2025.4.13周报
题目信息
- 题目: Physics-informed neural networks for inversion of river flow and geometry with shallow water model
- 期刊: Physics of Fluids
- 作者: Y. Ohara; D. Moteki ; S. Muramatsu; K. Hayasaka; H. Yasuda
- 发表时间: 2024
- 文章链接: Physics-informed neural networks for inversion of river flow and geometry with shallow water model
摘要
河流在环境变化中有着重要的作用,且坝的形成水流与河床几何形态相互作用影响,因此理解二者关系对掌握河流物理过程至关重要。虽通过实际观测、模型实验、理论分析和数值模拟等方法对沙坝的形成和发展有了一定认识,但洪水期沙坝形成过程中的水流测量困难,导致对水流与河床相互作用的理解不足。本文提出利用物理信息神经网络结合浅水方程和质量守恒定律,以稀疏的流速和水位数据为训练数据,对交替沙坝上的复杂河流流量进行预测。实验结果表明,该方法能在无直接训练数据的情况下估算水深、河床高程和糙率系数,且训练数据间隔小于沙坝波长时,数据量对估算结果影响不大。
创新点
本研究创新性在于利用PINNs结合二维平面浅水方程作为约束,构建反演分析方法,以相对易测的表面流速和水位数据为训练数据,估算难以测量的水深、河床几何形状和糙率系数。同时引入基于质量守恒定律的冗余物理约束,显著提高了模型收敛性和估算精度。
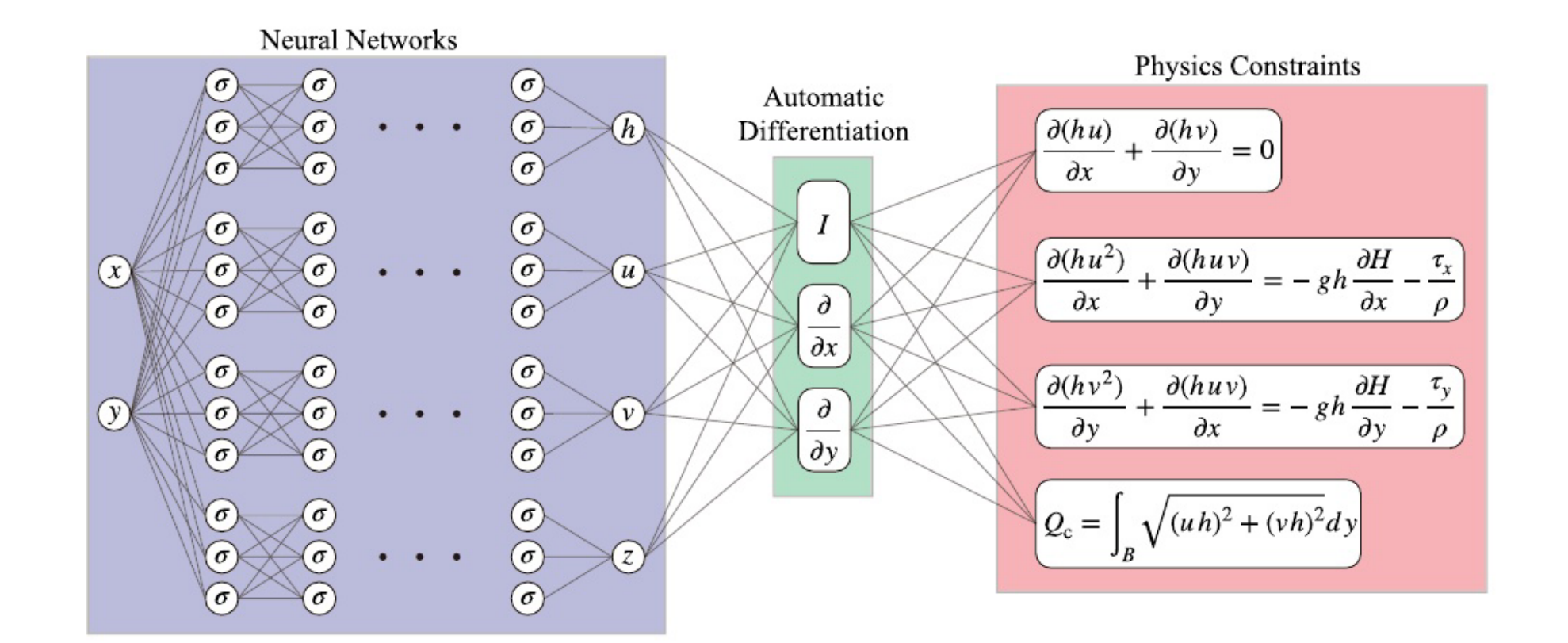
网络架构
构建框架采用全连接神经网络,将二维浅水方程和恒定流量条件作为物理约束,然后引入基于质量守恒定律的冗余物理约束,提高估计精度,最后最小化损失来优化网络参数。
使用二维浅水方程,其中包括连续性方程和运动方程,连续性方程确保水不会凭空消失或增加,运动方程是水流的加速度由重力坡度和摩擦力决定。其公式如下:
- 连续性方程 表示水流质量守恒,流入等于流出,公式为:
∂ ( h u ) ∂ x + ∂ ( h v ) ∂ y = 0 \frac{\partial (h u)}{\partial x} + \frac{\partial (h v)}{\partial y} = 0 ∂x∂(hu)+∂y∂(hv)=0
