1.引言
针对文本处理任务,正则表达式是一项很有用的能力。比如下面这些场景:
- 输入数据校验:保障数据符合格式要求(Email,电话号码)
- 数据提取:提取模式化数据(电话号码,ID,URL)
- 文本处理:替换,清洗,格式化
- 结构化文本解析:日志,配置文件
- 安全防护:敏感信息检查,攻击特征识别
等等。这篇文章,我们来看正则表达式的方方面面。
2.正则表达式
2.1.基础语法
2.1.1.元字符
正则表达式的本质,是通过一系列特殊字符构建匹配模式,这些特殊字符分类有:定位符,通配符,量词符,逻辑符。
shell
- 定位符
^:匹配字符串开始
$:匹配字符串结尾
\b:匹配单词边界^:匹配字符串开始示例

$:匹配字符串结尾示例

\b:匹配单词边界示例


shell
- 通配符
.:匹配除换行符以外的任意单个字符
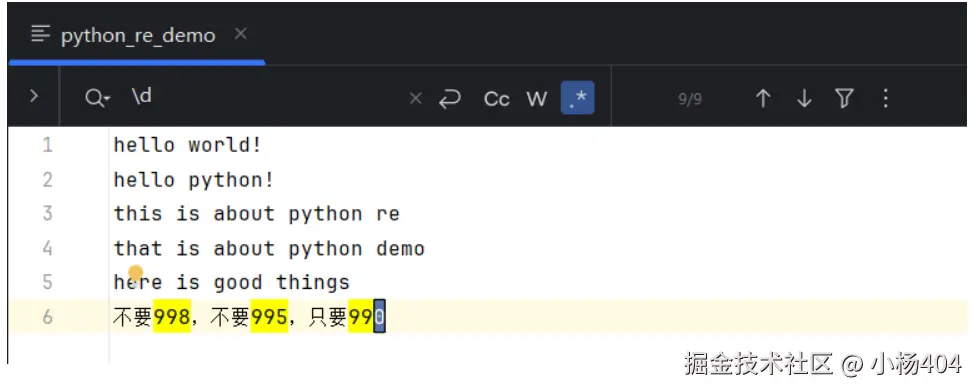
\d:匹配数字
\w:匹配单词字符(字母,数字,下划线)
\s:匹配空白字符(空格,制表符,换行).:匹配除换行符以外的任意单个字符

\d:匹配数字
\w:匹配单词字符(字母,数字,下划线)

\s:匹配空白字符(空格,制表符,换行)

