文章目录
- [3.3.2 应用层协议设计protobuf(二进制序列化协议)](#3.3.2 应用层协议设计protobuf(二进制序列化协议))
-
- [1. 什么是协议设计](#1. 什么是协议设计)
- [2. 判断消息的完整性->区分消息的边界](#2. 判断消息的完整性->区分消息的边界)
-
- 1.固定长度
- [2. 特定符号](#2. 特定符号)
- [3. 固定消息头加消息体](#3. 固定消息头加消息体)
- [4. 序列化后buffer前面加上一个字符流的头部,有个字符加上信息长度](#4. 序列化后buffer前面加上一个字符流的头部,有个字符加上信息长度)
- [3. 协议设计](#3. 协议设计)
-
- [1. 重点](#1. 重点)
- [2. 设计范例](#2. 设计范例)
-
- [1. IM即时通讯](#1. IM即时通讯)
- [2. 云平台节点服务器](#2. 云平台节点服务器)
- [3, nginx反向代理协议](#3, nginx反向代理协议)
- [4. http](#4. http)
- [5. redis](#5. redis)
- [3. 序列化方法](#3. 序列化方法)
-
- [1. 序列化和反序列化概念](#1. 序列化和反序列化概念)
- [2. 什么情况下需要序列化](#2. 什么情况下需要序列化)
- [3. 常见序列化方法(xml,json,protocolbuffer)](#3. 常见序列化方法(xml,json,protocolbuffer))
- [4. protobuf使用](#4. protobuf使用)
-
- protobuf协议的工作流程:
- protobuf为什么省字节:
- [3. protobuf使用实例以及工程经验](#3. protobuf使用实例以及工程经验)
- [4. protobuf编码原理](#4. protobuf编码原理)
- [5. protobuf的数据组织,协议消息升级](#5. protobuf的数据组织,协议消息升级)
- [5. 扩充oneof](#5. 扩充oneof)
- 6.示例
3.3.2 应用层协议设计protobuf(二进制序列化协议)
重点:
1.掌握通信协议设计原理
2.理解protobuf为什么快
3.掌握protobuf怎么在工程使用
1. 什么是协议设计
什么是协议
协议(Protocol) 是一套规则或约定,用于规范不同实体之间通信的格式、内容、顺序以及如何处理错误等。
在计算机系统中:
- 协议定义了数据如何编码、传输与解释。
- 类似现实生活中的"语言":如果你我要对话,必须说同一种语言、知道语序、停顿、语义。
比如:
- TCP 协议规定了传输层如何建立连接、如何可靠传输数据;
- HTTP 协议规定了浏览器和服务器之间如何请求和响应网页;
- 自定义的"消息格式"也是协议
为什么说进程间通信就需要协议,而不是客户端与服务端之间
客户端与服务端之间的通信 ,就是一种进程间通信(跨主机或本地)。进程间通信(IPC)包括:
- 本地 IPC:如共享内存、管道、消息队列;
- 网络 IPC:如 TCP/IP 通信(典型是客户端-服务器模式)。
不管哪种,只要两个独立进程 之间要交换数据,就必须 达成"怎么解释这些数据 "的共识 ------ 即需要 协议
为什么需要自己设计协议
| 原因 | 描述 |
|---|---|
| 效率需求 | 可能只需要几个字节传输,不需要完整 HTTP 报文(太臃肿) |
| 场景定制 | 系统消息结构是固定/可预测的,用现成协议反而复杂 |
| 资源受限 | 在嵌入式或无人机/无人船等平台,资源宝贵,自己设计协议可以压缩带宽和内存使用 |
| 安全性 | 有些自定义协议对攻击者来说是"黑盒",可降低被攻击面 |
| 功能扩展方便 | 可以灵活设计ACK机制、心跳包、数据校验等机制 |
举例:简单的自定义协议
plain
[HEAD][TYPE][LEN][DATA][CRC]- HEAD:帧头(0xAA55);
- TYPE:消息类型(如心跳/导航指令);
- LEN:数据长度;
- DATA:数据本体;
- CRC:校验码。
这种协议既精简又高效,适用于 USV/UAV 协同这类低时延、低资源的跨平台通信。
2. 判断消息的完整性->区分消息的边界
1.固定长度
- 每条消息占用固定的字节数,没有冗余的长度字段;
- 接收方按照"每N字节一条消息"读取和处理
优点:
- 解析速度极快,无需动态判断;
- 非常适合带宽有限、实时性强的嵌入式或硬实时系统;
- 实现简单,不需要缓冲区滚动或多线程解析器。
缺点:
- 缺乏灵活性,不能应对可变数据量;
- 可能造成 空间浪费(实际数据 < 固定长度);
- 不适合复杂的交互系统或信息种类过多的系统。
2. 特定符号
- 用特殊字符/标志表示消息开始和结束,如:
plain
<SOF>数据内容<EOF>举例:
- GPS NMEA 协议:
$GPRMC,.....*校验码\r\n - 串口通信中常见
<STX>...<ETX>
优点:
- 可变长度支持;
- 清晰易读,调试方便(尤其串口、日志里常用)。
缺点:
- 需要转义特殊字符(若内容中也出现SOF/EOF字符);
- 协议解析器略复杂
- 对字节流完整性要求较高(中间SOF/EOF丢失会错位)
3. 固定消息头加消息体
- 报文格式一般为:
plain
| HEAD | TYPE | LENGTH | BODY | CRC |- 解析时先识别HEAD,再读取LENGTH字段确定接收多少字节。
举例:
- 工业协议如 Modbus、CAN、无人机MAVLink;
优点:
- 通用性最强;
- 支持变长数据,适合异构系统通信;
- 能加校验码(CRC)、消息ID(用于ACK、重传等)等高级特性
缺点:
- 相比纯固定长度复杂
4. 序列化后buffer前面加上一个字符流的头部,有个字符加上信息长度
原理:
- 先用 JSON、Protobuf 等序列化数据;
- 再加上前缀(如总长度),如:
plain
[4字节长度][序列化后的内容]举例:
- Redis 使用 RESP 协议(文本前缀 + 换行符);
- HTTP/2、gRPC、Kafka 等使用 lengthpayload;
- socket.io、Thrift 等也有类似机制。
优点:
- 灵活性最高;
- 可嵌套结构体(如嵌入式系统与服务器对接);
- 配合现成的库(Protobuf/Flatbuffers)效率也很高。
缺点:
- 要引入额外序列化库;
- 消息体结构需要双方都了解(或共享 schema)
- 带宽、内存资源敏感的设备慎用(不适合裸片/超轻系统)
3. 协议设计
1. 重点
- 消息边界
- 版本区分
- 消息类型区分
- 消息budy序列化协议选择
2. 设计范例
1. IM即时通讯
- 消息边界:第一个字节作为帧的起始
- 版本号:靠前放
- appid:识别不同客户
- service_id:对应命令的分类组
- commend_id:分组里面的子命令
- seq_num:消息序号(业务序号)
- reserve:保留
头有十六个字节 - body
2. 云平台节点服务器
- STAG:通信协议数据开始标记
- version:版本号
- checksum:校验和,crc校验
- type:协议体格式(json,xml,protobuf等)
- seqno:序列号
- length:报文长度
- reserve:保留
头有十八个字节 - body
3, nginx反向代理协议
Nginx 自身协议不多,但它支持例如:
- HTTP(标准格式)
- FastCGI、GRPC、Websocket 转发协议
- 内部也可做 X-Forwarded-For、X-Real-IP 等头部协议标注。
实践中经常会在 Header 中加自定义字段来传递用户/设备上下文
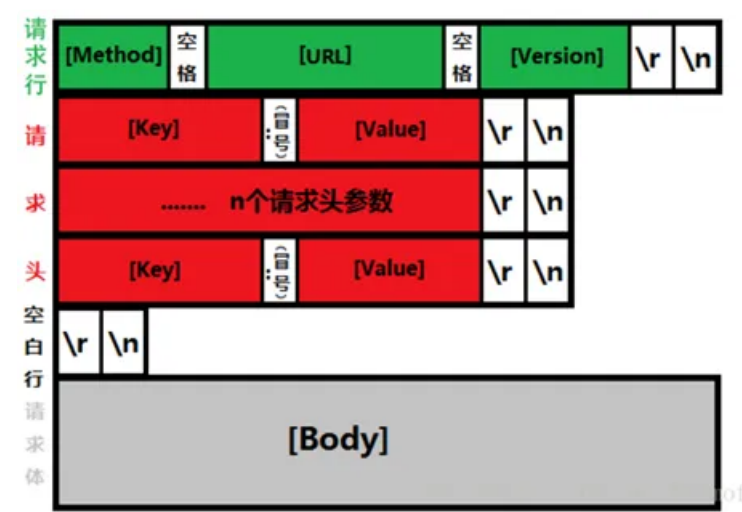
4. http
两个换行符之后就是body,复杂
5. redis
缺点:
- 基于行文本协议 ,有前缀
*、$等表示参数数量/长度; - 单行或多行结构都可以表示;
- 高效解析、极简实现、支持 pipeline。
优点:
- 文本协议,调试方便;
- 对性能也进行了很好的优化
3. 序列化方法

1. 序列化和反序列化概念
序列化(Serialization)
将内存中的对象(数据结构)转换为可存储或传输的格式。
常用于把:
- 内存对象 → 字节流 / 字符串 / 文件 / 网络报文
比如把结构体 Person{name="Tom", age=25} 转换成:
"{"name":"Tom","age":25}"(JSON)0A 03 54 6F 6D 10 19(protobuf 编码)
反序列化:
把序列化后的格式重新转换回内存中的对象。
它是序列化的逆过程,接收到字节流或字符串后重新还原成程序对象
2. 什么情况下需要序列化
场景一:网络通信
- 客户端和服务端要通过网络传输结构化数据;
- 需要把对象编码成"可发送的格式";
- 常用于 API 通信、微服务通信、远程调用(RPC)。
场景二:数据存储
- 对象持久化到磁盘、缓存、数据库等;
- 比如存储用户配置、本地缓存等。
场景三:跨语言/平台通信
- 不同语言之间的数据交互(如 Python ↔ C++);
- 需要通用协议(JSON、protobuf)
3. 常见序列化方法(xml,json,protocolbuffer)
| 序列化格式 | 可读性 | 压缩效率 | 跨语言 | 编码速度 | 使用场景举例 |
|---|---|---|---|---|---|
