你和生生不息的河流,生动了我人生中的美好瞬间
------ 25.4.11
一、词表的构造问题
为了nlp模型训练,词表(字表)是必要的
统计训练语料中的所有字符(或词)是一种做法,但是容易出现一些问题:
1)测试数据中出现训练数据中没有的词
2)词表过大
3)对于不同语种,切分粒度不好确认(字 or 词)
二、bpe(byte pair encoding)压缩算法
BPE 最初是一种数据压缩算法 ,通过迭代合并数据中最频繁出现的字节对 (Byte Pair),逐步构建一个编码表,将高频字节对替换为一个新的符号,从而减少数据中的重复模式,达到压缩目的。其核心逻辑是:通过统计数据中相邻符号的频率,不断合并高频符号对,生成更复杂的新符号,最终将原始数据转换为符号序列,减少数据冗余。
算法步骤
假设输入数据为字符串,初始符号为单个字符(或字节)
步骤 1:初始化符号表和频率统计
将输入数据拆分为最小单元(如单个字符或字节),初始符号表为所有唯一字符的集合。
例如: 输入数据为 {"low", "lower", "newer", "widest"},初始符号为 {"l", "o", "w", "e", "r", "n", "w", "i", "d", "s", "t"}。
步骤 2:统计相邻符号对的频率
遍历数据,统计所有相邻符号对(Bigram)的出现次数。
例如:
"lo" 出现 2 次("low" 和 "lower"),
"ow" 出现 1 次("low"),
"er" 出现 2 次("lower" 和 "newer"),
其他符号对频率依次统计。
步骤 3:合并最高频的符号对
选择频率最高的符号对,将其作为新符号加入符号表,并在数据中替换所有该符号对为新符号。
例如: 若 "er" 是最高频对(频率 2),合并后新符号为 "er",数据转换为 {"l ow", "l o er", "n ew er", "w i d e s t"}(注意空格表示符号间隔)。
步骤 4:重复合并直至终止条件
重复步骤 2-3,直到达到预设的合并次数(如生成 1000 个符号)或无法继续合并(所有符号对频率为 1)。
最终符号表包含原始字符和合并生成的新符号(如 "lo", "er", "new" 等),数据被转换为符号序列。
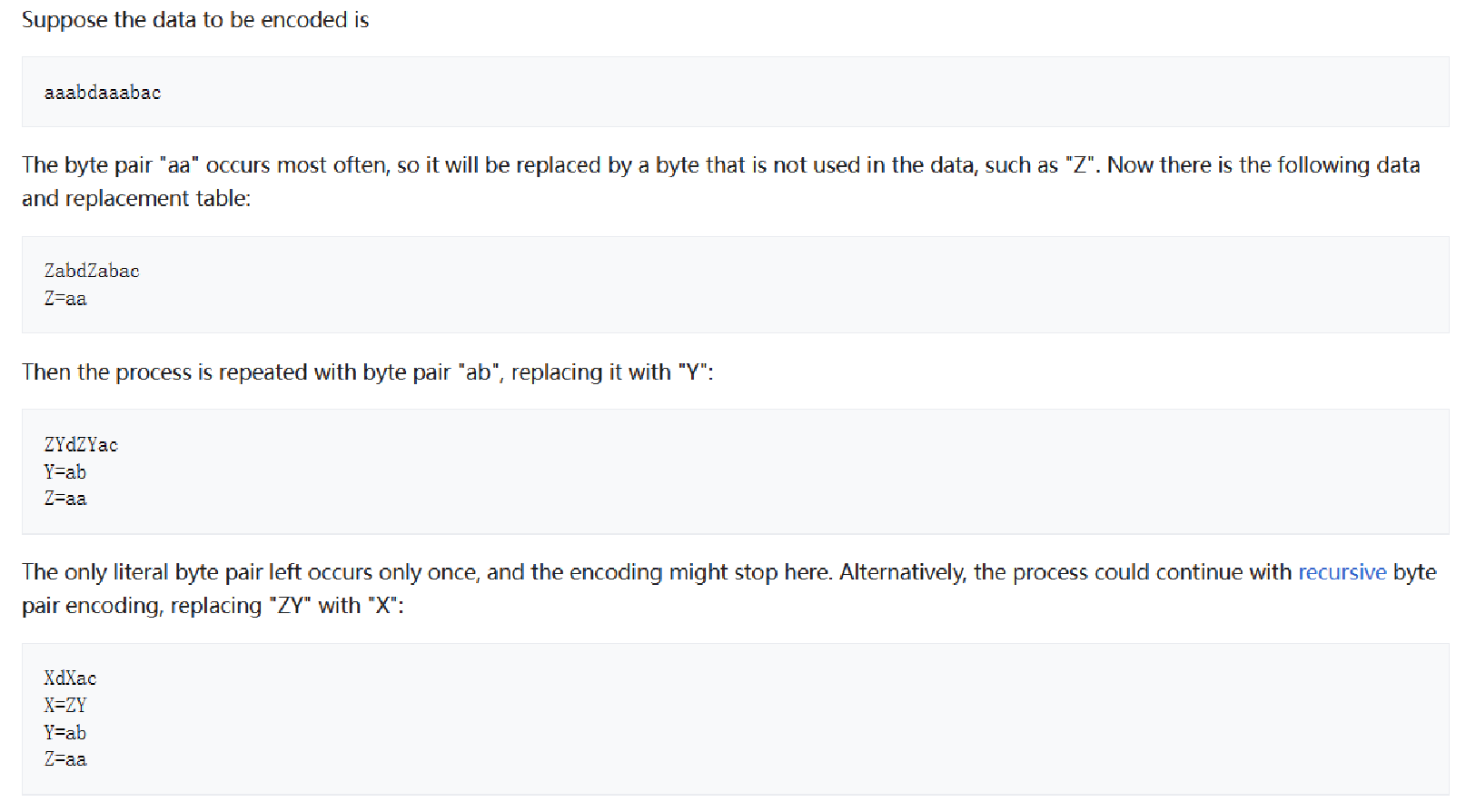
三、bpe在NLP中的使用示例
1.第一步
