Middle-output deep image prior for blind hyperspectral and multispectral image fusion
Signal Processing: Image Communication 2024,doi:10.1016/j.image.2024.117247
https://www.sciencedirect.com/science/article/pii/S0923596524001486
问题背景
-
高光谱和多光谱图像的特点与融合需求:高光谱成像能捕获数百个光谱带的二维场景信息,可用于精准农业、遥感、生物医学成像等领域,但通常空间分辨率低;多光谱图像能获取详细空间信息,但光谱分辨率低于高光谱图像。因此,HS 和 MS 图像融合旨在合并两者相关信息,得到高分辨率光谱图像。
-
传统融合方法的局限性:过去二十年,基于多分辨率分析、组件替换、光谱解混和贝叶斯估计等方法被用于解决融合问题,这些基于模型的技术依赖于对描述观测的退化算子的了解或近似,以及通过迭代算法解决优化问题。
-
监督深度学习融合方法的不足:卷积神经网络在计算机视觉和图像处理任务中表现出色,监督深度学习融合技术被提出,如基于 1D 卷积的 Unet 网络、3D 卷积神经网络等。但这些技术通常需要大训练数据集来优化网络参数,且性能受限于训练数据所跨越的子空间。
-
无监督深度图像先验方法的缺陷:无监督深度图像先验(DIP)方案克服了监督学习对训练集的依赖,可用于图像恢复等逆问题及融合问题。然而,DIP 方法需要知道确切的退化模型,因为期望图像是通过最小化观测值与恢复图像的退化版本之间的𝓁2 范数获得的。在光谱融合中,现实环境中退化算子通常未知或部分估计,这给 DIP 方法带来挑战。
-
盲高光谱图像融合方法的局限:处理估计退化算子和执行融合问题的方法称为盲高光谱图像融合。已有研究利用数据集学习退化模型并纳入融合方案,或修改 DIP 方法考虑盲高光谱图像融合,如学习全色(PAN)图像的线性退化模型、估计 MS 和 HS 图像的线性算子等。但在现实场景中,退化算子的线性假设可能无法准确捕捉高分辨率图像与 MS 和 HS 图像之间的复杂关系。
研究方法
-
MODIP 架构:提出中间输出深度图像先验(MODIP)用于无监督盲 HS 和 MS 图像融合。该架构将 DIP 实例作为连接网络的处理块,以无监督方式迭代学习生成融合图像的上采样非线性映射和描述 HS 和 MS 图像的退化算子。DIP 实例在单个模型 MODIP 中紧凑表达,通过最小化单个损失函数,使用端到端框架持续优化连接网络的所有权重集,融合图像在连接系统的中间阶段获得。
-
