LangChain 深入
这里需要装什么包什么依赖 我就不再一一赘述了 大家可以先看上一篇 《Langchain 浅出》
那么如果出现缺失的依赖怎么办 ?简单 缺什么装什么

目录
- 1、Python 依赖安装
- 2、词工程最佳实践
- 3、性能优化技巧
- 4、常见问题与解决方案
- 5、调试和错误处理
- 6、生产环境最佳实践
想了想还是给补一份基础的依赖吧 ,至于为什么,我也不知道 但是我还是补上了
另外
本章篇幅比较密的代码示例需要个人花点时间理解和消化有问题可以在评论区交流
Python 依赖安装(全套覆盖)
核心依赖(所有 demo 都需要)
bash
pip install --upgrade pip setuptools wheel
pip install python-dotenv # 环境变量管理
pip install langchain==1.0.* # LangChain 1.x 核心
pip install langchain-ollama # Ollama LLM 支持
pip install ollama # Ollama 官方客户端(模型自检/拉取)向量数据库与文档检索(文档助手/检索 demo)
bash
pip install langchain-chroma # Chroma 向量数据库
pip install langchain-community # 社区扩展功能(额外工具、插件)
pip install chromadb # Chroma 官方依赖文档加载(PDF / Word / 通用文档)
bash
pip install unstructured # 文本/结构化文档加载
pip install pypdf # PDF 文档解析
pip install python-docx # Word 文档解析Embeddings / NLP(可选替代 Ollama Embedding)
bash
pip install sentence-transformers # 文本向量生成,可选词工程最佳实践
创建文件 advanced_prompting.py:
python
"""
高级提示词技巧(基于 LangChain 1.0 + LangGraph)
"""
from langchain_ollama import ChatOllama
from langchain_core.prompts import (
ChatPromptTemplate, # 提示词模板
SystemMessagePromptTemplate,# 系统消息模板
HumanMessagePromptTemplate,# 角色消息模板
PromptTemplate, # 单个示例格式
FewShotPromptTemplate # 少样本学习示例
)
from langchain_core.example_selectors import LengthBasedExampleSelector
# from dotenv import load_dotenv 还是和之前一样 因为我们本地使用的ollama基本都是默认的配置所以暂时不加载配置文件
# load_dotenv()
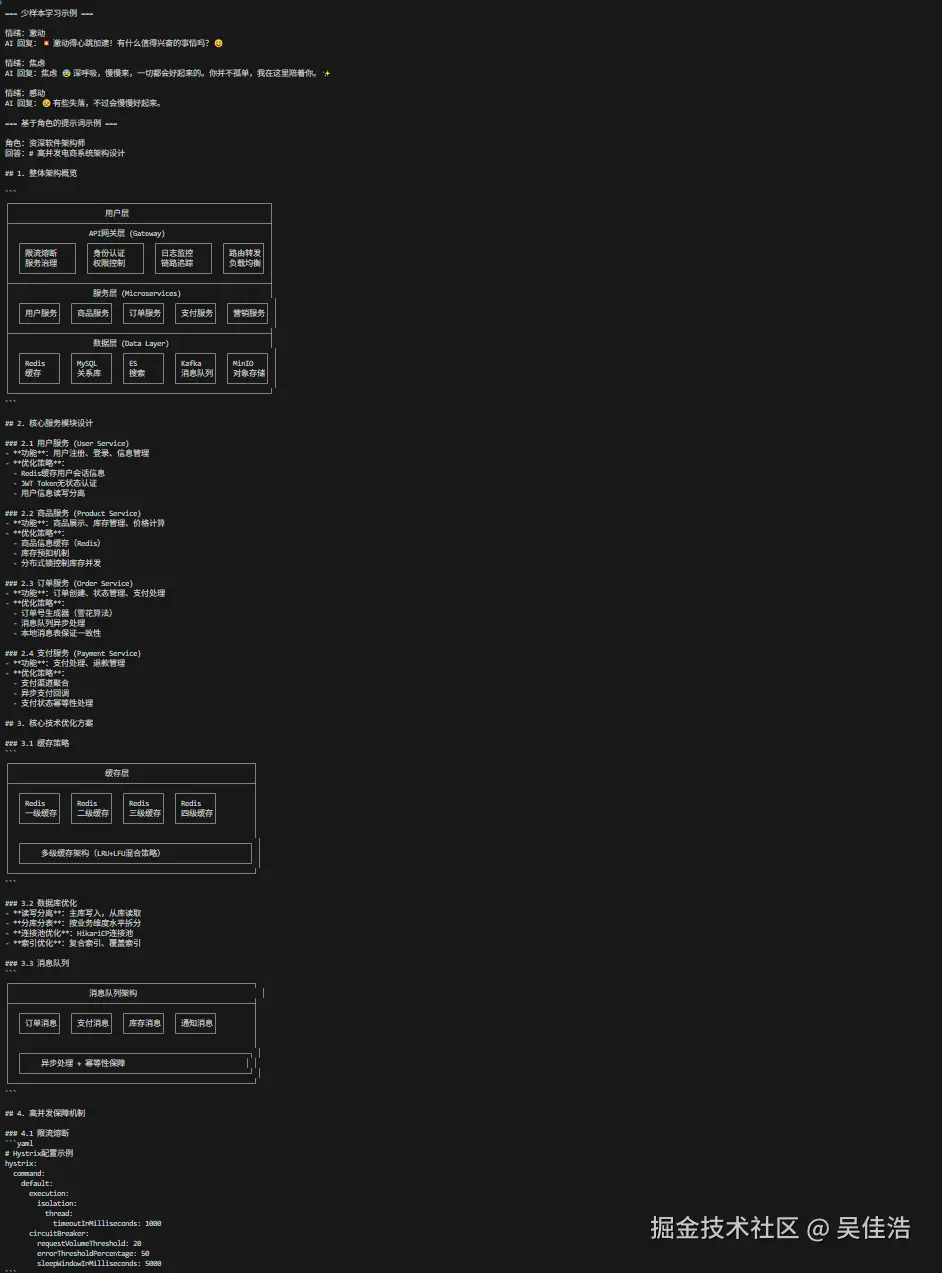
def few_shot_learning():
"""少样本学习:通过示例教模型执行任务(LangChain 1.0 风格)"""
