官方链接:
Github :https://github.com/unclecode/crawl4ai
文档主页:https://docs.crawl4ai.com/
当前版本:Crawl4AI v0.5.0
主要新功能:
- 可配置策略(广度优先、深度优先、最佳优先)探索整个网站。
- 根据可用内存动态调整并发性。
- 可 Docker 部署
- 有命令行界面 (CLI)
- LLM配置 (LLMConfig):方便 LLM模型用于提取、过滤和模式生成。
次要更新和改进:
- LXML爬取模式:使用LXMLWebScrapingStrategy进行更快的HTML解析。
- 代理轮换:添加了ProxyRotationStrategy,并实现了RoundRobinProxyStrategy。
- PDF处理:从PDF文件中提取文本、图像和元数据。
- URL重定向跟踪:自动跟踪并记录重定向。
- 遵守Robots.txt:可选择性地遵守网站爬取规则。
- LLM驱动的模式生成:使用LLM自动创建提取模式。
- LLMContentFilter:使用LLM生成高质量、重点突出的markdown。
- 改进的错误处理和稳定性:众多错误修复和性能增强。
- 增强文档:更新指南和示例。
安装 Crawl4AI
系统环境:
- Windows 11 Professional 与 Ubuntu24
- Python 3.12
安装过程:
1. 基础安装
在 Windows 11 CMD
pip install crawl4ai在 Ubuntu24 中运行:
python3 -m venv -venv
source venv/bin/activate
pip install crawl4ai安装核心库与基本依赖内容,不包含任何高级功能。
装了一堆:

2. 自动设置
crawl4ai-setup自动完成浏览器安装、系统兼容性检查和环境验证:
Ubuntu 24:
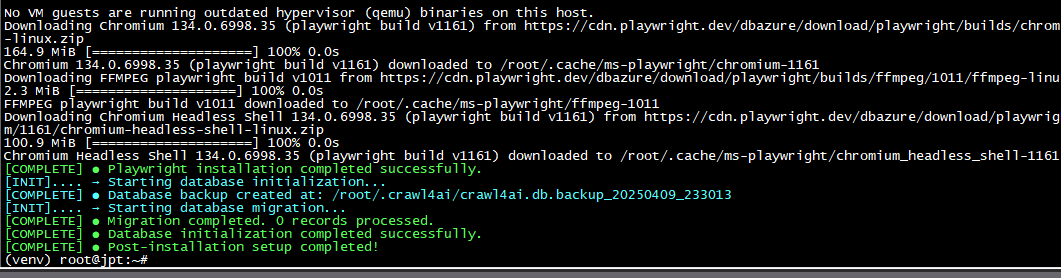
Windows 11:
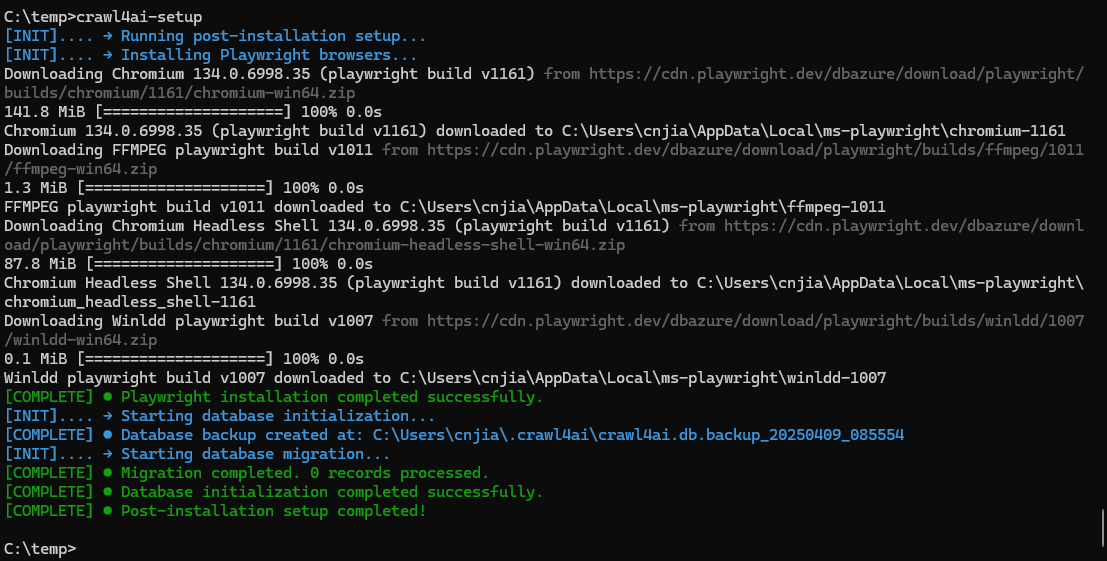
3. 校验安装
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.google.com",
)
print(result.markdown[:300]) # Show the first 300 characters of extracted text
if __name__ == "__main__":
asyncio.run(main())正常是:

4. 安装诊断命令
crawl4ai-doctor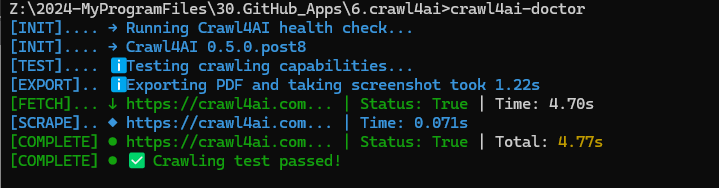
使用 Crawl4AI
基本的 CLI 方式:
1. 指定格式输出,参数:-o 或 --output all\|json\|markdown\|md\|markdown-fit\|md-fit
crwl https://docs.crawl4ai.com/ -o markdown2. 不使用已经存在的缓存,从服务器获取最新内容,参数: -b , --bypass-cache
crwl https://docs.crawl4ai.com/ --bypass-cache
crwl https://docs.crawl4ai.com/ -b3. 带有详细的运行信息和日志, 参数: -v, --verbose
详细信息:
- 爬取的每个步骤
- 请求和响应的详情
- 遇到的问题或警告
- 处理过程中的状态变化
- 性能相关的信息(如加载时间)
对于调试问题或了解程序的工作方式特别有用。如网站爬取失败或结果不符合预期,verbose 模式可以帮助你确定问题出在哪里。
crwl https://docs.crawl4ai.com/ -v
crwl https://docs.crawl4ai.com/ --verbose4. 指定提取策略的文件 参数: -e, --extraction-config PATH
crwl https://docs.crawl4ai.com/ -e [策略文件路径]
crwl https://docs.crawl4ai.com/ --extraction-config [策略文件路径]自定义爬虫如何从网页中提取内容的详细规则和策略,可以精确控制数据提取,使用YAML或JSON格式结构。
1) 提取策略配置文件的主要功能
- 指定使用哪种类型的选择器(CSS、XPath、正则表达式等)来定位页面元素
- 定义如何处理和转换提取的原始内容
- 删除多余空格、HTML标签
- 将价格文本转为数字
- 内容分割和合并
- 支持嵌套数据结构的提取
- 先定位父元素,再从父元素中提取子元素
- 处理列表、表格等复杂结构