h为水面与河床的垂直距离;u,v分别为x 和 y 方向的流速;∂/∂x,∂/∂y表示沿坐标方向的变化率。 - 运动方程 描述水流受重力坡度和摩擦力驱动,公式为:
∂ ( h u 2 ) ∂ x + ∂ ( h u v ) ∂ y = − g h ∂ H ∂ x − τ x ρ \frac{\partial (h u^2)}{\partial x} + \frac{\partial (h u v)}{\partial y} = -g h \frac{\partial H}{\partial x} - \frac{\tau_x}{\rho} ∂x∂(hu2)+∂y∂(huv)=−gh∂x∂H−ρτx
∂ ( h v 2 ) ∂ y + ∂ ( h u v ) ∂ x = − g h ∂ H ∂ y − τ y ρ \frac{\partial (h v^2)}{\partial y} + \frac{\partial (h u v)}{\partial x} = -g h \frac{\partial H}{\partial y} - \frac{\tau_y}{\rho} ∂y∂(hv2)+∂x∂(huv)=−gh∂y∂H−ρτy
其中,hu2、hv 2、huv表示水流携带的动能;g为重力加速度;H为水面高度; τ y {\tau_y} τy和 τ x {\tau_x} τx分别为y与x方向的床面摩擦力;ρ为水密度。
此外,作者还加入稳态流量守恒方程,确保每个横截面流量恒定,增强物理一致性。其公式表达为:
Q c = ∫ 0 B ( u h ) 2 + ( v h ) 2 d y Q_c = \int_0^B \sqrt{(u h)^2 + (v h)^2} \, dy Qc=∫0B(uh)2+(vh)2 dy
Q c Q_c Qc为横截面流量;uh,vh分别为x 和 y 方向的单位宽度流量;B为河宽;
下面分析一下PINN的神经网络架构:
输入: 输入是空间坐标 x 和 y
输出: h h h表示预测的流深、 u u u为x方向流速、 v v v为y方向流速和 z z z则表示河床高度。
