更多推荐阅读
Spark初探:揭秘速度优势与生态融合实践-CSDN博客
Spark与Flink深度对比:大数据流批一体框架的技术选型指南-CSDN博客
目录
[一、Spark SQL核心定位:大数据处理统的一入口](#一、Spark SQL核心定位:大数据处理统的一入口)
二、架构解析:Catalyst优化器与Tungsten引擎的协作
[1. 分区与分桶策略](#1. 分区与分桶策略)
[2. 数据倾斜破解方案](#2. 数据倾斜破解方案)
[3. 参数调优黄金法则](#3. 参数调优黄金法则)
[1. CTE列作用域异常](#1. CTE列作用域异常)
[2. 外部数据源连接失败](#2. 外部数据源连接失败)
[3. 动态参数替换问题](#3. 动态参数替换问题)
一、Spark SQL核心定位:大数据处理统的一入口
Spark SQL并非简单的"SQL查询工具",而是Spark生态中统一批流处理的入口层。它通过五大创新实现这一目标:
- 数据兼容性革命
- 突破传统Hive单一数据源限制,支持RDD、Parquet、JSON、CSV、JDBC(如MySQL/Oracle)等异构数据源,形成统一抽象的数据帧(DataFrame)接口
- 摆脱对Hive执行引擎的依赖(仅复用其元数据存储与HQL解析),自研执行引擎实现更高性能扩展。
- 批流统一API。
- Structured Streaming模块以相同的SQL语法处理实时流与离线批数据,消除了技术隔阂。
**技术决策启示:**选择Spark SQL而非纯Hive,意味着获得更灵活的数据源集成能力与批流统一开发体验。
二、架构解析:Catalyst优化器与Tungsten引擎的协作
1.Catalyst:逻辑优化到物理执行的智能映射

Catalyst通过规则库(Rules)完成关键优化:
- 谓词下推:将过滤条件提前到数据读取阶段
- 列剪裁:跳过非必要字段的IO39
2.Tungsten:堆外内存与二进制加速
- 堆外内存管理:规避JVM GC瓶颈,直接操作二进制数据
- 代码生成(CodeGen):将算子编译为字节码,减少虚函数调用
性能实测:在PB级数据聚合场景,Tungsten使Shuffle效率提升5倍以上
三、实战优化:从千万级到亿级数据的跨越
1. 分区与分桶策略
- 动态分区写入:避免小文件(需设置spark.sql.shuffle.partitions)
- 分桶(Bucket)优化:对JOIN键分桶可加速Shuffle
CREATE TABLE user_bucketed`