Ⅰ、假设语料内容如下:
he had a cat
the cat is sitting on the mat
Ⅱ、统计字符集合:
'a', 'c', 'd', 'e', 'g', 'h', 'i', 'm', 'n', 'o', 's', 't'
Ⅲ、统计相邻字符同时出现的次数(字符中如有空格不算相邻)
**he:**3 (he, the*2)
**ha:**1 (had)
**ad:**1 (had)
**ca:**2 (cat*2)
**at:**3 (cat*2, mat)
**th:**2
**is:**1
**si:**1
**it:**1
**ti:**1
**in:**1
**ng:**1
**on:**1
**ma:**1
Ⅳ、最高频的组合被视为一个新的字符,新的字符集合:
'a', 'c', 'd', 'e', 'g', 'h', 'i', 'm', 'n', 'o', 's', 't', 'X', 'Y',X = he,Y = at
2.第二步
Ⅰ、假设语料内容如下:
he had a cat
the cat is sitting on the mat
Ⅱ、新词表:
'a', 'c', 'd', 'e', 'g', 'h', 'i', 'm', 'n', 'o', 's', 't', 'X', 'Y',X = he,Y = at
Ⅲ、统计相邻字符同时出现的次数(字符中如有空格不算相邻)
**tX(t'he'):**2(the * 2)
**ha:**1(had)
ad:1(had)
**cY(c'at'):**2(cat * 2)
**is:**1
**si:**1
**it:**1
**ti:**1
**in:**1
**ng:**1
**on:**1
**mY(m'at'):**1
Ⅳ、最高频的组合被视为一个新的字符,新的字符集合:
'a', 'c', 'd', 'e', 'g', 'h', 'i', 'm', 'n', 'o', 's', 't', 'X', 'Y', 'Z', 'M' ,Z = tX(t'he'),M = ha
3.第三步
依次循环,重复合并直至终止条件
四、大语言模型处理中文时是分字还是分词?
**答:**既不是分字,也不是分词,是介于字与词之间的一种东西,我们称之为 token,大语言模型可以把一个字切分为多个token,也可能把多个字当成一个token,这些token本质上是由训练数据通过统计算法得到