博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
项目技术说明:
python语言、Flask框架、MySQL数据库、Echarts可视化、
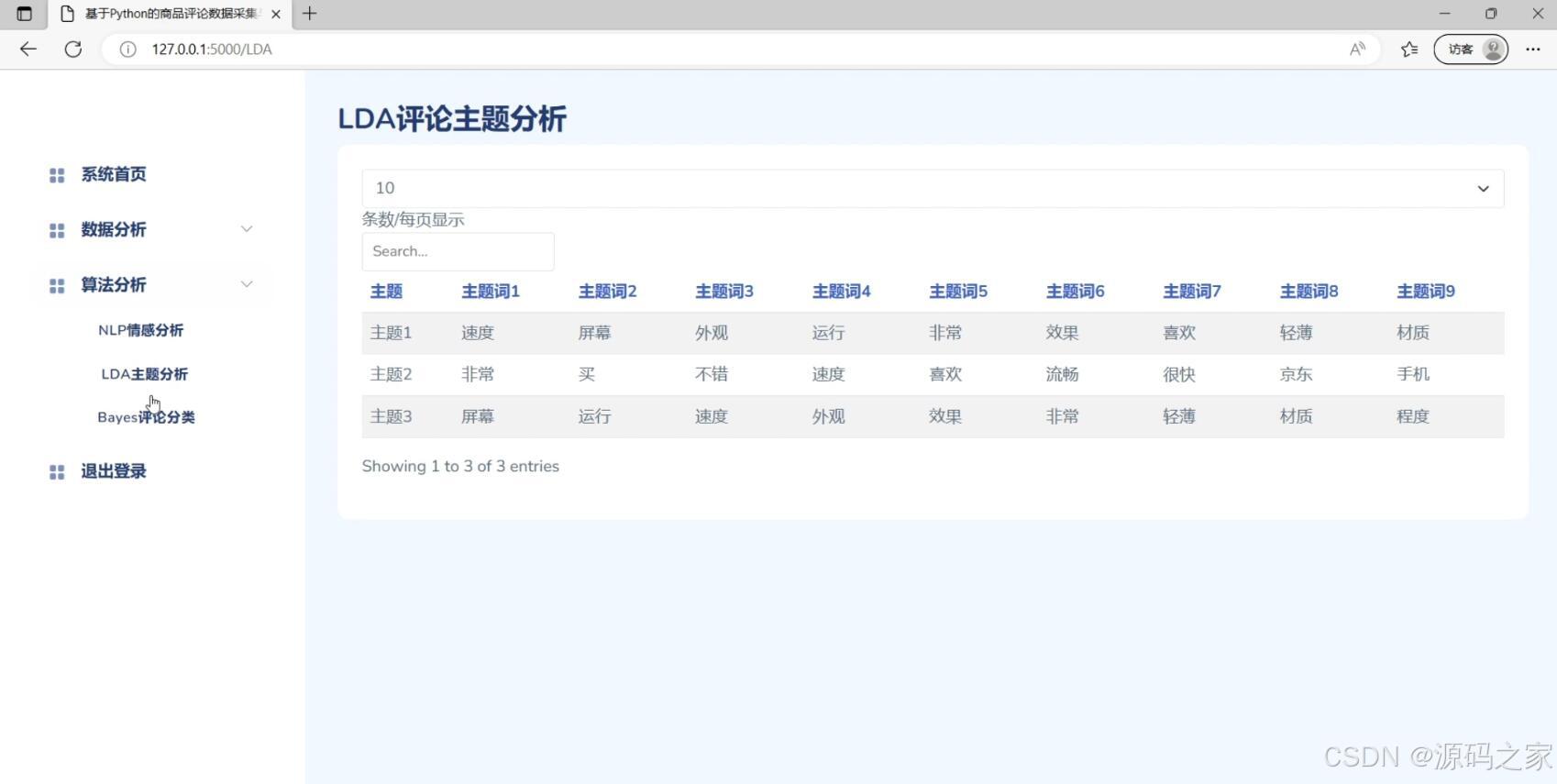
评论多维度分析、NLP情感分析、LDA主题分析、Bayes评论分类
商品评论数据采集分析可视化系统是基于Python语言和Flask框架开发的一个系统,用于采集商品评论数据并进行多维度分析和可视化展示。系统通过与MySQL数据库进行交互,实现数据的存储和查询。
系统主要包含以下功能:
-
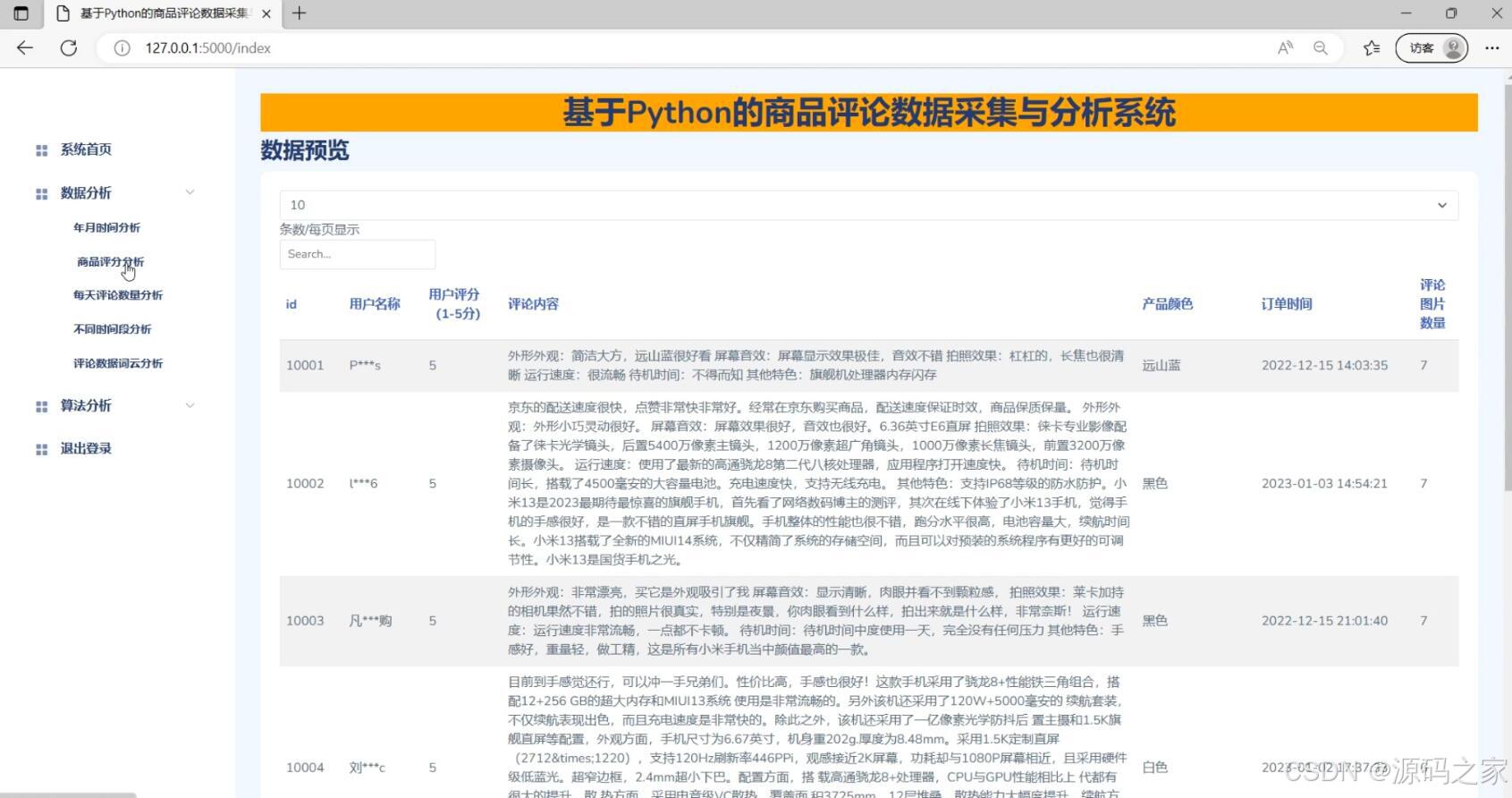
商品评论数据采集:系统可以根据用户输入的关键词自动爬取各大电商平台上的商品评论数据,并将数据存储在MySQL数据库中。
-
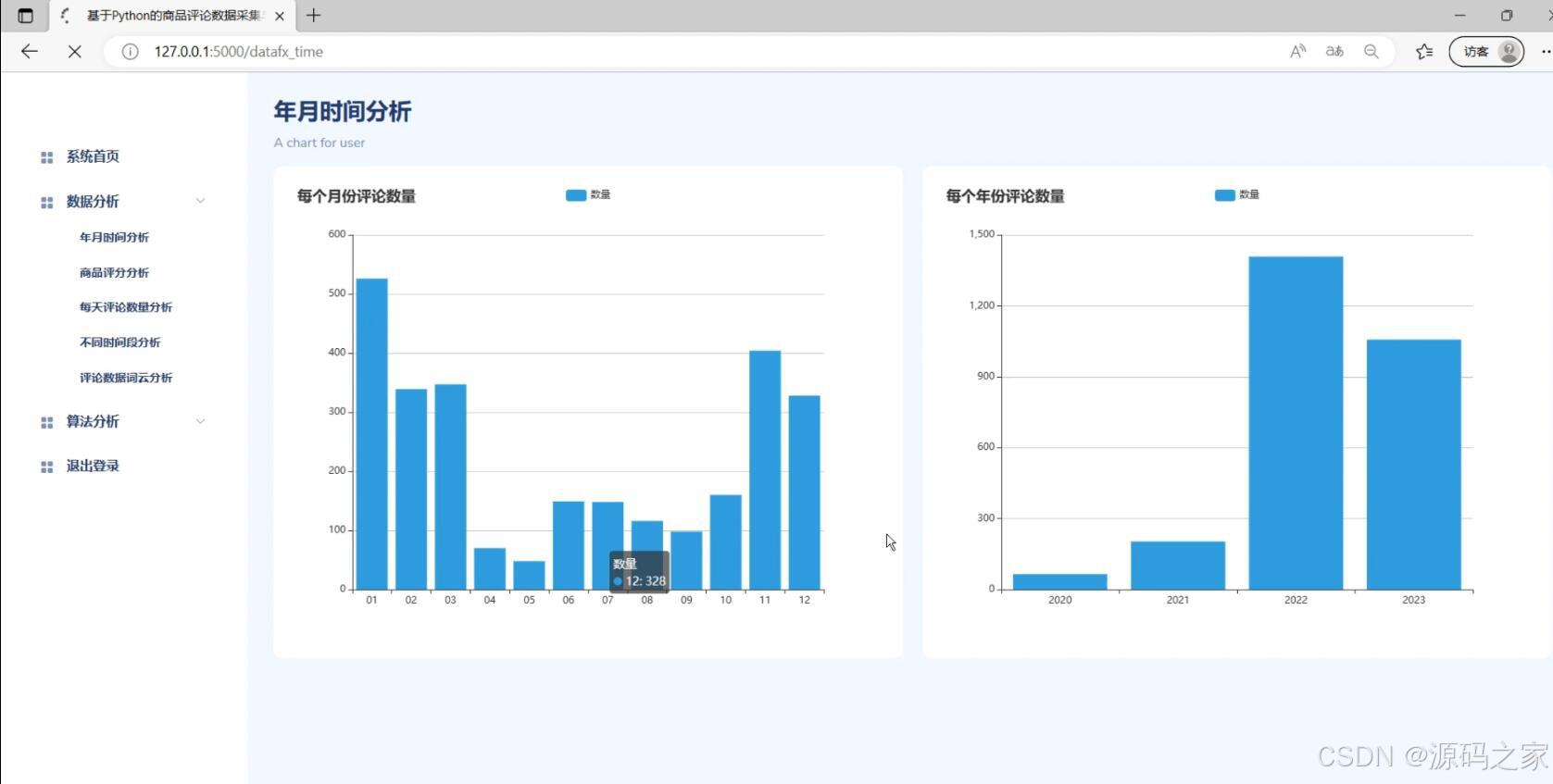
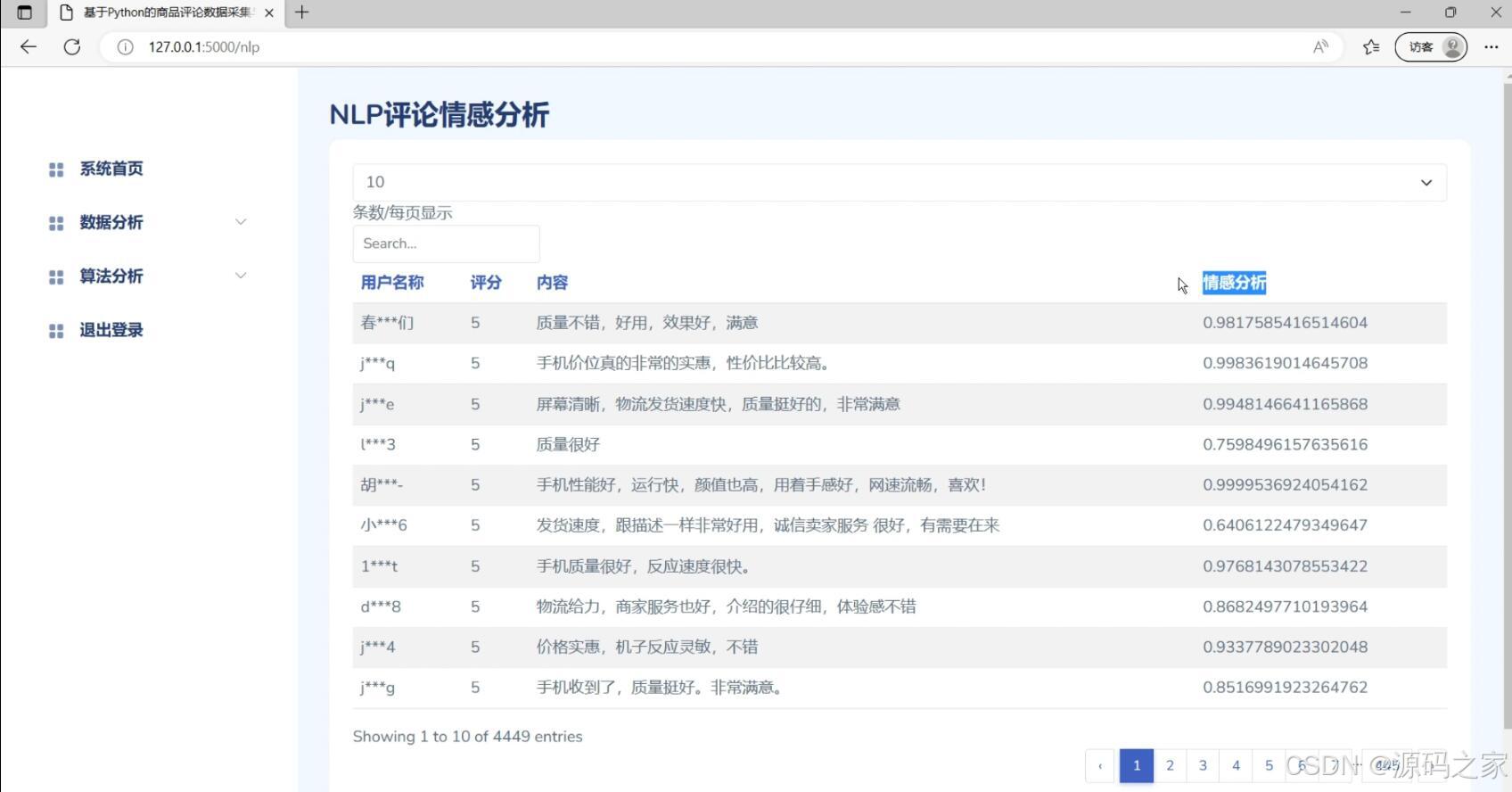
多维度分析:系统可以对商品评论数据进行多维度的分析,包括评论数量的趋势分析、评论的情感分析、评论的主题分析等。通过这些分析,可以了解用户对商品的评价和喜好。
-
可视化展示:系统使用Echarts可视化库,将分析结果以图表的形式展示出来。例如,可以通过折线图展示评论数量的变化趋势,通过情感分析结果展示用户对商品的整体情感倾向等。