网络特点:MODIP 中包含的 DIP 处理块由不平衡网络组成,其输入和输出具有不同的数据分辨率,该方法可处理退化算子未知或部分估计的场景。
研究贡献
-
架构创新:引入 MODIP 网络架构用于无监督 HS 和 MS 图像融合,该方法不需要大训练数据集,在网络架构的中间阶段获得高空间和光谱分辨率(融合)图像。
-
克服 DIP 缺陷:与 DIP 网络架构相比,MODIP 性能不高度依赖于知道描述测量的退化函数,它纳入额外网络分支学习这些退化算子并将其集成到总损失函数中,在退化函数仅部分已知或完全未知时,利用学习到的算子生成融合图像。
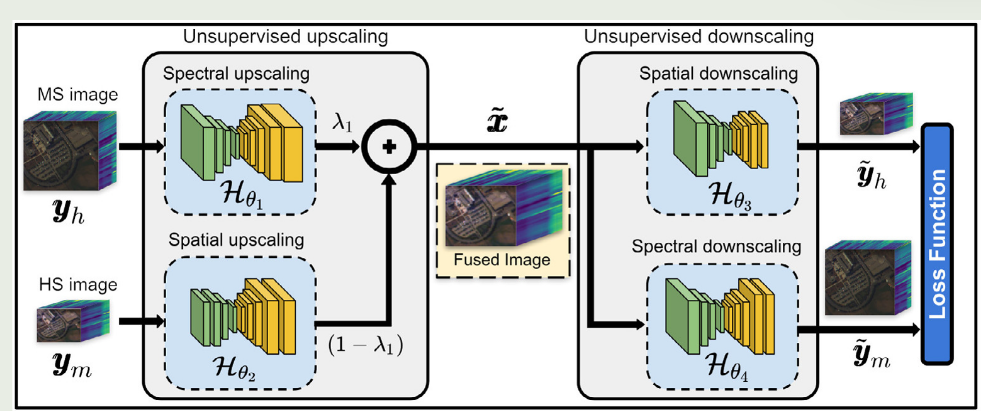
用于无监督HS和MS图像融合的拟议MODIP架构示意图。MODIP接收MS和HS图像作为输入。每个输入图像都经过一个升级的卷积网络,该网络试图产生高空间和光谱分辨率的特征。然后,应用仿射组合来获得融合的光谱图像。然后,融合光谱图像通过降尺度网络来估计HS和MS图像的近似版本。请注意,所有网络参数都是通过最小化单个损耗函数来联合优化的。
2.2. 深度图像先验
深度图像先验(DIP)是25提出的一种基于网络的框架,用于以无监督的方式解决成像逆问题。该框架假设卷积生成器的结构可以捕获表征图像细节的统计先验,而无需经过学习阶段。更确切地说,为了获得所需图像的估计,DIP方法拟合了卷积生成器网络的参数,最小化了考虑图像观察模型和可用退化图像的损失函数。在光谱图像融合的背景下,DIP方法可以适用于获得高分辨率图像,如下所示
其中z为固定随机噪声31,37或MS和HS29,41,其中Hθ1(⋅)表示卷积生成器网络仅接收MS图像并返回融合图像,θ1表示网络参数。请注意,损失函数最小化考虑了嵌入在HS和MS图像中的高光谱分辨率信息。一般来说,基于DIP的方法通过运行传统的深度学习优化算法(如从头开始梯度下降(随机初始化))来优化网络参数θ1。与使用大型数据库训练网络结构的传统深度学习方法相比,DIP方法使用可用图像(yyyh,yyym)和描述测量过程的降尺度算子(DDDh,DDDm)的确切知识来估计网络权重θ1。之后,在每次迭代中,通过实现训练好的图像生成器网络,可以从潜在输入zzz中获得目标图像xxx的估计,即xxx=θ1(zzz)。一般来说,DIP方法的良好性能需要正确了解下采样算子,因此DIP不会利用卷积网络提供的生成器功率来学习测量过程中引入的降级算子。因此,需要一个光谱图像融合框架,该框架考虑了无监督DIP模型的显著性能和卷积网络描述图像下采样算子的能力。
DIP 的不足
