2025深度学习发论文&模型涨点之------线性注意力
线性注意力(Linear Attention)是一种改进版的注意力机制,它在保持注意力机制强大建模能力的同时,显著降低了计算复杂度和内存占用,使其更适合处理大规模数据和长序列任务。线性注意力的核心思想是将传统的自注意力机制中的二次项计算(即两两位置之间的相似度计算)替换为线性操作。
我整理了一些线性注意力【**论文+代码】**合集,需要的同学看我简介
论文精选
论文1:
When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
当线性注意力遇上自回归解码:迈向更高效和有效的线性化大型语言模型
方法
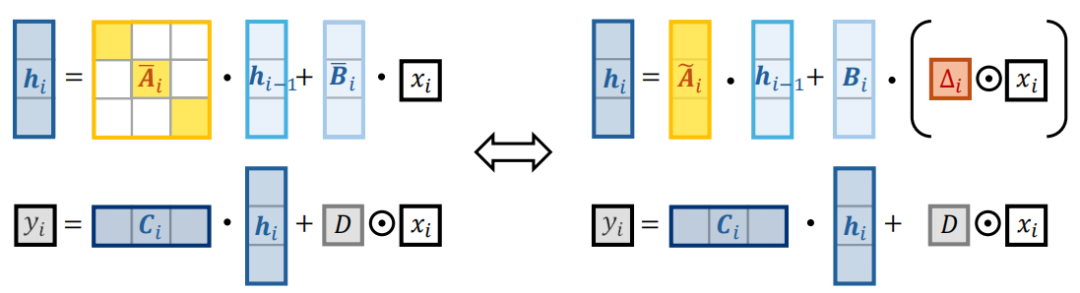
线性注意力(Linear Attention):通过将注意力计算从二次复杂度降低到线性复杂度,减少计算和内存需求。
局部卷积增强(Local Convolutional Augmentation):引入深度可分离卷积(DWConv)和因果掩码,防止信息泄露,提升性能。
分组线性注意力(Grouped Linear Attention):将输入序列划分为非重叠组,允许并行处理,提高效率。
兼容性设计:确保线性注意力与自回归解码和投机解码(Speculative Decoding)的兼容性,提升生成速度。
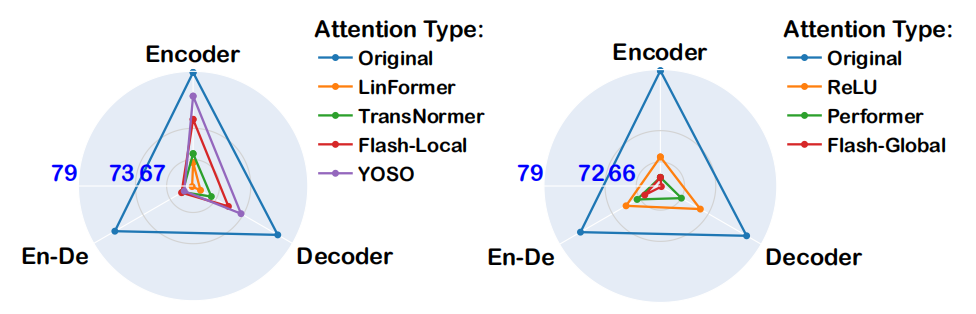
创新点
性能提升:在LLaMA模型上,使用增强线性注意力方法,相比传统线性注意力方法,实现了高达6.67倍的困惑度降低。
效率提升:在生成速度上,相比传统线性注意力方法,实现了高达2倍的速度提升。
兼容性增强:成功将线性注意力与投机解码集成,解决了线性注意力与自回归解码之间的兼容性问题,提升了训练和生成效率。
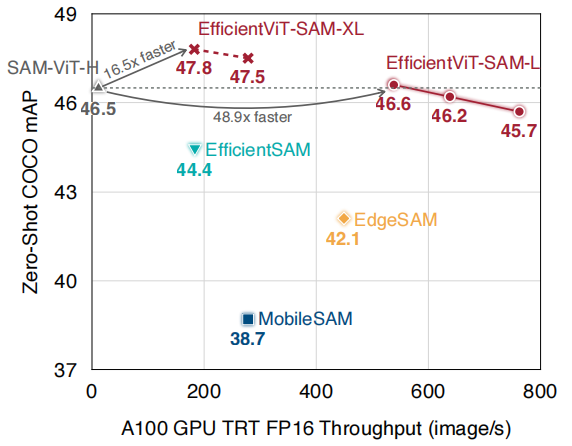
论文2:
Demystify Mamba in Vision: A Linear Attention Perspective
从线性注意力视角解密视觉中的Mamba
方法
选择性状态空间模型(Selective State Space Model):通过输入门、遗忘门和快捷连接等机制,增强模型的局部偏置和位置信息。
