本周精选10篇CV领域前沿论文,覆盖视频生成与理解、3D视觉与运动迁移、多模态与跨模态智能、专用场景视觉技术等方向。全部300多篇论文已经整理好,感兴趣的自取!

一、视频生成与理解方向
1、First Frame Is the Place to Go for Video Content Customization
作者:Jingxi Chen, Zongxia Li, Zhichao Liu, Guangyao Shi, Xiyang Wu, Fuxiao Liu, Cornelia Fermuller, Brandon Y. Feng, Yiannis Aloimonos
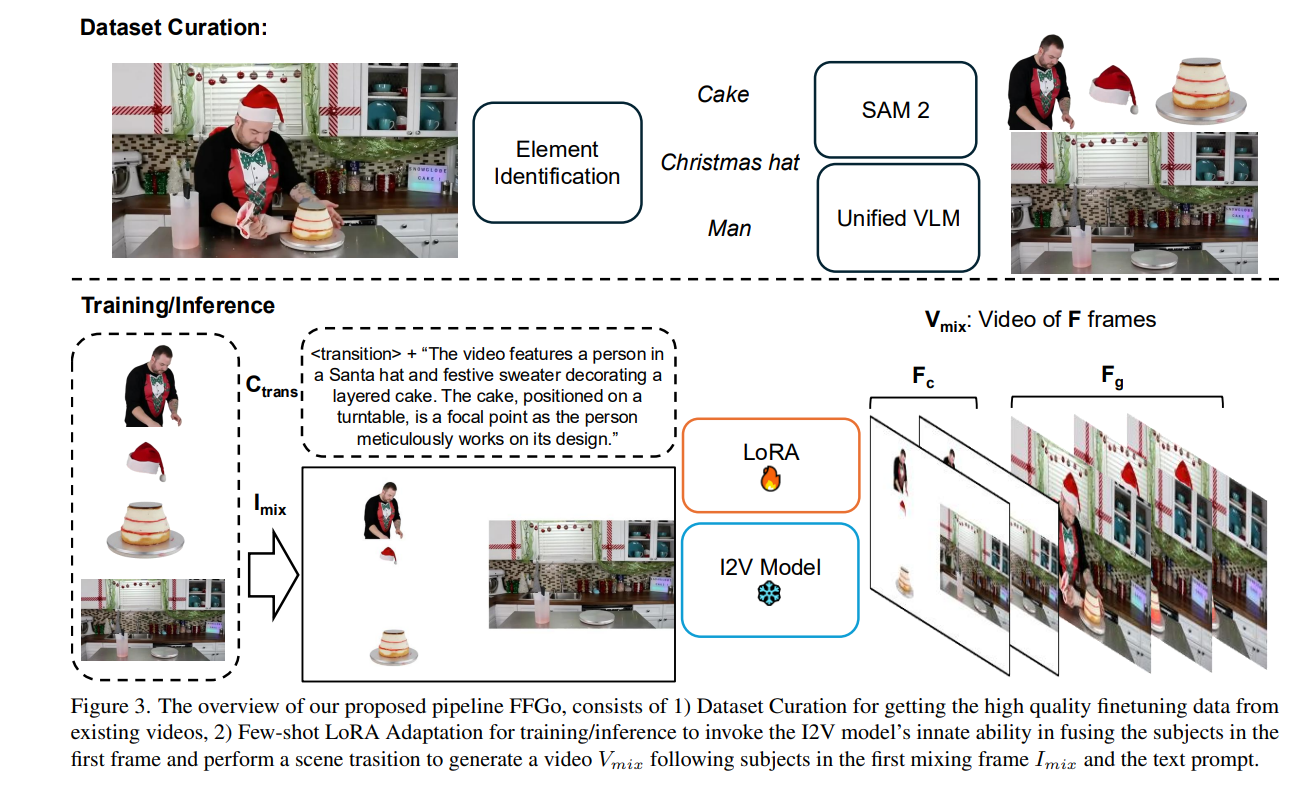
亮点:颠覆传统认知,揭示视频生成模型中第一帧的核心作用------并非仅作为时空起始种子,而是存储视觉实体供后续复用的"概念性记忆缓冲器";提出无需修改模型架构、无需大规模微调的视频内容定制方案,仅需20-50个训练样本即可实现多场景下的稳健通用定制;挖掘了视频生成模型在参考基视频定制任务中被忽视的强大潜力,为低成本视频内容个性化提供新范式。
论文:https://arxiv.org/abs/2511.15700
开源代码:https://firstframego.github.io/
2、AVATAAR: Agentic Video Answering via Temporal Adaptive Alignment and Reasoning
作者:Urjitkumar Patel, Fang-Chun Yeh, Chinmay Gondhalekar
