txt、Csv、Excel、JSON、SQL文件读取(Python)
txt文件读写
创建一个txt文件
python
f=open(r'text.txt','r',encoding='utf-8')
s=f.read()
f.close()
print(s)
open( )是打开文件的方法
'text.txt'文件名 在同一个文件夹下所以可以省略路径
如果不在同一个文件夹下 'xxx/xxx/text.txt' 文件名前加路径
encoding:设置字符编码
read( )是读取文件内容
close( )是关闭文件
with
open( )函数方法打开文件读取文件内容时,如果不关闭文件,将无法对该文件进行修改。当打开文件并写入文件内容后,不关闭文件会造成写入的内容不能保存。
在Python语言中,提供了with与open( )函数方法搭配使用
通过with与open( )函数搭配使用无须再去书写close( )函数方法
python
with open(r'text.txt','r',encoding='utf-8') as f:
s=f.read()
print(s)
写入
python
with open(r'text.txt','w') as f:
f.write('qwertyuiop')
写入多行
python
with open(r'text.txt','w') as f:
text=['asdfghjk\n','xcvbnmrtyui\n','123456789\n']
f.writelines(text)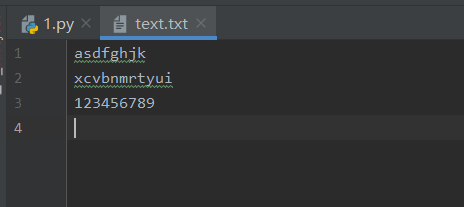
open(r'text.txt','w')函数中,'w'参数意为写入,会将文件原有的内容进行覆盖
文件打开模式
- r 只读 只读默认模式
- w 只写 在原文件写,覆盖原文件
- a 只写 不覆盖原文件,末尾追加
- wb 写入 以二进制形式写入,保存图片时使用
- r+ 读写 在原文件写,覆盖原文件
- w+ 读写 在原文件写,覆盖原文件
- a+ 读写 不覆盖原文件,末尾追加
CSV文件读写
read_csv( )
读取当前目录下的text.csv
python
import pandas as pd
a=pd.read_csv(r'text.csv')
print(a)
设置字段
python
import pandas as pd
a=pd.read_csv(r'text.csv',names=['id','name'])
print(a)
指定相应的索引列
python
import pandas as pd
a=pd.read_csv(r'text.csv',names=['id','name'],index_col='id')
print(a)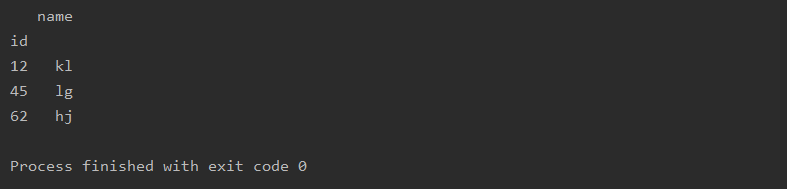
python
import pandas as pd
a=pd.read_csv(r'text.csv',names=['id','name'],index_col=0)
print(a)
获取指定列
python
import pandas as pd
a=pd.read_csv(r'text.csv',names=['id','name'],usecols=[0])