损失函数: 分为三个部分,表达形式为: L = L PDE + L ref + L Q L = L_{\text{PDE}} + L_{\text{ref}} + L_Q L=LPDE+Lref+LQ
其中包括:
- PDE损失:
L PDE = 1 N p ∑ i = 1 3 ∑ m = 1 N p ∣ e i m ∣ 2 L_{\text{PDE}} = \frac{1}{N_p} \sum_{i=1}^3 \sum_{m=1}^{N_p} |e_i^m|^2 LPDE=Np1∑i=13∑m=1Np∣eim∣2
e i m e_i^m eim表示第 i 个方程在第 m 个点的残差; N p N_p Np为PDE 采样点数。 - 数据损失:
L ref = ∑ i = 1 4 1 N i ∑ m = 1 N i ∣ U i m − U ^ i m ∣ 2 L_{\text{ref}} = \sum_{i=1}^4 \frac{1}{N_i} \sum_{m=1}^{N_i} |U_i^m - \hat{U}_i^m|^2 Lref=∑i=14Ni1∑m=1Ni∣Uim−U^im∣2
N i N_i Ni第 i 个变量的测量点数; U i m U_i^m Uim为第i个变量的第m个测量值(变量指的是u,v,h,H)。 U ^ i m \hat{U}_i^m U^im则是预测值。 - 流量损失:
L Q = 1 N q ∑ i = 1 N q ∣ Q ^ i − Q ref ∣ 2 L_Q = \frac{1}{N_q} \sum_{i=1}^{N_q} |\hat{Q}i - Q{\text{ref}}|^2 LQ=Nq1∑i=1Nq∣Q^i−Qref∣2
N q N_q Nq为流量采样截面数; N c N_c Nc为每个截面的离散点数; Q i Q_i Qi为第 i 个截面的预测流量; Q r e f Q_{ref} Qref为参考流量;
实验
本文围绕利用物理信息神经网络(PINNs)对交替沙坝上的河流流量和几何形状进行反演分析展开研究,以下是按逻辑顺序对实验结果或数据分析结果的概述:
-
平面比较参考值和预测值
尽管未直接使用训练数据,但底部高程z和流动深度h的预测值与参考值相比呈现出合适的分布,验证了 PINN 方法利用物理原理推断隐藏变量的有效性。
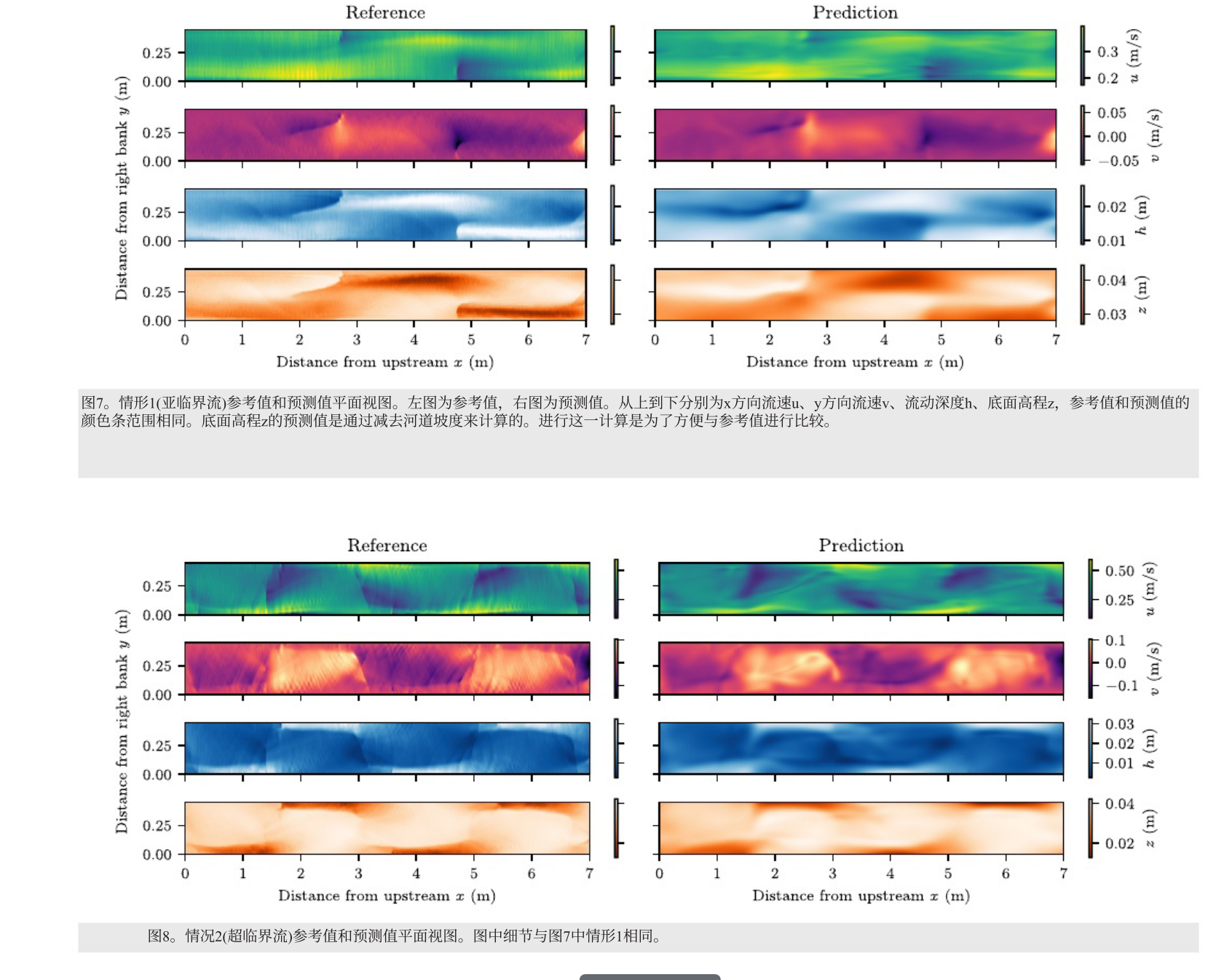
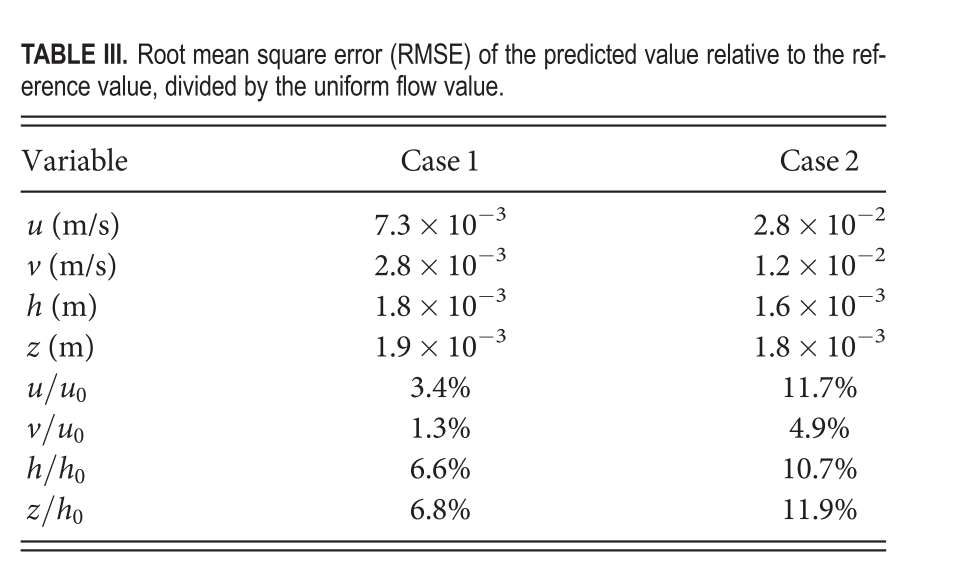