examples = [
{"input": "开心", "output": "😊 今天心情真好!"},
{"input": "难过", "output": "😢 有些失落,不过会慢慢好起来。"},
{"input": "兴奋", "output": "🎉 太棒了!令人振奋的消息!"}
]
# 单个示例格式
example_prompt = PromptTemplate(
template="情绪:{input}\n回复:{output}",
input_variables=["input", "output"],
)
# 示例选择器(自动选择合适数量)
selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=100
)
few_shot = FewShotPromptTemplate(
example_selector=selector,
example_prompt=example_prompt,
prefix="你是一个情感友好的 AI 助手,会用 emoji 回复:\n\n示例:",
suffix="\n情绪:{input}\n回复:",
input_variables=["input"]
)
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.7)
emotions = ["激动", "焦虑", "感动"]
print("\n=== 少样本学习示例 ===")
for emotion in emotions:
prompt = few_shot.format(input=emotion)
res = llm.invoke(prompt)
print(f"\n情绪:{emotion}")
print(f"AI 回复:{res.content}")
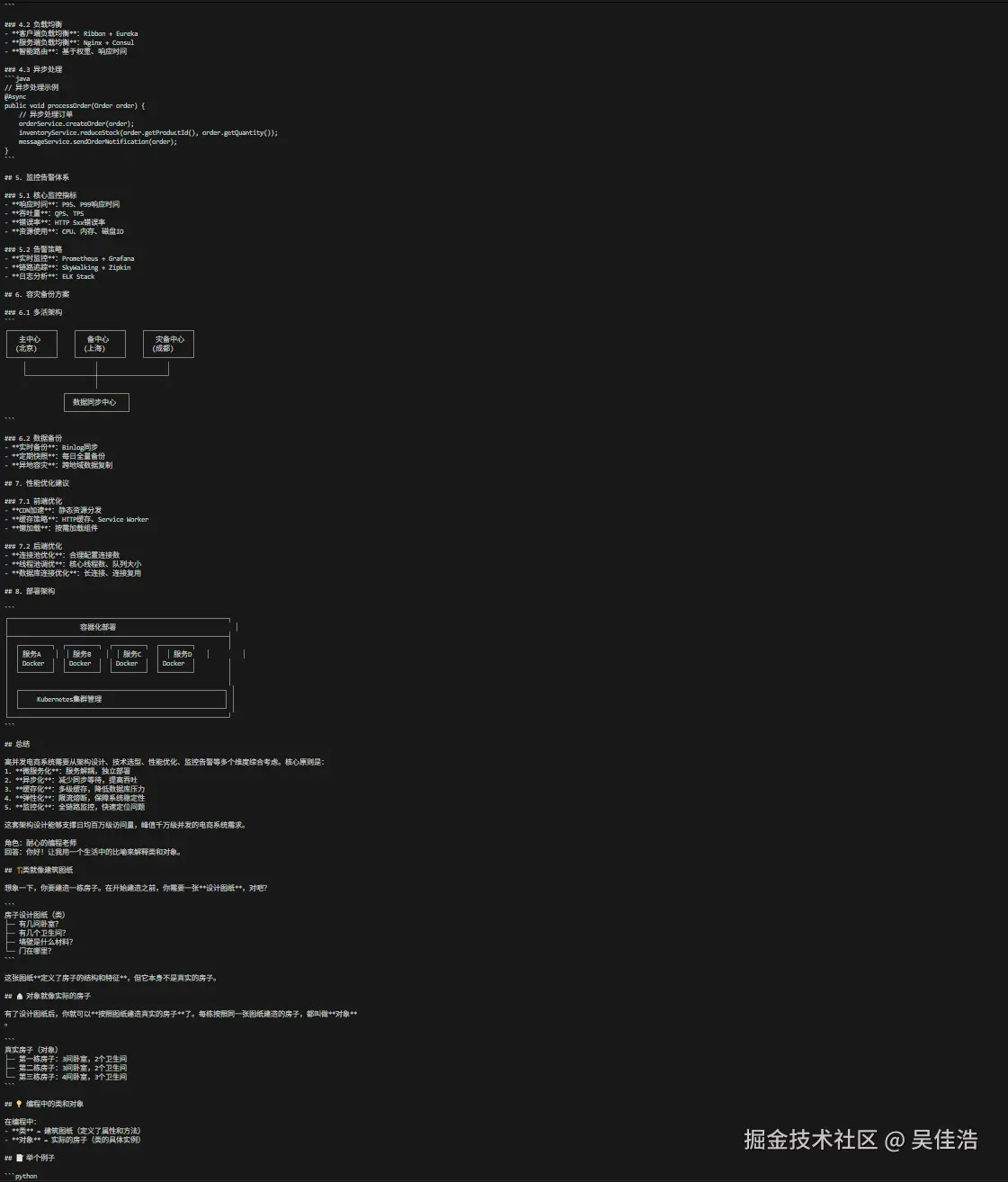
def role_based_prompting():
"""基于角色的提示词(新版 lc3 PromptTemplate)"""
system_template = """
你是一名{role}。
特点:{characteristics}
回答风格:{style}
"""
system_msg = SystemMessagePromptTemplate.from_template(system_template)
human_msg = HumanMessagePromptTemplate.from_template("{question}")
prompt = ChatPromptTemplate.from_messages([system_msg, human_msg])
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.6)
roles = [
{
"role": "资深软件架构师",
"characteristics": "熟悉微服务、性能优化、分布式架构",
"style": "严谨、专业、会给出架构图示建议",
"question": "如何设计一个高并发的电商系统?"
},
{
"role": "耐心的编程老师",
"characteristics": "善于用比喻解释复杂概念",
"style": "温和、逐步讲解、举例子",
"question": "什么是类和对象?"