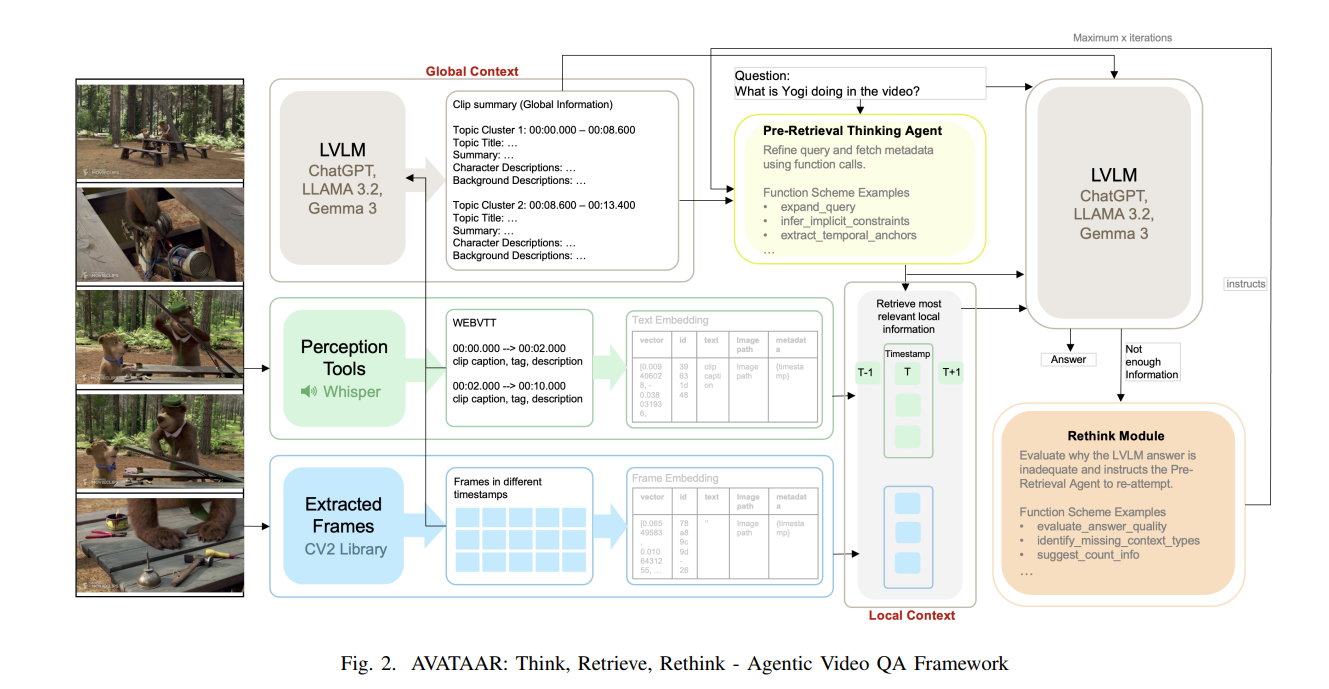
亮点:针对长视频问答中复杂查询(需综合理解与细节分析)的核心痛点,提出模块化、可解释的AVATAAR框架;创新融合全局视频摘要与局部上下文,设计"预检索思考代理+反思模块"的反馈循环,实现类人迭代推理,可根据部分答案优化检索策略;在CinePile基准上全面突破,temporal reasoning相对增益+5.6%、技术查询+5%、主题类问题+8%、叙事理解+8.2%,验证了各模块的正向贡献,为长视频QA提供兼具准确性、可解释性和扩展性的scalable解决方案。
论文:https://arxiv.org/abs/2511.15578
Comments:Accepted in the 5th IEEE Big Data Workshop on Multimodal AI (MMAI 2025), Dec 8-11, Macau, China, 2025 (Preprint Copy)
3、Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
作者:Cheng Yang, Haiyuan Wan, Yiran Peng, Xin Cheng, Zhaoyang Yu, Jiayi Zhang, Junchi Yu, Xinlei Yu, Xiawu Zheng, Dongzhan Zhou, Chenglin Wu