print(a)
b=pd.read_csv(r'text.csv',names=['id','name'],usecols=['id'])
print(b)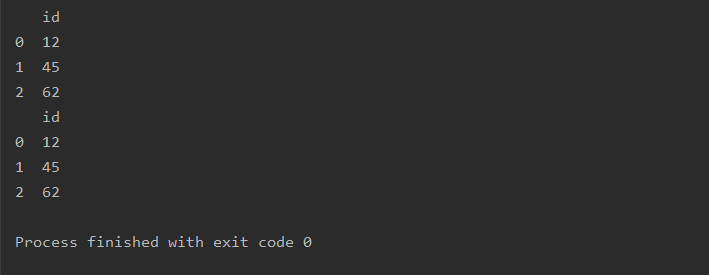
写入
to_csv( )
python
import pandas as pd
data={'id':['1','2','3'],'name':['gh','jk','ty']}
a=pd.DataFrame(data)
a.to_csv(r'text.csv')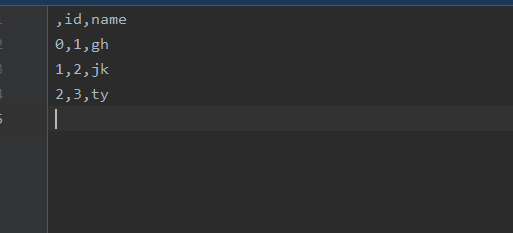
设置写入列
python
import pandas as pd
data={'id':['1','2','3'],'name':['gh','jk','ty']}
a=pd.DataFrame(data)
a.to_csv(r'text.csv',columns=['id'])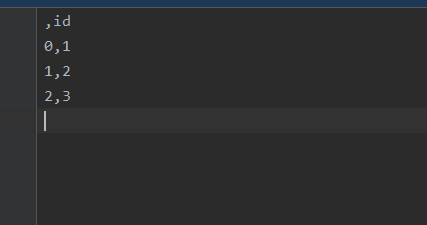
设置写入模式
mode w为写(覆盖) a为追加
import pandas as pd
data={'id':['1','2','3'],'name':['gh','jk','ty']}
a=pd.DataFrame(data)
a.to_csv(r'text.csv')
a.to_csv(r'text.csv',mode='a')
是否写入列名字段
header
python
import pandas as pd
data={'id':['1','2','3'],'name':['gh','jk','ty']}
a=pd.DataFrame(data)
a.to_csv(r'text.csv')
a.to_csv(r'text.csv',mode='a',header=False)
第二次写入不写入列名
删除索引
index=None
python
import pandas as pd
data={'id':['1','2','3'],'name':['gh','jk','ty']}
a=pd.DataFrame(data)
a.to_csv(r'text.csv',index=None)
a.to_csv(r'text.csv',mode='a',header=False,index=None)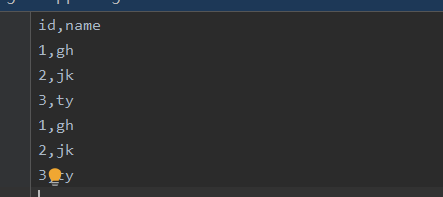
Excel文件读写
read_excel( )
参数:
sheet_name='name'为读取的分表名,可以写表名、位置下标。
index_col为指定相应的索引列,为字段名或者字段列表下标。
usecols为获取指定列
names为设置列字段
header为用哪一行做字段名
nrows为指定获取的行数
skiprows为跳过特定行,skipfooter跳过末尾n行
python
import pandas as pd
a=pd.read_excel(r'text.xlsx')
print(a)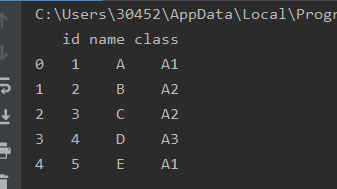
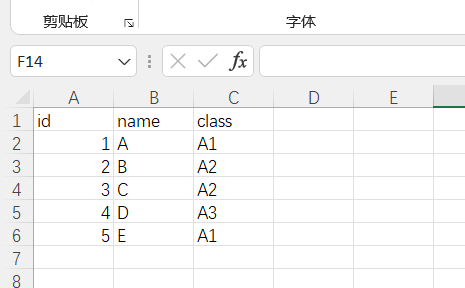