- 指定条件,决定是否提取内容
- 如:只提取含有特定关键词的段落
- 定义在多页面间导航以提取内容
- 分页处理
2) 例:从Amazon产品页面提取DEWALT电动工具的各种信息
主要提取内容
- 基本信息:标题、品牌、型号、ASIN
- 价格信息:当前价格、原价、优惠状态
- 产品图片:主图及所有备选图片
- 技术规格:电压、扭矩、重量、尺寸等
- 产品特点:所有列出的产品特性
- 评论数据:平均评分和评论数量
- 可用性:库存状态和配送选项
- 分类信息:主类别和面包屑导航中的子类别
- 相关产品:经常一起购买的商品
文件名:C:\temp\dewalt-extraction-strategy.yaml
extraction_strategies:
# Basic product information
- name: "product_title"
selector_type: "css"
selector: "#productTitle"
attribute: "text"
transform: "trim"
target_field: "productBasicInfo.title"
- name: "product_brand"
selector_type: "css"
selector: "#bylineInfo"
attribute: "text"
transforms:
- "trim"
- "regex_replace:Brand: (.*)|Visit the (.*) Store|(.*) Store|$1$2$3"
target_field: "productBasicInfo.brand"
- name: "product_model"
selector_type: "css"
selector: "tr.po-model_name td.po-model_name"
attribute: "text"
transform: "trim"
target_field: "productBasicInfo.model"
- name: "product_asin"
selector_type: "css"
selector: "tr:contains('ASIN') td.a-span9"
attribute: "text"
transform: "trim"
target_field: "productBasicInfo.asin"
# Price information
- name: "current_price"
selector_type: "css"
selector: ".priceToPay .a-offscreen"
attribute: "text"
transforms:
- "trim"
- "regex_replace:\\$(.*)$|$1"
- "to_number"
target_field: "pricing.currentPrice"
- name: "original_price"
selector_type: "css"
selector: ".basisPrice .a-offscreen"
attribute: "text"
transforms:
- "trim"
- "regex_replace:\\$(.*)$|$1"
- "to_number"
target_field: "pricing.originalPrice"
- name: "deal_badge"
selector_type: "css"
selector: "#dealBadge"
exists_as: "dealAvailable"
target_field: "pricing.dealAvailable"
# Images
- name: "product_images"
selector_type: "css"
selector: "#landingImage"
attribute: "data-old-hires"
target_field: "images"
is_list: true
- name: "alternate_images"
selector_type: "css"
selector: "#altImages .item img"
attribute: "src"
transforms:
- "regex_replace:(.*)\\._.*\\.jpg$|$1.jpg"
target_field: "images"
append: true
is_list: true
# Technical details
- name: "voltage"
selector_type: "css"
selector: "tr:contains('Voltage') td.a-span9"
attribute: "text"
