大家好,我是Toby老师,今天为大家带来21篇期刊论文专利复现文章。其中包含多篇顶刊,普刊,985,211高校博士生,研究生毕业论文1篇算法专利文章,1篇会议的审稿论文集,多个期刊配套和算法优化文章。文章附录还有25篇金融风控领域投稿和论文写作相关知识,记得收藏,喜欢可以转发。

1.顶刊复现-客户分组对商业银行个人信用评分模型的提升作用研究,作者张亚京-中国人民银行征信中心博士后工作站
2021年有篇经典论文《客户分组对商业银行个人信用评分模型的提升作用研究》发布。其作者在中国人民银行征信中心博士后工作站工作,发布过多篇金融风控相关论文,在此论文有较深研究,其论文有一定深度。各位学员可以多关注和学习。

摘要:分组模型是指根据借款人的行为特征分出不同的客群,是信用评分模型开发中的重要一环,可以提升信用评分模型的精度。采用模糊C均值聚类和CART决策树两种方法对全部借款人进行分组,并对分组后的每个客群进行WOE数值转换和逻辑回归信用评分模型的构建,通过对比发现分组后信用评分模型的KS和AUC均有提升,其中模糊C均值聚类作为无监督学习方法也取得较好的模型性能。
该论文发布于《征信》,属于核心期刊,更多相关信息请参考文章《客户分组对商业银行个人信用评分模型的提升作用研究,作者张亚京-中国人民银行征信中心博士后工作站 》
2.顶刊复现-供应链金融论文
2017年有篇经典论文<供应链金融模式下企业信用风险评价及其风险管理探究>,下载量上万。


摘要:在当前中小企业融资难的背景下,发展供应链金融这种融资模式成为中小企业融资的重要选择之一。然而,由于供应链金融模式下的信息不对称及风险传染,中小企业存在着较大的信用风险,如何对信用风险进行评价和防控显得尤为重要。笔者在前人研究的基础上,结合互联网金融大数据的思维和数据挖掘方向筛选出了评价指标,建立了供应链金融模式下中小企业信用风险的评价体系和评价模型,采用定性与定量的分析方法评价出中小企业信用风险,发现中小企业的风险最主要还是来自于自身,因此要回归到金融服务实体经济这一本质要求来加强风险管理。在此基础上,笔者建立了银行、核心企业和中小企业的三方博弈模型,分析了供应链金融各参与主体的风险分担原则。最后,依据评价结果和博弈结论,提出了推动中小企业创新发展、建立健全社会信用体系、加强银行风险管理水平等政策建议。
该论文发布于《中央财经大学学报》,属于核心期刊,如何建立供应链金融中中小微企业信用风险评估模型,更多相关信息请参考文章《顶刊复现-供应链金融模式下中小企业信用风险评价及其风险管理研究》。
3.顶刊复现-基于机器学习模型的贷款违约可解释预测
2023年有篇CiteScoreQ1期刊的文章,题目是:《Explainable prediction of loan default based on machine learning models》,翻译为中文:基于机器学习模型的贷款违约可解释预测。


Volume 6, Issue 3, September 2023, Pages 123-133第 6 卷,第 3 期,2023 年 9 月,页码 123-133
XuZhu a徐朱a, Qingyong Chu a清永楚A, Xinchang Song a宋欣昌A, Ping Hu a胡平, Lu Peng a b卢鹏ab
DOI:https://doi.org/10.1016/j.dsm.2023.04.003
论文简介:https://www.sciencedirect.com/science/article/pii/S2666764923000218。
摘要:
随着在线贷款的便利性,越来越多的人选择在网络平台上借款。机器学习技术的出现使得预测贷款违约成为一个热门话题。然而,机器学习模型存在"黑箱"问题,这使得模型的预测规则难以理解,影响用户对模型的信任。为了提高预测模型的可解释性,本研究采用了逻辑回归、决策树,XGBoost和LightGBM模型来预测贷款违约。预测结果显示,LightGBM和XGBoost在预测能力上优于逻辑回归和决策树模型。LightGBM的AUC值为0.7213,准确率和精确度均超过0.8和0.55。此外,本研究还采用了局部可解释模型无关解释方法(LIME)对预测结果进行了可解释性分析,发现贷款期限、贷款等级、信用评级和贷款金额等因素对预测结果有显著影响。
经费支持:
该论文得到武汉理工大学的财政支持。该研究得到中央高校基本科研业务费专项资金(WUT: 2022IVA067)的部分支持。
Toby老师备注一下,能得到科研经费支持的论文一般质量很高,是一个团队耗费大量时间撰写的经典文章。大家要高度关注和仔细阅读有经费支持的论文。
该文章收录期刊Data Science and Management 数据科学与管理,更多相关信息请参考文章《顶刊复现-基于机器学习模型的贷款违约可解释预测》。
4.SCI Q1金融顶刊复现:机器学习小微企业信用风险评估模型
2024年3月发布了一篇SSCI二区金融期刊中的文章《Credit risk assessment of small and micro enterprise based on machine learning》,中文翻译为基于机器学习的小微企业信用风险评估模型。文章DOI地址:https://doi.org/10.1016/j.heliyon.2024.e27096。
摘要:小型微型企业(Small and micro enterprises,简称SMEs)在国家经济和社会发展中起着关键作用。为了促进它们的成长,科学地管理其信用风险至关重要。本研究首先考察这些企业的信用信息。我们采用不平衡样本处理算法,以确保少数类样本的平衡表示。然后,运用机器学习分类器来识别导致这些企业信誉低下的关键因素。基于这些因素,开发了一个基于XGBoost的评分卡模型。研究揭示了以下几点:首先,SMOTE算法与XGBoost模型的结合在处理不平衡数据集时表现出一定的性能优势;其次,可靠的财务信息仍然是关键风险决定因素的核心;第三,基于重要特征的XGBoost评分卡模型有效提高了信用风险评估的准确性。这些见解为增强小型微型企业的稳健性、促进信用风险的早期预警以及完善融资效率提供了理论参考和实用工具。
该论文发布期刊《Heliyon》,属于二区核心期刊(目前被on hold)。更多相关信息请参考文章《SCI Q1金融顶刊复现:机器学习小微企业信用风险评估模型》。
5.中文核心周刊复现-基于逻辑回归的金融风投评分卡模型实现

