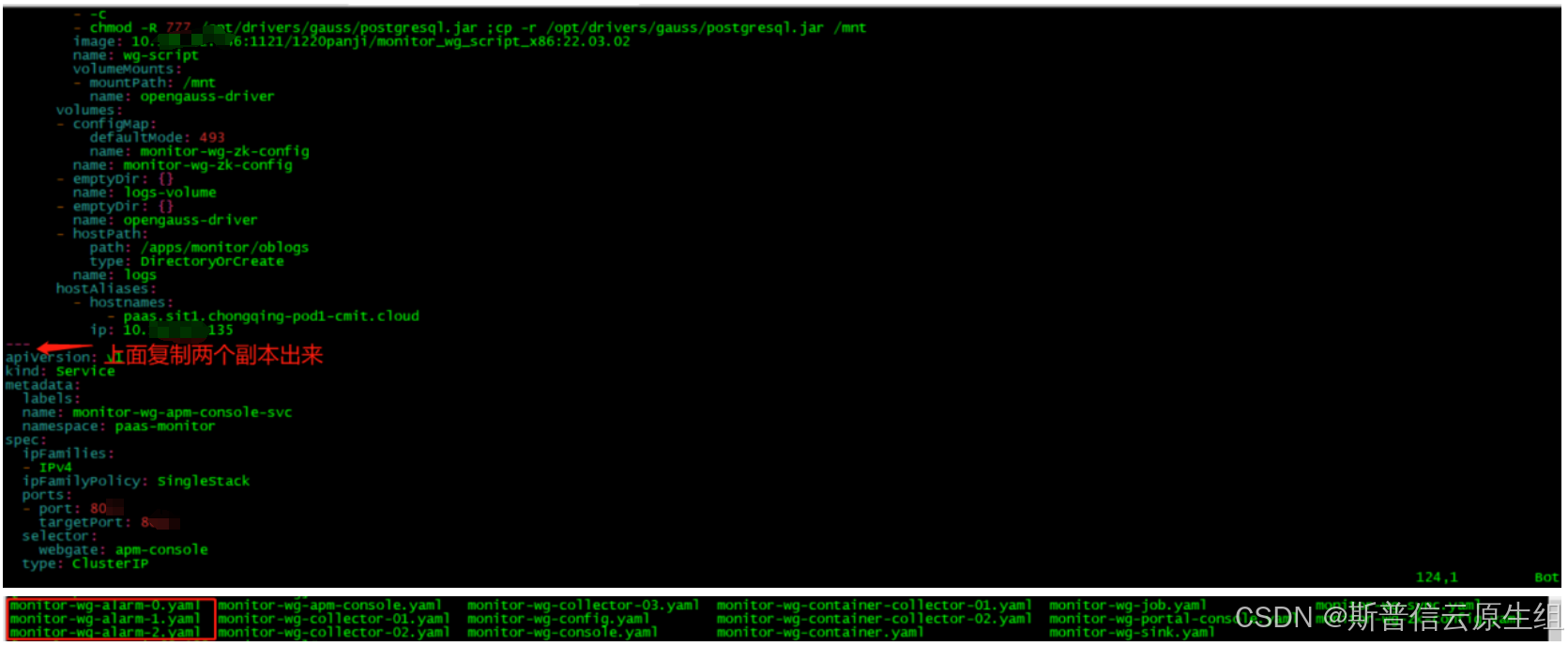
3个yaml调整副本与deploy,随机举例一个yaml
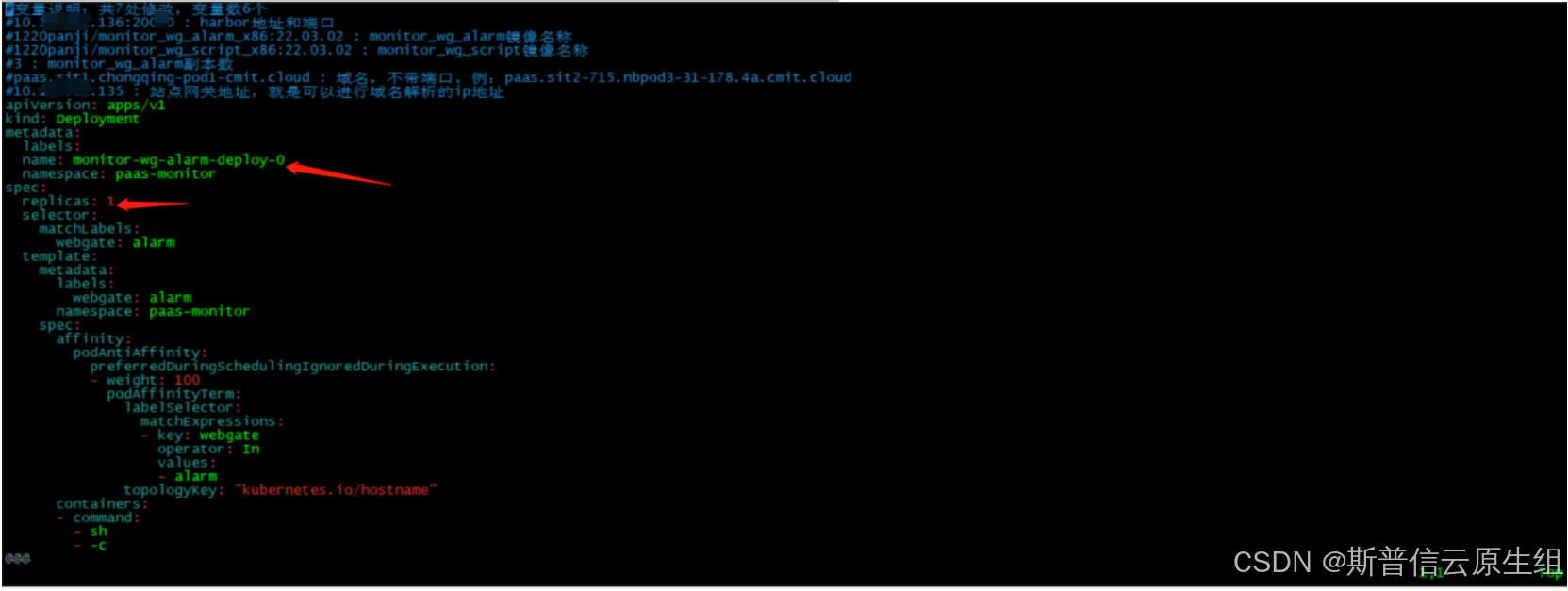 C、该更消费组名称,及groupid
C、该更消费组名称,及groupid
三个yaml对应位置,对照图片进行更改,随机列举一个,groupid不相同就行
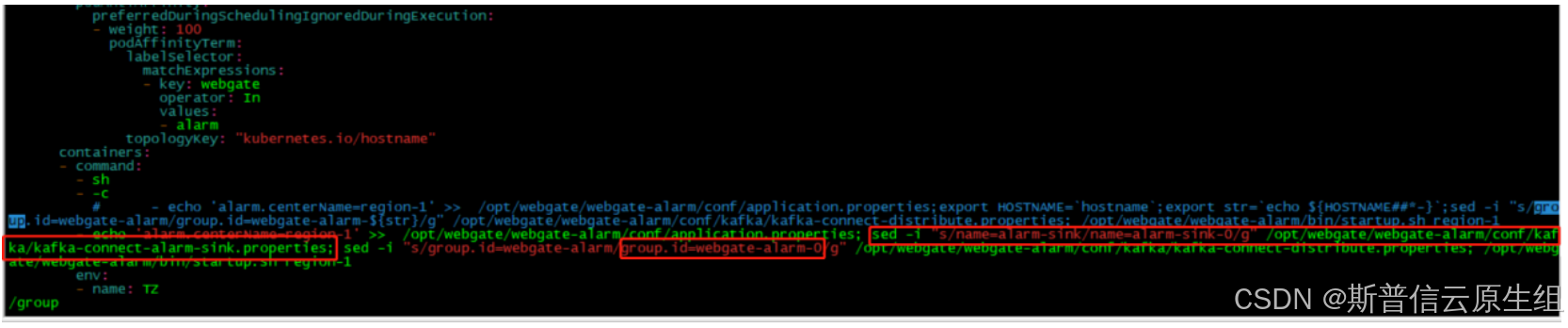
#groupID:
一个字符串用来指示一组consumer所在的组。相同的groupID表示在一个组里。相同的groupID消费记录offset时,记录的是同一个offset。 所以,此处需要注意:
(1)如果多个地方都使用相同的groupid,可能造成个别消费者消费不到的情况
(2)如果单个消费者消费能力不足的话,可以启动多个相同groupid的consumer消费,处理相同的逻辑。但是,多线程的时候,需要增加每个groupid下的partition分区数量,便于每个线程稳定读取固定的partition,提高消费能力。
5、创建alarm
kubectl apply -f *.alarm.yaml
apply后,此处需要到kafka容器内去查看是否生成alarm消费组
 6、删除之前使用的消费组
6、删除之前使用的消费组
#此处注意,如果修改了消费组必须进入kafka删除之前舍弃的消费组。
 四、验证
四、验证
1、查看kafka消费组内是否有延迟
 2、查看webgate是否有监控实例
2、查看webgate是否有监控实例