transform: "trim"
target_field: "technicalDetails.voltage"
- name: "torque"
selector_type: "css"
selector: "tr:contains('Torque') td.a-span9, tr:contains('Maximum Torque') td.a-span9"
attribute: "text"
transform: "trim"
target_field: "technicalDetails.torque"
- name: "weight"
selector_type: "css"
selector: "tr:contains('Item Weight') td.a-span9"
attribute: "text"
transform: "trim"
target_field: "technicalDetails.weight"
- name: "dimensions"
selector_type: "css"
selector: "tr:contains('Product Dimensions') td.a-span9"
attribute: "text"
transform: "trim"
target_field: "technicalDetails.dimensions"
- name: "battery_included"
selector_type: "css"
selector: "tr:contains('Batteries Included') td.a-span9"
attribute: "text"
transforms:
- "trim"
- "to_boolean:Yes=true,No=false"
target_field: "technicalDetails.batteryIncluded"
- name: "cordless"
selector_type: "css"
selector: "tr:contains('Power Source') td.a-span9"
attribute: "text"
transforms:
- "trim"
- "to_boolean:Battery Powered=true,*=false"
target_field: "technicalDetails.cordless"
# Features
- name: "features"
selector_type: "css"
selector: "#feature-bullets .a-list-item"
attribute: "text"
transform: "trim"
target_field: "features"
is_list: true
# Reviews
- name: "average_rating"
selector_type: "css"
selector: "#acrPopover .a-declarative"
attribute: "title"
transforms:
- "regex_replace:(.*) out of 5 stars|$1"
- "to_number"
target_field: "reviews.averageRating"
- name: "number_of_reviews"
selector_type: "css"
selector: "#acrCustomerReviewText"
attribute: "text"
transforms:
- "regex_replace:([0-9,]+) ratings|$1"
- "regex_replace:,||g"
- "to_number"
target_field: "reviews.numberOfReviews"
# Availability
- name: "in_stock"
selector_type: "css"
selector: "#availability"
attribute: "text"
transforms:
- "trim"
- "to_boolean:In Stock=true,*=false"
target_field: "availability.inStock"
- name: "delivery_options"
selector_type: "css"
selector: "#deliveryBlockMessage .a-list-item"
attribute: "text"
transform: "trim"
target_field: "availability.deliveryOptions"
is_list: true
# Warranty
- name: "warranty"
selector_type: "css"