亮点:开创"通过视频推理"新范式,将视频生成与空间推理结合,填补视频模型推理能力评估的空白;构建VR-Bench基准,包含7920个程序化生成视频(覆盖5种迷宫类型+多种视觉风格),实现对空间规划、多步推理能力的系统评估;实证表明SFT可高效激发视频模型推理潜力,其空间感知性能优于主流VLMs,且存在测试时缩放效应------多样化采样可将推理可靠性提升10-20%,为空间推理任务提供全新技术路径。
论文:https://arxiv.org/abs/2511.15065
开源代码:https://imyangc7.github.io/VRBench_Web
二、3D视觉与运动迁移方向
1、Gaussian See, Gaussian Do: Semantic 3D Motion Transfer from Multiview Video
作者:Yarin Bekor, Gal Michael Harari, Or Perel, Or Litany
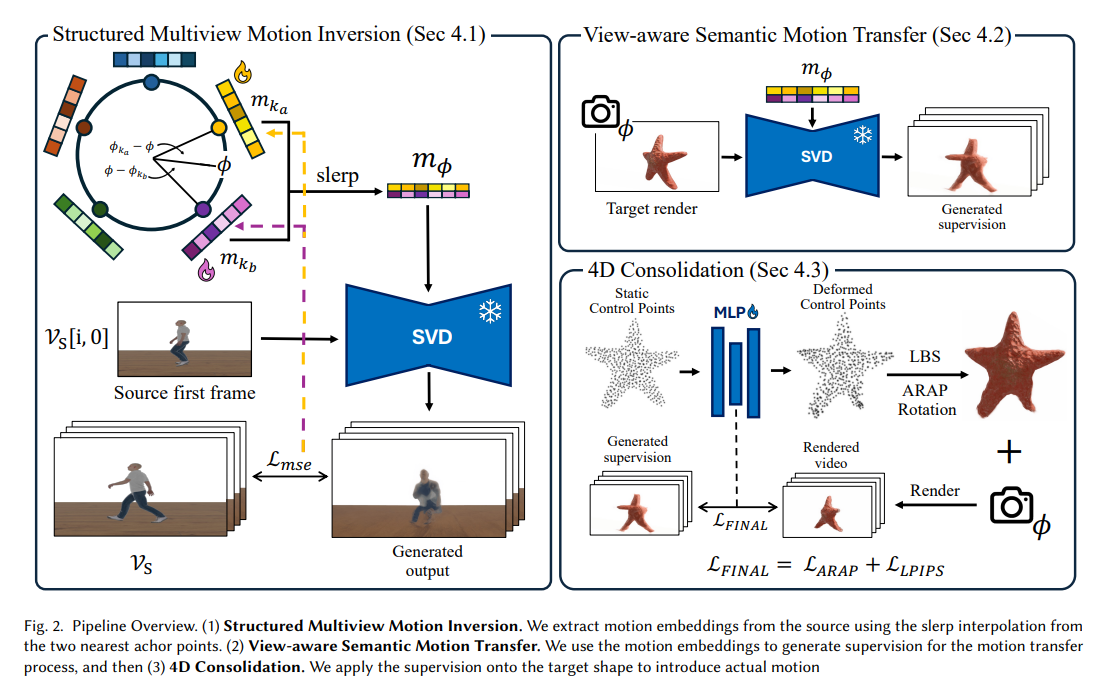
亮点:提出首个支持跨类别、语义对齐的无支架3D运动迁移方法,实现源视频运动向静态目标形状的精准迁移;创新引入锚点基视图感知运动嵌入机制,既保障跨视图一致性,又显著加速模型收敛;设计稳健4D重建流水线,有效整合含噪监督视频,优化动态3D高斯溅射(3D Gaussian Splatting)重建效果;建立首个语义3D运动迁移基准,实验验证其在运动保真度和结构一致性上显著优于现有基线。
论文:https://arxiv.org/abs/2511.14848
Comments:SIGGRAPH Asia 2025