在case 1 中,未利用训练数据得到的 z 和 h的 RMSE 约为均匀流深度 h 0 h_0 h0的 7%,与使用训练数据学习得到的流速u的 RMSE相当。case 2 中,z和h的 RMSE 约为 h 0 h_0 h0的 10%,与使用训练数据时 u / u 0 u/u_0 u/u0的 RMSE 相近。
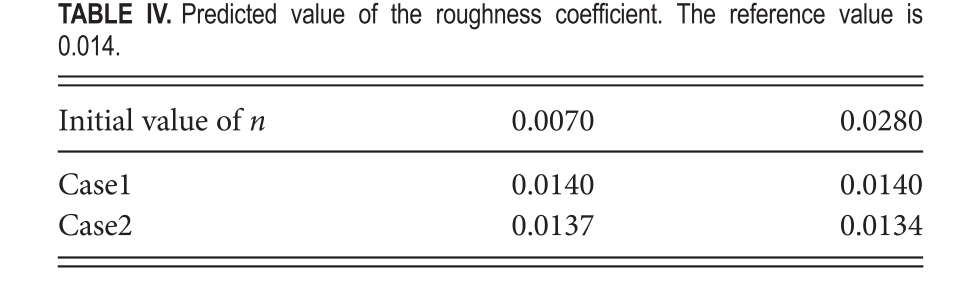
案例 1 中,粗糙度系数初始值为 0.007 和 0.028 时的预测值都与参考值 0.014 一致;case 2 中估计的粗糙度系数有误差。
-
纵向比较参考值和预测值
case1中所有变量的参考值和预测值的纵向分布总体匹配。对于使用稀疏训练数据的u和 v,估计值合适,包括突变点。但未使用训练数据间接估计的 z 和 h在某些位置误差较大,特别是右岸纵向分布的下游部分,可能是由于生成训练数据的数值模拟中,下游边界条件设置不当影响了结果。
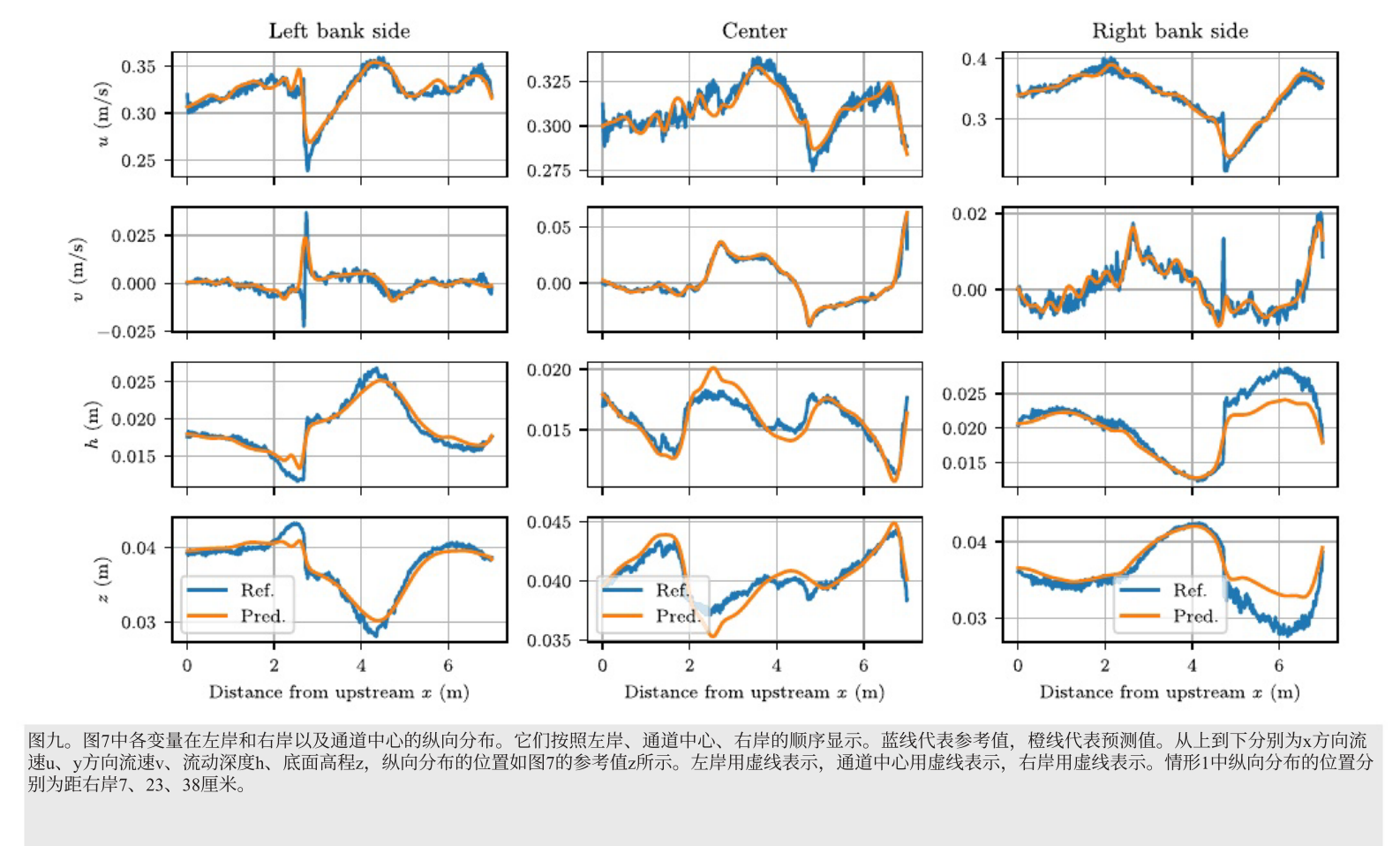
参考值和预测值的分布整体一致。与案例 1 相比,案例 2 的训练数据包含更多高波数分量,有过拟合倾向,但频谱偏差抑制了高波数分量的学习,有助于减轻过拟合,提高反演分析对噪声的鲁棒性。
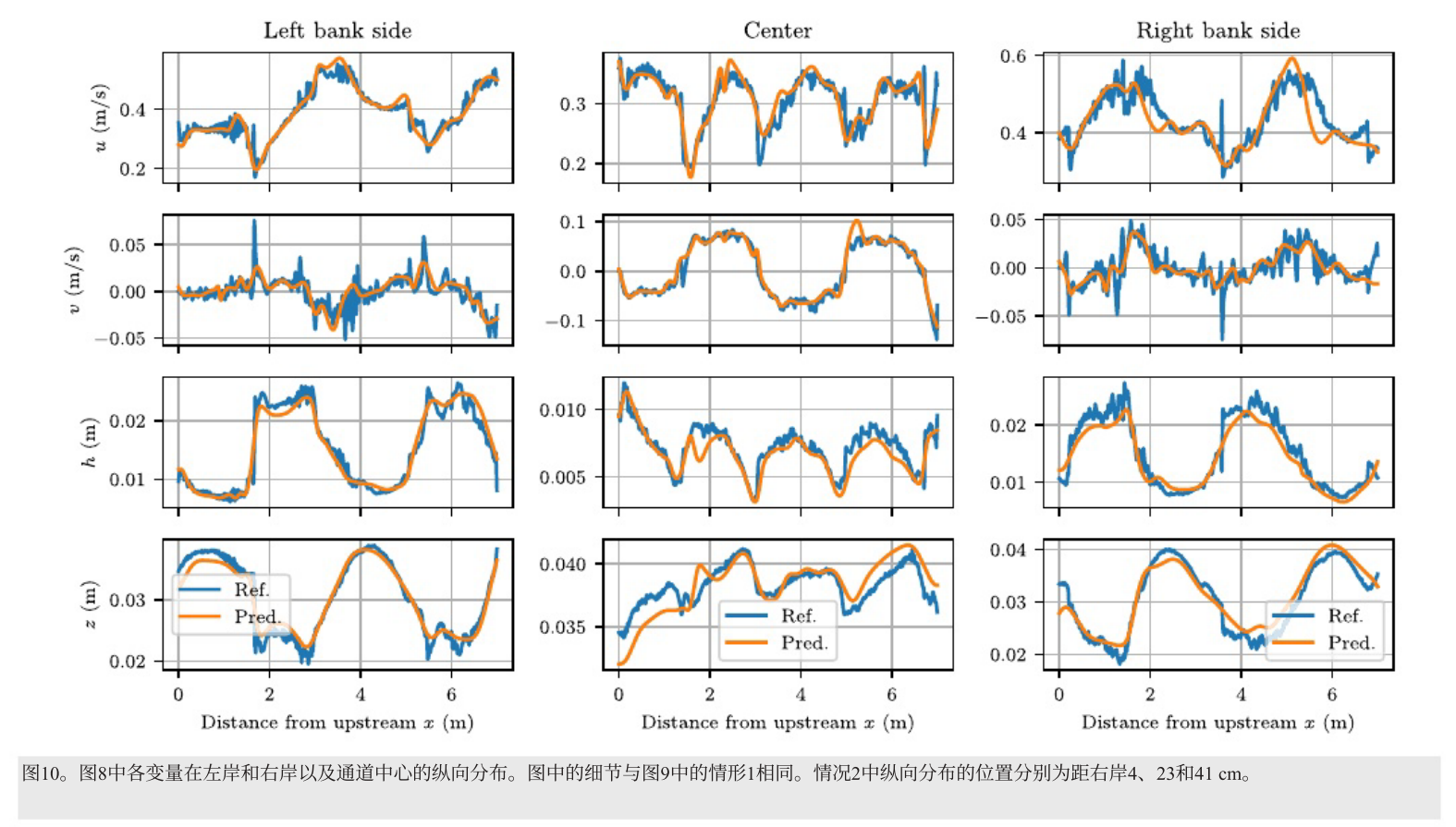
-
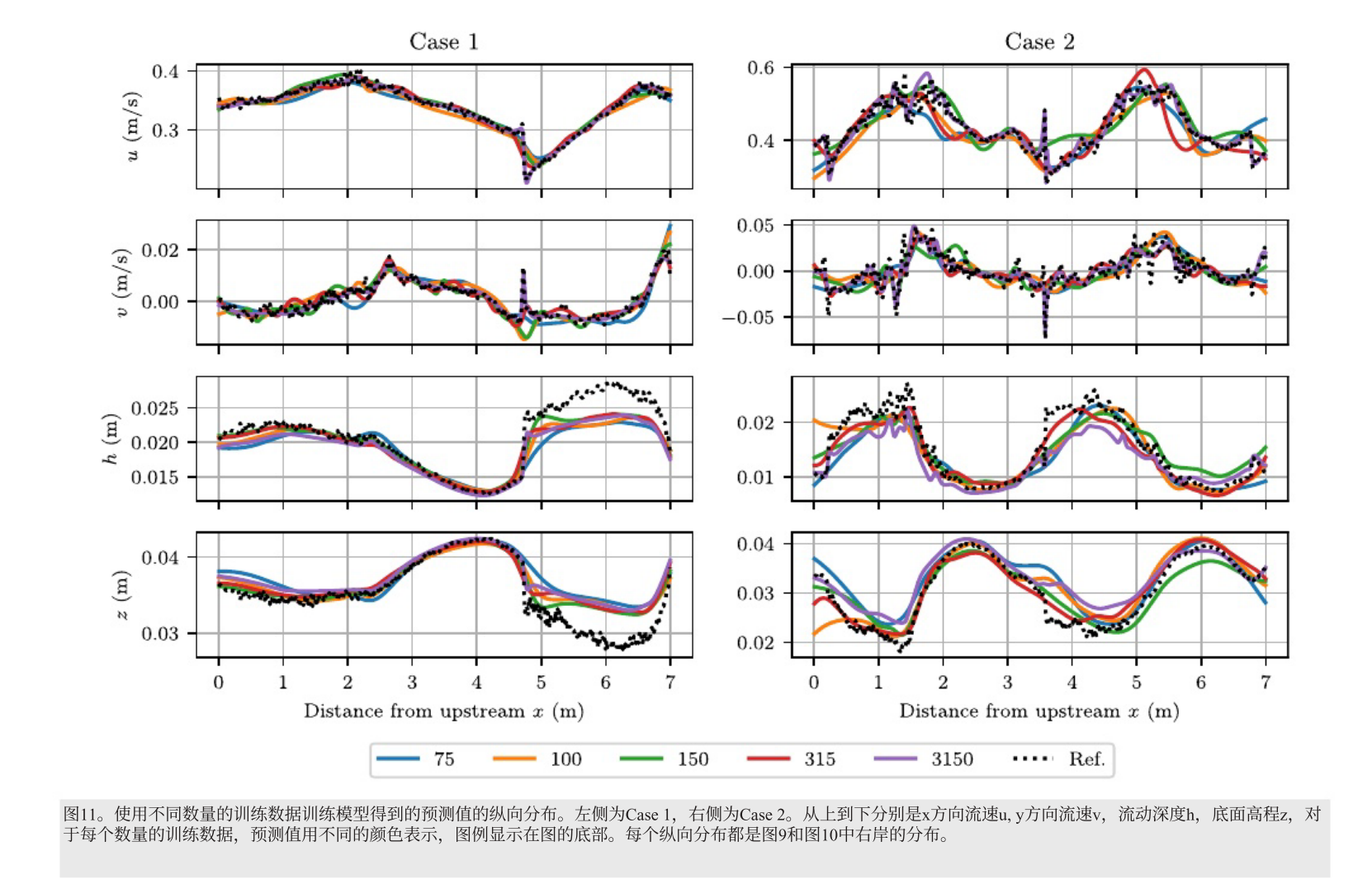
训练数据量增减对结果的影响
case 1 和case 2 的预测值在不同训练数据量下没有显著差异,表明只要训练数据间隔小于沙坝波长,就可以估计水力变量,不一定需要大量训练数据。训练数据越多,u和v的准确性越高,但间接估计的h和z的准确性提升程度小于u和 v,说明在不使用直接训练数据的情况下,这种方法的准确性存在一定极限。
-
物理约束在河流流量中的作用
排除恒定流量约束 L Q L_Q LQ后,只有case 1 的正向分析训练出的模型在物理上合理,其他情况下流量深度的预测值分布明显不合适,不仅分布不合理,数值大小也不可信。在case 1 中,包含 L Q L_Q LQ 时其他变量的 RMSE 小于排除 L Q L_Q LQ 时的 RMSE,说明冗余物理约束不仅有助于学习收敛,还能提高估计准确性。

论文代码如下:
python