selector: "tr:contains('Warranty Description') td.a-span9"
attribute: "text"
transform: "trim"
target_field: "warranty"
# Category info
- name: "main_category"
selector_type: "css"
selector: "#wayfinding-breadcrumbs_feature_div li:last-child"
attribute: "text"
transform: "trim"
target_field: "categoryInfo.mainCategory"
- name: "sub_categories"
selector_type: "css"
selector: "#wayfinding-breadcrumbs_feature_div li:not(:last-child)"
attribute: "text"
transform: "trim"
target_field: "categoryInfo.subCategories"
is_list: true
# Frequently bought together
- name: "frequently_bought_together"
selector_type: "css"
selector: "#sims-consolidated-2_feature_div .a-carousel-card h2"
attribute: "text"
transform: "trim"
target_field: "frequentlyBoughtTogether.name"
is_list: true
- name: "frequently_bought_together_links"
selector_type: "css"
selector: "#sims-consolidated-2_feature_div .a-carousel-card a"
attribute: "href"
transform: "trim"
target_field: "frequentlyBoughtTogether.url"
is_list: true运行:
crwl https://a.co/d/17HZeGj -e dewalt-extraction-strategy.yaml -s dewalt-schema.json因为:
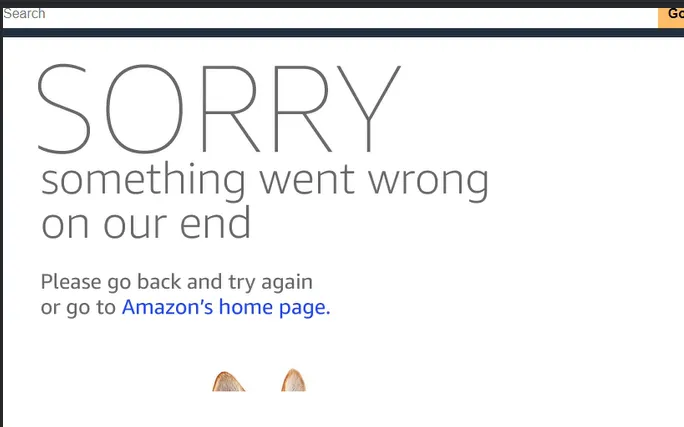 可能是太频繁,或我的 VPN 有在黑名单,没抓到数据。
可能是太频繁,或我的 VPN 有在黑名单,没抓到数据。
5. 指定一个JSON模式(JSON schema)文件的路径 参数:-s, --schema PATH
crwl https://docs.crawl4ai.com/ -s [JSON schema 文件的路径]
crwl https://docs.crawl4ai.com/ --schema [JSON schema 文件的路径]可以用 JSON schema (该模式) 文件来定义:从网站提取内容时的结构化的数据格式,如:
- 从网页中提取的数据的结构、属性和数据类型。它作为一个"模板",告诉爬虫工具应该提取哪些信息以及如何组织这些信息。
- 当爬虫处理网页时,它会根据提供的JSON模式来识别和提取符合该模式定义的数据元素,然后将它们组织成符合模式结构的输出。
例:从 Amazon.com 抓取 电动工具
从 Amazon.com 抓取 电动工具:DEWALT ATOMIC 20V MAX* 3/8 in. Cordless Impact Wrench with Hog Ring Anvil (Tool Only) (DCF923B)
链接(商品): https://a.co/d/cfTKG4j
内容包括:
- 基本产品信息:标题、品牌、型号和ASIN号
- 价格信息:当前价格、原价和折扣
- 产品图片:所有产品图片的URL数组
- 技术规格:电压、扭矩、速度、重量、尺寸等
- 产品特点:产品特性和优势的列表
- 分类信息:主类别和子类别
- 评论数据:平均评分、评论数量和评分分布
- 可用性信息:库存状态和配送选项
- 保修信息:产品保修详情
- 相关产品:兼容配件和经常一起购买的产品
文件名:C:\temp\dewalt-schema.json
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Amazon Power Tool Product Schema",
"description": "Schema for extracting DEWALT impact wrench product details from Amazon",