选择表
sheet_name
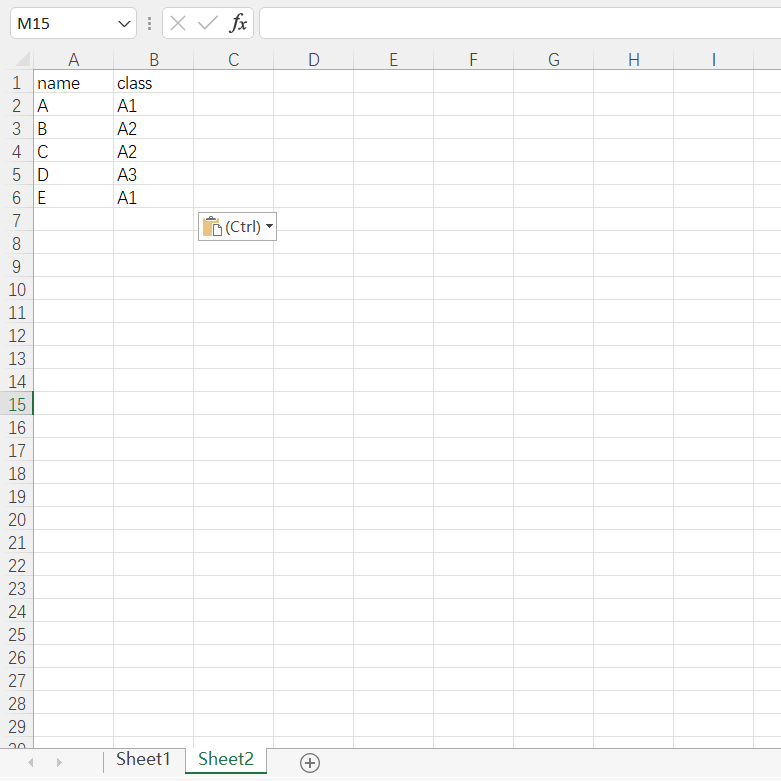
新建一个表
python
import pandas as pd
a=pd.read_excel(r'text.xlsx',sheet_name=1)
print(a)
设置索引列
index_col
python
import pandas as pd
a=pd.read_excel(r'text.xlsx',sheet_name=0,index_col=[0])
print(a)
获取指定列
usecols
python
import pandas as pd
a=pd.read_excel(r'text.xlsx',sheet_name=0,usecols=[0])
print(a)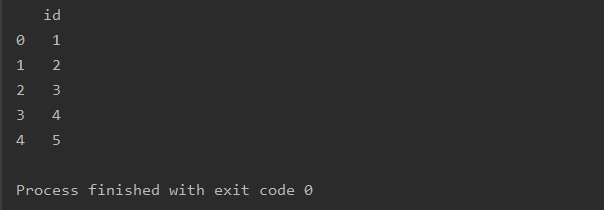
设置列字段
names
python
import pandas as pd
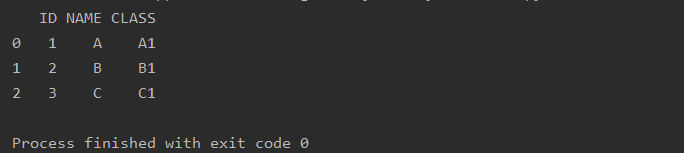
a=pd.read_excel(r'text.xlsx',sheet_name=0,names=['ID','NAME','CLASS'])
print(a)
指定某行为字段名
header
python
import pandas as pd
a=pd.read_excel(r'text.xlsx',sheet_name=0,header=1)
print(a)
设置获取行数
nrows
python
import pandas as pd
a=pd.read_excel(r'text.xlsx',sheet_name=0,nrows=2)
print(a)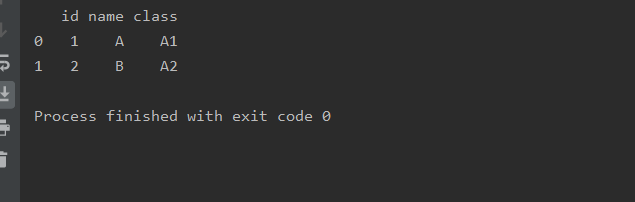
跳过n行
skiprows 跳过前n行
python
import pandas as pd
a=pd.read_excel(r'text.xlsx',sheet_name=0,skiprows=1)
print(a)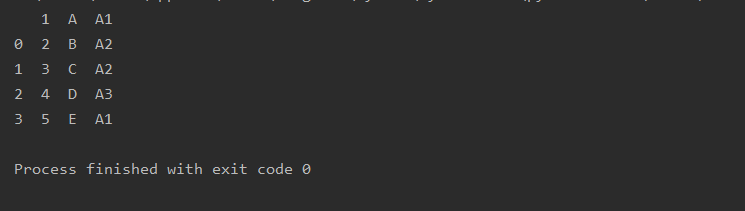
skipfooter跳过末尾n行
python
import pandas as pd
a=pd.read_excel(r'text.xlsx',sheet_name=0,skipfooter=3)
print(a)
写入
python
import pandas as pd
data={'id':[1,2,3,4],'name':['A','B','C','D']}
a=pd.DataFrame(data)
a.to_excel(r'text.xlsx')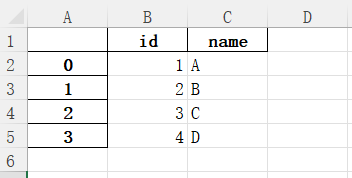
写入多表
python
import pandas as pd
data={'id':[1,2,3,4],'name':['A','B','C','D']}
a=pd.DataFrame(data)
writer = pd.ExcelWriter(r'text.xlsx')
a.to_excel(writer,sheet_name='1')
