在数据驱动决策的时代,电商平台的海量数据是十足金贵的。然而,像亚马逊这样的巨头为保护自身数据资产,构建了近乎完美的反爬虫防线,比如IP封锁、CAPTCHA验证、浏览器指纹识别,常规爬虫工具在这些防线面前往往束手无策。
下面介绍一种突破性技术Web Unlocker API,能够自动处理所有网站解锁操作,让您在不需要专业编码经验的情况下,也能高效获取亚马逊平台的各类数据。
一、Web Unlocker API简介
Web Unlocker使用Bright Data的代理基础设施,它具有三个主要组件:请求管理、浏览器指纹伪装和内容验证。这使得它能自动管理所有网站解锁操作,包括CAPTCHA验证、浏览器指纹识别、自动重试、选择合适的请求头和cookies等。当您需要获取亚马逊这样的高防网站数据时,这些功能尤为重要。
与常规代理服务不同,Web Unlocker API只需发送一个包含目标网站的API请求,系统就会返回干净的HTML/JSON响应。在后台,它的智能算法无缝管理寻找最佳代理网络、定制请求头、指纹处理和CAPTCHA验证等动态过程。

二、开始使用Web Unlocker API
Web Unlocker API可以以前所未有的成功率自动解锁防范最严密的网站。它的成功率超高,不成功不收费,自动化周期管理,并且不需要任何的编码和爬虫经验即可使用。
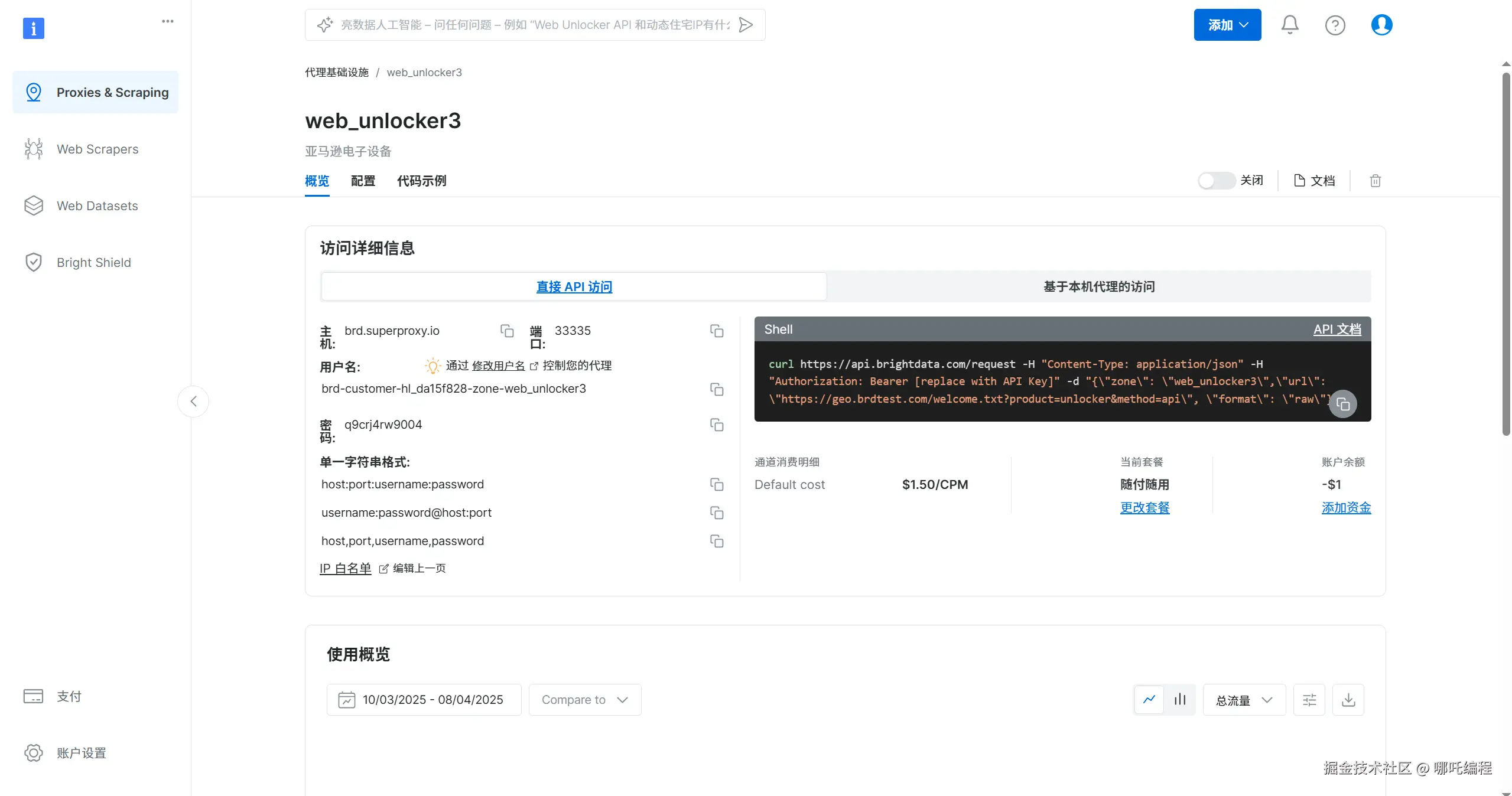
1、首先进入控制台页面,点击左侧第一个tab键"代理 & 抓取基础设施",找到"网页解锁器",开始使用。