"type": "object",
"properties": {
"productBasicInfo": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "Full product title"
},
"brand": {
"type": "string",
"description": "Product brand name"
},
"model": {
"type": "string",
"description": "Model number of the product"
},
"asin": {
"type": "string",
"description": "Amazon Standard Identification Number"
}
},
"required": ["title", "brand", "model"]
},
"pricing": {
"type": "object",
"properties": {
"currentPrice": {
"type": "number",
"description": "Current listed price"
},
"originalPrice": {
"type": "number",
"description": "Original price before any discounts"
},
"discount": {
"type": "number",
"description": "Discount percentage if available"
},
"dealAvailable": {
"type": "boolean",
"description": "Whether the product has an active deal"
}
},
"required": ["currentPrice"]
},
"images": {
"type": "array",
"items": {
"type": "string",
"format": "uri",
"description": "URL of product image"
},
"description": "Collection of product image URLs"
},
"technicalDetails": {
"type": "object",
"properties": {
"voltage": {
"type": "string",
"description": "Battery voltage"
},
"torque": {
"type": "string",
"description": "Maximum torque rating"
},
"speed": {
"type": "string",
"description": "Speed ratings (RPM)"
},
"weight": {
"type": "string",
"description": "Weight of the tool"
},
"dimensions": {
"type": "string",
"description": "Physical dimensions"
},
"batteryIncluded": {
"type": "boolean",
"description": "Whether batteries are included"
},
"cordless": {
"type": "boolean",
"description": "Whether the tool is cordless"
}
}
},
"features": {
"type": "array",
"items": {
"type": "string"
},
"description": "List of product features and benefits"
},
"categoryInfo": {
"type": "object",
"properties": {
"mainCategory": {
"type": "string",
"description": "Main product category"
},
"subCategories": {
"type": "array",
"items": {
"type": "string"
},
"description": "Sub-categories the product belongs to"
}
}
},
"reviews": {
"type": "object",
"properties": {
"averageRating": {
"type": "number",