2、IBGS: Image-Based Gaussian Splatting
作者:Hoang Chuong Nguyen, Wei Mao, Jose M. Alvarez, Miaomiao Liu
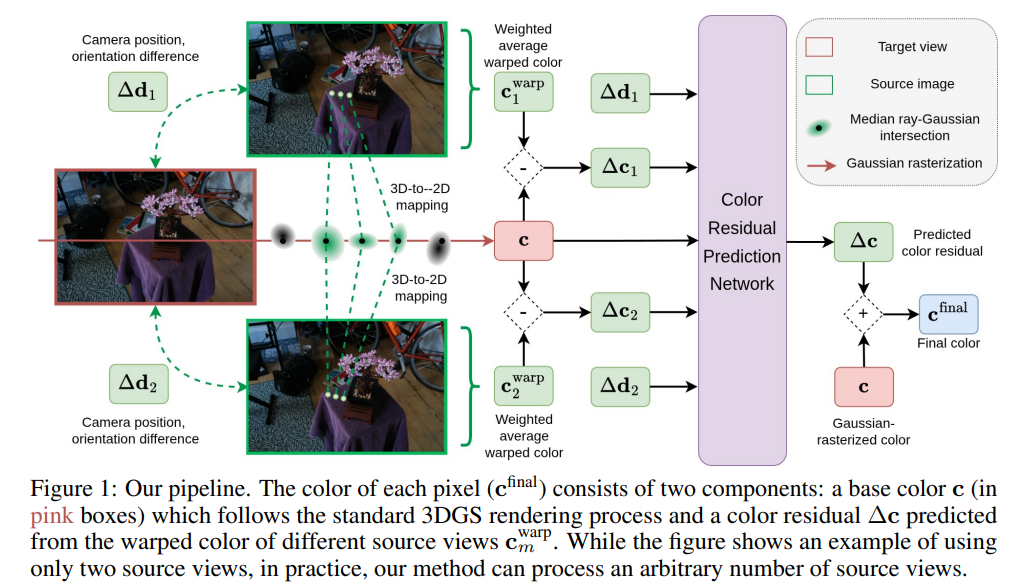
亮点:针对传统3D高斯溅射(3DGS)依赖低阶球谐函数,难以捕捉空间变化颜色和镜面高光等视图依赖效应的缺陷,提出图像基高斯溅射方案;创新将像素颜色建模为"3DGS基色+邻近训练图像学习残差"的组合,兼顾高分辨率细节还原与视图特异性颜色表达;在不增加存储开销的前提下,显著提升新视角合成(NVS)质量,尤其在高频细节和准确视图依赖效果上实现SOTA突破。
论文:https://arxiv.org/abs/2511.14357
开源代码:https://hoangchuongnguyen.github.io/ibgs
Comments:Accepted to NeurIPS 2025
三、多模态与跨模态智能方向
1、CroPS: Improving Dense Retrieval with Cross-Perspective Positive Samples in Short-Video Search
作者:Ao Xie, Jiahui Chen, Quanzhi Zhu, Xiaoze Jiang, Zhiheng Qin, Enyun Yu, Han Li
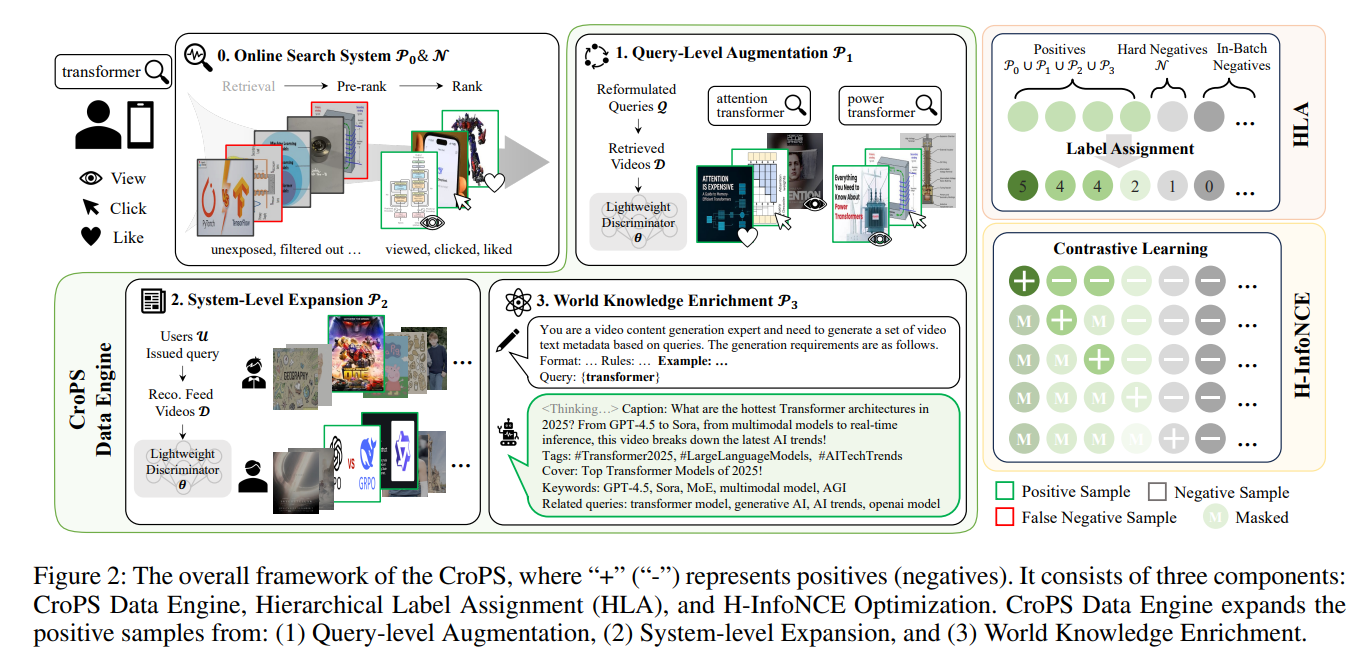