- 对下采样算子知识的依赖:一般来说,要使 DIP 方法取得良好性能,需要关于下采样算子的准确知识。因为 DIP 不会明确校正卷积网络提供的生成能力来学习测量过程中引入的降质算子,所以如果缺乏对下采样算子的准确认知,其性能会受到影响。
- 现实应用的局限性:在实际的光谱图像融合中,描述测量过程的下采样算子可能是未知的或难以准确获取的。但 DIP 方法依赖这些算子的准确知识来估计网络权重,这就导致在现实应用场景中,DIP 方法的适用性和效果会大打折扣,因此需要一种既能利用 DIP 模型的出色性能,又能借助卷积网络能力来描述图像下采样算子的光谱图像融合框架 。
DIP 不会明确校正卷积网络提供的生成能力来学习测量过程中引入的降质算子,主要有以下原因:
- 方法原理特性:DIP 基于这样的前提,即某些深度学习架构能在不使用训练集的情况下,在网络权重中捕获图像统计先验。它更侧重于利用现有图像和已知的降质算子信息,通过最小化观测图像与恢复图像的降质版本之间的特定范数(如𝓁2 范数)来估计网络权重,进而生成目标图像。其重点在于利用已有信息进行网络权重估计,而非对卷积网络生成能力进行明确校正来专门学习降质算子。
- 缺乏针对性机制:DIP 方法在优化网络参数时,运行的是传统的深度学习优化算法(如梯度下降),从随机初始化开始,依赖的是对降质算子的准确知晓以及可用图像信息。它没有内置专门的机制或模块,去对卷积网络在生成图像过程中的能力进行调整,使其能够主动学习测量过程中引入的降质算子的特性和规律。
- 对降质算子的依赖方式:DIP 依赖于对降质算子的准确知识来估计网络权重。它将降质算子作为已知条件纳入到网络权重的估计过程中,而不是通过校正卷积网络的生成能力去推断或学习降质算子。也就是说,它默认降质算子是明确已知的,而不是通过卷积网络自身的调整来适应或学习这些未知或不确定的降质算子 。
3. Proposed approach
我们介绍了中间输出深度图像先验(MODIP),这是一种用于光谱图像融合的盲无监督方法,通过消除对退化算子先验知识的需求,克服了标准DIP的局限性。首先,我们概述了所提出的深度学习架构。然后,我们分析了迭代优化网络参数的损失函数。最后,我们使用流形表示对所提出的方法进行了概念可视化。
3.1. 架构概述
图1显示了用于盲无监督HS和MS图像融合的拟议MODIP架构的示意图。请注意,前一节中描述的DIP模型接收单个输入潜在向量,并通过最小化考虑观察到的图像和描述测量值的退化算子的损失函数来生成高分辨率图像xxx。与DIP方法相比,MODIP接收两个不同大小的输入潜在矢量(与HS图像和MS图像相关的大小),以利用嵌入在两个观察图像中的高分辨率信息。我们的输入潜在向量分别是HS(zzzh)和MS(zzzm)图像的损坏版本,而不是随机固定向量。如图1所示,每个输入图像都经过一个特定的卷积