"minimum": 0,
"maximum": 5,
"description": "Average customer rating out of 5"
},
"numberOfReviews": {
"type": "integer",
"description": "Total number of customer reviews"
},
"ratingDistribution": {
"type": "object",
"properties": {
"5star": {"type": "integer"},
"4star": {"type": "integer"},
"3star": {"type": "integer"},
"2star": {"type": "integer"},
"1star": {"type": "integer"}
},
"description": "Distribution of ratings by star level"
}
}
},
"availability": {
"type": "object",
"properties": {
"inStock": {
"type": "boolean",
"description": "Whether the product is in stock"
},
"deliveryOptions": {
"type": "array",
"items": {
"type": "string"
},
"description": "Available delivery options"
},
"estimatedDeliveryDate": {
"type": "string",
"description": "Estimated delivery date range"
}
}
},
"warranty": {
"type": "string",
"description": "Warranty information"
},
"compatibleAccessories": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"asin": {"type": "string"},
"url": {"type": "string", "format": "uri"}
}
},
"description": "Compatible accessories for this product"
},
"frequentlyBoughtTogether": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"asin": {"type": "string"},
"url": {"type": "string", "format": "uri"}
}
},
"description": "Products frequently bought together with this item"
}
},
"required": ["productBasicInfo", "pricing", "images", "technicalDetails"]
}运行:
crwl https://a.co/d/17HZeGj -s dewalt-schema.json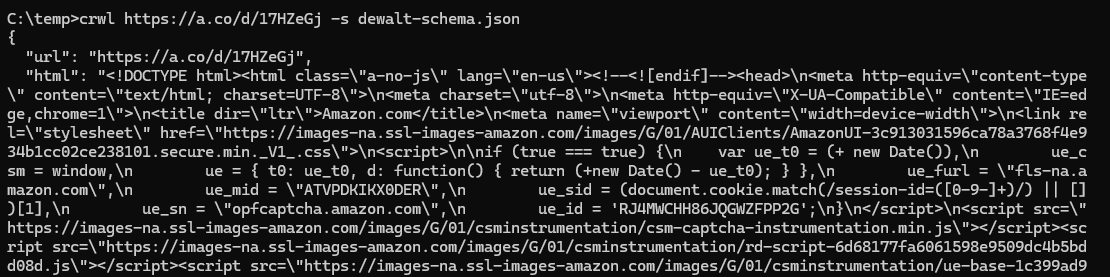
6. 指定浏览器配置文件(JSON/YAML),参数:-B,--browser-config PATH
crwl https://docs.crawl4ai.com/ -B [JSON 或 YAML 格式 配置文件的路径]
crwl https://docs.crawl4ai.com/ -browser-config [JSON 或 YAML 格式 配置文件的路径]指定浏览器配置文件的路径,该文件以YAML或JSON格式定义爬虫使用的浏览器行为和设置。许多网站使用 JavaScript 动态加载内容或实现反爬机制。浏览器配置文件让你能控制爬虫如何与网页交互,特别重要。
1)浏览器配置文件的主要功能
- 浏览器类型设置
- 指定使用浏览器引擎(如Chromium、Firefox)
- 设置浏览器的版本
- 请求头和身份识别
- 自定义User-Agent
- 设置HTTP头部信息
- 配置Cookie处理方式
- 渲染控制
- 等待页面完全加载的时间
- 设置JavaScript执行超时
- 控制是否加载图片和其他媒体资源
- 代理和网络设置
- 配置代理服务器
- 设置网络请求超时
- 控制并发连接数
- 交互行为
- 自动滚动页面
- 模拟鼠标移动
- 配置点击行为
2)例:配置文件
browser:
# 基本浏览器设置
type: "chromium" # 使用Chromium浏览器