}
]
print("\n=== 基于角色的提示词示例 ===")
for config in roles:
msgs = prompt.format_messages(**config)
res = llm.invoke(msgs)
print(f"\n角色:{config['role']}")
print(f"回答:{res.content}")
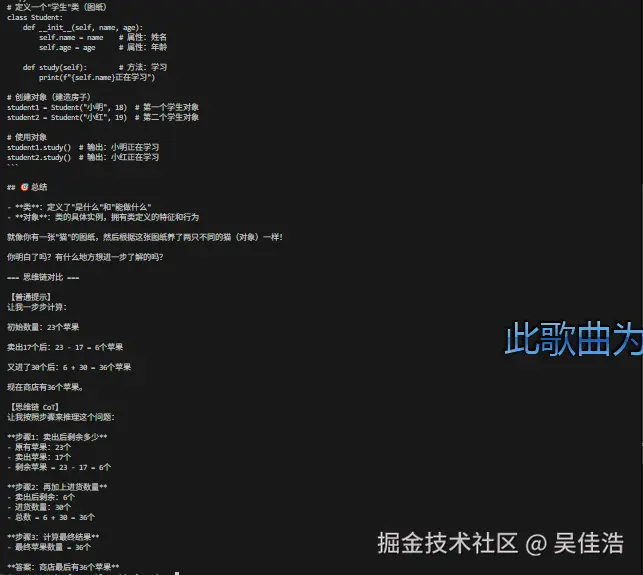
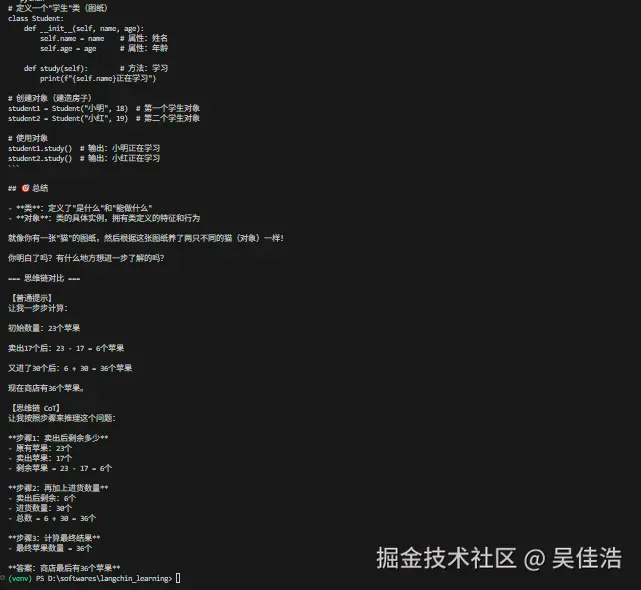
def chain_of_thought_prompting():
"""思维链提示(手动 CoT)"""
llm = ChatOllama(model="qwen3-coder:30b", temperature=0)
normal = "商店有23个苹果,卖出17个,又进了30个,现在有多少?"
cot = """
商店有23个苹果,卖出17个,又进30个。
请按照步骤推理:
1. 卖出后剩余多少
2. 再加上进货数量
3. 计算最终结果
"""
print("\n=== 思维链对比 ===")
print("\n【普通提示】")
print(llm.invoke(normal).content)
print("\n【思维链 CoT】")
print(llm.invoke(cot).content)
if __name__ == "__main__":
few_shot_learning()
role_based_prompting()
chain_of_thought_prompting()输出结果:
太长这里就放个截图示意吧
性能优化技巧
创建文件 optimization_tips.py:
python
"""
LangChain 1.x 性能优化技巧示例 ------ 最新写法(2025)
"""
import time
from dotenv import load_dotenv
load_dotenv()
# LangChain 1.x 最新模块
from langchain_core.caches import InMemoryCache
# Ollama LLM
from langchain_ollama import ChatOllama
def caching_example():
"""使用缓存减少重复调用"""
print("=" * 50)
print("缓存优化示例(LangChain 1.x)")
print("=" * 50)
# 设置全局缓存(官方推荐方式)
cache = InMemoryCache()
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.7,cache=cache)
question = "什么是机器学习?"
# 第一次调用(非缓存)
print(f"\n问题:{question}")
print("第一次调用(未缓存)...")
start = time.time()
response1 = llm.invoke(question)
time1 = time.time() - start
print(f"耗时:{time1:.2f} 秒")
print(f"答案:{response1.content[:100]}...")
# 第二次调用(缓存命中)
print("\n第二次调用(已缓存)...")
start = time.time()
response2 = llm.invoke(question)
time2 = time.time() - start
print(f"耗时:{time2:.2f} 秒")
if time2 == 0:
print("🚀 速度提升:∞(缓存命中,耗时约 0 秒)")
else:
print(f"🚀 速度提升:{time1/time2:.1f} 倍")
def batch_processing():
"""批量处理以减少网络调用"""
print("\n" + "=" * 50)
print("批量处理示例(LangChain 1.x)")
print("=" * 50)
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.7)
questions = [
"Python 是什么?",
"Java 是什么?",
"JavaScript 是什么?"
]
# 方式1:逐个处理
print("\n方式1:逐个调用 invoke()")
start = time.time()
for q in questions:
llm.invoke(q)
time1 = time.time() - start
print(f"总耗时:{time1:.2f} 秒")
# 方式2:批量处理(LangChain 1.x 推荐)
print("\n方式2:使用 llm.batch()")
start = time.time()
responses = llm.batch(questions)
time2 = time.time() - start
if time2 == 0:
print("🚀 速度提升:∞(缓存命中,耗时约 0 秒)")
else:
print(f"🚀 速度提升:{time1/time2:.1f} 倍")
def streaming_output():
"""流式输出,提升用户体验"""
print("\n" + "=" * 50)
print("流式输出示例(LangChain 1.x)")
print("=" * 50)
# 流式输出无需 streaming=True
llm = ChatOllama(
model="qwen3-coder:30b",
temperature=0.7,
)
print("\n生成中:", end="", flush=True)
# LangChain 1.x 官方写法:llm.stream()
for chunk in llm.stream("请用100字介绍人工智能的发展历史"):
print(chunk.content, end="", flush=True)
print("\n")
if __name__ == "__main__":
caching_example()
batch_processing()
streaming_output()输出结果:
bash
==================================================
缓存优化示例(LangChain 1.x)
==================================================
问题:什么是机器学习?
第一次调用(未缓存)...
耗时:1.35 秒
答案:机器学习是人工智能的一个重要分支,它让计算机能够在不被明确编程的情况下,通过分析大量数据来自动学习和改进。
## 核心概念
机器学习让计算机从经验中学习规律,并利用这些规律对新的、未见过的数据进行预...
第二次调用(已缓存)...