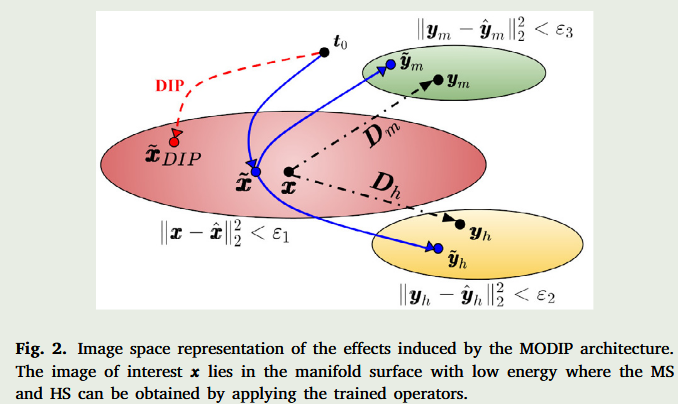
高低分辨率图像的关系高分辨率图像:刚才说的感兴趣图像 x 是高分辨率图像。通过对它使用降质算子 \(D_m\) 和 \(D_h\),就能得到低分辨率图像 \(y_m\)(多光谱图像)和 \(y_h\)(高光谱图像)。低分辨率图像:低分辨率图像 \(y_h\) 属于一个用黄色表示的低能量误差的低分辨率流形点集, \(y_m\) 则在绿色表示的流形区域里。也就是说,这两类低分辨率图像各自在它们对应的 "小空间" 里,并且都满足一定的低能量误差条件。
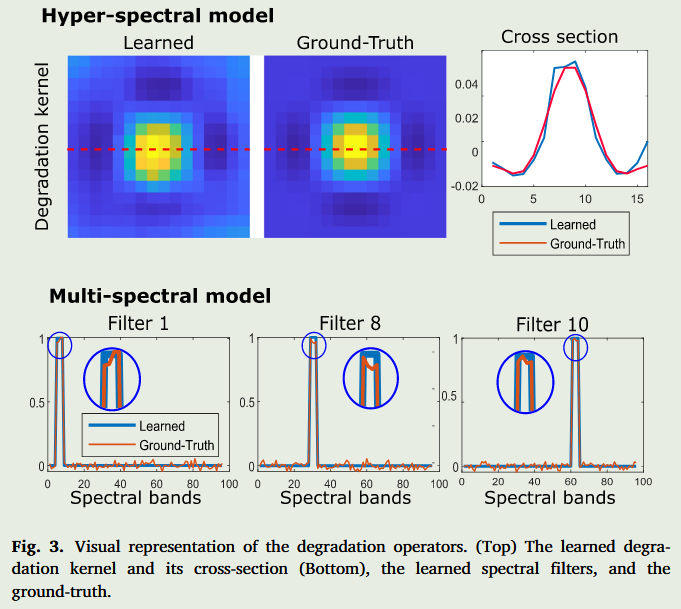
5.4. 学习退化模型
所提出的融合方法的主要贡献之一是,不需要知道MSI和HSI的确切退化模型,因为这些算子是使用子网络θ3和θ4学习的。为了证明所提出方法的有效性,我们使用τ1,τ2=0进行了之前的实验,即丢弃了嵌入在Dh和Dm中的知识。为了获得多光谱核,执行了一个获得θ3的全分辨率空间点扩散函数的过程56。该过程包括将白色光谱点单独通过̂θ3算子并记录测量值。这种光响应是通过空间窗口进行的,测量的中心值被排列在一个称为核的矩阵中。同样,通过̂θ4对每个光谱带通进行白色图像处理,并获得每个滤波器的强度。图3显示了MS图像中内核和HS图像中滤波器的估计和原始退化模型。可以看出,尽管模型完全未知,但所提出的网络可以正确估计退化模型,保持模型的准确性。
实验:
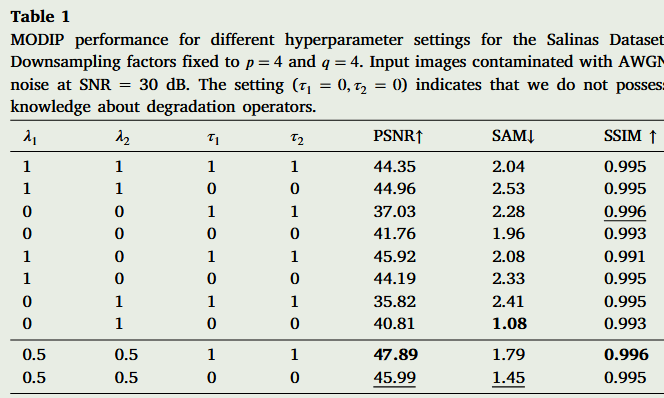
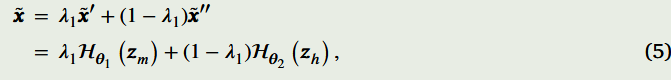
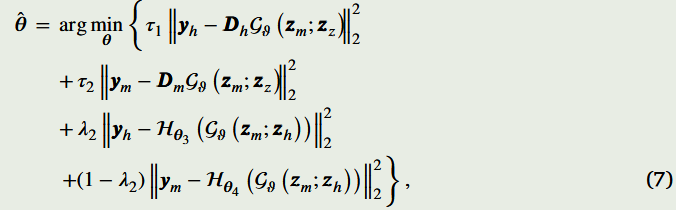
第一个实验说明了改变MODIP超参数的效果。注意,公式(5)中的λ1控制输入(MS和HS)图像对在所提出的架构的中间阶段获得的MODIP的影响。具体来说,λ1控制输入的影响。我们分析了固定值,如λ1=0,其中MODIP仅使用HS图像,λ1=1,其中MODIIP仅考虑MS图像。同样,方程式(7)中的λ2调节了退化网络对损失函数最小化的影响。例如,当λ2=0时,损失函数忽略了频谱下采样网络,而λ2=1则从损失函数中排除了空间下采样分支。所提出模型的两个基本和令人兴奋的超参数是τ1和τ2,它们由表示退化算子知识水平的指示变量组成,即如果τ1=0,损失函数将丢弃包含描述HS图像Dh的退化算子的项。因此,当Dh未知时,我们可以设置τ1=0。另一方面,当退化算子Dm未知时,我们可以固定τ2=0。此外,当两个退化算子都未知时,我们可以设置τ1=τ2=0。