2020-11-15发布文章《基于逻辑回归的金融风投评分卡模型实现》,下载量上千,比较火爆。
摘要:文以当前银行信贷业务中客户违约问题为出发点,将客户违约率和信贷评分卡分值的关系合理映射。运用逻辑回归建立评分卡预测模型,使用梯度下降算法来实现银行风险投资中客户评分卡的构建。首先加载数据并对数据进行分析,接着划分数据集,并使用跨时间验证集作为模型最后的验证。最后使用KS值和AOC曲线双向评价模型的稳定性。实验证明,采用所提方法构建的评分卡模型具有较好的稳定性。
基金资助: 北京科技创新服务能力建设项目(PXM2016_014223_000025);广东省科技重大专项项目(190826175545233)~~;
该文章发布期刊《计算机科学》,属于核心期刊,更多相关信息请参考文章《中文核心周刊复现-基于逻辑回归的金融风投评分卡模型实现》。
6.期刊复现-深度学习与企业债券信用风险
姜富伟、柴百霖、林奕皓于2024年在《计量经济学报》上发表的论文《深度学习与企业债券信用风险》,提出了一种基于生成对抗网络(GAN)的深度学习模型------CDL,用于企业债券信用风险的预测。本文将带你快速梳理该研究的核心方法、主要发现与复现价值。
**发布时间:**2024年11月
标题title:
深度学习与企业债券信用风险Deep Learning and Corporate Bond Credit Risk
DOI:10.12012/CJoE2024-0092
期刊:计量经济学China Journal of Econometrics

具体内容参考文章《期刊复现-深度学习与企业债券信用风险》
我们公司还支持多种债券机器学习预测模型的期刊论文定制服务-国债,地方债,企业债,信用债,ABS,具体可参考《11种债券概述-国债,地方债,企业债,信用债,ABS》
7.期刊复现-基于Stacking融合模型的信用贷款违约预测的研究
今天发现有篇期刊《基于Stacking融合模型的信用贷款违约预测的研究------以Give Me Some Credit数据集为例》发布与去年,有197次下载量。Toby老师以lightgbm算法为base model尝试简单复现一下。


文章在Give Me Some Credit数据集上构建Stacking模型,使用SMOTE+Tomek Link综合采样法处理非平衡数据。在实证研究上,选择逻辑回归、K近邻、神经网络、随机森林、LightGBM、XGBoost、Adaboost以及CatBoost模型,并将上述模型分3种情况进行Stacking模型融合。结果显示,对此数据集而言,将随机森林、XGBoost、Adaboost、K近邻以及神经网络5个模型作为基学习器,将逻辑回归作为第二层学习器建立Stacking模型的效果最好。因此,利用Stacking模型构建信用贷款违约风险预测模型具有优异的分类性能和较强的可行性。
该文章发布于期刊《信息与电脑》,非核心期刊,更多相关信息请参考文章《论文复现-基于Stacking融合模型的信用贷款违约预测的研究》。
8.期刊复现-基于决策树算法构建银行贷款审批预测模型
今天发现有篇经典期刊下载量非常大,有5000多条。Toby老师尝试简单复现一下。


摘要:农村商业银行控制运营成本、提升经济效益的重要手段是信贷风险管理,但是银行每天都需要处理大量的信贷业务。本文针对农村商业银行信贷业务中风险较高等问题,设计了一种基于决策树算法的信贷风险评估模型。该模型具有较高的准确率,为银行信贷风险评估提供重要决策依据。
该论文发布于期刊《科技资讯》,非核心期刊。更多相关信息请参考文章《论文复现-基于决策树算法构建银行贷款审批预测模型》。
8.期刊复现-ESG表现与农业上市公司财务绩效研究
ESG属于近年金融期刊的热点话题,2025年4月有篇经典论文《ESG表现与农业上市公司财务绩效研究》发布。作者王晓亚,刘潇擎,王美,在此论文属于经典ESG相关论文,各位学员可以多关注和学习。

