wan2.1是阿里推出的一款视频生成大模型,具备强大的视觉生成能力,一经推出就受到创作者的广泛关注。虽然wan2.1大模型非常优秀,但有些同学苦于没有好的GPU设备一直没法自由体验,下面分享如何使用Cloud Studio免费服务器部署wan2.1大模型
1、创建项目
Cloud Studio是腾讯推出的一款云端开发者工具,支持开远程协作开发和应用部署,相当于一台集成了vscode的linux服务器。Cloud Studio提供了每月10000分钟的高性能GPU使用时间,基本够工作外使用了(用腾讯服务器部署阿里大模型,这何尝不是一种...),类似的IDE 还有阿里天池、魔塔等,基于免费额度等原因博主选择了Cloud Studio,有兴趣的同学可以尝试其他平台
打开腾讯Cloud Studio官网,点击登录,进入高性能工作空间
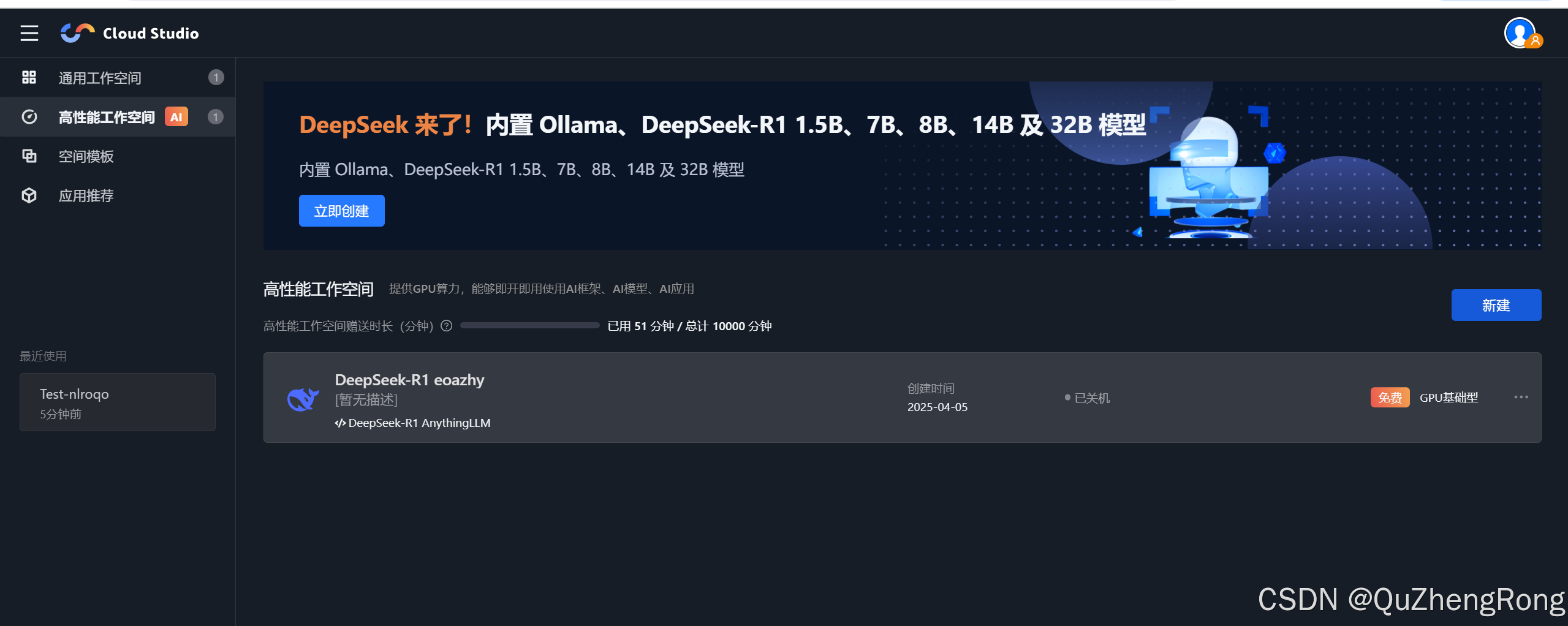
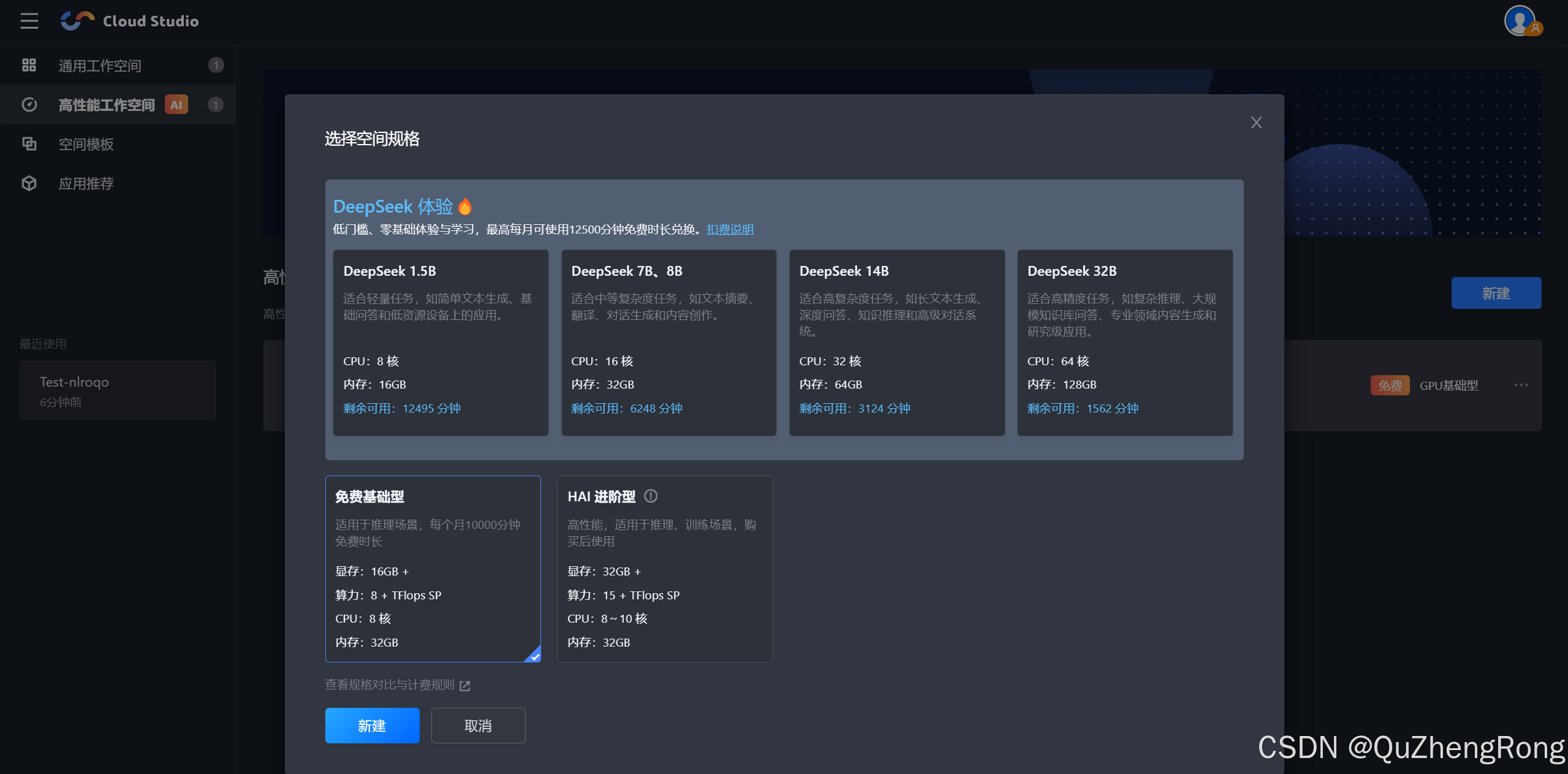
点击新建,选择免费基础型,等待开机
开机成功后会自动进入服务器主页,主页是一个vscode编辑器,可以写python代码训练大模型,编码功能我们暂时用不到,部署大模型只需要用到终端
2、安装comfyui
点击新建终端,在终端逐条执行下面的指令
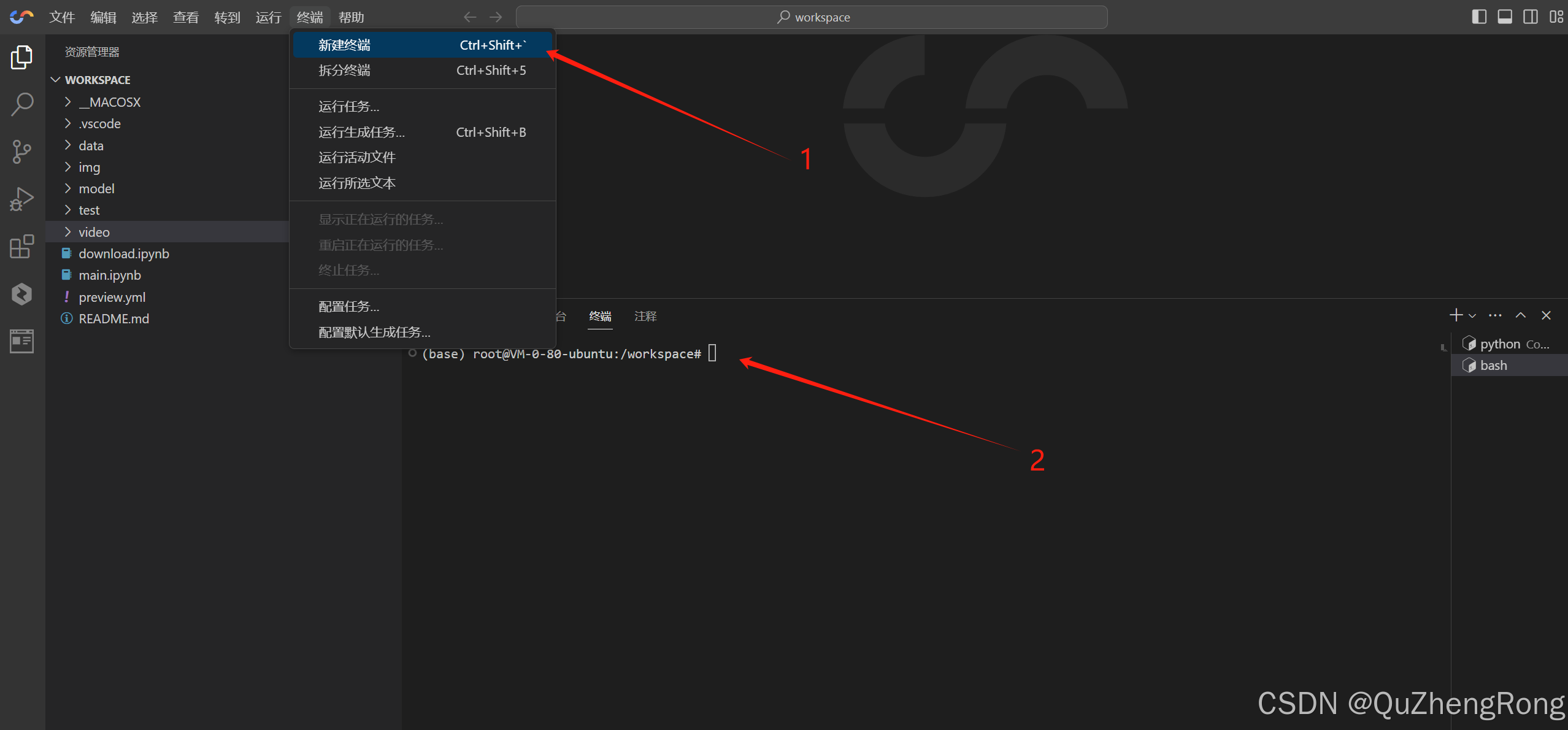
bash
# 安装git
apt-get update