亮点:直击短视频搜索中密集检索的"过滤气泡效应"(依赖历史交互导致模型偏保守),提出CroPS跨视角正样本策略;从查询级(用户重写行为)、系统级(推荐流参与数据)、知识级(大模型世界知识)三维度引入多样化语义正样本;设计层级标签分配(HLA)策略与H-InfoNCE损失,实现细粒度、相关性感知的模型优化;在快手搜索大规模验证(离线+线上A/B测试),显著提升检索性能并降低查询重写率,已服务数亿日活用户。
论文:https://arxiv.org/abs/2511.15443
Comments:AAAI-2026, Oral
2、A Multimodal Transformer Approach for UAV Detection and Aerial Object Recognition Using Radar, Audio, and Video Data
作者:Mauro Larrat, Claudomiro Sales
亮点:针对单一模态在无人机检测/空中目标识别中的局限性,提出融合雷达、音频、RGB视频、红外(IR)视频的多模态Transformer模型;利用自注意力机制高效融合异模态特征,学习全面、互补且高判别力的表示;在独立测试集上实现近完美性能:宏平均准确率0.9812、召回率0.9873、F1分数0.9826、特异性0.9954,且计算高效(1.09 GFLOPs、122万参数、41.11 FPS),完全满足实时监控需求。
论文:https://arxiv.org/abs/2511.15312
3、Think Visually, Reason Textually: Vision-Language Synergy in ARC