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
class PINN(nn.Module):
def __init__(self, num_hidden=8, dim_hidden=20):
super(PINN, self).__init__()
# 输入层:2个维度 (x, y)
# 输出层:4个变量 (u, v, h, z),粗糙系数 n 为可训练参数
self.net = nn.Sequential(
nn.Linear(2, dim_hidden),
nn.Tanh(),
*[nn.Sequential(nn.Linear(dim_hidden, dim_hidden), nn.Tanh()) for _ in range(num_hidden - 1)],
nn.Linear(dim_hidden, 4) # 输出 u, v, h, z
)
# Manning 粗糙系数 n 作为可训练参数,初始值设为 0.03
self.n = nn.Parameter(torch.tensor(0.03))
def forward(self, x, y):
# 将 x, y 拼接为输入张量
xy = torch.stack([x, y], dim=-1)
# 通过神经网络预测 u, v, h, z
preds = self.net(xy)
u, v, h, z = preds[:, 0], preds[:, 1], preds[:, 2], preds[:, 3]
# 确保流深 h 非负
h = torch.relu(h)
return u, v, h, z
# 浅水方程
def shallow_water_equations(model, x, y, g=9.81):
# 将 x, y 设置为需要梯度的张量
x = x.requires_grad_(True)
y = y.requires_grad_(True)
# 预测
u, v, h, z = model(x, y)
# 水面高度 H = z + h
H = z + h
# 计算偏导数
hu_x = torch.autograd.grad(h * u, x, grad_outputs=torch.ones_like(h * u), create_graph=True)[0]