-
Bayes评论分类:系统还实现了基于Bayes算法的评论分类功能,可以根据评论的内容将其分类为正面评价、负面评价或中性评价,帮助用户快速了解商品的整体评价。
通过这个系统,用户可以方便地进行商品评论数据的采集、分析和可视化展示,从而更好地了解用户对商品的评价和喜好,为商品的改进和推广提供参考依据。
2、项目界面
(1)评论数据时间分析
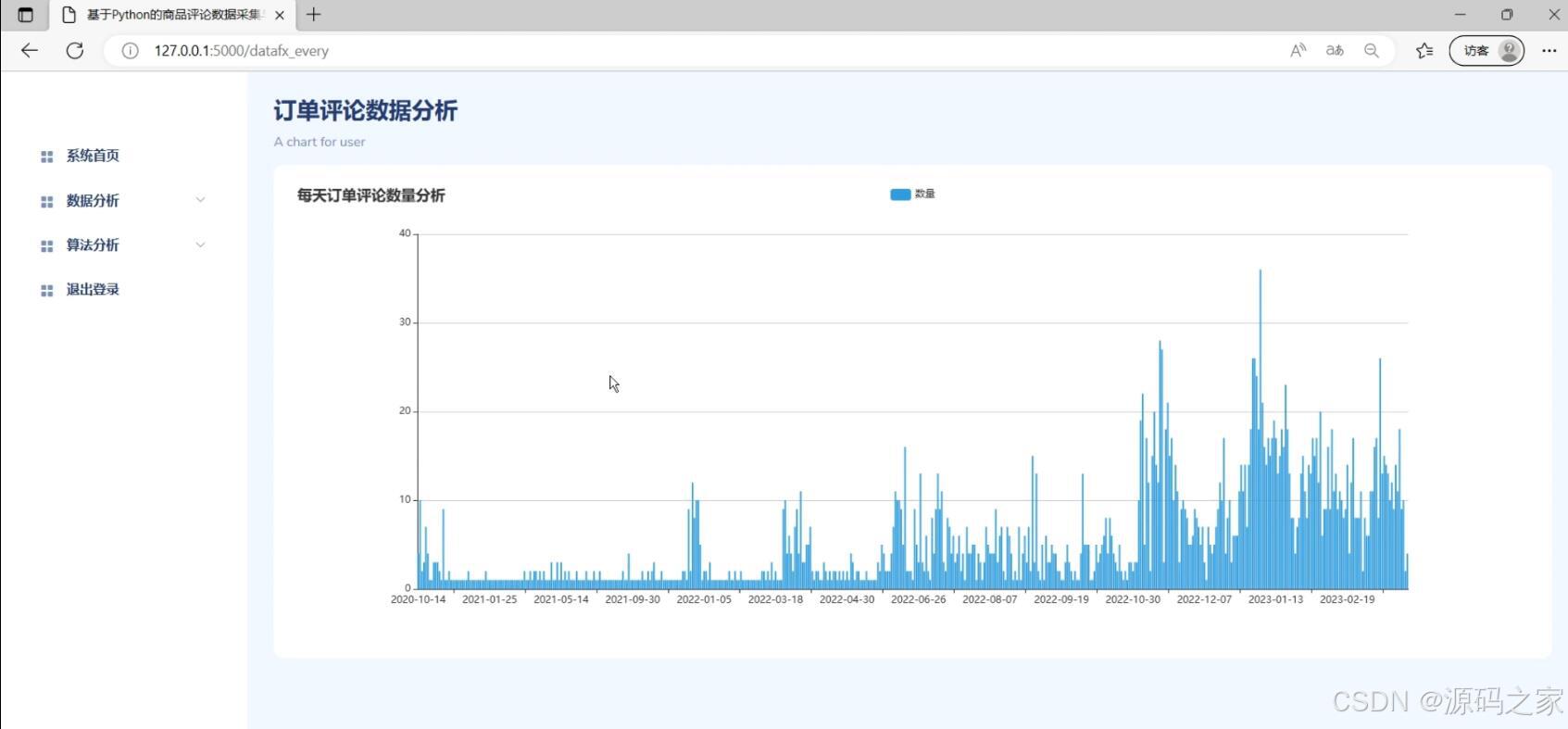
(2)订单评论数据分析
(3)商品评论数据词云图分析

(4)商品评论数据
(5)NLP评论情感分析
(6)LDA评论数据主题分析
(7)注册登录界面
3、项目说明
商品评论数据采集分析可视化系统是基于Python语言和Flask框架开发的一个系统,用于采集商品评论数据并进行多维度分析和可视化展示。系统通过与MySQL数据库进行交互,实现数据的存储和查询。
系统主要包含以下功能:
-
商品评论数据采集:系统可以根据用户输入的关键词自动爬取各大电商平台上的商品评论数据,并将数据存储在MySQL数据库中。
-
多维度分析:系统可以对商品评论数据进行多维度的分析,包括评论数量的趋势分析、评论的情感分析、评论的主题分析等。通过这些分析,可以了解用户对商品的评价和喜好。
-
