横跨150个任务和五大MAS框架的失败模式分类法
作者:Salvatore Raieli

图片由作者使用AI生成
"失败本身不可怕,但不改变才可怕"------John Wooden
"一个组织,无论设计得多好,最终也只能和其中生活和工作的人一样好。"------Dee Hock
基于大型语言模型(LLM)的智能体系统被认为是下一个大事件。大家热情高涨,因为能把LLM的能力扩展到需要与环境互动的复杂多步骤任务上。简单说,这被认为是解决现实世界问题(药物研发、科学模拟、软件工程等等)的关键。不过,现在大家关注的不是单个智能体,而是一群AI智能体一起协作解决问题。多智能体系统(MAS)成了AI研究中最被看好的方向之一。
然而,尽管很热闹,这些系统却经常以灾难性失败告终。为啥?
最近一些研究试着分析了这个问题,虽然我们离找到解决方案还远,但至少已经知道了可能的原因。本文就是来聊这个事儿的。
智能体被视为克服LLM(以及其基于transformer模型的局限性)的一种方法。各种研究为此引入了长时记忆、工具使用能力之类的系统。
智能体这个概念就是把这些元素组合出来的,对于一个基于LLM的智能体,可以这么定义:它有一个初始状态(通常在prompt里描述),可以跟踪它的产出(状态),还能通过工具跟环境互动(行动)。而多智能体系统(MAS)就是一群智能体以协调的方式互相配合解决任务。

虽然看起来像是单智能体的自然延伸,MAS却有一整套很不简单的挑战,比如要怎么组织智能体之间的讨论协议,它们怎么分工协作、怎么制定策略,等等。这些挑战导致,即便最近MAS被大量采用,性能相对于单个智能体的提升也很有限。
MAS比单个智能体复杂得多、成本也高得多。按理说,它们应该更聪明、更稳健、更可靠。但如果不是这样,它们为什么还会失败?
在最近发表的一项工作里,作者们提出了第一个MAS失败分类法(MASFT),用来分析这些失败的原因。
"我们并不声称MASFT覆盖了所有可能的失败模式;它只是迈向给MAS失败分类、理解它们的第一步。这些发现表明,MASFT不仅仅是现有多智能体框架的一个副产物,而是反映了MAS在设计上的根本缺陷。"------来源

这篇论文系统地研究了多种领域里发表过的MAS。他们收集了MAS的执行记录(智能体之间的对话),然后分析出了出了什么问题。

更细节地讲:
• 数据收集与分析。他们系统地收集了不同类型的MAS及其执行记录(目标、内部结构、组织方式和实现方式各异)。数据收集后,对失败现象进行了仔细标注。接着通过迭代比较,把各种失败归纳整理,奠定了分类法的基础。
• 标注者一致性研究与迭代完善。不同的标注者对结果进行了验证,并迭代完善分类法,直到达成共识。
• LLM标注器。此外,他们还用一个LLM充当"裁判",自动识别和诊断MAS失败(用的是OpenAI的o1模型)。

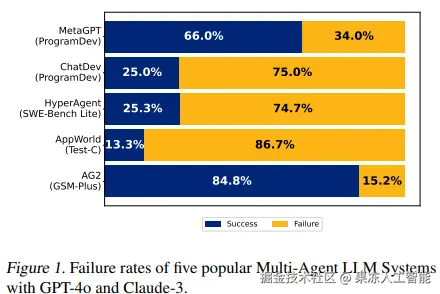
一个失败例子。图片来源:arxiv.org/pdf/2503.13...
具体来说,作者提出了三个主类别、十四个子类别的失败分类法,并把它们对应到三个过程阶段:执行前、执行中、执行后。研究结果显示失败的主要原因是:
• 大部分失败源于MAS设计上的缺陷(指令不完整或不清晰)。即使指令清晰,智能体也可能跟用户意图不一致,或者不遵守角色设定。要么是指令设计不好,要么是智能体不听话。
• 失败也可能来自智能体之间的沟通(沟通无效、协作差、行为冲突)。事实上,智能体可能进行了一堆无效交流,只是浪费资源(有时是很长的对话周期,成本很高)。
• 失败也可能跟任务执行本身有关,比如过早结束,或者缺乏结果验证机制(准确性、完整性、成果)。很多MAS根本没有一个验证任务完成情况的机制(比如专门负责验证的智能体)。
不过分析显示,没有哪一个大类(或子类)在失败中占绝对主导地位,说明当前MAS失败是多种问题交织的。

其他有趣的发现包括:
• 不同的MAS模型受不同失败影响。这说明MAS的设计直接影响它怎么失败。
• 不同子类别和主类别之间没有很强的关联。这意味着不同失败事件之间没有强烈的因果联系。中等程度的相关性提示,失败可能有连锁效应------一个失败可能导致接连的其他失败。

"在我们的研究中,我们专注于验证环节的问题------在系统能真正从验证中受益的场景里。很多情况下,验证可以看作是防止失败的最后一道防线。这让我们得出结论:虽然许多问题可以追溯到验证不足,但并不是所有问题都能归咎于这一点。"------来源
换句话说,其中一个主要问题是缺少验证。要是有个智能体专门负责验证过程和结果,很多问题就能解决。不过,还有一批问题是验证也搞不定的,比如规范本身烂、设计差、沟通无效,等等。总之,不光要加验证智能体,还得从源头设计上就做好。
既然知道了为什么MAS会失败,那怎么让它们更强更可靠呢?
作者们提出了两类改进MAS的策略:
• 战术性方法。这一类方法关注改进智能体prompt和组织结构。比如,使用清晰明确的规范,制定对话和流程终止的清晰模式,引入能识别不一致的验证流程。
• 结构性策略。建议采取更结构化的方法,比如增加单元测试、符号验证、代码执行检查、引入标准化协议、使用强化学习等等。

作者还用两个案例测试了他们的改进建议:
• 第一个案例是MathChat,它有一个学生智能体和一个助手智能体,助手会用Python执行代码来解题。他们拿了200道题,分别测试不同策略,比如改善prompt,或者优化工具结构。这些简单改进就能让系统击败原基线,说明哪怕只是简单调整prompt,也很有效。
• 第二个案例是ChatDev,模拟一个公司,不同智能体分别扮演CEO、CTO、软件工程师、审核员等角色,一起生成软件。他们也测试了两种策略:一是改进各个智能体的prompt、改善验证流程、加强角色约束;二是把系统拓扑结构从有向无环图(DAG)改成循环图(cyclic graph)。这两种改进都有效提升了成果。

"在这项研究中,我们首次系统地调查了基于LLM的多智能体系统的失败模式,通过收集和分析150+条执行记录,在扎根理论的指导下不断迭代完善分类法,并通过多标注者研究进行了验证。"------来源
这项研究系统分析了大量任务中的MAS,得出了MAS失败的分类(14种可能性)。可以归纳成三个主类:
系统设计缺陷(规则和设置没搞好)、
智能体之间配合失灵(沟通失败)、
任务完成与验证不足(系统无法判断任务是否完成且是否成功)。
一方面,之前大家也意识到了一些失败,比如智能体之间高效沟通的挑战。但这篇论文首次系统性地提出了分析MAS失败的框架。作者们还展示了一些简单策略如何提升MAS表现。另一方面,简单策略也不是万能的,因为有些失败根本就是LLM本身的结构性问题。不过,这篇论文提供了一个数据集和一个基于LLM的评估工具,为未来的研究打下了基础。