作者:Beichen Zhang, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, Jiaqi Wang
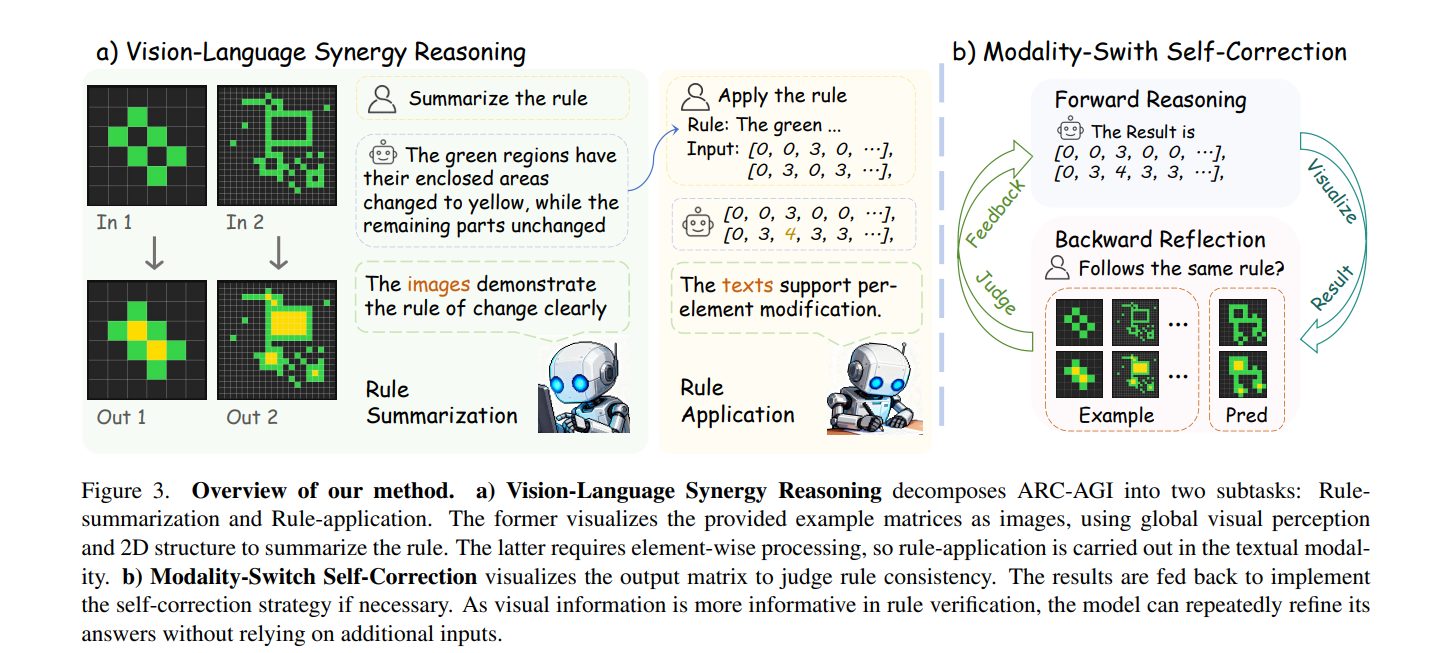
亮点:破解ARC-AGI抽象推理任务的核心矛盾------纯文本方法规则执行不精确、纯视觉方法模式抽象不足;提出视觉-语言协同推理范式,明确两种模态的互补优势:视觉负责全局模式抽象与验证,语言负责符号规则制定与精确执行;设计VLSR(模态对齐子任务分解)与MSSC(视觉验证文本推理纠错)两大策略;在多款旗舰模型上实现最高4.33%的性能提升,为通用人工智能的抽象推理提供关键技术支撑。
论文:https://arxiv.org/abs/2511.15703
四、专用场景视觉技术方向
1、ProPL: Universal Semi-Supervised Ultrasound Image Segmentation via Prompt-Guided Pseudo-Labeling
作者:Yaxiong Chen, Qicong Wang, Chunlei Li, Jingliang Hu, Yilei Shi, Shengwu Xiong, Xiao Xiang Zhu, Lichao Mou
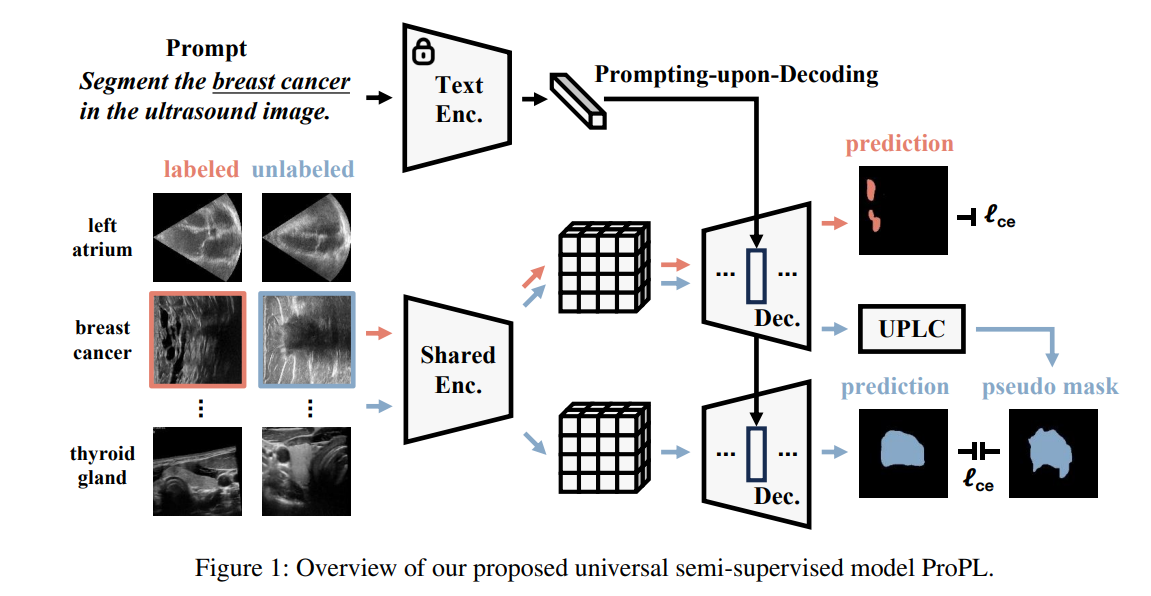