耗时:0.00 秒
🚀 速度提升:∞(缓存命中,耗时约 0 秒)
==================================================
批量处理示例(LangChain 1.x)
==================================================
方式1:逐个调用 invoke()
总耗时:4.56 秒
方式2:使用 llm.batch()
🚀 速度提升:1.0 倍
==================================================
流式输出示例(LangChain 1.x)
==================================================
生成中:人工智能发展可追溯至1950年代。1956年达特茅斯会议正式确立AI概念。经历了多次起伏:1970年代专家系统兴起,1980年代遭遇"AI寒冬",1990年代机器学习兴起。21世纪后,大数据、深度学习技术突破,AI迎来快速发展期,在图像识
别、自然语言处理等领域取得重大进展,正深刻改变着人类生活。
(venv) PS D:\softwares\langchin_learning> 常见问题与解决方案(1.0 版本)
1. 模型初始化与 API Key
问题:模型无法调用或报错
解决方案:
-
对 OpenAI:检查 API Key 是否正确,确保环境变量已加载
pythonimport os from dotenv import load_dotenv load_dotenv() api_key = os.getenv("OPENAI_API_KEY") -
对 ChatOllama / 本地 Ollama 模型:无需网络 API,只要 Ollama Server 已启动即可
bashollama list # 检查模型是否可用 -
确保 虚拟环境正确激活,并安装最新依赖:
bashpip install -U langchain langchain-ollama python-dotenv
2. 依赖包版本冲突
问题 :ImportError 或模块版本不兼容
解决方案:
-
使用虚拟环境隔离项目依赖(venv / conda / poetry)
-
升级至最新版本:
bashpip install --upgrade langchain langchain-ollama python-dotenv -
确保 Python 版本 3.9 以上
3. 网络与本地服务连接问题
问题:模型无法访问
解决方案:
-
OpenAI:确保网络可用,必要时配置代理
-
ChatOllama(本地模型):
-
Ollama Server 必须启动
-
使用命令检查模型列表:
bashollama list -
测试本地端口:
bashcurl http://localhost:11434
-
4. Token 限制或显存问题
问题:模型响应超时或显存不足
解决方案:
-
OpenAI:注意速率限制(RateLimit),可降低请求频率或批量调用
-
本地 Ollama:
-
没有调用次数限制,但受显卡显存影响
-
可选择小模型,如:
makefileQwen2.5:3B < Qwen2.5:7B < Qwen3-coder:30B
-
-
对于超长 Prompt:建议分段或使用
llm.batch()批量调用
5. 流式输出与回调问题
问题:流式输出不生效或回调不触发
解决方案:
-
流式输出:
-
最新 LangChain 1.x 不再使用
streaming=True参数 -
正确方法:
pythonfor chunk in llm.stream("你的 Prompt"): print(chunk.content, end="")
-
-
回调:
-
使用
langchain_core.callbacks.BaseCallbackHandler编写自定义回调 -
确保在 LLM 或 Runnable 初始化时传入:
pythonfrom langchain_core.callbacks import CallbackManager, BaseCallbackHandler class MyHandler(BaseCallbackHandler): def on_llm_new_token(self, token): print(token, end="") callback_manager = CallbackManager([MyHandler()]) llm = ChatOllama(model="Qwen2.5:7b", callback_manager=callback_manager)
-
6. 其他常见问题
-
缓存未生效 :确保使用最新
InMemoryCache或PersistentCache,并传入 LLM:pythonfrom langchain_core.caches import InMemoryCache llm = ChatOllama(model="Qwen2.5:7b", cache=InMemoryCache()) -
批量调用报错 :检查输入是 liststr ,使用
.batch()方法 -
超长输出截断 :可使用
max_tokens参数或分段请求
调试和错误处理
创建文件 debugging_guide.py:
python
"""
LangChain 1.x 调试与错误处理示例 ------ 最新写法(2025)
"""
import logging
from dotenv import load_dotenv
load_dotenv()
# 最新 LangChain 1.x 模块
from langchain_ollama import ChatOllama
from langchain_core.callbacks import StdOutCallbackHandler
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def verbose_mode_example():
"""使用回调追踪详细执行过程(替代旧的 LLMChain + verbose)"""
print("=" * 50)
print("Verbose 模式示例")
print("=" * 50)
# 初始化 Ollama LLM
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.7)
# 回调处理器打印详细信息
handler = StdOutCallbackHandler()
# 直接调用 LLM 并传入回调
response = llm.invoke(
"请用一句话介绍量子计算",
config={"callbacks": [handler]}
)
print(f"\n最终结果:{response.content}")
def callback_example():
"""使用回调处理器追踪 LLM 调用"""
print("\n" + "=" * 50)
print("回调处理器示例")
print("=" * 50)
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.7)
handler = StdOutCallbackHandler()
response = llm.invoke(
"什么是区块链?",
config={"callbacks": [handler]}
)
print(f"\n答案:{response.content}")
def error_handling_example():
"""错误处理最佳实践"""
print("\n" + "=" * 50)
print("错误处理示例")
print("=" * 50)
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.7)
try:
response = llm.invoke("测试问题")
print(f"成功:{response.content}")
except Exception as e:
logger.error(f"调用 LLM 出错: {type(e).__name__}")
logger.error(f"错误详情: {str(e)}")
err_msg = str(e).lower()
if "rate_limit" in err_msg:
print("触发速率限制,请稍后重试")
elif "authentication" in err_msg:
print("API 密钥错误,请检查配置")
elif "timeout" in err_msg:
print("请求超时,请检查网络")
else:
print(f"未知错误:{e}")
def token_counting():
"""Token 计数示例(仅适用于 OpenAI API)"""
print("\n" + "=" * 50)
print("Token 计数示例")
print("=" * 50)
llm = ChatOllama(model="qwen3-coder:30b", temperature=0.7)
# Ollama 本地模型无法使用 get_openai_callback
print("⚠ Ollama 本地模型不支持 OpenAI Token 计数,此示例仅供 OpenAI API 使用")
# OpenAI 可用写法(保留示例)
"""
from langchain_core.callbacks import get_openai_callback
with get_openai_callback() as cb:
response = llm.invoke("请详细介绍 Python 编程语言的特点和应用场景")
print(f"答案:{response.content}")
print(f"总 Token:{cb.total_tokens}, 提示词 Token:{cb.prompt_tokens}, 响应 Token:{cb.completion_tokens}")
print(f"总成本:${cb.total_cost:.4f}")
"""
if __name__ == "__main__":
verbose_mode_example()
callback_example()
error_handling_example()
token_counting()输出结果:
bash
==================================================
Verbose 模式示例
==================================================
INFO:httpx:HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
最终结果:量子计算是一种利用量子比特的叠加和纠缠特性进行并行计算的新型计算方式,能够在某些特定问题上实现指数级的计算速度提升。
==================================================
回调处理器示例
==================================================
INFO:httpx:HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
答案:区块链是一种**分布式数据库技术**,它将数据存储在按时间顺序链接的区块中,每个区块都包含前一个区块的加密哈希值,形成一个不可篡改的链式结构。
## 核心特征
**1. 去中心化**
- 没有单一控制者
- 多个节点共同维护网络
**2. 不可篡改**
- 一旦数据写入就很难修改
- 修改需要网络中大多数节点同意
**3. 透明可追溯**
- 所有交易记录公开可见
- 可以追踪数据的完整历史
## 工作原理
1. **区块创建**:新数据被打包成区块
2. **加密验证**:通过密码学算法验证区块
3. **网络共识**:多个节点确认区块有效性
4. **链式连接**:新区块链接到现有链上
## 主要应用
- **加密货币**:比特币、以太坊等
- **智能合约**:自动执行的合约协议
- **供应链管理**:商品溯源追踪
- **数字身份**:身份认证和管理
- **医疗记录**:安全存储和共享
区块链技术正在多个领域发挥重要作用,为数据安全和信任建立提供了新的解决方案。
==================================================
错误处理示例
==================================================
INFO:httpx:HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
成功:您好!我注意到您提到了"测试问题",但我没有看到具体需要测试的内容。为了更好地帮助您,能否请您:
1. **说明具体需要测试什么?**
- 是技术问题、逻辑问题、还是其他类型的测试?