hv_y = torch.autograd.grad(h * v, y, grad_outputs=torch.ones_like(h * v), create_graph=True)[0]
huu_x = torch.autograd.grad(h * u * u, x, grad_outputs=torch.ones_like(h * u * u), create_graph=True)[0]
huv_y = torch.autograd.grad(h * u * v, y, grad_outputs=torch.ones_like(h * u * v), create_graph=True)[0]
hvv_y = torch.autograd.grad(h * v * v, y, grad_outputs=torch.ones_like(h * v * v), create_graph=True)[0]
huv_x = torch.autograd.grad(h * u * v, x, grad_outputs=torch.ones_like(h * u * v), create_graph=True)[0]
H_x = torch.autograd.grad(H, x, grad_outputs=torch.ones_like(H), create_graph=True)[0]
H_y = torch.autograd.grad(H, y, grad_outputs=torch.ones_like(H), create_graph=True)[0]
# 计算Manning 摩擦力
speed = torch.sqrt(u**2 + v**2)
tau_x = g * model.n**2 * u * speed / (h**(1/3))
tau_y = g * model.n**2 * v * speed / (h**(1/3))
# 连续性方程残差
continuity = hu_x + hv_y
# 动量方程残差(x 和 y 方向)
momentum_x = huu_x + huv_y + g * h * H_x + tau_x
momentum_y = hvv_y + huv_x + g * h * H_y + tau_y
return continuity, momentum_x, momentum_y