亮点:首次提出"通用半监督超声图像分割"任务,突破现有方法局限于特定器官/任务的瓶颈,大幅提升临床实用性;设计ProPL框架,采用"共享视觉编码器+提示引导双解码器"结构,通过解码时提示机制实现灵活任务适配,结合UPLC模块(不确定性驱动伪标签校准)保障自训练可靠性;构建涵盖5个器官、8个分割任务的综合数据集,实验验证其在多种指标上优于SOTA,建立通用超声分割新基准。
论文:https://arxiv.org/abs/2511.15057
Comments:AAAI 2026
2、A Dataset and Baseline for Deep Learning-Based Visual Quality Inspection in Remanufacturing
作者:Johannes C. Bauer, Paul Geng, Stephan Trattnig, Petr Dokládal, Rüdiger Daub
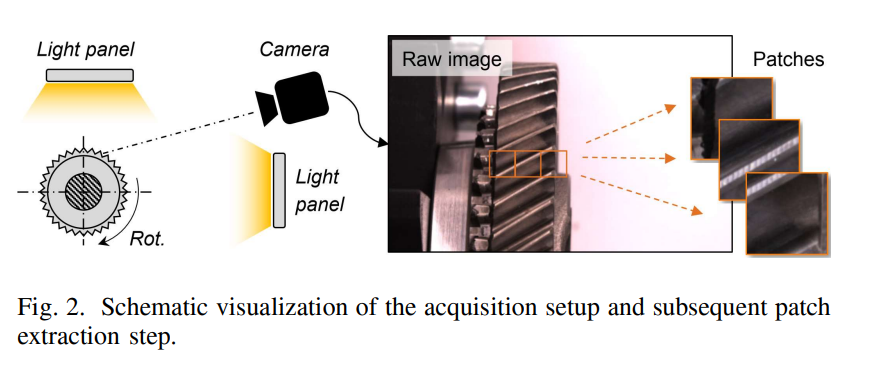
亮点:针对再制造行业视觉质检自动化的核心需求(人工为主、模型泛化性差),构建首个面向变速箱部件的视觉质量检测数据集,包含两种汽车变速箱的完好/缺陷部件图像,支持多种分布偏移场景的泛化能力评估;提出对比正则化损失函数,有效提升模型对未见过的部件类型、缺陷模式的泛化性能;为再制造领域提供标准化数据集与基准模型,助力行业实现质检自动化升级,释放生态与经济价值。
论文:https://arxiv.org/abs/2511.15440
Comments:Journal ref: 2025 IEEE 30th International Conference on Emerging Technologies and Factory Automation (ETFA)