headless: true # 无头模式(不显示浏览器界面)
# 超时和等待设置
page_load_timeout: 30000 # 页面加载超时(毫秒)
default_wait_time: 5000 # 默认等待时间(毫秒)
# 请求头设置
user_agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
# 媒体和资源设置
block_images: true # 阻止加载图像
block_css: false # 不阻止CSS
block_fonts: true # 阻止字体加载
# 代理设置
proxy:
server: "http://proxy-server.example.com:8080"
username: "proxy_user"
password: "proxy_password"
# Cookie和存储设置
cookies_enabled: true
local_storage_enabled: true
# 浏览器窗口设置
viewport:
width: 1920
height: 1080
# 交互行为设置
auto_scroll:
enabled: true
delay: 500 # 滚动间隔(毫秒)
scroll_amount: 200 # 每次滚动像素
max_scrolls: 20 # 最大滚动次数上面有解释,打字太累,不再重复。
3)使用场景
- 有的网站使用"无限滚动"或"加载更多"按钮,需要配置自动滚动和点击行为
- 绕过反爬策略,调整User-Agent和请求频率,使爬虫行为更像真人
- 通过阻止加载不需要的资源 (像:图片、字体、广告)提高爬取效率
- 使用代理网络访问,可以 DELETED 区域限制的内容
- 按照网站特点调整超时、等待时间等
- 常与 -e -c -b 共同工作
7. 指定内容过滤配置文件,参数:-f, --filter-config PATH
crwl https://docs.crawl4ai.com/ -f [如:YAML 格式 配置文件的路径]
crwl https://docs.crawl4ai.com/ --filter-config [如:YAML 格式 配置文件的路径]文件定义了如何筛选和处理爬取到的数据,屏蔽大量无关内容的网页。
1)内容过滤配置文件的主要功能
- 含与排除规则
- 基于关键词或正则表达式包含特定内容
- 排除不相关的内容块或元素
- 设置优先级规则处理内容冲突
- 数据清理
- 去除HTML标签、广告内容
- 清理多余空白、特殊字符
- 标准化日期、价格等格式
- 内容过滤
- 基于文本长度筛选内容
- 过滤低质量或重复内容
- 评估内容的相关性得分
- 内容分类与标记
- 将提取的内容按类型分类
- 为不同内容块添加标签
- 确定内容的层次结构
2)例:过滤配置文件
filters:
# 文本清理过滤器
- name: "text_cleanup"
type: "text_transform"
enabled: true
actions:
- replace: ["[\r\n\t]+", " "] # 替换多行为单个空格
- replace: ["\s{2,}", " "] # 替换多个空格为单个空格
- replace: [" ", " "] # 替换HTML特殊字符
- trim: true # 去除首尾空白
# 内容包含过滤器
- name: "content_inclusion"
type: "inclusion"
enabled: true
rules:
- field: "description"
patterns:
- "DEWALT"
- "Impact Wrench"
- "cordless"
match_type: "any" # 匹配任一关键词即包含
# 内容排除过滤器
- name: "content_exclusion"
type: "exclusion"
enabled: true
rules:
- field: "description"
patterns:
- "unavailable"
- "out of stock"
- "advertisement"
match_type: "any" # 匹配任一关键词即排除
# 长度过滤器
- name: "length_filter"
type: "length"
enabled: true
rules:
- field: "review"
min_length: 50 # 最小长度(字符)
max_length: 5000 # 最大长度(字符)
# 内容分类过滤器
- name: "content_classifier"
type: "classifier"
enabled: true
rules:
- field: "text"
