准备工作
下载地址:Download Elasticsearch | Elastic
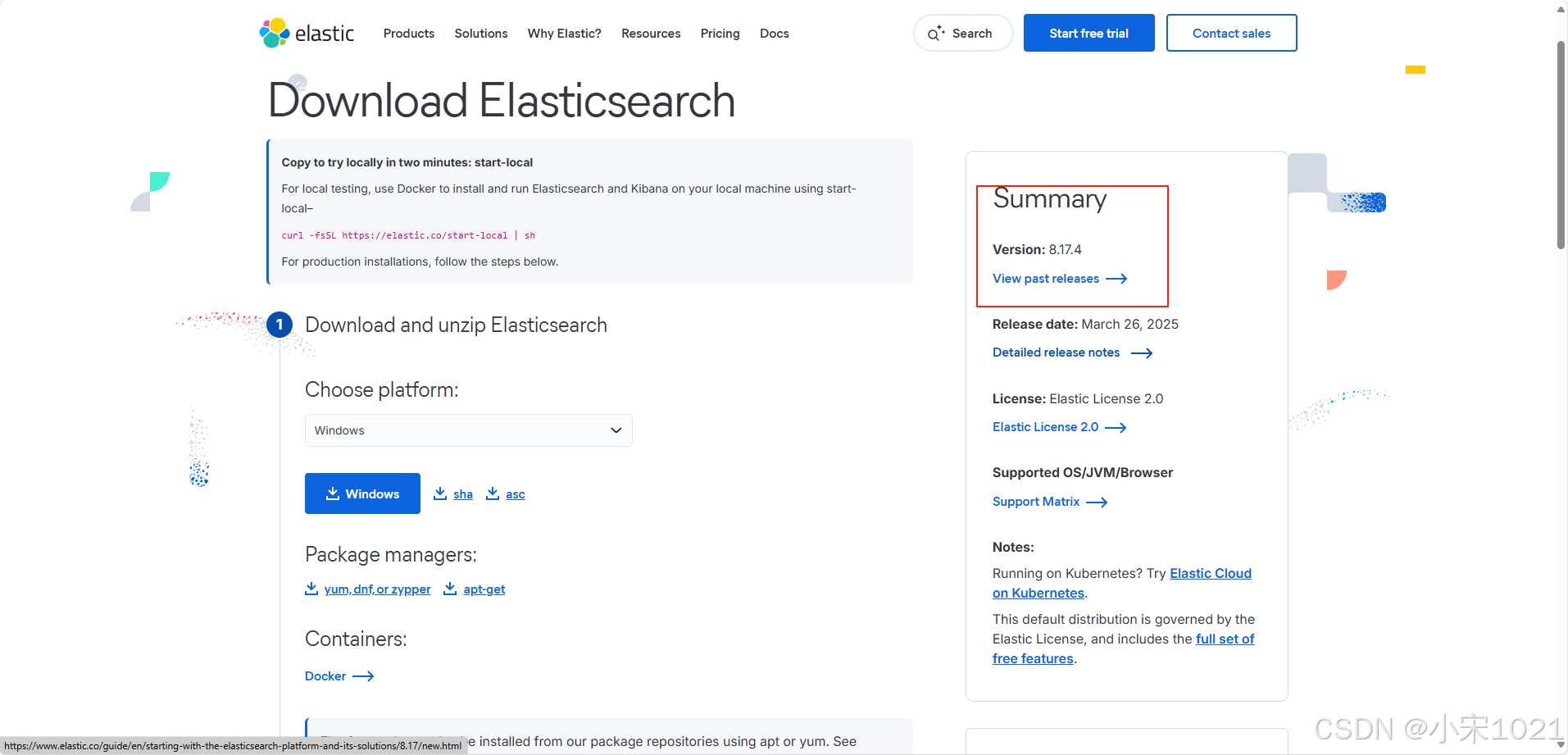
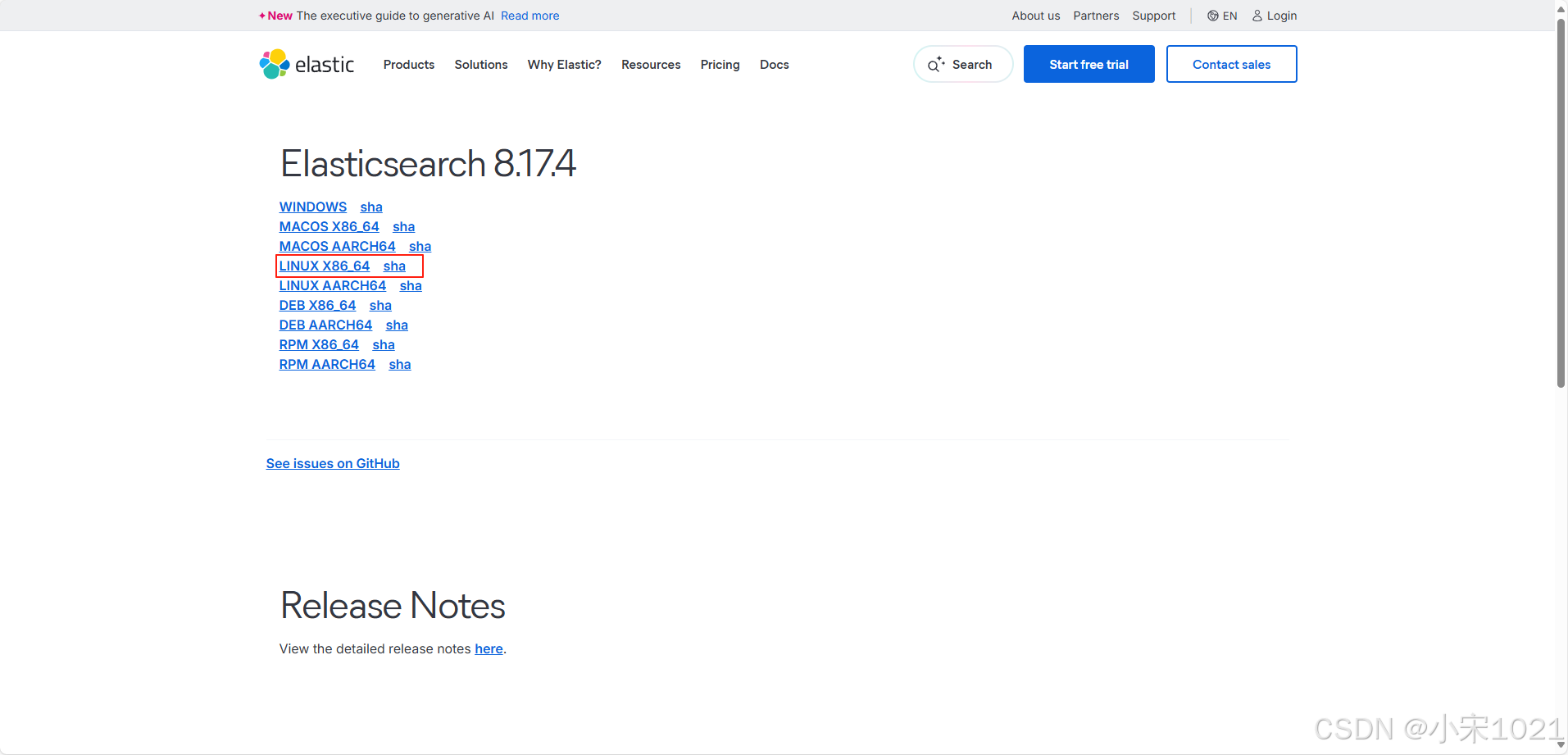
下载时需要注意es与jdk版本对应关系
ES 7.x 及之前版本,选择 Java 8
ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 18
Java 9、Java 10、Java 12 和 Java 13 均为短期版本,不推荐使用
M1(Arm) 系列 Mac 用户建议选择 ES 7.8.x 以上版本,因为考虑到 ELK 不同产品自身兼容性,7.8.x以上版本原生支持 Arm 原生 JDK
由于es和jdk是一个强依赖的关系,所以当我们在新版本的ElasticSearch压缩包中包含有自带的jdk,但是当我们的Linux中已经安装了jdk之后,就会发现启动es的时候优先去找的是Linux中已经装好的jdk,此时如果jdk的版本不一致,就会造成jdk不能正常运行,报错如下:
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME
Future versions of Elasticsearch will require Java 11; your Java version from /usr/local/jdk1.8.0_291/jre does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
注:如果Linux服务本来没有配置jdk,则会直接使用es目录下默认的jdk,反而不会报错
创建用户:
sudo useradd elasticsearch
sudo passwd elasticsearch
解压一下压缩包:
进入bin目录
cd elasticsearch-7.16.0/bin/
vim ./elasticsearch
修改elasticsearch配置
export JAVA_HOME=/usr/local/java/jdk-11.0.13/
export PATH=JAVA_HOME/bin:PATH
if -x "$JAVA_HOME/bin/java" ; then
JAVA="/usr/local/java/jdk-11.0.13/"
else
JAVA=`which java`
fi
ES为了安全不允许使用root用户启动,添加es用户并授权文件夹权限
#添加用户
useradd es
#修改/etc/sudoers文件,进入超级用户,因为没有写权限,所以要先把写权限加上
chmod u+w /etc/sudoers
#编辑/etc/sudoers文件,找到这一 行
vim /etc/sudoers
root ALL=(ALL:ALL) ALL
#添加这一行 es为新添加的用户名
es ALL=(ALL) ALL
#为了安全撤销文件的写权限
chmod u-w /etc/sudoers
#给es普通用户授理访问这个文件权限
sudo chown -R es:es /usr/local/softwore/elasticsearch/elasticsearch-7.15.2
#切换到es用户
su es
启动es
#切换到bin目录
cd bin
#启动es服务 -d表示后台运行
./elasticsearch -d #
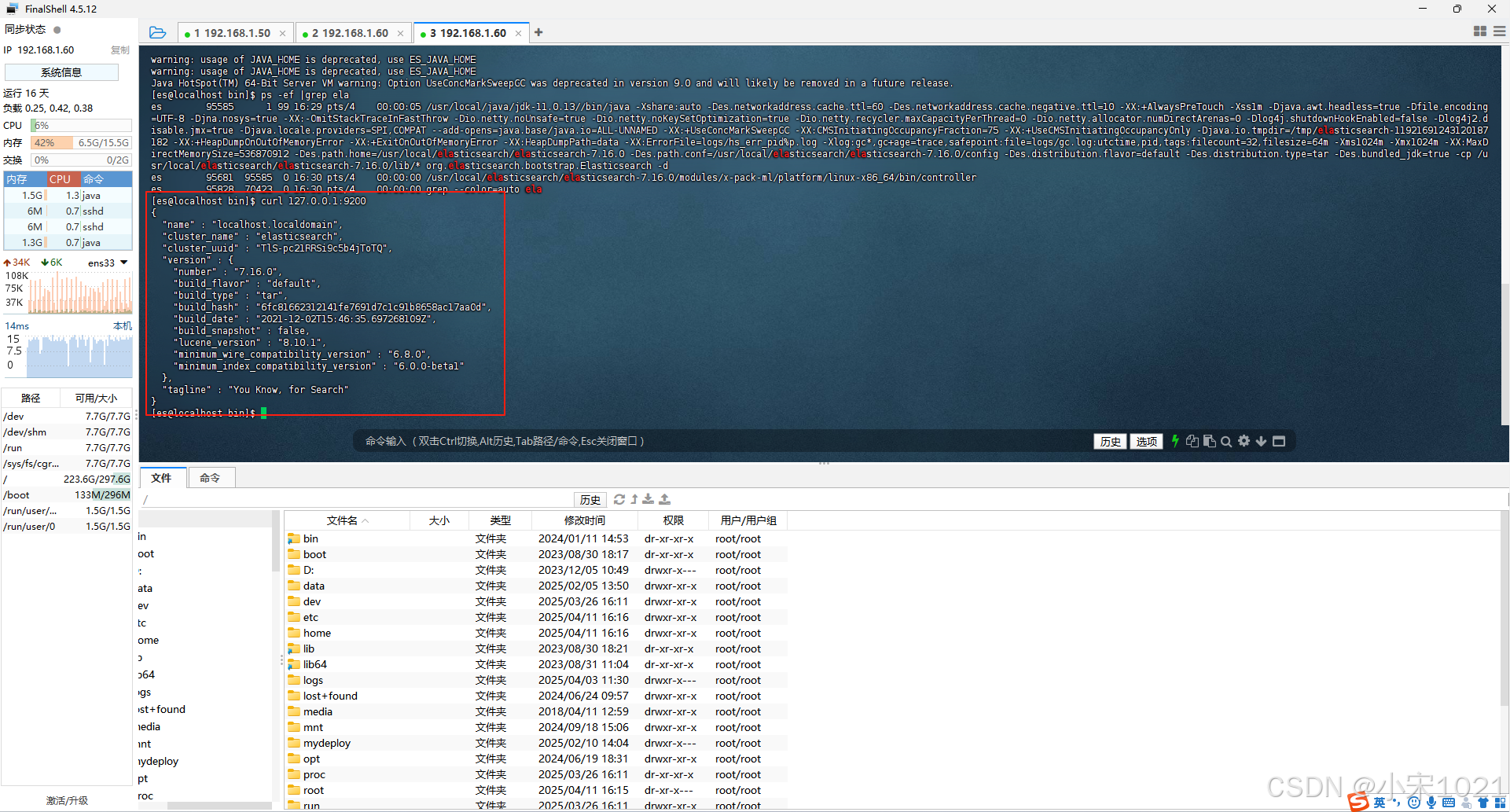
测试 看到如下信息说明启动成功
curl 127.0.0.1:9200
开启远程访问
默认ES无法使用远程连接,修改ES安装包中config/elasticsearch.yml配置文件
vim elasticsearch.yml
修改网络配置
#network.host: 192.168.0.1
改为:
network.host: 0.0.0.0