shell
- 量词符
*:0次或多次
+:一次或多次
?:0次或一次
{n}:精确n次
{n,}:至少n次
{n,m}:n到m次*:0次或多次

+:一次或多次

?:0次或一次

{n}:精确n次

{n,}:至少n次

{n,m}:n到m次

shell
- 逻辑符
|:或运算
[...]:字符集合
[^...]:否定字符集合|:或运算

...:字符集合

\^...:否定字符集合
2.1.2.分组
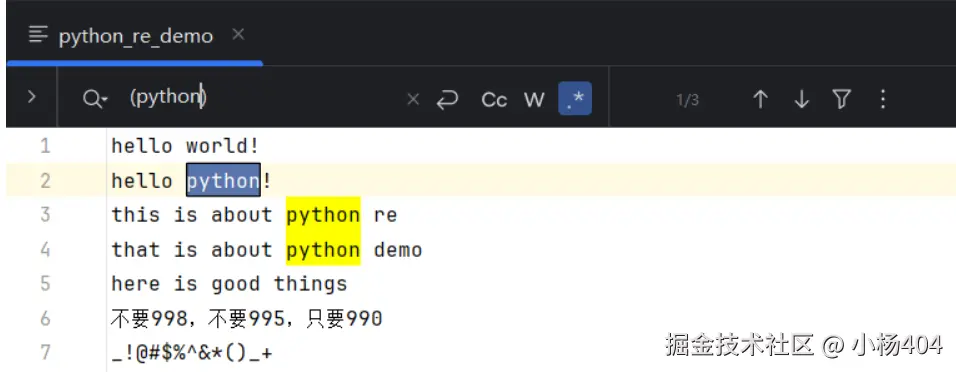
在文本提取场景中,可以通过"()"创建分组方式提取目标数据:
shell
():创建捕获分组
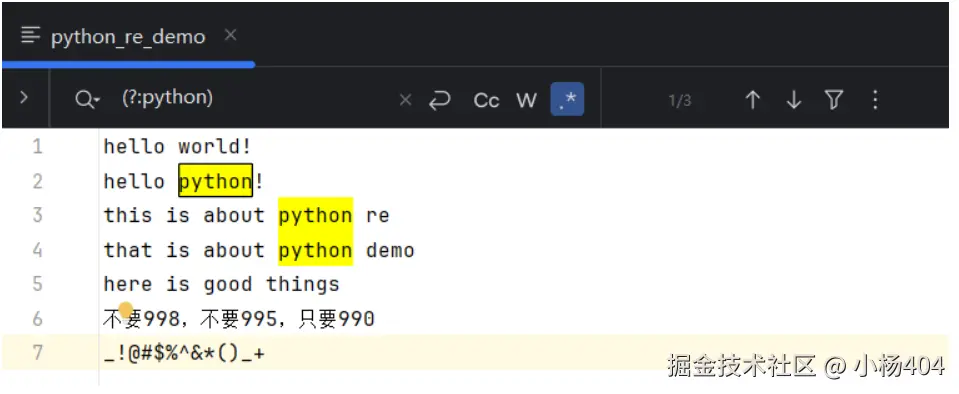
(?:):非捕获组
(?P<name>):命名分组():创建捕获分组
(?:):非捕获组
(?P<name):命名分组
非捕获组,命名分组IDE工具体现不出效果,后面我们通过python编程接口来示例。
2.1.3.断言
shell
(?=):正向先行断言
(?!):负向先行断言
(?<=):正向后行断言
(?<!):负向后行断言参考示例:
shell
# 匹配后面跟着"GB"的数字
lookahead = r'\d+(?=GB)'
# 匹配前面有"$"的价格数字
lookbehind = r'(?<=\$)\d+\.\d{2}'2.2.编程接口re
2.2.1.基本函数
python中re模块,提供了正则表达式相关编程接口,方便我们在应用中使用。
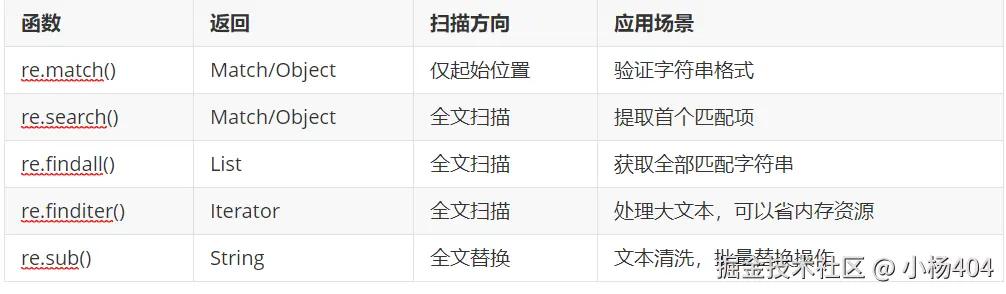
2.2.2.示例演示
