一、背景介绍:为什么要爬取 Pexels 的图片?
想象一下,你正在做一份与鲜花相关的 PPT,或者你是一名电商运营,需要一批精美的花卉图片来装点你的商品页面。然而,每次手动去 Pexels 找图、下载、整理,简直太费时间了!🙄 有没有办法用 Python 实现自动下载呢?当然有!
今天我们就来聊聊如何使用 playwright,一个强大的 Python 爬虫库,来批量爬取 Pexels 网站上关于鲜花的高清图片,让你的办公效率直接起飞 🚀。
二、技术方案:用 playwright 自动化浏览器操作
在开始编码之前,我们需要明确这次爬取的核心目标:
- 访问 Pexels 网站 (
https://www.pexels.com/zh-cn/)。 - 接受 Cookie 授权,确保正常浏览。
- 搜索"鲜花"关键词,获取相关图片。
- 获取图片的下载链接,并自动保存。
- 避免反爬,模拟用户浏览行为。
1. 安装 playwright
如果你还没有安装 playwright,先执行以下命令:
bash
pip install playwright
playwright install # 安装浏览器内核💡 为什么选 playwright?
- 支持多种浏览器(Chromium、Firefox、WebKit)。
- 可以无头模式运行,避免占用屏幕。
- 操作 API 直观,可以像用户一样点击、输入、滚动。
三、代码实现:自动爬取 Pexels 的鲜花图片
1. 启动浏览器并访问 Pexels
我们先写一个简单的代码,让 playwright 自动打开 Pexels 网站,接受 Cookie 并搜索"鲜花"。
python
from playwright.sync_api import sync_playwright
def open_pexels():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False) # 先开启可视化模式,调试方便
page = browser.new_page()
page.goto("https://www.pexels.com/zh-cn/search/鲜花/") #search后面的内容为搜索内容
# 接受 Cookie
if page.query_selector("button:has-text('接受所有')"):
page.click("button:has-text('接受所有')")
# 等待搜索结果加载
page.wait_for_load_state("networkidle")
print("搜索完成!")
browser.close()
open_pexels()运行代码后,浏览器会自动打开 Pexels 搜索"鲜花"页面,接受 Cookie 然后开始爬取图片内容。
2. 获取图片链接并下载
接下来,我们提取页面上的图片地址,并自动下载。
python
import os
import requests
from playwright.sync_api import sync_playwright
def download_images():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False) # 设为无头模式
page = browser.new_page()
page.goto("https://www.pexels.com/zh-cn/search/鲜花/")
# 接受 Cookie
if page.query_selector("button:has-text('接受所有')"):
page.click("button:has-text('接受所有')")
# 等待图片加载
page.wait_for_selector("img[src]")
# 获取图片的链接
img_elements = page.query_selector_all("img[src]")
img_urls = [img.get_attribute("src") for img in img_elements]
# 创建存储目录
os.makedirs("flowers", exist_ok=True)
for i, url in enumerate(img_urls):
if url.startswith("https"):
response = requests.get(url)
with open(f"flowers/flower_{i+1}.jpg", "wb") as f:
f.write(response.content)
print(f"下载成功:flower_{i+1}.jpg")
browser.close()
download_images()💡 代码解读:
page.wait_for_selector("img[src]"):确保图片加载完毕。query_selector_all("img[src]"):获取所有图片元素。requests.get(url):下载图片并保存到flowers/目录。page.click("button:has-text('接受全部')"):接受 Cookie,避免弹窗影响。
运行代码后,flowers/ 目录下会出现下载好的花卉图片!🎉
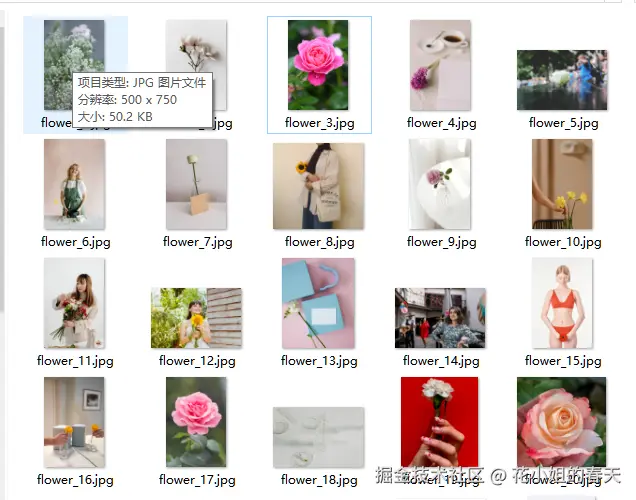
四、代码优化------爬取高清图
查看下载的图片属性,我们发现图片大小普遍在50kb左右,这显然是经过压缩的,如果你对图片质量没有要求,那到这一步基本上就可以实现我们的要求了。
但是花姐要下载高清图,通过在网页上观察html格式,我们发现当鼠标悬浮在图片上以后就会出现一个下载的按钮,按钮对应的URL就是高清图的下载地址。
对应下载按钮的html如下:
html
<a download="" title="下载" class="Button_button__RDDf5 spacing_noMargin__F5u9R
spacing_pr20__ZH8T3 spacing_pl20__MrrA1 DownloadButton_downloadButton__0aNOo
DownloadButton_fullButtonOnDesktop__EWWUC Button_clickable__DqoNe
Button_responsiveButton__9BBRz
Button_color-white__Wmgol Link_link__Ime8c spacing_noMargin__F5u9R"
href="https://images.pexels.com/photos/31213458/pexels-photo-31213458.jpeg?cs=srgb&
dl=pexels-andy-lee-222330306-31213458.jpg&fm=jpg&
_gl=1*v1y7x4*_ga*Njc3ODAyMzE3LjE3Mzk5NTA1ODk.