可视化展示:系统使用Echarts可视化库,将分析结果以图表的形式展示出来。例如,可以通过折线图展示评论数量的变化趋势,通过情感分析结果展示用户对商品的整体情感倾向等。
-
Bayes评论分类:系统还实现了基于Bayes算法的评论分类功能,可以根据评论的内容将其分类为正面评价、负面评价或中性评价,帮助用户快速了解商品的整体评价。
通过这个系统,用户可以方便地进行商品评论数据的采集、分析和可视化展示,从而更好地了解用户对商品的评价和喜好,为商品的改进和推广提供参考依据。
4、核心代码
python
import pandas as pd
import jieba
import pymysql
import re
sql = 'select id,nickname, score, content, productColor, creationTime from data '
con = pymysql.connect(host='127.0.0.1', user='root', passwd='123456', port=3306, db='comment', charset='utf8mb4')
df = pd.read_sql(sql, con)
postive = pd.read_sql(sql, con)
postive = postive[postive['score'] == 5].drop_duplicates()
print(postive)
negtive = pd.read_sql(sql, con)
negtive = negtive[negtive['score'] == 1].drop_duplicates()
print(negtive)
# 文本去重(文本去重主要是一些系统自动默认好评的那些评论 )
# 文本分词
mycut = lambda s: ' '.join(jieba.cut(s)) # 自定义分词函数
po = postive.content.apply(mycut)
ne = negtive.content.apply(mycut)
# 停用词过滤(停用词文本可以自己写,一行一个或者用别人整理好的,我这是用别人的)
with open(r'stopwords.txt', encoding='utf-8') as f: #这里的文件路径最好改成自己的本地绝对路径
stop = f.read()
stop = [' ', ''] + list(stop[0:]) # 因为读进来的数据缺少空格,我们自己添加进去
po['1'] = po[0:].apply(lambda s: s.split(' ')) # 将分词后的文本以空格切割
po['2'] = po['1'].apply(lambda x: [i for i in x if i not in stop]) # 过滤停用词
