
文章目录
- [1、Multiscale Dual-Representation Alignment Filter](#1、Multiscale Dual-Representation Alignment Filter)
- 2、代码实现
paper:SFFNet: A Wavelet-Based Spatial and Frequency Domain Fusion Network for Remote Sensing Segmentation
1、Multiscale Dual-Representation Alignment Filter
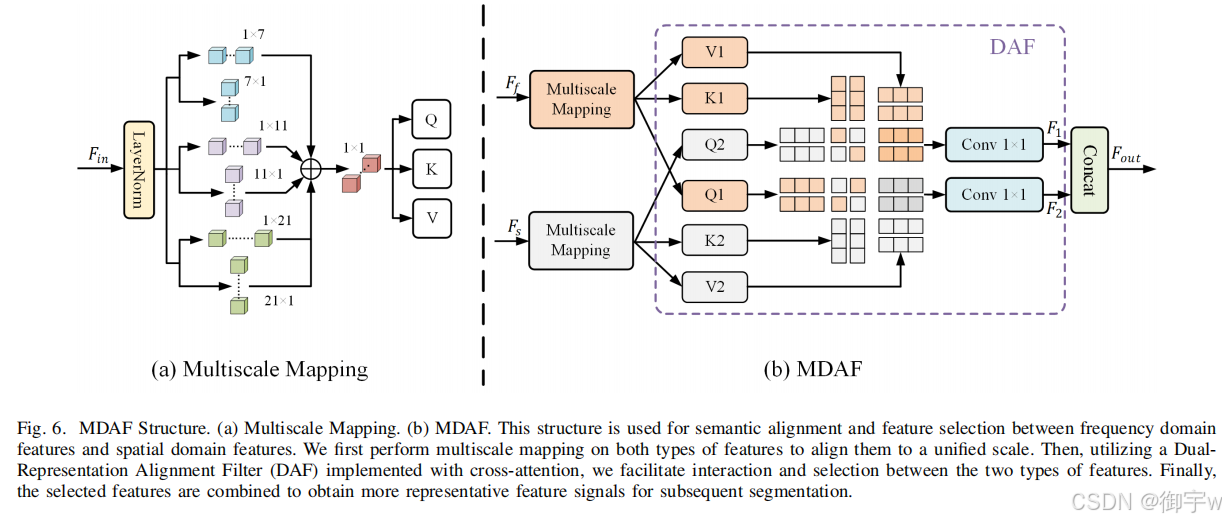
频率域特征和空间域特征分别捕捉图像的不同方面和属性,但它们之间存在语义差异。直接将两者融合可能导致特征表示不一致,无法充分发挥各自优势。需要一种方法来对齐两者的语义,并选择更具代表性的特征进行融合。所以这篇论文提出一种 多尺度双表示对齐过滤器(Multiscale Dual-Representation Alignment Filter) ,其主要包含以下两点:多尺度映射 (Multiscale Mapping) :使用不同尺度的竖条卷积对频率域特征和空间域特征进行处理。将处理后的特征拼接并进行 1x1 卷积,得到统一尺度的矩阵 Q, K, V 作为输入。多域注意力融合 (MDAF):设计了 DAF (Dual-Representation Alignment Filter) 结构,利用交叉注意力机制实现语义对齐和特征选择。通过查询对方及其自身的键值对计算注意力,并进行特征加权,最终实现特征选择。
实现过程:
- 多尺度映射:对空间域特征 Fs 和频率域特征 Ff 分别进行多尺度映射,得到两组矩阵 (Q1, K1, V1) 和 (Q2, K2, V2)
- DAF 计算:计算 DAF 输出 F1 和 F2:(1)F1 = δ1×1(Attn(Q2, K1, V1)):使用 Ff 的 Q, K, V 与 Fs 的 K, V 计算注意力,并进行特征加权。(2)F2 = δ1×1(Attn(Q1, K2, V2)):使用 Fs 的 Q, K, V 与 Ff 的 K, V 计算注意力,并进行特征加权。
- MDAF 输出:将 F1 和 F2 拼接得到最终的输出特征。
Multiscale Dual-Representation Alignment Filter 结构图:
2、代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import numbers
from einops import rearrange
def to_3d(x):
return rearrange(x, 'b c h w -> b (h w) c')
def to_4d(x, h, w):
return rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
class BiasFree_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(BiasFree_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
sigma = x.var(-1, keepdim=True, unbiased=False)
return x / torch.sqrt(sigma + 1e-5) * self.weight
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
mu = x.mean(-1, keepdim=True)
sigma = x.var(-1, keepdim=True, unbiased=False)
return (x - mu) / torch.sqrt(sigma + 1e-5) * self.weight + self.bias
class LayerNorm(nn.Module):
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type == 'BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x):
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
class MDAF(nn.Module):
def __init__(self, dim, num_heads=8, LayerNorm_type='WithBias'):
super(MDAF, self).__init__()
self.num_heads = num_heads
self.norm1 = LayerNorm(dim, LayerNorm_type)
self.norm2 = LayerNorm(dim, LayerNorm_type)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1)
self.conv1_1_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv1_1_2 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_1_3 = nn.Conv2d(
dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv1_2_1 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_2_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv1_2_3 = nn.Conv2d(
dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv2_1_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv2_1_2 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv2_1_3 = nn.Conv2d(
dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2_1 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv2_2_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_2_3 = nn.Conv2d(
dim, dim, (21, 1), padding=(10, 0), groups=dim)
def forward(self, x1,x2):
b, c, h, w = x1.shape
x1 = self.norm1(x1)
x2 = self.norm2(x2)
attn_111 = self.conv1_1_1(x1)
attn_112 = self.conv1_1_2(x1)
attn_113 = self.conv1_1_3(x1)
attn_121 = self.conv1_2_1(x1)
attn_122 = self.conv1_2_2(x1)
attn_123 = self.conv1_2_3(x1)
attn_211 = self.conv2_1_1(x2)
attn_212 = self.conv2_1_2(x2)
attn_213 = self.conv2_1_3(x2)
attn_221 = self.conv2_2_1(x2)
attn_222 = self.conv2_2_2(x2)
attn_223 = self.conv2_2_3(x2)
out1 = attn_111 + attn_112 + attn_113 +attn_121 + attn_122 + attn_123
out2 = attn_211 + attn_212 + attn_213 +attn_221 + attn_222 + attn_223
out1 = self.project_out(out1)
out2 = self.project_out(out2)
k1 = rearrange(out1, 'b (head c) h w -> b head h (w c)', head=self.num_heads)
v1 = rearrange(out1, 'b (head c) h w -> b head h (w c)', head=self.num_heads)
k2 = rearrange(out2, 'b (head c) h w -> b head w (h c)', head=self.num_heads)
v2 = rearrange(out2, 'b (head c) h w -> b head w (h c)', head=self.num_heads)
q2 = rearrange(out1, 'b (head c) h w -> b head w (h c)', head=self.num_heads)
q1 = rearrange(out2, 'b (head c) h w -> b head h (w c)', head=self.num_heads)
q1 = torch.nn.functional.normalize(q1, dim=-1)
q2 = torch.nn.functional.normalize(q2, dim=-1)
k1 = torch.nn.functional.normalize(k1, dim=-1)
k2 = torch.nn.functional.normalize(k2, dim=-1)
attn1 = (q1 @ k1.transpose(-2, -1))
attn1 = attn1.softmax(dim=-1)
out3 = (attn1 @ v1) + q1
attn2 = (q2 @ k2.transpose(-2, -1))
attn2 = attn2.softmax(dim=-1)
out4 = (attn2 @ v2) + q2
out3 = rearrange(out3, 'b head h (w c) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out4 = rearrange(out4, 'b head w (h c) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out3) + self.project_out(out4) + x1+x2
return out
if __name__ == '__main__':
x = torch.randn(4, 64, 128, 128).cuda()
y = torch.randn(4, 64, 128, 128).cuda()
model = MDAF(64).cuda()
out = model(x,y)
print(out.shape)