摘要:ESG理念符合我国推行农业绿色、可持续发展的趋势,不仅可以有效推动农业上市企业财务绩效提升,还有助于实现农业高质量发展。文章以我国A股42家农业上市公司2010---2022年的数据为样本,采用固定效应模型,实证检验农业上市公司ESG表现与财务绩效之间的关系。研究发现:农业上市公司的ESG表现与财务绩效呈正相关关系,良好的ESG表现有利于农业上市公司经济效益向好发展;异质性分析表明,在农林牧渔行业中,农业行业上市公司的ESG表现对财务绩效的促进效应尤为显著,ESG的推动效果较好;相较于大规模企业,小规模企业ESG表现对财务绩效的影响较大。最后从政府、企业、利益相关者三个方面提出建议。
基金资助:
2023山东农业大学课程思政教学改革研究项目(项目编号:S2023025); 山东省自然科学基金(项目编号:ZR2017BG006); 郭牌委托山东农业大学横向课题项目(项目编号:JSS243231);
具体内容见《期刊复现-ESG表现与农业上市公司财务绩效研究》
9.《期刊点评《商业银行数字化转型对经营绩效的影响研究》,作者中国民生银行和清华大学经济管理学院博士后》
2024年论文《商业银行数字化转型对经营绩效的影响研究》由姚益家撰写,主要探讨了数字经济时代商业银行数字化转型对其经营绩效的影响。论文选取了2017至2021年中国32家上市商业银行的年度经营数据,构建了指标体系,测度了商业银行数字化转型指数,并在此基础上实证检验了数字化转型对经营绩效的影响效应。发布情况《中国市场》。《中国市场》曾是北大核心期刊,入选《中文核心期刊要目总览》2004年版贸易经济类核心期刊,但目前不是北大核心期刊。不过,它是中国社会科学院引文数据库来源期刊、中国人民大学"复印报刊资料"重要转载来源期刊、RCCSE中国核心学术期刊。《期刊点评《商业银行数字化转型对经营绩效的影响研究》,作者中国民生银行和清华大学经济管理学院博士后》
10.SHAP PK LIME评估用于网络入侵检测的黑盒可解释 AI 框架
今天Toby老师分享一篇论文《E-XAI: Evaluating Black-Box Explainable AI Frameworks for Network Intrusion DetectionE-XAI:评估用于网络入侵检测的黑盒可解释 AI 框架》,详细描述了多个数据集SHAP PK LIME实验。一山不容二虎,到底谁更优秀,接下来看完这篇文章就知。
论文地址:https://ieeexplore.ieee.org/abstract/document/10433134

这篇论文为网络入侵检测领域提供了一个重要的评估工具,有助于理解和改进AI模型的可解释性。
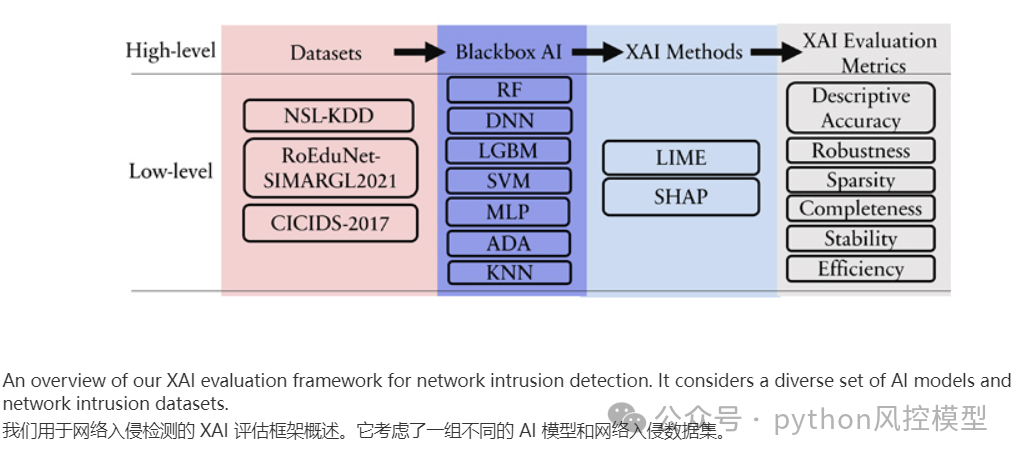
更多相关信息请参考文章《期刊点评-评估用于网络入侵检测的黑盒可解释 AI 框架,SHAP PK LIME实验测评!》。
11.毕业论文复现-《基于随机森林模型的个人信用风险评估研究》
2018年有篇经典硕士研究生毕业论文,789下载量。论文标题是《基于随机森林模型的个人信用风险评估研究》。作者是湖南大学学生,属于985高校。