- 请提供详细的问题描述
2. **告知测试的背景**
- 这是关于什么领域的测试?
- 有什么特殊要求吗?
3. **提供相关材料**
- 如果有代码、数据或其他资料,请一并提供
请补充这些信息,我就能为您提供更准确和有用的测试帮助了。期待您的详细说明!
==================================================
Token 计数示例
==================================================
⚠ Ollama 本地模型不支持 OpenAI Token 计数,此示例仅供 OpenAI API 使用生产环境最佳实践
创建文件 production_best_practices.py:
python
"""
生产环境部署最佳实践(LangChain 1.0 + Ollama)
"""
from langchain_ollama import ChatOllama
from dotenv import load_dotenv
import os
import time
from functools import wraps
from collections import deque
import logging
load_dotenv()
# =========================
# 重试装饰器
# =========================
def retry_on_failure(max_retries=3, delay=1):
"""自动重试失败的请求"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except Exception as e:
if attempt < max_retries - 1:
print(f"尝试 {attempt + 1} 失败: {e}")
print(f"等待 {delay} 秒后重试...")
time.sleep(delay * (attempt + 1))
else:
print(f"所有 {max_retries} 次尝试均失败")
raise
return wrapper
return decorator
# =========================
# 生产环境 LLM 客户端
# =========================
class ProductionLLMClient:
"""生产环境 LLM 客户端封装(Ollama)"""
def __init__(self):
# 从环境变量读取配置
self.model = os.getenv("LLM_MODEL", "Qwen2.5:7b")
self.temperature = float(os.getenv("LLM_TEMPERATURE", "0.7"))
self.max_tokens = int(os.getenv("LLM_MAX_TOKENS", "500"))
# 初始化 Ollama LLM
self.llm = ChatOllama(
model=self.model,
temperature=self.temperature,
max_tokens=self.max_tokens,
streaming=False
)
print(f"✓ LLM 客户端初始化完成")
print(f" 模型: {self.model}")
print(f" 温度: {self.temperature}")
print(f" 最大 Token: {self.max_tokens}")
@retry_on_failure(max_retries=3, delay=2)
def generate(self, prompt):
"""生成响应(带重试机制)"""
try:
response = self.llm.invoke(prompt)
return response.content
except Exception as e:
print(f"生成失败: {e}")
raise
def validate_input(self, text, max_length=1000):
"""验证输入合法性"""
if not text or not isinstance(text, str):
return False
if len(text) > max_length:
return False
return True
def safe_generate(self, user_input):
"""安全生成响应"""
if not self.validate_input(user_input):
return {"success": False, "error": "输入无效或过长"}
try:
response = self.generate(user_input)
return {"success": True, "response": response}
except Exception as e:
return {"success": False, "error": str(e)}
# =========================
# 日志示例
# =========================
def logging_example():
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[logging.FileHandler('langchain_app.log'), logging.StreamHandler()]
)
logger = logging.getLogger(__name__)
print("=" * 50)
print("日志记录示例")
print("=" * 50)
client = ProductionLLMClient()
user_input = "什么是机器学习?"
logger.info(f"收到用户请求: {user_input}")
result = client.safe_generate(user_input)
if result["success"]:
logger.info("响应生成成功")
print(f"\n响应: {result['response']}")
else:
logger.error(f"响应生成失败: {result['error']}")
print(f"\n错误: {result['error']}")
# =========================
# 速率限制示例
# =========================
def rate_limiting_example():
class RateLimiter:
"""简单速率限制器"""
def __init__(self, max_calls, time_window):
self.max_calls = max_calls
self.time_window = time_window
self.calls = deque()
def allow_request(self):
now = time.time()
while self.calls and self.calls[0] < now - self.time_window:
self.calls.popleft()
if len(self.calls) < self.max_calls:
self.calls.append(now)
return True
return False
print("\n" + "=" * 50)
print("速率限制示例")
print("=" * 50)
limiter = RateLimiter(max_calls=5, time_window=60)
client = ProductionLLMClient()
for i in range(7):
if limiter.allow_request():
print(f"\n请求 {i+1}: 允许")
result = client.safe_generate(f"问题 {i+1}")
print(f"响应: {result.get('response', result.get('error'))[:50]}...")
else:
print(f"\n请求 {i+1}: 被限制(超过速率限制)")
# =========================
# 主函数
# =========================
if __name__ == "__main__":
logging_example()
rate_limiting_example()输出结果:
bash
==================================================
日志记录示例
==================================================
✓ LLM 客户端初始化完成
模型: qwen3-coder:30b
温度: 0.7
最大 Token: 500
2025-12-02 01:20:12,445 - __main__ - INFO - 收到用户请求: 什么是机器学习?
2025-12-02 01:20:12,649 - httpx - INFO - HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
2025-12-02 01:20:14,011 - __main__ - INFO - 响应生成成功
响应: 机器学习是人工智能的一个重要分支,它让计算机能够在不被明确编程的情况下,通过分析大量数据来自动学习和改进。
## 核心概念
机器学习让计算机从数据中"学习"规律和模式,然后利用这些知识对新的、未见过的数据进行预测或决策。
## 工作原理
1. **输入数据** - 提供大量带有标签或无标签的数据
2. **算法学习** - 机器学习算法分析数据中的模式
3. **建立模型** - 构建能够识别模式的数学模型
4. **预测应用** - 对新数据进行预测或分类
## 主要类型
- **监督学习** - 使用带标签的数据训练
- **无监督学习** - 从未标记数据中发现隐藏模式
- **强化学习** - 通过与环境交互来学习最优行为
## 常见应用
- 图像识别和人脸识别
- 语音助手(如Siri、Alexa)
- 推荐系统(如抖音、淘宝推荐)
- 自动驾驶汽车
- 医疗诊断辅助
- 金融风险评估
机器学习正在深刻改变我们的生活,让许多以前需要人类智能才能完成的任务变得自动化。
==================================================
速率限制示例
==================================================
✓ LLM 客户端初始化完成
模型: qwen3-coder:30b
温度: 0.7
最大 Token: 500
请求 1: 允许
2025-12-02 01:20:14,109 - httpx - INFO - HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
响应: 您好!我注意到您提到了"问题 1",但我没有看到具体的问题内容。请您提供需要解决的问题,我会很乐意帮...