2、进入网页解锁器页面后,填写通道名称,添加简短描述,点击添加

3、直接展示代理基础设施/web_unlocker3的详细信息
包含Web Unlocker API的详细信息、配置信息、代码示例。
4、配置网页解锁器
针对最难的网站进行自动化抓取,利用动态住宅IP,解决CAPTCHA,渲染JS,使用自定义指纹和cookies。

5、以Python脚本获取亚马逊平台数据为示例
(1)定位具体数据
进入亚马逊平台后,搜索"gaming",点击搜索,复制网页地址链接,在下面Python代码中有需要。
这个页面给出了很多电脑相关的产品,定位具体数据,比如华硕ROG的电脑、三星的固态硬盘的,还包含了产品信息、价格等。

(2)编写Python代码
代码中需要修改为已配置好的web_unlocker3的详细信息,比如主机brd.superproxy.io,端口33335,用户名brd-customer-hl_da15f828-zone-web_unlocker3,密码q9crj4rw9004等信息。
python
import requests
from bs4 import BeautifulSoup
import pandas as pd
import warnings
# 忽略SSL警告
warnings.filterwarnings('ignore', message='Unverified HTTPS request')
# 您的Bright Data凭证
customer_id = "brd-customer-hl_da15f828-zone-web_unlocker3"
zone_name = "web_unlocker3"
zone_password = "q9crj4rw9004"
# 代理设置
proxy_url = "brd.superproxy.io:33335"
proxy_auth = f"brd-customer-{customer_id}-zone-{zone_name}:{zone_password}"
proxies = {
"http": f"http://{proxy_auth}@{proxy_url}",
"https": f"http://{proxy_auth}@{proxy_url}"
}
# 目标亚马逊搜索URL
target_url = "https://www.amazon.com/s?k=gaming&language=zh&_encoding=UTF8&content-id=amzn1.sym.860dbf94-9f09-4ada-8615-32eb5ada253a&pd_rd_r=55c71001-73f7-488e-a943-eff18bee567b&pd_rd_w=4hK8A&pd_rd_wg=JgRuS&pf_rd_p=860dbf94-9f09-4ada-8615-32eb5ada253a&pf_rd_r=FWYKX6PAWN9C758RR97V&ref=pd_hp_d_atf_unk"
# 添加适当的请求头,模拟真实浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", # 设置为中文优先,因为URL包含language=zh参数
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.amazon.com/"
}
try:
print("正在通过Bright Data代理发送请求...")
response = requests.get(
target_url,
proxies=proxies,
headers=headers,
verify=False # 禁用SSL验证
)
print(f"请求状态码: {response.status_code}")
# 保存HTML响应
with open("amazon_gaming_search.html", "w", encoding="utf-8") as file:
file.write(response.text)
print("成功获取亚马逊搜索数据,已保存到amazon_gaming_search.html")
# 解析搜索结果
soup = BeautifulSoup(response.text, "html.parser")
search_results = []
# 针对亚马逊搜索结果页面的选择器
product_cards = soup.select(".s-result-item[data-asin]:not([data-asin=''])")
print(f"找到 {len(product_cards)} 个产品")
for card in product_cards:
asin = card.get("data-asin")
try:
title_element = card.select_one("h2 a span")
title = title_element.text.strip() if title_element else "N/A"
price_element = card.select_one(".a-price .a-offscreen")
price = price_element.text.strip() if price_element else "N/A"
rating_element = card.select_one(".a-icon-star-small")
rating = rating_element.text.strip() if rating_element else "N/A"
reviews_element = card.select_one("span.a-size-base.s-underline-text")
reviews = reviews_element.text.strip() if reviews_element else "N/A"
search_results.append({
"asin": asin,
"title": title,
"price": price,
"rating": rating,
"reviews": reviews,
"url": f"https://www.amazon.com/dp/{asin}"
})
print(f"已解析: {title[:30]}...")
except Exception as e:
print(f"解析产品 {asin} 时出错: {str(e)}")
# 保存结果到CSV
if search_results:
df = pd.DataFrame(search_results)
df.to_csv("amazon_gaming_search_results.csv", index=False, encoding="utf-8-sig")
print(f"已成功抓取 {len(search_results)} 个搜索结果,保存到amazon_gaming_search_results.csv")
# 显示前5条数据
print("\n搜索结果前5条数据:")
print(df.head().to_string())
else:
print("未找到搜索结果")
except Exception as e:
print(f"请求失败: {str(e)}")6、结果示例
成功运行后,代码会下载亚马逊游戏类别的搜索页面HTML,将原始HTML保存到amazon_gaming_search.html文件,解析出产品信息(ASIN、标题、价格、评分、评论数等),将解析结果保存到amazon_gaming_search_results.csv文件。