# 在这里我们也可以用到之前的词云图分析
# post = []
# for word in po:
# if len(word)>1 and word not in stop:
# post.append(word)
# print(post)
# wc = wordcloud.WordCloud(width=1000, font_path='simfang.ttf',height=800)#设定词云画的大小字体,一定要设定字体,否则中文显示不出来
# wc.generate(' '.join(post))
# wc.to_file(r'..\yun.png')
ne['1'] = ne[0:].apply(lambda s: s.split(' '))
ne['2'] = ne['1'].apply(lambda x: [i for i in x if i not in stop])
from gensim import corpora, models
# 负面主题分析
neg_dict = corpora.Dictionary(ne['2'])
neg_corpus = [neg_dict.doc2bow(i) for i in ne['2']]
neg_lda = models.LdaModel(neg_corpus, num_topics=3, id2word=neg_dict)
# 正面主题分析
pos_dict = corpora.Dictionary(po['2'])
pos_corpus = [pos_dict.doc2bow(i) for i in po['2']]
pos_lda = models.LdaModel(pos_corpus, num_topics=3, id2word=pos_dict)
pos_theme = pos_lda.show_topics()
# 展示主题
pos_theme = pos_lda.show_topics()
# 取出高频词
pattern = re.compile(r'[\u4e00-\u9fa5]+')
pattern.findall(pos_theme[0][1])
pos_key_words = []
for i in range(3):
pos_key_words.append(pattern.findall(pos_theme[i][1]))
pos_key_words = pd.DataFrame(data=pos_key_words, index=['主题1', '主题2', '主题3'])
pos_key_words.to_csv('lda.csv')🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