摘要:随着网络科技的迅猛发展和个人贷款需求的不断上升,我国个人信贷产品的市场潜力逐渐显出,个人信贷行业俨然成为金融市场竞争的热点。在银行和金融机构发展个人信贷产品时,需要解决的主要问题就是信用风险。但目前我国金融机构缺乏对信用风险评估的深究,个人征信系统尚不成熟,仍处于初期探索阶段。如何有效地评估和度量个人信用风险水平,是银行和金融机构从源头降低不良资产的关键所在。因而,研究个人信用风险水平的重要特征,建立好个人信用体系,选择合适的个人信用风险评估模型,是我国金融市场在个人信贷产业健康发展的核心课题。本文选择随机森林模型对个人信用风险进行评估研究,该模型对噪声数据容忍度高,能有效防止过拟合且运算速度快。与传统的风险评估模型相比,可以更好地解决个人信用风险评估问题。本文采用美国著名P2P公司Lending Club2017年第三季度的42535条样本做为基础数据集,建立了个人信用体系和评估模型。首先对数据进行缺失值处理及相关性检验;接着,对特征选取方式进行了优化,引入了 Boruta特征选择算法筛选出合理的指标变量;然后,用SMOTE算法优化训练集,改善数据的不平衡度,提高负类样本的预测精度,并据此建立了基于随机森林模型的个人信用风险评估方法;最后,将随机森林模型与逻辑回归模型进行对比。结果表明,无论是原始不平衡数据集还是经过SMOTE算法处理后的平衡数据集,基于随机森林模型的个人信用风险评估结果都要优于基于逻辑回归模型个人信用风险评估结果。在经过SMOTE处理后的平衡数据训练集建模后,两类学习模型的样本准确率均有显著提高,随机森林模型的负类训练集合测试集的样本预测准确率分别从2.0%和0.7%提升至79.5%和64.1%,逻辑回归模型的负类样本预测准确率从0.1%和0.0%提升至62.6%和21.0%;随机森林模型不仅对负类样本的预测精度提升效果要远远好于逻辑回归模型,其总体准确率84.7%和82.4%也要显著高于逻辑回归模型的预测准确率62.6%和63.2%。这充分证明了随机森林模型在个人信用风险评估中的适用性和有效性。
更多相关信息请参考文章《 论文复现和点评《基于随机森林模型的个人信用风险评估研究》》。
12.985博士论文复现-基于数据挖掘的信用卡个人信用风险评估研究
题目:基于数据挖掘的信用卡个人信用风险评估研究
作者:张秋菊
北京理工大学
北京市211工程院校985工程院校一流大学
摘要
近年来,随着我国经济不断发展,居民收入水平持续提高,购买力越来越强,作为主要支付结算方式之一的信用卡也得到了普遍的推广。与之伴随的是信用卡风险问题不断升级。对信用卡用户进行信用风险评估对银行降低风险、减小损失意义重大。
本研究在回顾国内外目前对于信用卡风险评估的一些研究现状的基础上,分析了信用卡风险的概念和特点、信用卡风险的类型,并比较了个人信用风险评估常用的几种技术方法的优劣点。
然后,针对信用卡申请时的信用风险评估问题,考虑到信用卡申请人递交的申请资料冗余属性多的特点,建立了基于随机森林的属性约简模型。又由于银行在实际处理信用卡申请的过程中,大多产生的是不平衡数据,本研究结合前人的一些数据处理方法,提出了对数据进行再平衡的SMOTE-UNDER方法,并在一些UCI数据集上进行了实验,实验结果表明,本研究提出的方法确实能有效处理不平衡数据的分类问题。
在此基础上,本研究提出了基于GA-SVM的信用卡客户申请人信用风险评估模型。该模型利用遗传算法对SVM的两个重要参数进行优化,能有效提高预测精度。
针对交易阶段的持卡人信用风险细分问题,本研究通过对一般常见的信用风险的类型及其在交易行为上的表现进行分析,提出了相应的风险评估方法。
关键词:信用卡;信用风险;风险管理;数据挖掘;风险评估;逾期还款
专辑 :经济与管理科学
专题 :金融
DOI :10.26948/d.cnki.gbjlu.2017.000903
分类号 :F832.4
导师 :李金林
学科专业 :管理科学与工程
博士电子期刊出版信息 :
年期:2021年第07期
网络出版时间:2021-06-16---2021-07-15
更多信息参考《985博士论文复现-基于数据挖掘的信用卡个人信用风险评估研究》
13.硕士毕业论文复现-《基于Logistic模型的汽车金融公司个人贷款信用评分研究》
2017年发布一篇经典研究生毕业论文《基于Logistic模型的汽车金融公司个人贷款信用评分研究》,有900多次下载量。作者是西南大学研究生,属于211高校。