三、Web Scraper
1、快速使用Web Scraper
Web Scrapers提供了最大的灵活性,无需维护代理和解封基础设施,让用户能够轻松地从任何地理位置抓取数据,同时避开验证码和网站封锁。Web Scrapers作为一种专为网页抓取设计的GUI浏览器,内置了网站解锁功能,可自动处理封锁问题。
Bright Data的Web Scrapers是一种云服务,能够自动处理IP轮换、验证码解决和数据解析,将数据转换为结构化格式。 对于亚马逊数据,能够提取标题、卖家名称、品牌、描述、价格、货币、可用性和评论数量等信息。这种结构化的数据输出使得分析和集成变得简单直接,支持JSON、NDJSON和CSV等多种数据格式。

2、通过python获取亚马逊网页数据
python
# 获取商品信息
product_elements = driver.find_elements(By.CSS_SELECTOR, ".s-main-slot .s-result-item")
# 创建CSV文件并写入数据
with open('amazon_products.csv', 'w', newline='', encoding='gbk') as csvfile:
fieldnames = ['Title', 'Price', 'Image URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for index, product in enumerate(product_elements):
try:
title = product.find_element(By.CSS_SELECTOR, ".a-text-normal").text
price = product.find_element(By.CSS_SELECTOR, ".a-price-whole").text
image_url = product.find_element(By.CSS_SELECTOR, "img.s-image").get_attribute("src")
print(f"Product {index + 1}:")
print(f"Title: {title}")
print(f"Price: {price} USD")
print(f"Image URL: {image_url}")
# 写入CSV文件
writer.writerow({'Title': title, 'Price': price, 'Image URL': image_url})
except Exception as e:
print(f"Skipping product {index + 1} due to missing information.")
time.sleep(2)
# 关闭浏览器
driver.quit()3、定位具体数据

4、运行并保存到csv文件

四、SERP API
SERP API是解锁抓取套件的一部分,其核心优势在于处理完整的代理、解锁和解析基础设施,让用户可以专注于从搜索引擎结果页(SERPs)收集数据。SERP API通过模拟真实浏览器行为并提供完整的JavaScript支持来绕过搜索引擎的访问限制,实时提供准确的、结构化的搜索数据。
这种强大的自动化机制处理了IP轮换、验证码解决、浏览器指纹管理等复杂问题,使用户无需担心被搜索引擎封锁。

五、优惠升级
Web Unlocker (网页解锁器API)、Web Scraper API(网页抓取API)、SERP API(搜索引擎结果页 API)全部七五折,促销代码APIS25。
亮数据目前仍有首次充值1比1赠送,现在点击注册,充多少送多少,最高送500美金(相当于半价),并可与其它所有促销叠加使用,是中小企业商用的首选。
六、总结
Bright Data提供的Web Unlocker API、Web Scraper及SERP API构成了一套完整的数据采集解决方案,可有效应对亚马逊等高防网站的反爬挑战。
Web Unlocker API通过请求管理、浏览器指纹伪装和内容验证三大核心组件,实现了对CAPTCHA的自动解决、浏览器指纹的智能处理以及请求的自动优化。Web Scraper则提供了更高级的灵活性和控制力,能将原始数据转化为结构化格式。SERP API专注于搜索引擎结果页的数据获取,进一步拓展了数据采集的边界。
这些工具的核心价值在于让数据采集工作变得简单高效,使用户无需深厚的编程背景也能实现专业级的数据抓取。