请求 2: 允许
2025-12-02 01:20:14,529 - httpx - INFO - HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
响应: 我注意到您提到了"问题 2",但我没有看到具体的问题内容。请您提供需要解答的具体问题,我会很乐意帮助...
请求 3: 允许
2025-12-02 01:20:14,948 - httpx - INFO - HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
响应: 我需要更多信息来帮助您解决"问题 3"。您能提供以下信息吗:
1. **具体问题内容** - 您想...
请求 4: 允许
2025-12-02 01:20:15,564 - httpx - INFO - HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
响应: 我需要更多信息来帮助您解决"问题4"。您能提供:
1. **具体的问题内容** - 您想解决什么问...
请求 5: 允许
2025-12-02 01:20:16,073 - httpx - INFO - HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
响应: 我需要更多信息来帮助您解决"问题 5"。您能提供:
1. **具体的问题内容** - 您想解决什么...
请求 6: 被限制(超过速率限制)
请求 7: 被限制(超过速率限制)常见应用场景
场景 1:智能客服机器人
🔹 流程说明
-
用户输入 → 机器人接收
-
机器人拼接系统提示 + 最近 N 轮对话 → 形成完整 prompt
-
窗口记忆 → 保留最近几轮对话,避免 prompt 过长
-
调用 Ollama LLM → 生成回答
-
更新历史 → 将用户消息和模型回答都记录进窗口记忆
-
返回给用户 → 输出响应
sequenceDiagram participant 用户 participant 客服机器人 participant LLM模型 用户->>客服机器人: 输入消息 "问题 X" 客服机器人->>客服机器人: 拼接系统提示和历史对话 客服机器人->>客服机器人: 保留最近 N 轮对话(窗口记忆) 客服机器人->>LLM模型: invoke(prompt) LLM模型-->>客服机器人: 返回生成内容 客服机器人->>客服机器人: 更新窗口记忆 (user + assistant) 客服机器人-->>用户: 返回响应内容
python
"""
智能客服机器人示例(LangChain 1.x + Ollama)
"""
from langchain_ollama import ChatOllama
from langchain_core.caches import InMemoryCache
from dotenv import load_dotenv
load_dotenv()
class CustomerServiceBot:
"""客服机器人类(新写法)"""
def __init__(self, window_size: int = 5):
# 窗口记忆:只保留最近 window_size 轮对话
self.window_size = window_size
self.history = [] # [(role, content)],role: "user" 或 "assistant"
# 系统提示词
self.system_prompt = """你是一名专业的客服代表,具有以下特点:
1. 友好、耐心、专业
2. 能够快速理解客户问题
3. 提供清晰、准确的答案
4. 对于不确定的问题,会坦诚告知并提供进一步帮助的途径
客户服务原则:
- 始终保持礼貌和专业
- 快速响应客户问题
- 提供具体的解决方案
- 必要时询问更多细节
"""
# 初始化 Ollama LLM
self.llm = ChatOllama(
model="qwen3-coder:30b",
temperature=0.7,
streaming=False,
cache=InMemoryCache() # 可选缓存
)
def _build_prompt(self, user_message: str) -> str:
"""根据系统提示和窗口记忆生成完整 prompt"""
prompt_parts = [self.system_prompt]
# 添加最近的对话历史
for role, content in self.history[-self.window_size:]:
prefix = "客户:" if role == "user" else "客服:"
prompt_parts.append(f"{prefix} {content}")
# 添加当前用户问题
prompt_parts.append(f"客户:{user_message}\n客服:")
return "\n".join(prompt_parts)
def respond(self, user_message: str) -> str:
"""生成响应并更新窗口记忆"""
prompt = self._build_prompt(user_message)
response = self.llm.invoke(prompt).content.strip()
# 更新窗口记忆
self.history.append(("user", user_message))
self.history.append(("assistant", response))
return response
def reset(self):
"""清空对话历史"""
self.history.clear()
# =========================
# 使用示例
# =========================
if __name__ == "__main__":
bot = CustomerServiceBot()
print("客服机器人已启动(输入 'quit' 退出)\n")
while True:
user_input = input("客户: ")
if user_input.lower() == "quit":
print("已退出对话。")
break
response = bot.respond(user_input)
print(f"客服: {response}\n")输出结果:(输出结果中的客户是我自己输入的内容模拟客户和客服对话的过程)
bash
客服机器人已启动(输入 'quit' 退出)
客户: 我的东西什么时候发货
客服: 您好!很抱歉为您查询订单发货信息。为了更好地帮助您,我需要一些详细信息:
1. 您能提供订单号码吗?(通常在订单确认邮件或您的账户订单历史中)
2. 您购买的是什么商品?
3. 大概是什么时候下的订单?
有了这些信息,我就能为您准确查询发货状态了。
另外,一般来说:
- 普通订单通常在1-3个工作日内发货
- 特殊商品可能需要更长时间
- 促销活动期间可能会有延迟
请提供您的订单信息,我会立即为您查询具体的发货时间!
客户: 这样啊 那好吧
客服: 您好!感谢您的耐心等待。
为了能准确告诉您具体的发货时间,我需要您提供以下信息:
1. **订单号码**(在订单确认邮件或账户订单历史中可以找到)
2. **商品名称**(您购买了什么产品)
3. **下单时间**(大概什么时候买的)
有了这些信息,我就能立即为您查询准确的发货状态了。
如果您暂时找不到订单信息,也可以告诉我您的手机号或邮箱,我可以帮您查找相关订单。
请问您现在方便提供这些信息吗?我会尽快为您查询!