a.to_excel(writer,sheet_name='2')
writer.save()
writer.close()

写入新分表
python
import pandas as pd
import openpyxl
book = openpyxl.load_workbook(r'text.xlsx')
writer=pd.ExcelWriter(r'text.xlsx')
writer.book=book
writer.sheets=dict((ws.title,ws) for ws in book.worksheets)
data={'id':[5,2,8,4],'name':['H','B','C','D']}
a=pd.DataFrame(data)
a.to_excel(writer,sheet_name="3")
writer.save()
writer.close()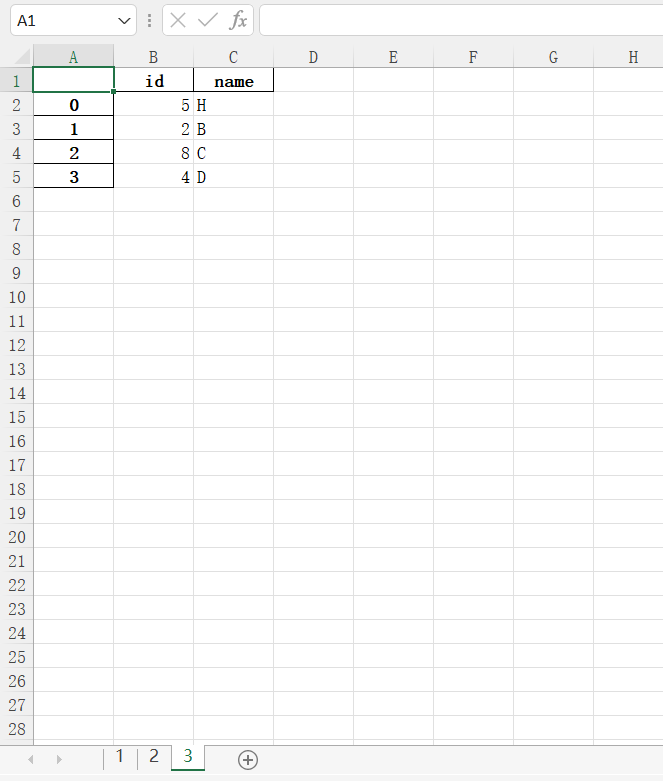
JSON文件读写
read_json()
python
import pandas as pd
a=pd.read_json(r'text.json',encoding='utf8')
print(a)
序列化
python
import pandas as pd
a=pd.read_json(r'text.json',encoding='utf8')
b=pd.json_normalize(a.data)
print(a)
print(b)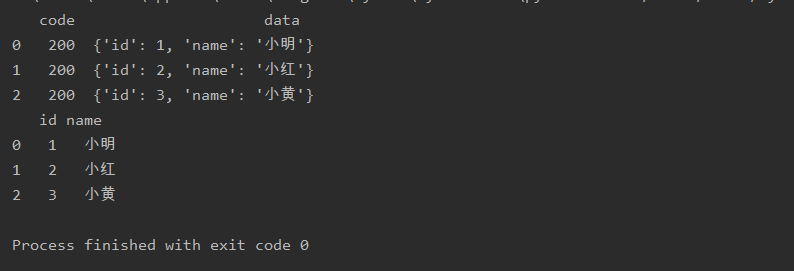
写入
to_json( )
force_ascii为数据编码格式,默认为True,中文以Unicode形式写入,如果为False,中文以ANSI形式写入。
python
import pandas as pd
data={'id':[1,2,3],'name':['a','b','c']}
a=pd.DataFrame(data)
a.to_json('text.json',force_ascii=False)
SQL文件读取
python
import pymysql
con = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
password='123456',
db='test03',
charset='utf8'
)
# 创建游标
cursor=con.cursor()
# 执行sql语句
cursor.execute("select * from test")
# 解释全部返回结果
res=cursor.fetchall()
print(res)
con.close()
Pandas读取MySQL数据库内容
python
import pymysql
import pandas as pd
con = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
password='123456',
db='test03',
charset='utf8'
)
sql="select * from test"
pd=pd.read_sql_query(sql,con)
print(pd)