`USING parquet`
`CLUSTERED BY` `(user_id) INTO 128 BUCKETS2. 数据倾斜破解方案
- 倾斜Key分离:将大Key单独处理
-- 将大Key与小Key拆分处理`
`SELECT` `/*+` `SKEW('orders', 'product_id')` `*/` `*` `FROM` `orders- 随机前缀扩容法:对倾斜Key添加随机前缀打散
3. 参数调优黄金法则
|--------------------------------------|---------|--------------|
| 参数 | 推荐值 | 作用 |
| spark.sql.autoBroadcastJoinThreshold | 100MB | 广播JOIN阈值 |
| spark.sql.shuffle.partitions | 核心数×4 | 控制Shuffle并行度 |
| spark.sql.adaptive.enabled | true | 开启自适应查询优化 |
四、典型陷阱与解决方案
1. CTE 列作用域异常
WITH tmp AS` `(`
`SELECT id, name FROM users`
`)`
`SELECT user_id FROM tmp -- 报错:user_id列不存在2. 外部数据源连接失败
- 缺失JDBC驱动:提交任务时通过--jars加载驱动
spark-submit --jars mysql-connector-java-8.0.28.jar- 权限问题:检查Kerberos认证或IAM策略
3. 动态参数替换问题
SQL中如${V_DATE}需用编程语言预处理替换,避免直接执行报错。
五、适用场景决策树
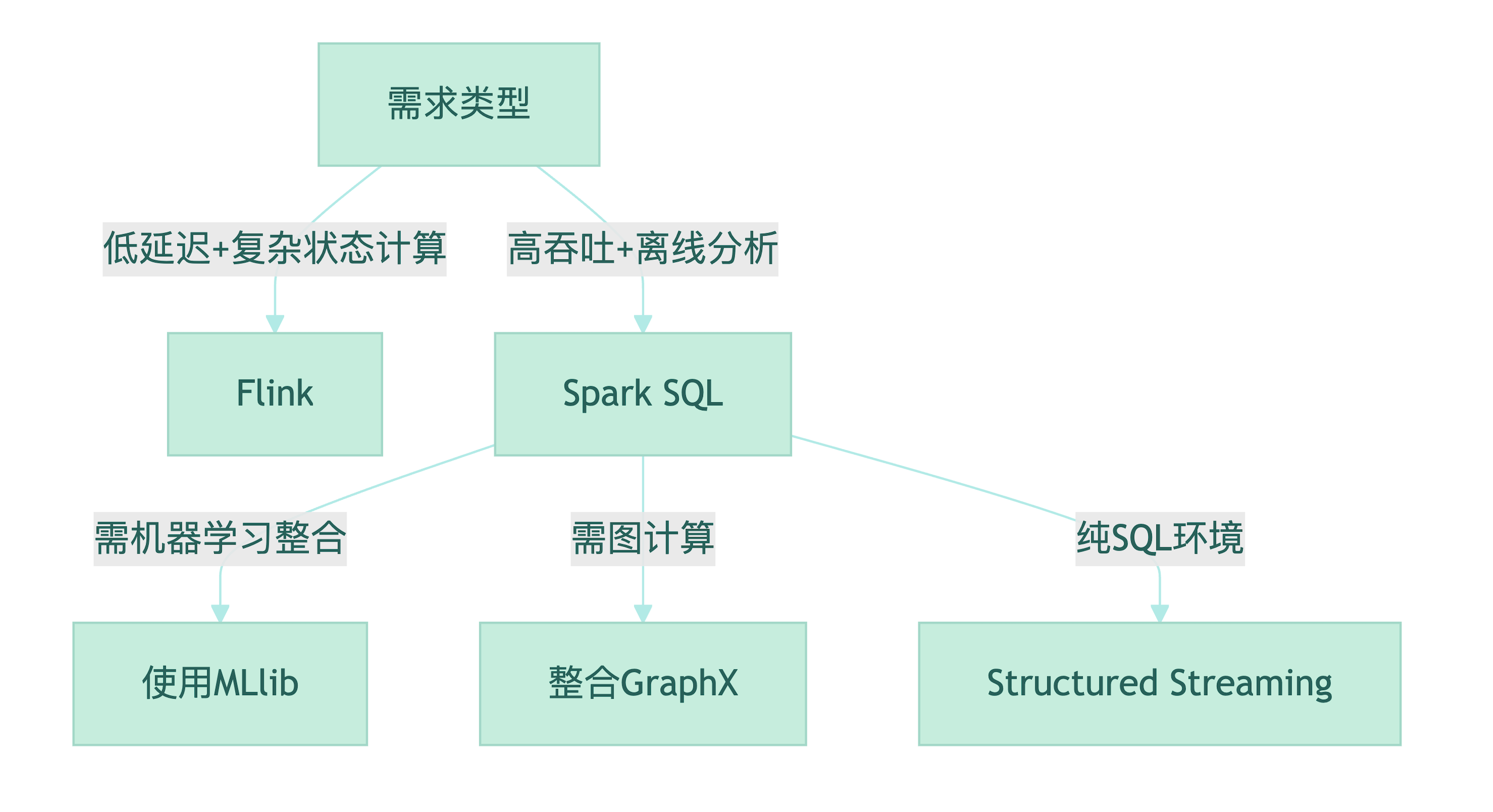
典型场景
- 电商用户行为分析(TB级日志聚合)
- 金融风控指标实时计算(秒级延迟)
六、未来演进:AI与SQL的融合
Spark 3.0+已支持:
- GPU加速SQL:借助RAPIDS加速排序/聚合
- 联邦查询:跨数据库(如MySQL+Snowflake)联合分析
- AI内置函数:直接调用XGBoost模型推理9
**总结:**Spark SQL的核心价值在于以SQL语法统一异构数据处理流程,通过Catalyst与Tungsten的深度协同,使开发者无需关注底层分布式复杂性,专注业务逻辑实现。
**作者:**道一云低代码
**作者想说:**喜欢本文请点点关注~