apt install git-all
# 拉取ComfyUI代码
git clone https://github.com/comfyanonymous/ComfyUI.git
# 进入ComfyUI
cd ComfyUI
# 安装torch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
# 安装项目包
pip install -r requirements.txt
# 启动ComfyUI
python main.py启动ComfyUI成功后会提示To see the GUI go to: http://127.0.0.1:8188,127.0.0.1:8188是服务器内部的访问地址,我们在本地浏览器是无法直接访问的
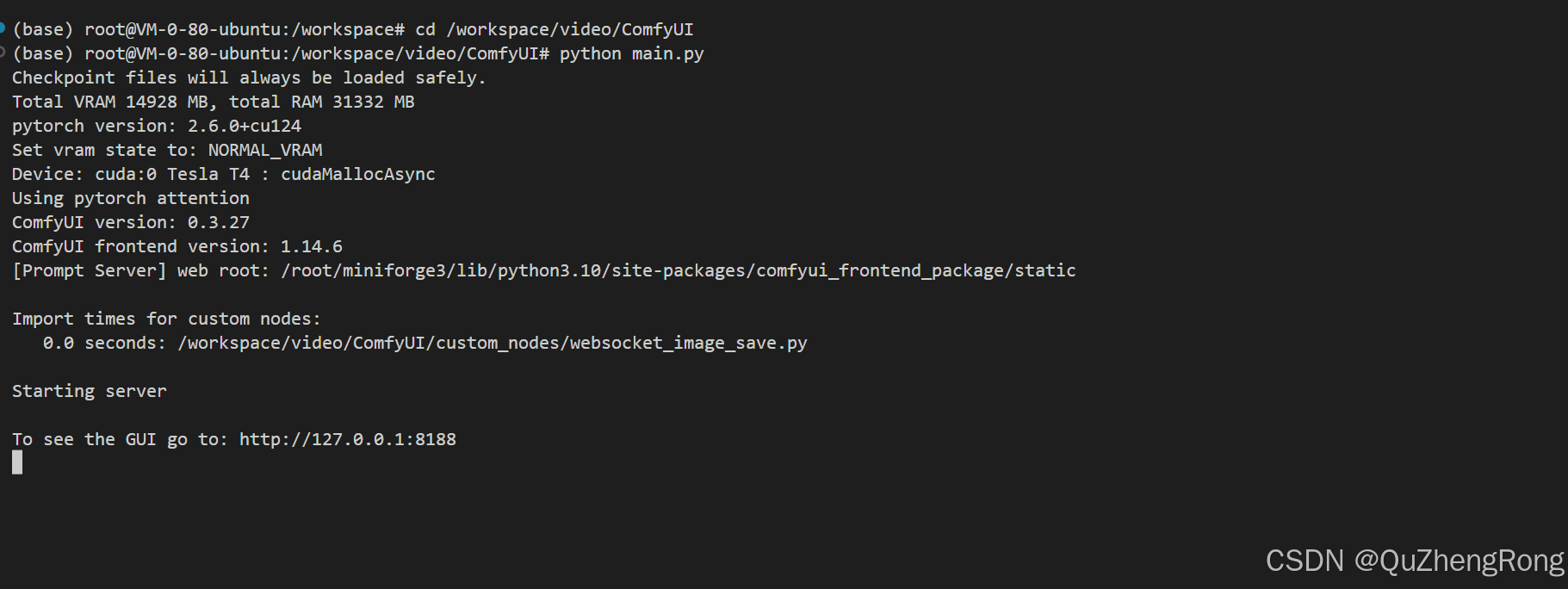
Cloud Studio提供了端口服务的预览方法,预览地址格式如下
bash
#预览地址格式
https://${X_IDE_SPACE_KEY}--${PORT}.${REGION}.cloudstudio.work/
#假设当前项目的浏览器地址为
https://hfrsgm.ap-guangzhou.cloudstudio.work/
#启动了一个的ComfyUI服务并使用8188端口
${X_IDE_SPACE_KEY}: hfrsgm
${PORT}: 8188