摘要:我国现正处于经济高速发展时期,汽车产业正是支撑经济增长的重要组成部分。而在整个汽车产业链中,汽车金融业的利润占到了近20%。汽车金融公司作为专业从事该行业的金融机构,随着利润的增长近几年内相继成立。中国个人汽车按揭贷款买车量占汽车销售总量的比例,即贷款渗透率在10年前尚不足5%,目前已经达到25%-35%,但距离很多发达国家70%以上的渗透率相比还有很大的差距。因此,我国汽车金融市场有着巨大的发展潜力,到2020年中国汽车金融的渗透率将达到50%,市场规模将达到2万亿元。但与国外成熟汽车金融市场相比,目前国内汽车金融市场还很混乱。由于存在信用体系建设不完善、个人收入信息不透明、地域广阔、人口流动性较大等客观原因,以及贷款审核效率不能满足市场需求、个人信用评级不完善等主观因素,造成了汽车金融公司违约风险的增加。因此,研究汽车金融公司如何通过个人信用评级来有效地控制违约风险就具有理论和现实意义。本文首先对国内外汽车金融的历史发展和现状进行了研究,并对国内汽车金融公司当前存在的问题及风险进行了阐述。然后对国内某大型汽车金融公司近三年个人汽车贷款客户的信息和还款记录进行了分析,研究如何通过建立信用评分模型来有效的对客户进行风险等级评估,从而提高审核效率和降低违约风险。研究过程中抽取了该公司近3年约25000名客户的资料,并通过问卷调查、借鉴行业先进经验等方式从基础信息、贷款信息及征信信息等筛选出了对个人汽车贷款风险有显著影响的8个变量,然后利用其中18592名客户进行Logistic回归建立个人信用评分模型,7970个客户用于验证个人信用评分模型区分能力。经分析检验表明:建立的评分模型的所有变量回归系数为负数,WALD检验P<0.05,模型变量趋势与实际业务含义一致;方差膨胀系数VIF<10,模型不存在多重共线性;K-S值为32.59,GINI系数为44.82,模型对好坏账户有较好的区分能力。最后根据评分模型对个人汽车贷款客户进行信用评级,根据其评级结果审核人员对客户实行差异化的审核,有效地提高了审核效率,还能较好地控制了个人汽车贷款风险。研究过程中还发现,个人数据资料的真实性、完整性是保证评分模型可靠的关键。同时,本文还研究提出了提高汽车金融公司风险防范能力的措施和办法:加强内部培训,提高审核人员综合素质和业务技能;根据等级评分模型统一审核要求;建立审核人员的资格认证,建立淘汰制度;针对不同评级客户实行差异化审核政策和建立不同的金融产品;建立完善贷后管理,建立风险共担的金融风险体制,明确单个客户风险监控主责任人,建立责任人负责制度和重点客户管理制度。
这项研究为汽车金融公司在信用评级和风险控制方面提供了理论和实践指导。
更多相关信息请参考文章《论文复现-基于Logistic模型的汽车金融公司个人贷款信用评分研究》。
14.985硕士毕业论文复现-A汽车金融公司零售信贷风险管理优化研究
今天看到一篇研究生毕业论文《A汽车金融公司零售信贷风险管理优化研究》。下载量上千。作者是华东师范大学学生,属于985高校。