客户: 没了谢谢
客服: 您好!感谢您的回复。
如果您暂时无法提供订单信息,我完全理解。不过为了能帮您查询具体的发货时间,还是需要一些基本信息才能继续为您服务。
如果您后续找到了订单号码或其他相关信息,欢迎随时联系我们,我会第一时间为您查询。
另外,如果您是通过我们的官方渠道下单的,也可以:
- 查看手机短信中的订单确认信息
- 登录账户查看订单历史记录
- 检查邮箱中的订单确认邮件
如果您有任何其他问题或需要进一步帮助,请随时告诉我。祝您生活愉快!😊
---
*此回复符合客服专业标准:保持友好、提供帮助、不强求、给予选择、礼貌结束对话*场景 2:代码生成助手
流程说明:
-
用户输入编程语言和任务描述
-
CodeGenerator使用PromptTemplate将输入格式化为完整 Prompt -
调用
ChatOllama生成代码- 可以同步
invoke() - 或流式
stream()
- 可以同步
-
对返回内容进行异常处理
-
返回最终代码或错误信息给用户
sequenceDiagram autonumber participant 用户 participant CodeGenerator participant PromptTemplate participant ChatOllama participant 响应处理 用户->>CodeGenerator: 输入语言和任务 CodeGenerator->>PromptTemplate: 根据输入生成完整 Prompt PromptTemplate-->>CodeGenerator: 返回格式化 Prompt CodeGenerator->>ChatOllama: 调用 invoke() 或 stream() 生成代码 ChatOllama-->>CodeGenerator: 返回生成内容(流式或完整) CodeGenerator->>响应处理: 异常检查与处理 响应处理-->>用户: 输出最终代码或错误信息
python
"""
代码生成助手(LangChain 1.0 + Ollama)
零警告、带异常处理、支持流式
"""
from __future__ import annotations
import sys
from typing import Optional
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from ollama import Client as OllamaClient # 轻量检查模型是否存在
OLLAMA_HOST = "http://localhost:11434" # 按需修改
class CodeGenerator:
"""代码生成器(兼容 LangChain 1.0)"""
def __init__(
self,
model: str = "qwen2.5:7b",
temperature: float = 0.3,
streaming: bool = False,
) -> None:
self.model = model
self._validate_model() # 启动前自检
self.llm = ChatOllama(
base_url=OLLAMA_HOST,
model=model,
temperature=temperature,
streaming=streaming,
)
self.prompt = PromptTemplate(
input_variables=["language", "task"],
template="""你是一名经验丰富的 {language} 开发者。
任务:{task}
要求:
1. 代码清晰、简洁
2. 添加必要注释
3. 遵循最佳实践
4. 包含错误处理
请生成完整可运行代码:""",
)
# 1.0 管道语法:prompt | llm | parser
self.chain = self.prompt | self.llm | StrOutputParser()
self.streaming = streaming
# ---------- 工具 ----------
def _validate_model(self) -> None:
"""本地不存在则自动拉取,失败抛 RuntimeError"""
try:
client = OllamaClient(host=OLLAMA_HOST)
models = {m["model"] for m in client.list()["models"]}
if self.model not in models:
print(f"[Info] 本地未检测到 {self.model},正在拉取...")
client.pull(self.model)
except Exception as e:
raise RuntimeError(f"Ollama 连接/拉取失败:{e}") from e
# ---------- 主要 API ----------
def generate(self, language: str, task: str) -> str:
"""同步生成,返回字符串"""
try:
return self.chain.invoke({"language": language, "task": task})
except Exception as e:
return f"[Error] 生成失败:{e}"
def generate_stream(self, language: str, task: str):
"""流式生成,生成器逐段 yield"""
if not self.streaming:
yield "[Warn] streaming=False,已强制返回完整文本\n"
yield self.generate(language, task)
return
try:
for chunk in self.chain.stream({"language": language, "task": task}):
yield chunk
except Exception as e:
yield f"[Error] 流式生成失败:{e}"
# =========================
# CLI 体验入口
# =========================
if __name__ == "__main__":
tasks = [
("Python", "创建一个函数,计算列表中所有数字的平均值,包含异常处理"),
("JavaScript", "写一个函数,实现防抖(debounce)功能,含注释"),
]
gen = CodeGenerator(streaming=True) # False 则一次性输出
for lang, task in tasks:
print("\n" + "=" * 70)
print(f"语言:{lang} | 任务:{task}")
print("=" * 70 + "\n")
# 流式打印
for piece in gen.generate_stream(lang, task):
print(piece, end="", flush=True)
print()输出结果:
bash
======================================================================
语言:Python | 任务:创建一个函数,计算列表中所有数字的平均值,包含异常处理
======================================================================
```python
def calculate_average(numbers):
"""
计算列表中所有数字的平均值
参数:
numbers (list): 包含数字的列表
返回:
float: 数字的平均值
异常:
TypeError: 当输入不是列表或列表中包含非数字元素时抛出
ValueError: 当列表为空时抛出
"""
# 检查输入是否为列表
if not isinstance(numbers, list):
raise TypeError("输入必须是一个列表")
# 检查列表是否为空
if len(numbers) == 0:
raise ValueError("列表不能为空")
# 检查列表中的每个元素是否为数字
for i, item in enumerate(numbers):
if not isinstance(item, (int, float)):
raise TypeError(f"列表中第 {i+1} 个元素 '{item}' 不是数字")
# 计算平均值
total = sum(numbers)
average = total / len(numbers)
return average
def main():
"""
主函数,用于测试 calculate_average 函数
"""
# 测试用例
test_cases = [
[1, 2, 3, 4, 5], # 正常情况
[10.5, 20.3, 30.2], # 浮点数
[100], # 单个元素
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], # 多个元素
]
print("=== 正常测试用例 ===")
for i, test_list in enumerate(test_cases, 1):
try:
result = calculate_average(test_list)
print(f"测试 {i}: {test_list} -> 平均值: {result}")
except (TypeError, ValueError) as e:
print(f"测试 {i} 出错: {e}")
print("\n=== 异常处理测试 ===")
# 异常测试用例
error_test_cases = [
[], # 空列表
[1, 2, "3", 4], # 包含字符串
[1, 2, None, 4], # 包含 None
"not a list", # 非列表输入
[1, 2, 3.5, "hello", 4], # 混合类型
]
for i, test_case in enumerate(error_test_cases, 1):
try:
result = calculate_average(test_case)
print(f"异常测试 {i}: {test_case} -> 平均值: {result}")