${REGION}: ap-guangzhou
#预览地址为
https://hfrsgm--8188.ap-guangzhou.cloudstudio.work/打开预览地址进入ComfyUI的web页面,预览没问题的话我们回到终端,按ctrl + c关闭服务
3、下载大模型
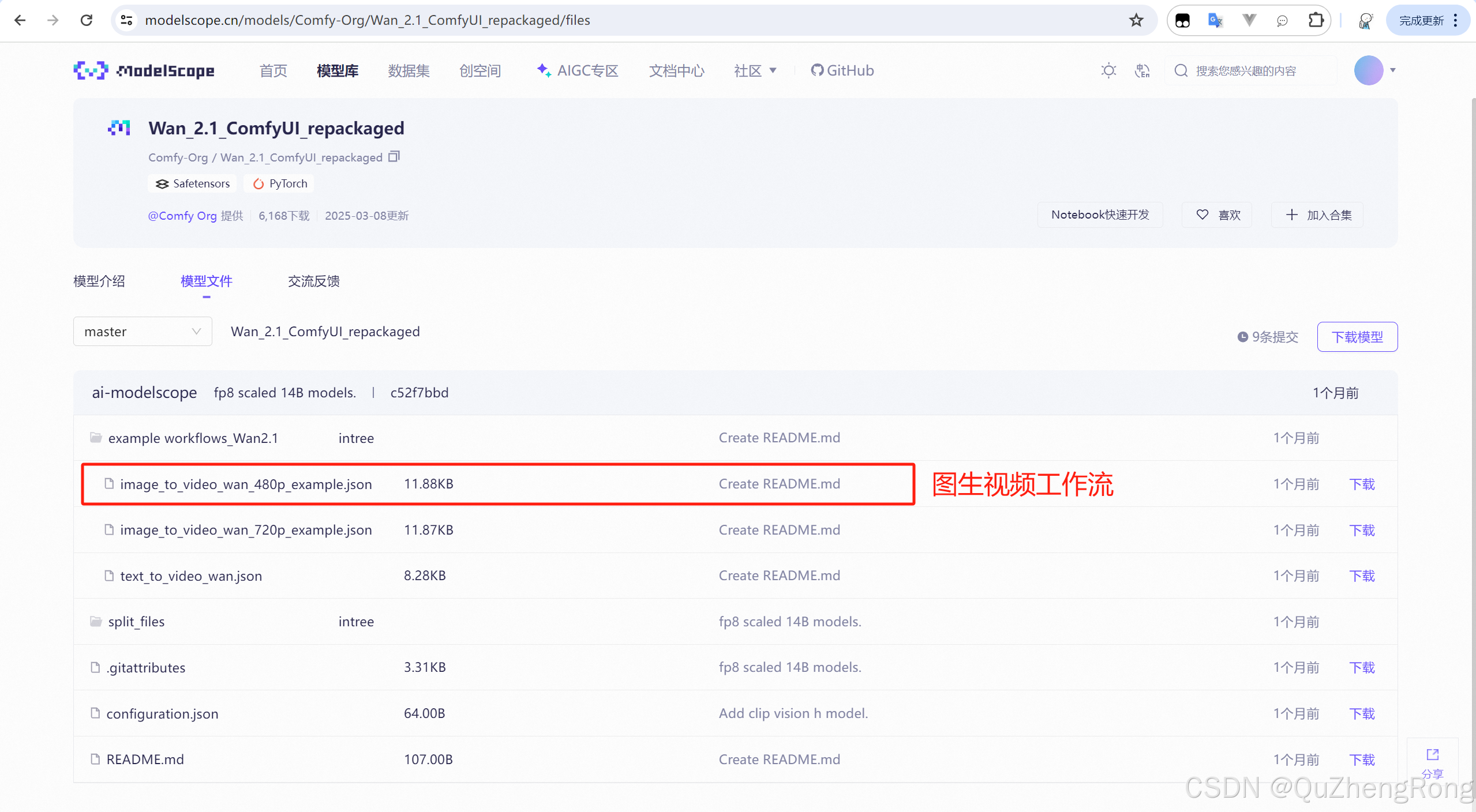
wan2.1的模型分为文生视频和图生视频两种,本篇以图生视频模型为例,在终端执行下面的指令下载大模型
bash
# 安装魔塔客户端
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple modelscope