# 定义流量守恒约束
def flow_conservation(model, x_sections, y, Q_ref):
# 对每个横截面计算预测流量
Q_pred = []
for x_sec in x_sections:
x = torch.full_like(y, x_sec, requires_grad=True)
u, v, h, _ = model(x, y)
# 计算流量积分
q = torch.sqrt((u * h)**2 + (v * h)**2)
Q = torch.trapz(q, y)
Q_pred.append(Q)
Q_pred = torch.stack(Q_pred)
# 流量损失
return torch.mean((Q_pred - Q_ref)**2)
# 训练函数
def train(model, epochs=5000, lr=0.001):
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
x_data, y_data, u_data, v_data, H_data = generate_data()
# 物理采样点
x_pde = torch.linspace(0, 10.0, 50).repeat(20)
y_pde = torch.linspace(0, 1.0, 20).repeat_interleave(50)
# 流量参考值
Q_ref = torch.tensor(1.0)
x_sections = torch.linspace(0, 10.0, 5) # 横截面位置
for epoch in range(epochs):
optimizer.zero_grad()
# 数据损失
u_pred, v_pred, h_pred, z_pred = model(x_data, y_data)
H_pred = z_pred + h_pred
loss_data = (torch.mean((u_pred - u_data)**2) +
torch.mean((v_pred - v_data)**2) +
torch.mean((H_pred - H_data)**2))
# PDE 损失
cont, mom_x, mom_y = shallow_water_equations(model, x_pde, y_pde)