线性注意力(Linear Attention):将Mamba模型重新表述为线性注意力的一种变体,通过分析其与传统线性注意力的差异来揭示其成功的关键因素。
块设计(Block Design):引入改进的块设计,结合深度卷积和门控机制,提升模型性能。
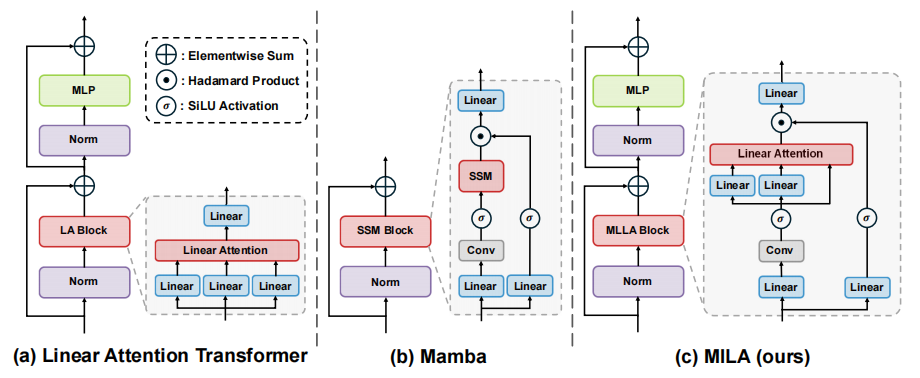
创新点
性能提升:提出的MILA模型在图像分类任务上,相比Mamba模型,Top-1准确率提升了0.6%至1.6%,同时保持了并行计算和快速推理速度。
效率提升:MILA模型在推理速度上相比Mamba模型有显著提升,例如在ADE20K数据集上,MILA-B模型的推理速度比Mamba2D-B模型快4.5倍。
设计优化:通过替换遗忘门为适合视觉任务的位置编码,解决了遗忘门在非自回归视觉模型中的适用性问题。
论文3:
EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
EfficientViT:用于高分辨率密集预测的多尺度线性注意力
方法
多尺度线性注意力(Multi-Scale Linear Attention):结合ReLU线性注意力和小核卷积,生成多尺度token,实现全局感受野和多尺度学习。
深度可分离卷积(Depthwise Separable Convolution):在FFN层中插入深度可分离卷积,提升局部特征提取能力。
硬件高效设计:避免使用softmax等硬件不友好的操作,确保模型在硬件设备上的高效部署。
创新点
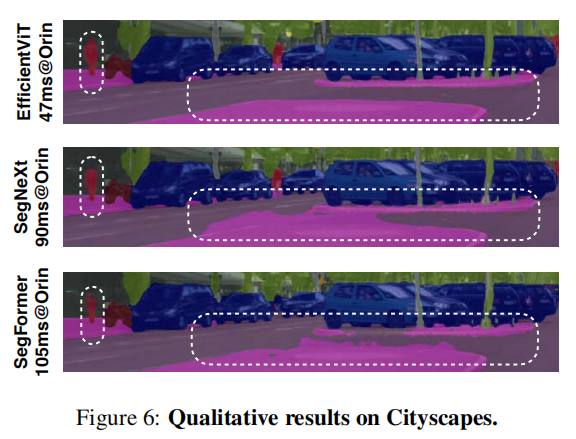
性能提升:在Cityscapes数据集上,EfficientViT-B3模型相比SegFormer-B1模型,mIoU提升了4.5%,同时在边缘GPU(Jetson AGX Orin)上的推理速度提升了8.8倍。
效率提升:在ADE20K数据集上,EfficientViT-B2模型相比SegFormer-B2模型,计算成本降低了1.8倍,推理速度在Jetson AGX Orin GPU上提升了2.4倍。
适用性增强:EfficientViT模型不仅在语义分割任务上表现出色,还在超分辨率和Segment Anything等任务上实现了显著的性能和效率提升。