2.2.2.1.match
python
import re
# match示例
text = "support_86@qq.com"
pattern = re.compile(r'(\w+)@([\w.]+)')
match = pattern.match(text)
if match:
print(f"Email验证成功,匹配结果为:",match.group())
print(match.group(1))
print(match.group(2))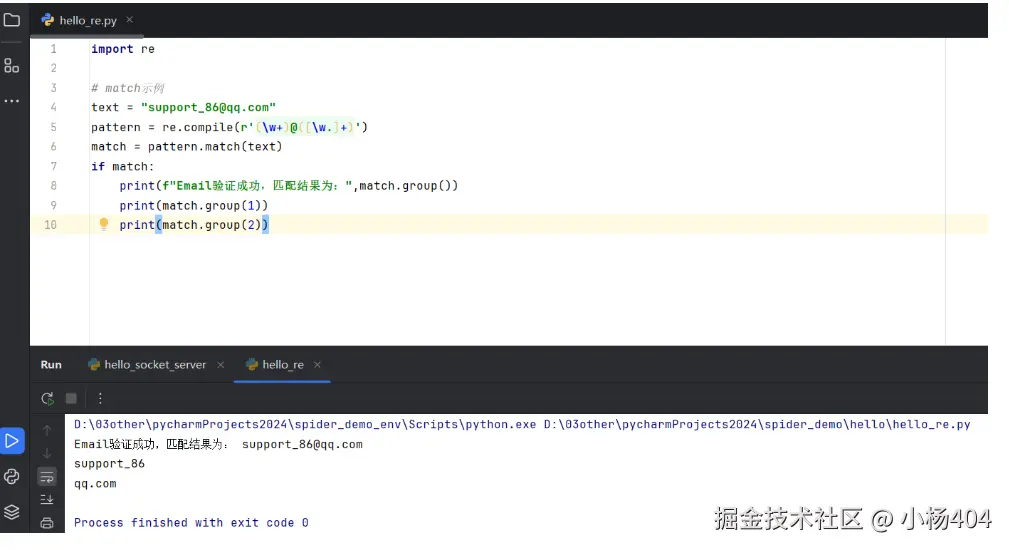
2.2.2.2.search
python
import re
# search示例
text = """
hello world!
hello python!
this is about python re
that is about python demo
here is good things
不要998,不要995,只要990
_!@#$%^&*()_+
Email:support@qq.com
Email2:support@163.com
Phone:13012345678
"""
pattern = re.compile(r'(\w+)@([\w.]+)')
search = pattern.search(text)
if search:
print(f"提取首次Email结果:",search.group())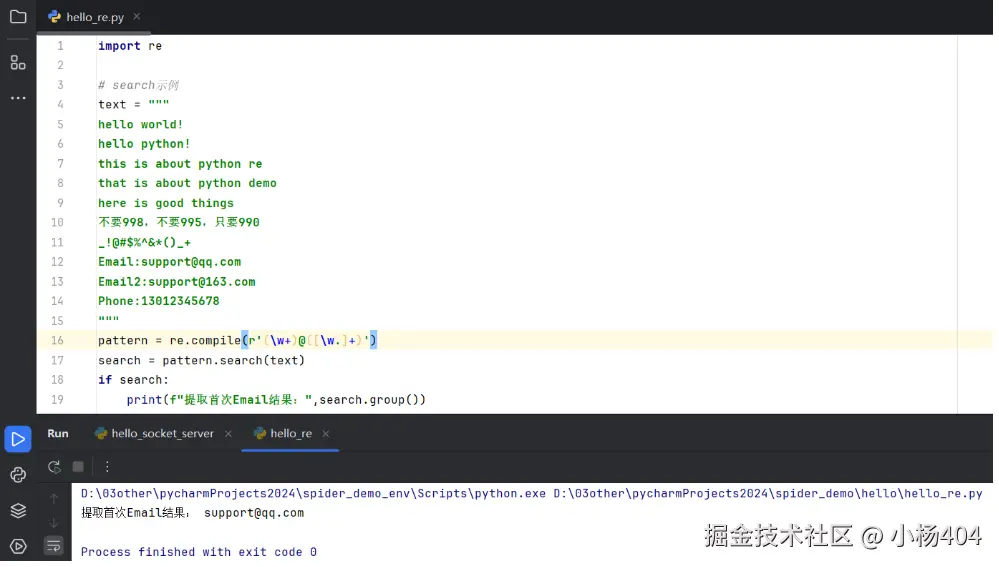
2.2.2.3.findall
python
import re