loss_pde = torch.mean(cont**2) + torch.mean(mom_x**2) + torch.mean(mom_y**2)
# 流量损失
loss_flow = flow_conservation(model, x_sections, y_pde[:20], Q_ref)
# 总损失
loss = loss_data + 0.1 * loss_pde + 0.1 * loss_flow
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.6f}, n: {model.n.item():.6f}")
if __name__ == "__main__":
model = PINN()
train(model)
x_test = torch.linspace(0, 10.0, 100)
y_test = torch.linspace(0, 1.0, 100)
X, Y = torch.meshgrid(x_test, y_test, indexing='ij')
u, v, h, z = model(X.flatten(), Y.flatten())
plt.figure(figsize=(10, 6))
plt.contourf(X, Y, h.reshape(100, 100), levels=20)
plt.colorbar(label='流深 h (m)')
plt.title('预测流深分布')
plt.xlabel('x (m)')
plt.ylabel('y (m)')
plt.show()结论
本论文应用结合浅水方程和质量守恒定律的物理信息神经网络,以稀疏流速和水位数据为训练数据。结果表明,该方法能补全稀疏流速,在无直接训练数据情况下估算水深、河床高程和糙率系数。且训练数据间隔短于沙坝波长时,数据量差异对估算结果影响不大。
不足以及展望
作者在论文的最后表示研究存在一定局限性。第一是基于浅水和稳态假设,对不满足该假设的现象估算可能不准确;第二是主要聚焦于直河道水流估算,应用于任意弯曲平面几何形状受限;
作者认为后续可以修改模型方程和约束条件,使方法适用于不满足浅水和稳态假设的现象。此外,可以将泥沙输移作为未知变量纳入PINNs框架,改进泥沙输移模型。