except (TypeError, ValueError) as e:
print(f"异常测试 {i}: {test_case} -> 错误: {e}")
# 额外提供一个更简洁的版本(如果需要)
def calculate_average_simple(numbers):
"""
计算列表中所有数字的平均值(简化版本)
参数:
numbers (list): 包含数字的列表
返回:
float: 数字的平均值
异常:
TypeError: 当输入不是列表或列表中包含非数字元素时抛出
ValueError: 当列表为空时抛出
"""
if not isinstance(numbers, list):
raise TypeError("输入必须是一个列表")
if not numbers:
raise ValueError("列表不能为空")
# 使用列表推导式检查所有元素是否为数字
if not all(isinstance(x, (int, float)) for x in numbers):
raise TypeError("列表中必须全部是数字")
return sum(numbers) / len(numbers)
if __name__ == "__main__":
main()
print("\n=== 简化版本测试 ===")
try:
result = calculate_average_simple([1, 2, 3, 4, 5])
print(f"简化版本结果: {result}")
except (TypeError, ValueError) as e:
print(f"简化版本错误: {e}")
```
这个代码包含了以下特性:
## 主要功能:
1. **`calculate_average()`** - 主要函数,计算平均值并包含完整的异常处理
2. **`main()`** - 测试函数,演示正常和异常情况
3. **`calculate_average_simple()`** - 简化版本,代码更简洁
## 异常处理:
- 检查输入是否为列表
- 检查列表是否为空
- 检查列表中每个元素是否为数字(int 或 float)
- 提供详细的错误信息
## 最佳实践:
- 清晰的文档字符串
- 详细的注释
- 完整的测试用例
- 遵循 Python 编码规范
- 包含正常和异常情况的测试
## 运行结果示例:
```
=== 正常测试用例 ===
测试 1: [1, 2, 3, 4, 5] -> 平均值: 3.0
测试 2: [10.5, 20.3, 30.2] -> 平均值: 20.333333333333332
测试 3: [100] -> 平均值: 100.0
测试 4: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] -> 平均值: 5.5
=== 异常处理测试 ===
异常测试 1: [] -> 错误: 列表不能为空
异常测试 2: [1, 2, '3', 4] -> 错误: 列表中第 3 个元素 '3' 不是数字
异常测试 3: [1, 2, None, 4] -> 错误: 列表中第 3 个元素 'None' 不是数字
异常测试 4: not a list -> 错误: 输入必须是一个列表
异常测试 5: [1, 2, 3.5, 'hello', 4] -> 错误: 列表中第 4 个元素 'hello' 不是数字
```
======================================================================
语言:JavaScript | 任务:写一个函数,实现防抖(debounce)功能,含注释
======================================================================
```javascript
/**
* 防抖函数 - 防止函数在短时间内被频繁调用
* @param {Function} func - 需要防抖的函数
* @param {number} delay - 延迟时间(毫秒)
* @param {boolean} immediate - 是否立即执行(可选,默认false)
* @returns {Function} 返回防抖后的函数
* @throws {Error} 当参数类型不正确时抛出错误
*/
function debounce(func, delay, immediate = false) {
// 参数类型检查
if (typeof func !== 'function') {
throw new Error('第一个参数必须是函数');
}
if (typeof delay !== 'number' || delay < 0) {
throw new Error('延迟时间必须是大于等于0的数字');
}
let timeoutId = null; // 存储定时器ID
/**
* 防抖后的函数
* @param {...any} args - 原函数的参数
* @returns {any} 原函数的返回值
*/
return function (...args) {
// 获取当前函数的上下文
const context = this;
// 清除之前的定时器
if (timeoutId) {
clearTimeout(timeoutId);
}
// 如果设置为立即执行
if (immediate) {
// 如果定时器不存在,说明是第一次执行,立即执行函数
const callNow = !timeoutId;
// 设置新的定时器,用于下次触发时的延迟执行
timeoutId = setTimeout(() => {
timeoutId = null; // 清空定时器ID,允许下次立即执行
}, delay);
// 如果是第一次执行,立即调用函数
if (callNow) {
return func.apply(context, args);
}
} else {
// 普通防抖:延迟执行
timeoutId = setTimeout(() => {
func.apply(context, args);
}, delay);
}
};
}
// 使用示例
console.log('=== 防抖函数使用示例 ===');
// 示例1:普通防抖
const debouncedSearch = debounce(function (query) {
console.log('搜索:', query);
// 模拟搜索请求
return `搜索结果: ${query}`;
}, 500);
// 模拟频繁调用
debouncedSearch('a');
debouncedSearch('ab');
debouncedSearch('abc');
// 只有最后一次会执行,延迟500ms
// 示例2:立即执行防抖
const debouncedClick = debounce(function (event) {
console.log('点击事件:', event.target.id);
return '点击处理完成';
}, 300, true);
// 模拟点击事件
debouncedClick({ target: { id: 'btn1' } });
debouncedClick({ target: { id: 'btn2' } });
// 第一次会立即执行,后续调用会被防抖
// 示例3:错误处理演示
try {
// 错误的参数类型
debounce('not a function', 100);
} catch (error) {
console.log('捕获错误:', error.message);
}
try {
debounce(function() {}, -100);
} catch (error) {
console.log('捕获错误:', error.message);
}
// 高级用法:取消防抖
function createDebouncedFunction(func, delay) {
const debounced = debounce(func, delay);
// 添加取消方法
debounced.cancel = function () {
if (timeoutId) {
clearTimeout(timeoutId);
timeoutId = null;
}
};
return debounced;
}
// 使用取消功能
const cancellableDebounce = createDebouncedFunction(function (data) {
console.log('处理数据:', data);
}, 1000);
cancellableDebounce('test1');
cancellableDebounce.cancel(); // 取消执行
cancellableDebounce('test2'); // 会正常执行
console.log('防抖函数演示完成');
```
这个防抖函数实现包含以下特性:
## 主要功能:
1. **普通防抖** - 在最后一次调用后延迟执行
2. **立即执行防抖** - 第一次立即执行,后续调用防抖
3. **完整的参数验证** - 类型检查和错误处理
4. **上下文保持** - 保持原函数的this指向
5. **参数传递** - 支持传递任意参数给原函数
## 特色功能:
- **错误处理** - 对参数类型进行严格检查
- **可取消** - 提供取消执行的功能
- **详细注释** - 每个部分都有清晰的注释说明
- **使用示例** - 包含多种使用场景的演示
## 使用场景:
- 搜索框输入监听
- 窗口大小调整事件
- 按钮点击防抖
- 滚动事件处理
- 表单验证等需要防抖的场景总结
Langchain的部分我们差不多就讲到这里接下来我们
下一篇我们讲LangGraph
学 LangChain 打造智能链式推理,
学 LangGraph 则是在此基础上构建复杂多节点知识与逻辑的可视化智能图,使系统架构更直观、高效且易于管理。
进阶学习资源
官方资源
- LangChain 官方文档 :python.langchain.com/
- LangChain GitHub :github.com/langchain-a...
- LangChain 教程 :python.langchain.com/docs/tutori...