# findall示例
text = """
hello world!
hello python!
this is about python re
that is about python demo
here is good things
不要998,不要995,只要990
_!@#$%^&*()_+
Email:support@qq.com
Email2:support@163.com
Phone:13012345678
"""
pattern = re.compile(r'(\w+)@([\w.]+)')
all = pattern.findall(text)
if all:
print(f"提取全部Email结果:",all)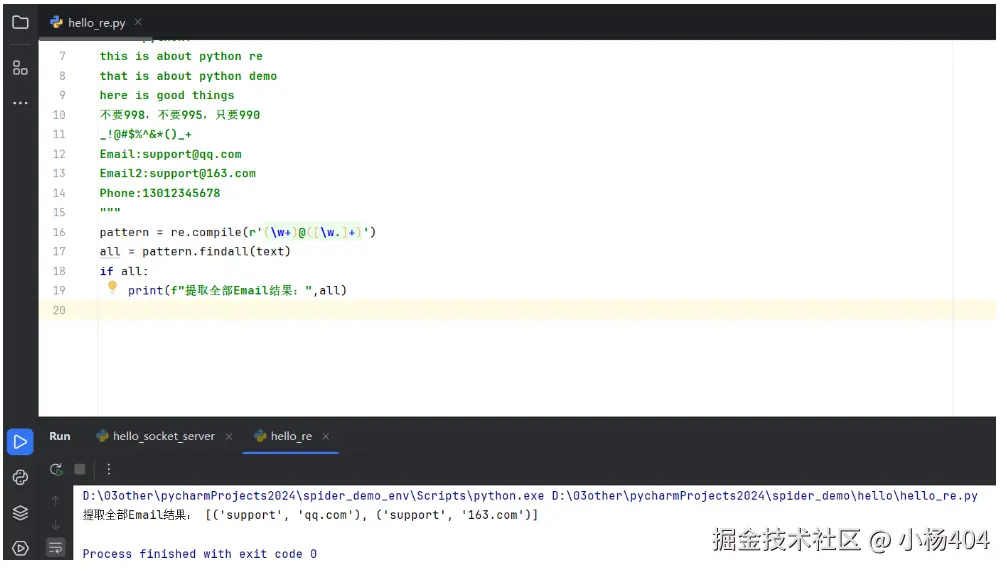
2.2.2.4.finditer
python
import re
# finditer示例
text = """
hello world!
hello python!
this is about python re
that is about python demo
here is good things
不要998,不要995,只要990
_!@#$%^&*()_+
Email:support@qq.com
Email2:support@163.com
Phone:13012345678
"""
pattern = re.compile(r'(\w+)@([\w.]+)')
iter = pattern.finditer(text)
if iter:
for i in iter:
print(f"提取全部Email结果:",i.group())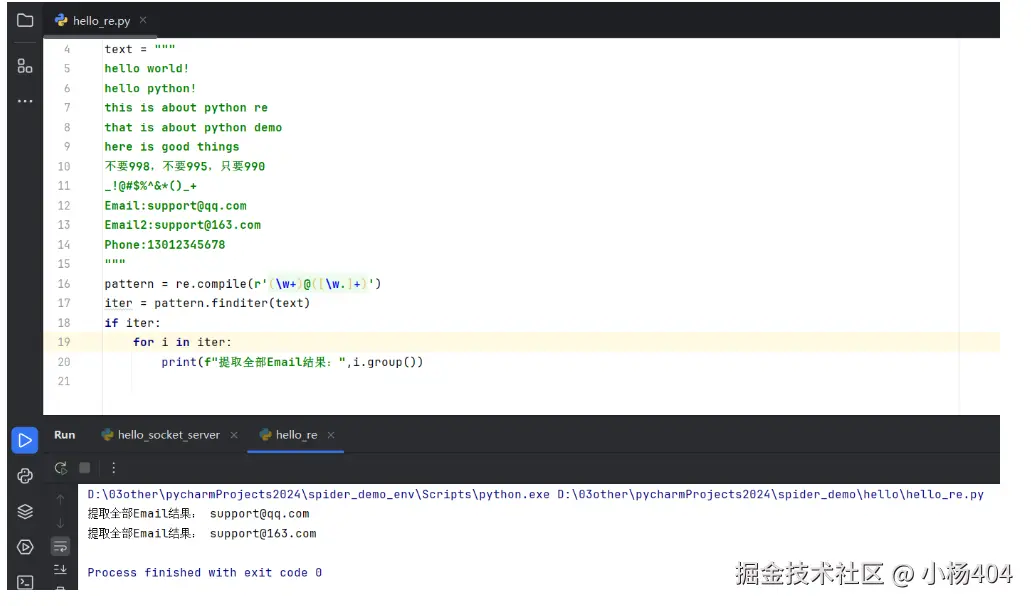
2.2.2.5.sub
python
import re
# sub示例
text = "<p>Hello, world!</p><a href='https://www.example.com'>Example</a>2023/08/15 2023/08/15"
def clean_text(text):
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
print("移除html标签结果:",text)
# 标准化日期格式 2023-08-15
text = re.sub(r'(\d{4})/(\d{2})/(\d{2})', r'\1-\2-\3', text)
print("替换日期格式结果:",text)
# 删除重复空格
text = re.sub(r'\s+', ' ', text)
print("删除重复空格结果:",text)
return text.strip()
# 调用函数进行文本清洗
cleaned_text = clean_text(text)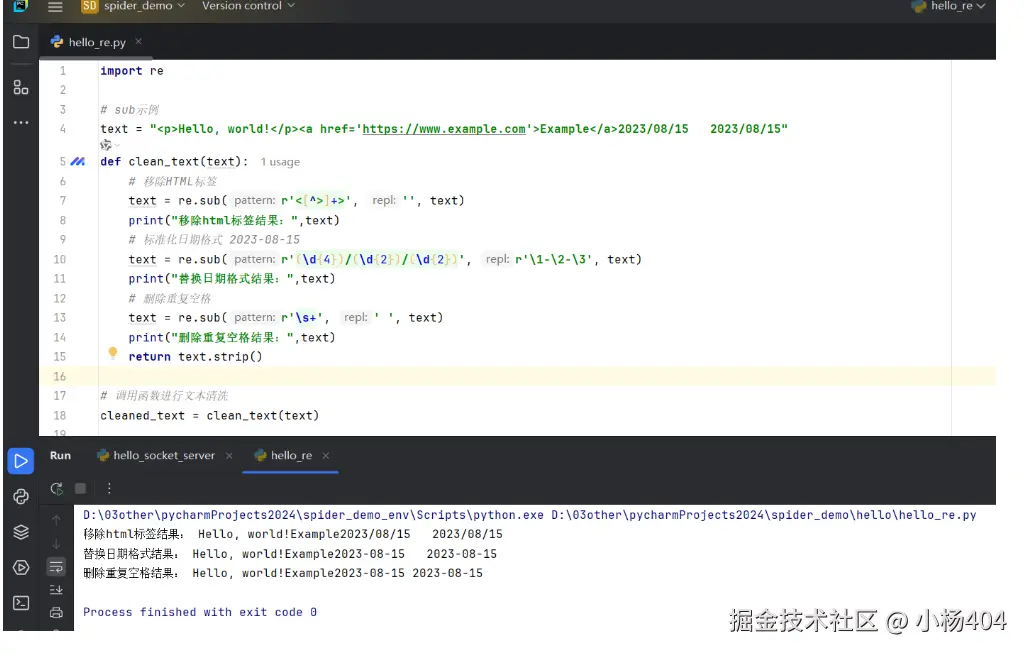
2.2.3.最佳实践
在使用python编程接口处理正则表达式中,有一些可参考的最佳实践原则:
- 优先使用原始字符串(r'')
- 复杂模式添加注释(re.VERBOSE)
- 预编译多次使用正则表达式
- 非捕获分组减少内存消耗
- 安全审查用户输入的正则表达式
- 合理使用第三方库,比如regex功能更强大