摘要如下:
自2018年以来,汽车市场发展增速放缓,汽车金融领域的竞争不断加剧。目前,我国持牌经营汽车金融公司数量已达25家。与银行系汽车金融业务不同,汽车金融公司虽然在规模上无法与银行相比,但是,在专业化服务的提供方面,汽车金融公司有着得天独厚的优势。尽管如此,由于我国信用体系建设覆盖面不全,缺乏汽车金融专业人才等因素,汽车金融公司在风险管理方面,还存在着不少问题,其中,尤其以信贷风险问题最为突出。本文以A汽车金融公司为例,研究其在信贷风险管理过程中产生的问题,针对性地提出优化方案,评估实施效果。在内容编排上,本文首先梳理了A汽车金融公司信贷风险管理现状。在此基础上,指出了其在信贷风险管理过程中存在的问题。即,贷前管理阶段的信贷资产质量下降、欺诈风险增大和人工审核效率低下的问题;贷中管理阶段的信贷档案缺失度高的问题;以及贷后管理阶段催收效率低下的问题。其后,本文运用数据驱动、问卷调研等多种研究方法,梳理了上述问题的成因。即,由于贷前管理阶段缺乏科学有效的信贷风险计量手段、缺少有效的欺诈风险侦测手段和审批自动化程度低;贷中管理阶段不规范的经销商管理;和贷后管理阶段催收管理制度缺失和催收策略固化的原因导致了上述问题的产生。本文后续针对上述问题针对性地提出了优化方案,即,贷前管理阶段建立信用评分模型、反欺诈系统和优化规则引擎,贷中管理阶段建立经销商管理体系及贷后管理阶段加强委外催收管理和建立动态催收策略体系。同时,为保障优化方案的顺利实施,本文提出了强化风险文化建设、加强人员培训机制、建立科学考核体系和完善信息技术基础设施的保障措施。最后,在结论部分梳理优化成果并加以推广,为同业提供经验借鉴。
Toby老师复现汽车金融反欺诈信用评分模型,更多相关信息请参考文章《论文复现-汽车金融信用评分模型 》。
15、硕士毕业论文复现-基于机器学习的消费信贷违约概率预测模型研究
摘要:随着信息化建设和大数据技术的高速发展,信贷业务的审批速度由以前的7到20天的审批周期到现在的秒申秒贷,用户的业务体验得到了极大的提升,同时国家扶持力度也在不断加大,因此消费信贷领域的用户规模也在极具增加,且未来发展潜力依旧巨大,伴随着消费信贷规模急剧增长而来的是巨大的用户违约风险,再加上新冠疫情的影响,在今后的一段时间内,不良贷款率预计仍会有比较明显的上升压力。为了精准的对消费信贷领域的用户违约概率进行预测,达到控制信用风险的目的,本文通过stacking策略构建了一种信贷违约概率预测模型,并引入了一种基于SHAP解释器的模型解释机制,在追求模型预测效果和模型稳定性的同时,也兼顾了预测结果的可解释性,具体研究内容如下:首先,对论文数据进行预处理,处理措施包括缺失值填补、数据去重、异常点检测,将处理好的数据进行归纳整理,为之后构建模型做准备。在特征筛选阶段,基于IV、PSI以及树模型的featureimportance对特征进行筛选,在保证模型效果相差不大的情况下,减少入模变量,从而有效的降低了模型复杂度,增加了模型的跨时间稳定性。其次,基于stacking策略构建了...
关键词:
信用风险;信贷违约概率预测;集成学习;深度学习;模型可解释性;
-
专辑:
基础科学;经济与管理科学
-
专题:
数学;宏观经济管理与可持续发展;金融;投资
-
DOI:
10.27006/d.cnki.gdbcu.2022.000593
-
分类号:
F832.479;F224
导师:佟婷婷
学科专业:应用统计
硕士电子期刊出版信息:
年期:2023年第02期 网络出版时间:2023-01-16---2023-02-15
我方公司可复现毕业论文,并且提供多头借贷实证分析数据集和代码,具体可参考文章《基于机器学习的多头借贷预测模型》

16、985南开大学-基于机器学习方法的企业非法集资风险预测
今天看到一篇研究生毕业论文《基于机器学习方法的企业非法集资风险预测》。下载量上千。作者是南开大学学生,属于985高校。

近年来,非法集资以互联网平台为依托,在民间资本市场中迅速发展,给民间资本的安全和监管带来了无法忽视的风险问题,社会损害日益严重。我国非法集资涉案的数量与金额逐年扩大,打击非法集资的形势仍然严峻。如何根据企业信息数据建立预测模型,判断企业是否存在非法集资风险,研发基于政务大数据和社会大数据融合的企业全息画像系统,为企业提供精准的画像和服务,对于掌握全面可靠信息、及时防范企业非法集资风险具有重要的意义和价值。
在研究企业非法集资风险的相关文献后,利用CCF BDCI已经脱敏处理过的真实数据,对企业的各项信息数据通过四种机器学习模型展开分析与挖掘,预测企业为非法集资企业的风险。
更多信息参考文章《基于机器学习方法的企业非法集资风险预测-南开大学论文复现》
17、基于KMV---Logistic混合模型的城投债信用风险研究
作者:梁银香,齐林,贵州大学经济学院
摘要:为了准确衡量城投债的信用风险,本文首先运用KMV模型估算2023-2026年不同城投债债务规模下的预期违约概率,随后选取12个指标对影响城投债信用风险的因素进行有序逻辑回归分析。结果发现:第一,当可担保财政收入为地方政府财政收入的30%时,到期城投债的债务规模已超过安全债务规模,具有一定的违约风险。第二,城投企业的获利能力、短期偿债能力和当地的财政实力等因素与城投债的信用风险水平呈负相关关系,而城投债发行的票面利率、发行规模和当地政府的债务率等因素则与城投债的信用风险水平呈正相关关系。最后,基于研究结论提出推动经济可持续发展、积极引导平台市场化转型、有序置换隐性债务和拉长偿债期限、提升信息披露的透明度等政策建议。
关键词:
城投债;信用风险;多元有序;Logistic模型;KMV模型;
-
专辑:
经济与管理科学;基础科学
-
专题:
数学;财政与税收;金融;证券
-
分类号:
F812.5;O212.1;F832
-
在线公开时间:
2024-09-30 17:10(知网平台在线公开时间,不代表文献的发表时间)
我方公司可提供城投企业债务数据和代码复现,具体可参考《期刊复现-城投企业信用风险预测模型》和《KMV模型预测上市公司信用风险-(附Python代码),实战绿地控股违约概率》
18、论文复现NGBoost Interpretation Using LIME
LIME和NGboost结合技术在互联网上非常少,百度谷歌基本找不到资料,但这本书却有记载https://link.springer.com/chater/10.1007/978-3-030-63322-6_76。
今天复现书籍《Software Engineering Perspectives in Intelligent Systems》的文章《NGBoost Interpretation Using LIME for Alcoholic EEG Signal Based on GLDM Feature Extraction》。
《Software Engineering Perspectives in Intelligent Systems》书籍概述
这本书是第4届计算方法在系统和软件中应用(CoMeSySo 2020)会议的审稿论文集。软件工程、计算机科学和人工智能是智能系统问题领域研究的关键主题。CoMeSySo 2020会议打破了传统限制,以线上形式举办,旨在为讨论最新的高质量研究成果提供一个国际论坛。

