- Paper: https://arxiv.org/abs/2107.04034
- Project: https://ashish-kmr.github.io/rma-legged-robots/
- Code: https://github.com/antonilo/rl_locomotion
- 训练环境:Raisim
1.方法
RMA(Rapid Motor Adaptation)算法通过两阶段训练实现四足机器人在复杂环境中的快速适应。
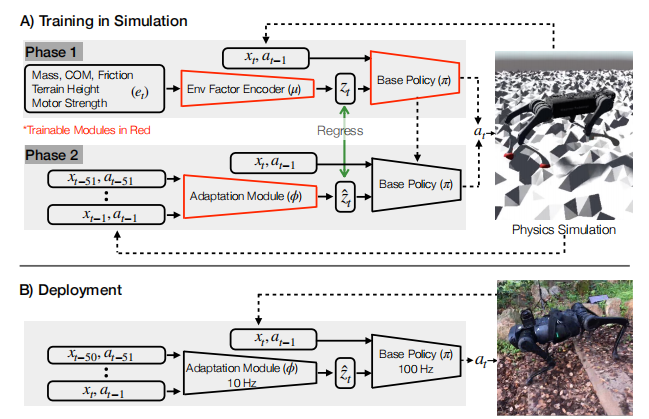
1.1.第一阶段:基础策略训练
在第一阶段,算法引入了一个17维的特权观测向量( e t e_t et),该向量包含了以下信息:
- 3维的质量和质心位置:描述机器人整体的质量分布。
- 12维的电机强度:表示每个关节电机的最大输出能力。
- 1维的摩擦系数:描述机器人与地面之间的摩擦特性。
- 1维的相对地面高度:表示机器人当前所处地形的相对高度。
这些特权观测信息虽然对训练过程非常有帮助,但在实际部署中无法直接获取。这些信息首先通过一个环境因素编码器( μ \mu μ) 被压缩为一个8维的潜在空间向量 ( z t z_t zt)。压缩的好处包括:
- 降低维度:减少计算复杂度,提高训练效率。
- 提取关键特征:提取对适应性最有帮助的特征,减少噪声和冗余信息。
- 增强泛化能力:通过压缩,潜在空间向量更能捕捉到环境变化的关键特征,从而在不同环境中具有更好的泛化能力。
策略网络 ( π \pi π) 的输入包括:
- 30维的本体观测:包含机器人的关节位置、速度、姿态等信息。
- 12维的历史动作:包含前一时刻的动作信息。
- 8维的潜在空间向量 ( z t z_t zt):由环境因素编码器生成。
策略网络的输出为12维的关节期望位置指令 a = q ^ ∈ R 12 a=\hat q \in \mathbb R^{12} a=q^∈R12,这些指令通过PD控制器被转换为关节力矩 ( τ \tau τ),驱动机器人运动。
τ = K p ( q ^ − q ) + K d ( 0 − q ˙ ) \tau = K_p(\hat q - q) + K_d (0-\dot q) τ=Kp(q^−q)+Kd(0−q˙)
第一阶段的训练目标是最大化策略网络在模拟环境中的累积奖励。通过强化学习(PPO算法),策略网络和环境因素编码器被联合训练,以适应各种模拟环境中的复杂地形和动态条件。
1.2.第二阶段:自适应模块训练
第一阶段训练得到的策略网络无法直接部署到实际机器人上,因为实际机器人无法获取17维的特权观测信息( e t e_t et),也无法获取由环境因素编码器生成的8维潜在空间向量 ( z t z_t zt)。为了解决这个问题,RMA算法引入了一个自适应模块网络 ( ϕ \phi ϕ),用于在运行时估计特权信息。
自适应模块网络的输入是机器人最近50组历史状态和动作,这些信息被用来估计特权观测经过压缩后的8维潜在空间向量 ( z ^ t \hat{z}_t z^t)。自适应模块网络由一个1维卷积神经网络(CNN)和一个多层感知机(MLP)组成,通过监督学习进行训练。具体来说,自适应模块网络的训练目标是最小化估计的潜在空间向量 ( z ^ t \hat{z}_t z^t) 与真实潜在空间向量 ( z t z_t zt) 之间的均方误差(MSE)。
第二阶段训练得到的自适应模块网络可以与基础策略网络一起部署到实际机器人上。在实际运行中,自适应模块网络以10Hz的频率更新潜在空间向量 ( z ^ t \hat{z}_t z^t) ,而基础策略网络则以100Hz的频率根据当前状态、历史动作和最新的潜在空间向量生成关节期望位置指令。
2.关键创新点
- 异步执行设计:基础策略网络和自适应模块网络以不同的频率运行(100Hz和10Hz),并且异步执行。这种设计使得算法能够在计算资源有限的机器人上高效运行,同时保证了实时性和适应性。
- 无需微调:RMA算法完全在模拟环境中训练,无需在现实世界中进行任何微调或数据收集,即可直接部署。
- 快速适应:通过自适应模块网络在运行时快速估计特权信息,RMA算法能够在几秒钟内适应新的环境条件,如不同的地形、负载和摩擦系数。
3.实验验证
RMA算法在多种复杂地形上进行了实验验证,包括沙地、泥土、草地、混凝土、鹅卵石、楼梯等。实验结果表明,RMA算法在这些复杂环境中的成功率和适应性优于基线方法,展示了其在实际应用中的潜力。
4.总结
RMA算法通过两阶段训练,第一阶段在模拟环境中训练基础策略,第二阶段训练自适应模块以估计特权信息。通过将17维特权观测压缩为8维潜在空间,算法能够更高效地提取关键特征,减少计算复杂度,增强泛化能力。这种设计使得算法能够在实际机器人上快速适应新环境,无需额外的微调或数据收集。