*_ga_8JE65Q40S6*MTc0MjM1MDM2Ni40LjEuMTc0MjM1MDY4Ny4wLjAuMA..">
<span class=""><svg class="spacing_noMargin__F5u9R" viewBox="0 0 24 24" width="24"
height="24"><use xlink:href="#file_download-c05dabe6d58e960ac55b98a0a0d0d223">
</use></svg><span class="Button_text__Yp1Qo"><span
class="DownloadButton_downloadButtonText__04wa_">下载</span></span></span></a>根据上面的规律我们把代码做一个简单的优化:
python
import os
import requests
from playwright.sync_api import sync_playwright
def download_images():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False) # 设为无头模式
page = browser.new_page()
page.goto("https://www.pexels.com/zh-cn/search/鲜花/")
# 接受 Cookie
if page.query_selector("button:has-text('接受所有')"):
page.click("button:has-text('接受所有')")
# 等待图片加载
page.wait_for_selector("img[src]")
img_elements = page.query_selector_all("img[src]")
if img_elements:
print("悬浮在第一张图片上...")
img_elements[0].hover() # 让鼠标悬停在第一张图片上使得<a download="" >标签可以显示出来
# 等待图片加载
page.wait_for_selector("a[download]")
# 获取前10张图片的链接
a_elements = page.query_selector_all("a[download]")
img_urls = [img.get_attribute("href") for img in a_elements]
# 创建存储目录
os.makedirs("flowers", exist_ok=True)
for i, url in enumerate(img_urls):
if url.startswith("https"):
response = requests.get(url)
with open(f"flowers/flower_{i+1}.jpg", "wb") as f:
f.write(response.content)
print(f"下载成功:flower_{i+1}.jpg")
browser.close()
download_images()五、爬取更多图片
上面的方法只能爬取几十张图片,我们可以通过模拟滚动,让网页加载更多图片从而能下载更多的图片。同时为了避免重复下载,可以使用Python中的集合(set)来存放图片的url。更改后的代码如下:
python
import os
import requests
from playwright.sync_api import sync_playwright
import time
def download_images(max_images=100):
"""
max_images 要下载的数量,默认100张
"""
with sync_playwright() as p:
browser = p.chromium.launch(headless=False) # 设为无头模式
page = browser.new_page()
page.goto("https://www.pexels.com/zh-cn/search/鲜花/")
# 接受 Cookie
if page.query_selector("button:has-text('接受所有')"):
page.click("button:has-text('接受所有')")
# 等待图片加载
page.wait_for_selector("img[src]")
img_elements = page.query_selector_all("img[src]")
if img_elements:
print("悬浮在第一张图片上...")
img_elements[0].hover() # 让鼠标悬停在第一张图片上使得<a download="" >标签可以显示出来
# 等待图片加载
page.wait_for_selector("a[download]")
img_urls = set() # 使用集合防止重复
scroll_pause_time = 2 # 每次滚动后等待时间
while len(img_urls) < max_images:
# 获取当前页面上的图片链接
a_elements = page.query_selector_all("a[download]")
for img in a_elements:
url = img.get_attribute("href")
if url and url.startswith("https"):
img_urls.add(url)
print(f"已获取 {len(img_urls)} 张图片")
# 模拟滚动鼠标(向下滚 1000 像素)
page.mouse.wheel(0,1000)
time.sleep(scroll_pause_time)
# 创建存储目录
os.makedirs("flowers", exist_ok=True)
for i, url in enumerate(list(img_urls)[:max_images]):
response = requests.get(url)
with open(f"flowers/flower_{i+1}.jpg", "wb") as f:
f.write(response.content)
print(f"下载成功:flower_{i+1}.jpg")
browser.close()
download_images(100)思考: 如果下载图片的过程中由于网络问题下载失败怎么办?可以尝试加个try except然后把下载失败的图片存放到本地csv文件中,等程序运行结束后重新把csv文件里的图片下载即可。
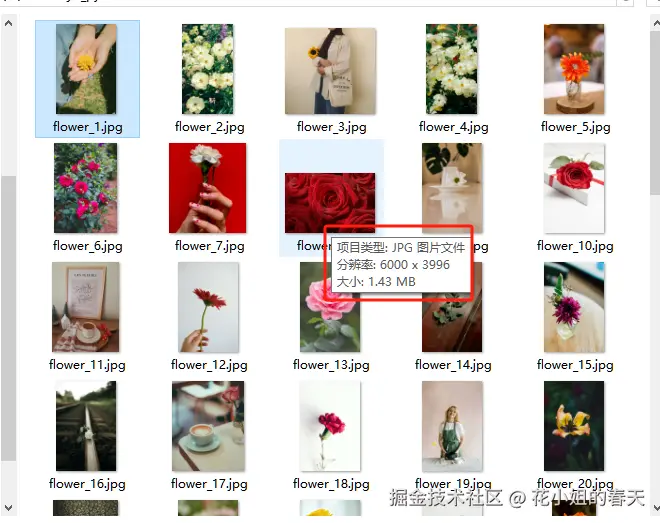
六、总结:你学到了什么?
- 了解了
playwright的基本用法,包括如何打开网页、输入搜索内容、提取数据。 - 学会了如何爬取 Pexels 网站的图片,并自动化下载。
- 掌握了反爬技巧,如等待元素加载、模拟用户操作、接受 Cookie。
这个方法不仅可以用来爬取鲜花图片,还可以扩展到其他类别,比如风景、动物、城市等。🎨 你可以试试改进代码,让它支持更多功能,比如批量下载更多图片、按关键词分类存储等。
学会了就快去试试吧!💪 如果你觉得这篇文章有用,别忘了分享给你的朋友们,一起提高 Python 自动化办公技能!🎉