文章概述
NGBoost是一种预测概率分布的提升算法。在应用于经过灰度差异矩阵(GLDM)特征提取的酒精脑电图(EEG)信号时,由于其黑箱特性,得到的模型难以解释。在本研究中,使用LIME对NGBoost在酒精EEG数据集上的实现及其解释进行了研究。之所以使用LIME技术,是因为它在解释其他黑箱模型(如神经网络和支持向量机)时被证明是可靠的。通过对3个测试数据进行的实验,结果显示LIME能够解释NGBoost在酒精EEG数据集使用时的工作原理。此外,所得到的三个结果表明,在旋转角度为和时,逆差分矩特征是影响NGBoost模型预测"酒精"或"对照"(非酒精)概率的最重要特征。
更多相关信息请参考文章《论文复现NGBoost Interpretation Using LIME》。
19.期刊优化:使用SHAP解释基于深度学习的银行信贷违约模型
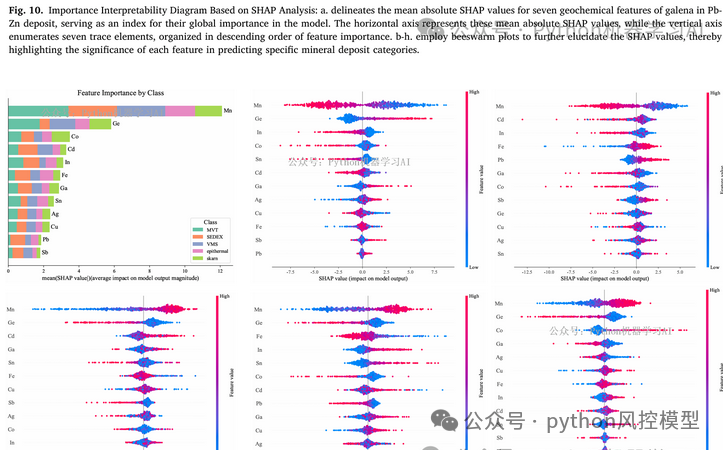
在文献中,研究人员利用深度学习技术来分析Galena(方铅矿)的微量元素数据,以此来区分不同类型的Pb-Zn(铅锌)矿床。他们采用了SHAP(SHapley Additive exPlanations)分析方法,来解释模型是如何根据Galena中的微量元素数据来区分不同类型矿床的。我方公司复现该技术使用SHAP解释基于深度学习的银行信贷违约模型。
20.期刊复现:SCI一区数据缺失率可视化-帕雷托图(Pareto Chart)
图片中展示的是一篇发表在《老年学杂志A:生物科学和医学科学》(The Journals of Gerontology, Series A: Biological Sciences and Medical Sciences)上的论文。论文的标题是"使用机器学习模型预测社区居住的中老年人未来衰弱:ELSA队列研究"(Machine Learning Models to Predict Future Frailty in Community-Dwelling Middle-Aged and Older Adults: The ELSA Cohort Study)。重庆未来之智Toby老师复现帕雷托图,并对不同变量缺失率用不同颜色表示。
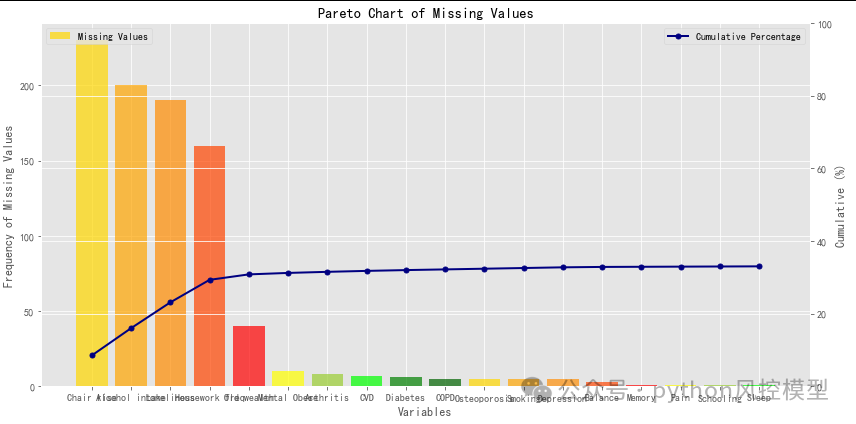
具体内容见《期刊复现:SCI一区数据缺失率可视化-帕雷托图(Pareto Chart)》
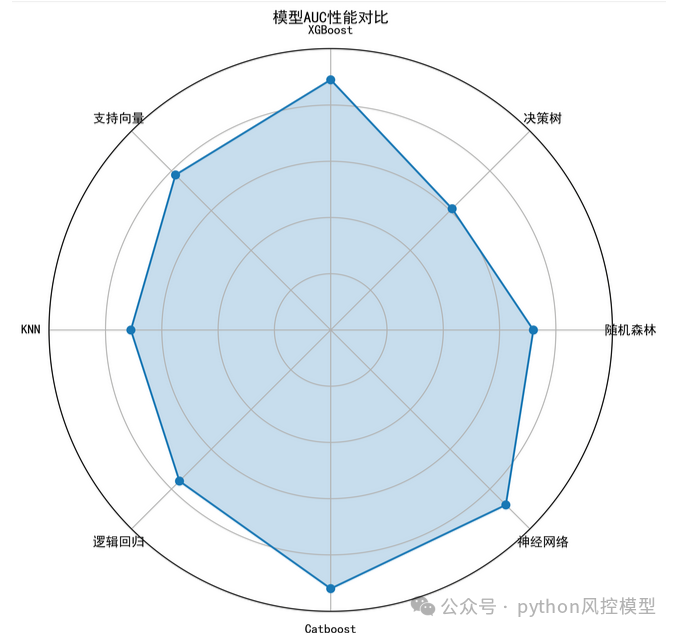
21.期刊配图复现:基于雷达图Radar Chart的多机器学习模型指标对比
期刊文章《年轻女性急性心肌梗死患者:1年住院再入院风险预测模型》中用了雷达图。