classifications:
- name: "product_spec"
patterns: ["specification", "technical detail", "dimension"]
- name: "user_review"
patterns: ["review", "rating", "stars", "purchased"]
- name: "shipping_info"
patterns: ["shipping", "delivery", "arrive"]
target_field: "content_type" # 将分类结果存储到此字段3)使用场景
- 过滤产品描述、规格和价格,排除广告和推荐商品
- 提取有效评论,过滤掉垃圾评论和自动生成内容
- 筛选特定主题的新闻,排除不相关的广告和导航元素
- 从长篇内容中只提取所需的章节或段落
- 保留特定语言的内容,过滤其他语言
8. 使用大型语言模型(LLM)从网页中提取结构化数据,参数:-j,--json-extract TEXT
crwl https://docs.crawl4ai.com/ -j [给LLM 的提示词 PROMPT]
crwl https://docs.crawl4ai.com/ --json-extract [给LLM 的提示词 PROMPT]指定想要从爬取的网页中提取什么类型的结构化数据,而且可以通过提供描述来引导 LLM 如何进行提取。支持的模型很多,见官网:Providers | liteLLM (https://docs.litellm.ai/docs/providers)
需要有 API KEY OF LLM
例:从网站提取信息
crwl https://docs.crawl4ai.com/ -j "如何配置 LLM-based extraction"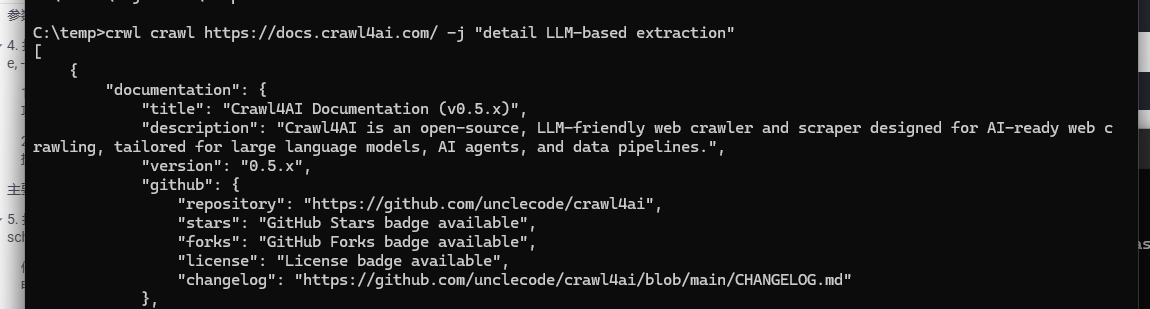

9. 把结果保存到文件里,参数: -O, --output-file PATH
crwl https://docs.crawl4ai.com/ -O [输出结果的路径与文件名]
crwl https://docs.crawl4ai.com/ --output-file [输出结果的路径与文件名]- 将结果保存到文件中,方便后续使用
- 方便将数据传递给其他程序或工具进行后续处理
- 结合之前的 -o, --output 选项,保存为不同格式(json、markdown 等),见 CLI 第1个介绍
10. 对已爬取的网页内容提出自然语言问题,参数,-q, --question 给LLM 的提示词 PROMPT
crwl https://docs.crawl4ai.com/ -q [给LLM 的提示词 PROMPT]
crwl https://docs.crawl4ai.com/ --question [给LLM 的提示词 PROMPT]依赖于大型语言模型(LLM),首先 crwl 爬取并处理指定网站的内容,工具会分析爬取的内容,找到相关信息并提供答案。
例:
crwl https://docs.crawl4ai.com/ -q "如何配置 LLM-based extraction"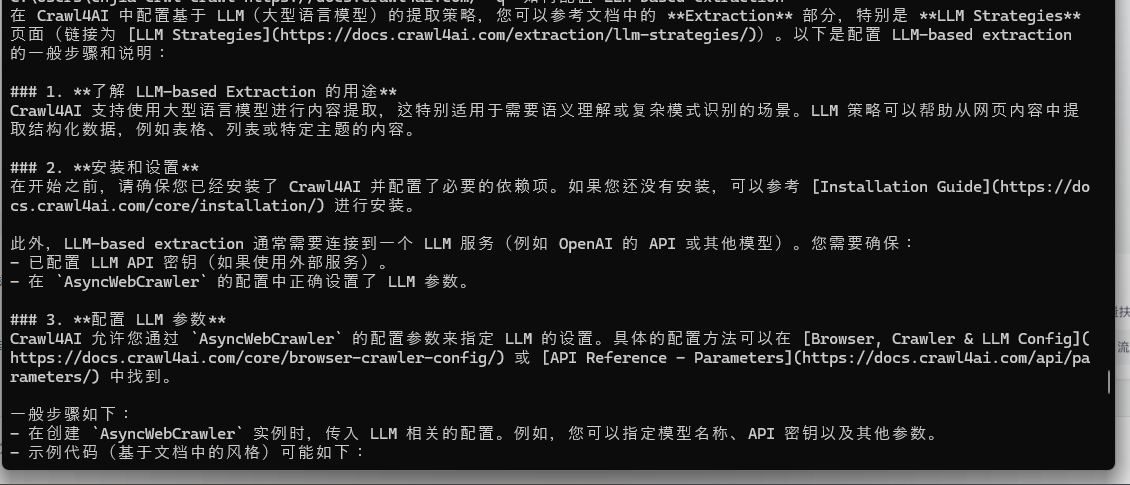
11. 指定特定的浏览器配置文件来运行,参数:-p, --profile TEXT
crwl https://docs.crawl4ai.com/ -p TEXT
crwl https://docs.crawl4ai.com/ --profile TEXT需要提前配置 Profiles 配置文件,命令:
crwl profiles
LLM 配置方法
1. 初始设置
首次设置时,会提示输入 LLM 提供商和 API 令牌,然后将配置保存在 ~/.crawl4ai/global.yml 文件中。文件内容:

2. 使用 -e 选项,指定LLM配置文件
文件:extract_llm.yml
type: "llm"
provider: "openai/gpt-4"
instruction: "提取所有文章的标题和链接"
api_token: "token / key"
params:
temperature: 0.3
max_tokens: 1000运行:
crwl https://docs.crawl4ai.com/ -e extract_llm.yml小结:
码字太多,也未必有人看,作为自用文就写到这里。
CRAWL4AI 是一个强大的爬虫(刮刀)软件,特别是支持 LLM 的使用。 以上只是 CLI 的功能介绍,还涉及到配置文件的示例。
在这篇文章只是详细的介绍 CLI 命令行的使用,也有详细的示例来介绍这些配置文件。但这些也只是 APP 的小部分,更多还是要去参考官方 Doc. 见文章开头的链接。