# 下载模型到ComfyUI/models文件夹下
# 图片编码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/clip_vision/clip_vision_h.safetensors --local_dir /workspace/ComfyUI/models/clip_vision/
# 视频扩散模型
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/diffusion_models/wan2.1_i2v_480p_14B_fp8_scaled.safetensors --local_dir /workspace/ComfyUI/models/diffusion_models/
# 文本编码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors --local_dir /workspace/ComfyUI/models/text_encoders/
# 视频解码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/vae/wan_2.1_vae.safetensors --local_dir /workspace/ComfyUI/models/vae/4、生成视频
重新启动ComfyUI
bash
python main.py打开魔塔社区下载图生视频工作流文件
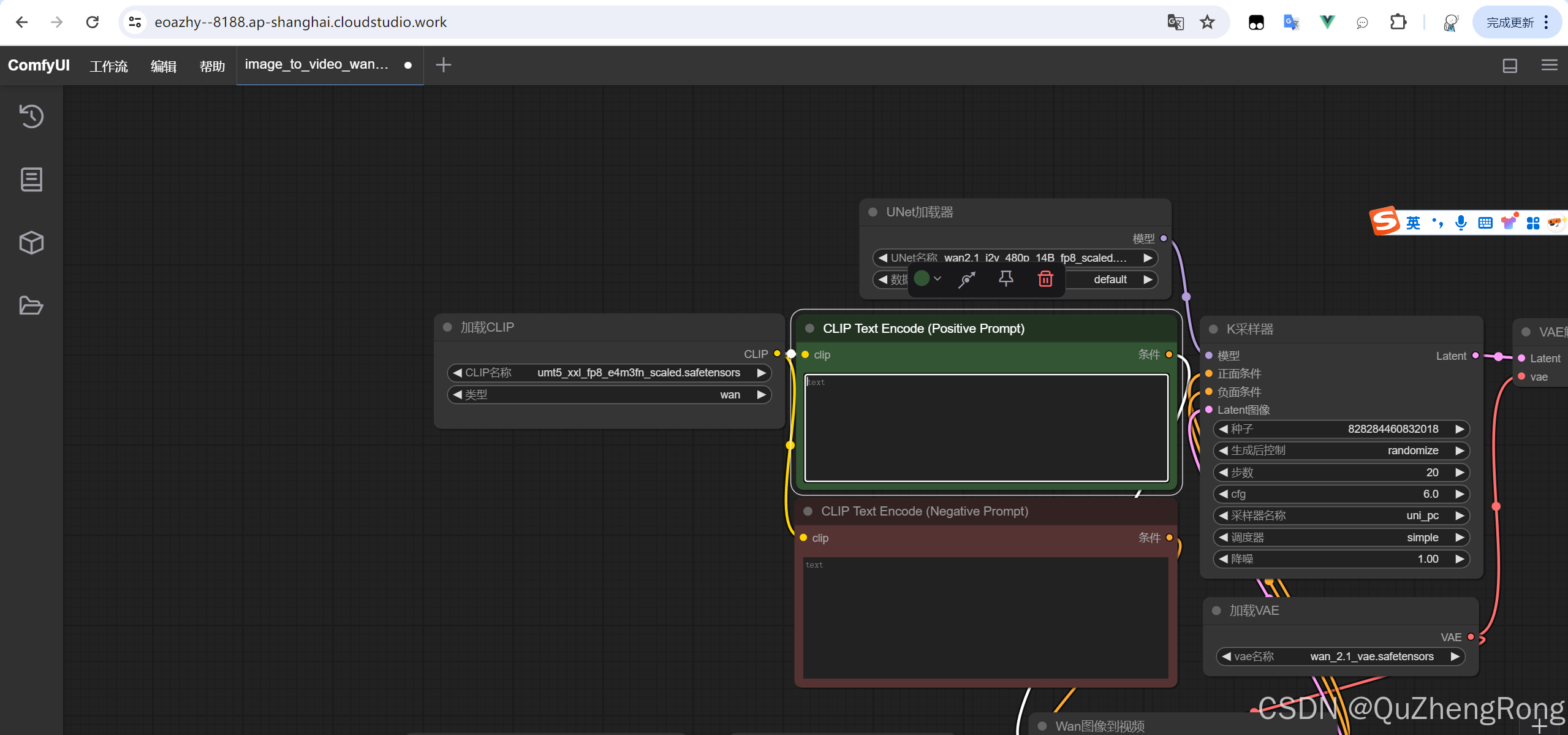
进入ComfyUI的web页面,打开下载好的工作流文件
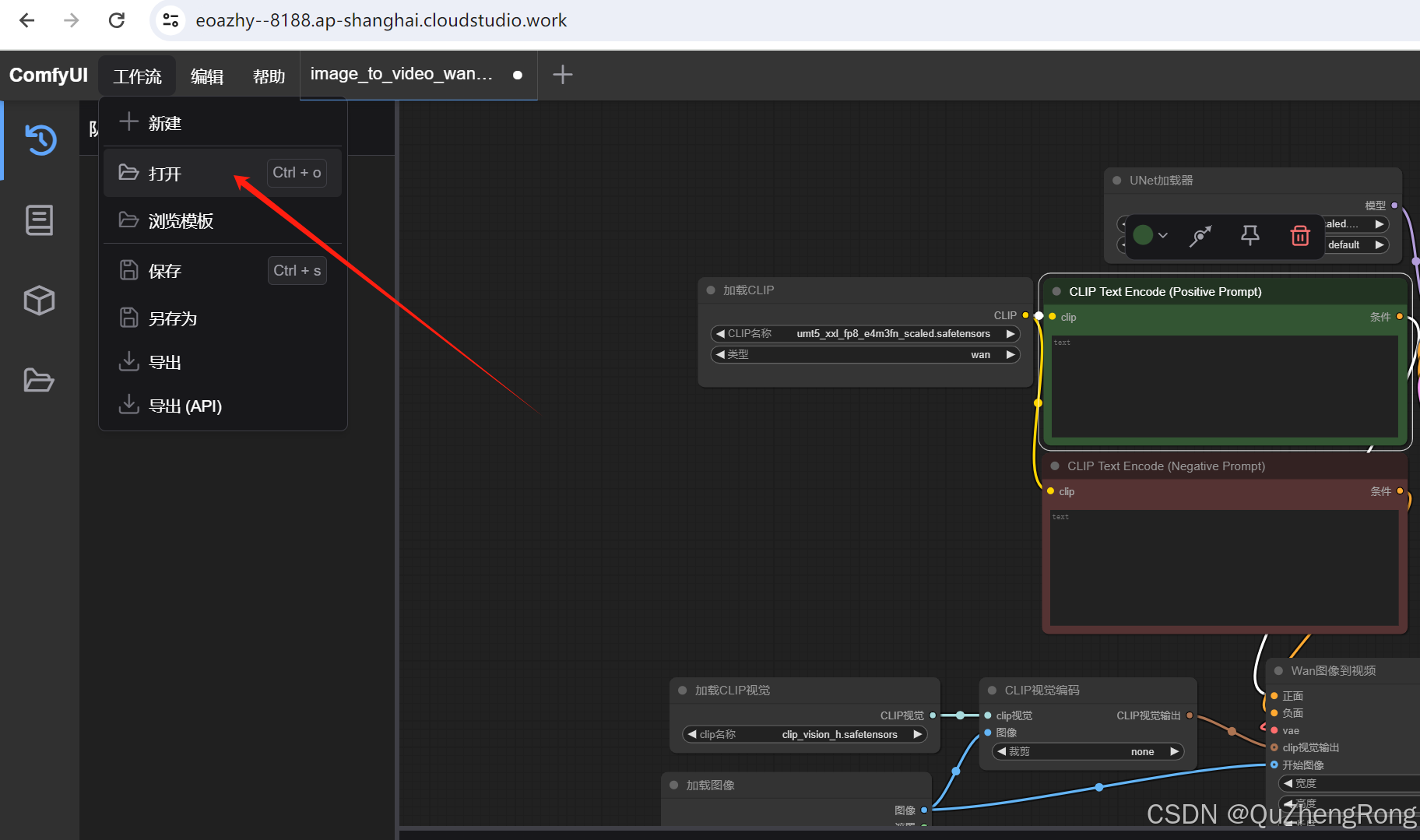
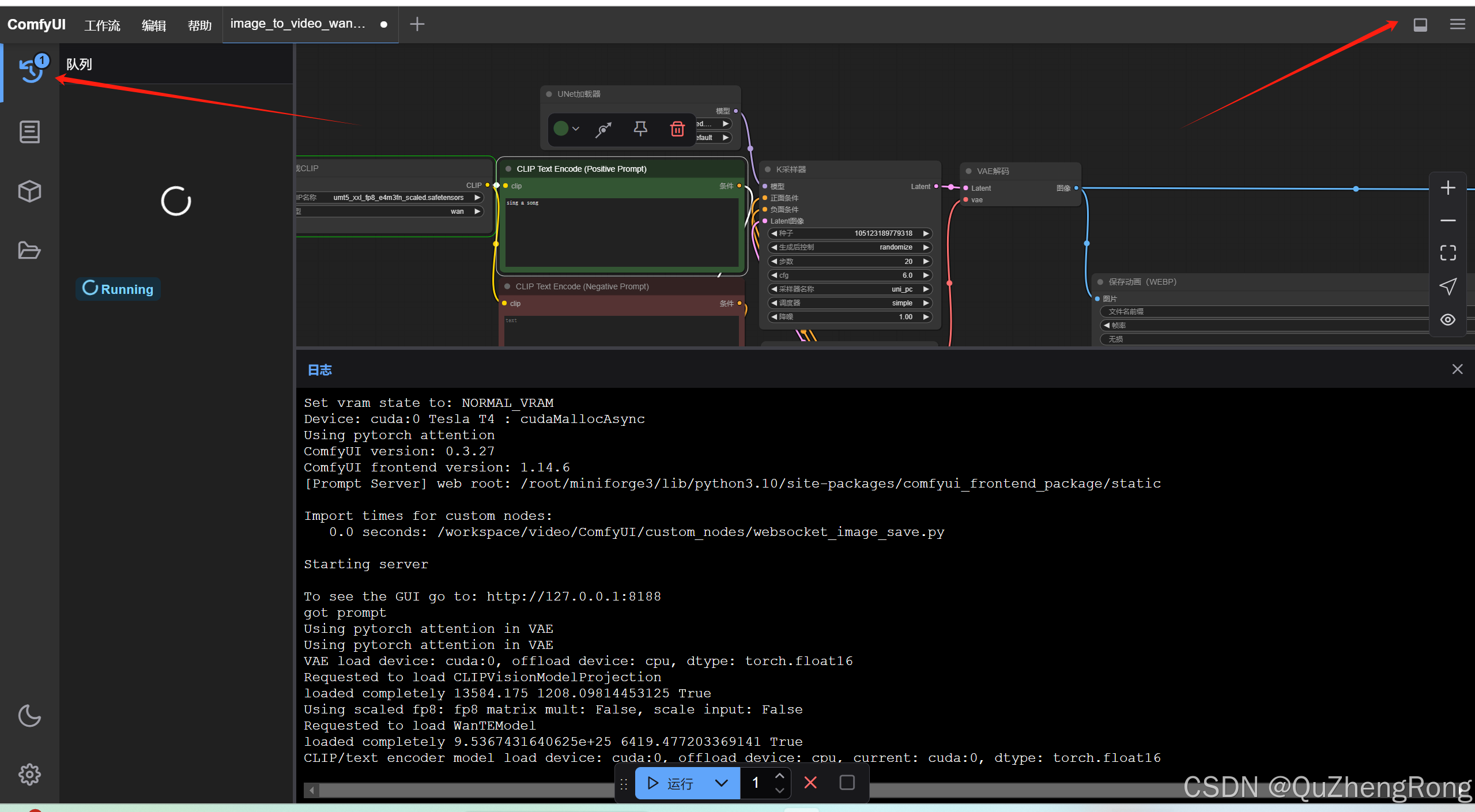
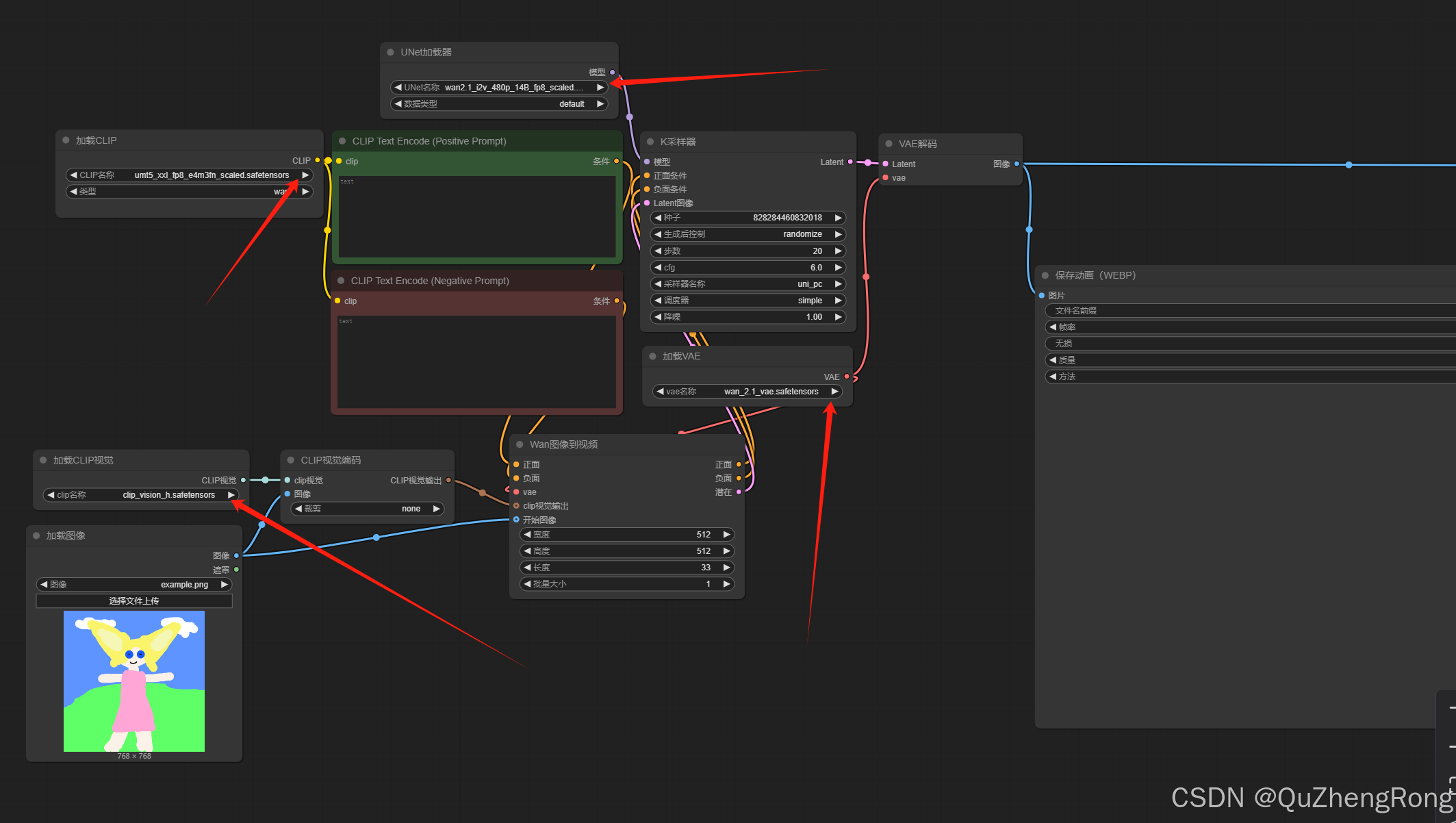
点击图片中的三角箭头,确保对应节点和模型均已加载来完成来确保模型能够正常运行
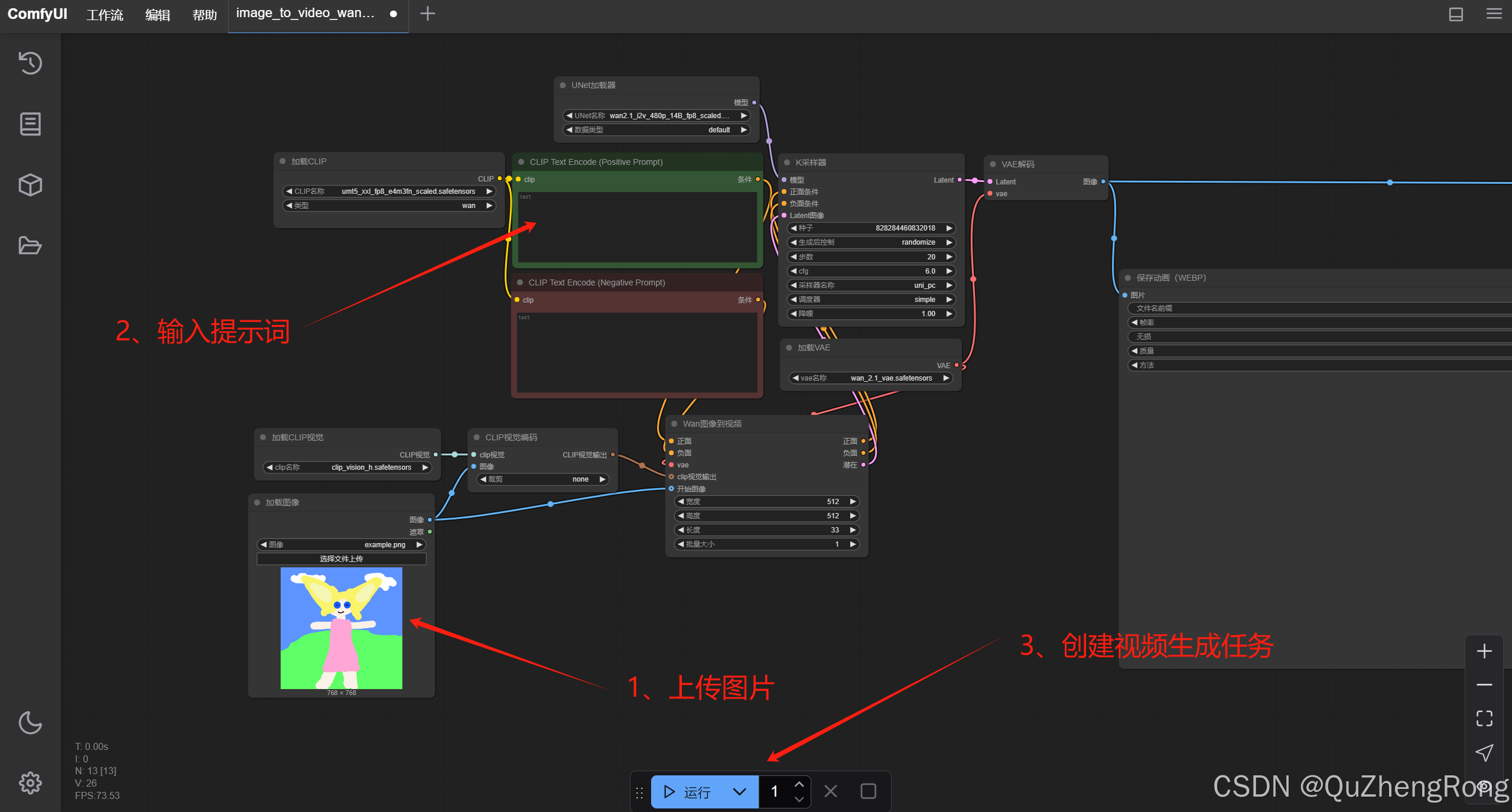
上传图片文件,输入提示词,点击运行创建视频生成任务
打开队列和面板查看视频生成进度