重庆未来之智的Toby老师复现了期刊中雷达图,用于金融风控建模项目,可表达多模型AUC性能对比,并且修复中文显示出错bug,如下图。通过雷达图我们可以清楚看到不同算法建模后性能有显著差异的,此项目中决策树效果非常差。
下图是Toby老师用《python信用评分卡建模(附代码)》课程的give me some credit案例建立的模型验证雷达图。如下图模型accuracy,AUC很高,sensitivity和f1分数很低。通过雷达图可以轻松推断该数据集属于严重的非平衡数据集。
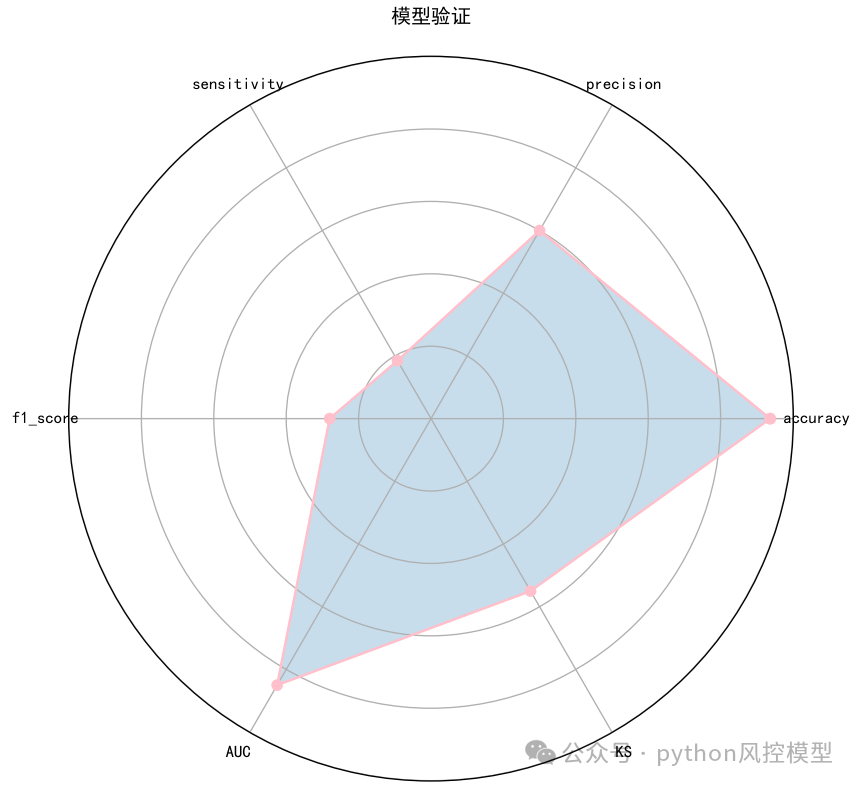
具体内容参考《期刊配图复现:基于雷达图Radar Chart的多机器学习模型指标对比》
22.算法专利复现_基于ngboost和SHAP值可解释预测方法
2021年3月2日发布一篇专利,名称是《基于NGBoost和SHAP值的可解释地震动参数概率密度分布预测方法》。
更多相关信息请参考文章《算法专利复现_基于ngboost和SHAP值可解释预测方法》。
论文期刊投稿写作相关链接
《金融风控类期刊-编辑部初审流程(Desk Review)》
《金融风控期刊-同行评审(Peer Review)流程详解》
《金融风控领域的顶级学术期刊有哪些? 附JCR分区和中科院分区评分》