| JSON | ✅ 高 | ❌ 一般 | ✅ 强 | ✅ 快 | Web API、配置文件 |
| XML | ✅ 高 | ❌ 差 | ✅ 强 | ❌ 慢 | 配置、SOAP协议 |
| protobuf | ❌ 差 | ✅ 高 | ✅ 强 | ✅ 非常快 | 微服务、IoT传输 |
JSON(JavaScript Object Notation)
plain
{"name":"Alice","age":23}- 文本格式,易读易写;
XML(eXtensible Markup Language)
plain
<person><name>Alice</name><age>23</age></person>- 结构清晰,冗余更高;
Protocol Buffers(Google 出品)
plain
message Person {
string name = 1;
int32 age = 2;
}- 编译成高效二进制格式
- 非常适合高性能、低带宽传输场景
- 支持版本升级、字段可选
4. protobuf使用
由 Google 提出的一种语言无关、平台无关、可扩展的结构化数据序列化方法
IDL:接口描述语言'
protobuf协议的工作流程:
(1)编写 .proto 文件(IDL,接口描述语言)
plain
syntax = "proto3";
message Person {
int32 id = 1;
string name = 2;
string email = 3;
}(2)用 protoc 编译器生成语言对应的代码
plain
protoc --cpp_out=. person.proto生成文件包括:
person.pb.h:头文件,包含类声明person.pb.cc:源文件,包含实现
(3)在代码中使用
plain
#include "person.pb.h"
Person p;
p.set_id(123);
p.set_name("Alice");
p.set_email("alice@example.com");
string data;
p.SerializeToString(&data); // 序列化成二进制字符串
Person p2;
p2.ParseFromString(data); // 反序列化回来(4)编译时记得加上 .pb.cc
plain
g++ main.cpp person.pb.cc -lprotobuf -o myprogprotobuf为什么省字节:
1)只传编号,不传字段名
- Protobuf 会将每个字段赋予一个唯一编号(比如
name = 2) - 序列化时不会发送"name",而是发送编号 2 + 内容
- 这比 JSON 里
"name":"Alice"要节省非常多
2)可变长度编码(Varint)
- 小数字用更少字节表示,比如:
int32 id = 1;→ 值为5时只用 1 个字节
- 不像固定长度的
int32总是占 4 字节
3)不传默认值
- 字段没设置时不会被序列化(默认值省略)
- 例如,
string name = ""不会写入输出数据
3. protobuf使用实例以及工程经验
- proto文件命名规则:工程名.模块名.proto
- proto命名空间
- 引用文件
plain
import "auth/user.proto";
message LoginRequest {
auth.User user = 1;
}- 多个平台使用同一份proto文件(独立git去维护这个git文件)
4. protobuf编码原理
- TLV结构
- T(Tag):字段编号 + wire type
- L(Length):字段长度(部分类型,如 string, bytes)
- V(Value):字段值本身
例如:
plain
message Person {
int32 id = 1;
string name = 2;
}会被编码为:
plain
[Tag=8][Varint=id] [Tag=18][Length][String=name]2.为什么要用变长编码
原理(Base128 编码):
- 一个字节只有 7 位存储有效数据,第 8 位(MSB)表示是否还有下一个字节。
- 最后一字节的 MSB 为 0,其他为 1。
| 数值 | 二进制 | Base128 表示(字节流) |
|---|---|---|
| 1 | 00000001 | 0x01 |
| 300 | 100101100 | 0xAC 0x02 |
优点:
- 小整数压缩特别高效(如常见的 id、flag)
- 节省带宽与存储
缺点:
- 编码解析稍复杂(需 bit 操作)
和固定长度编码区别
| 类型 | 描述 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| 可变长度(Varint) | int32、int64、bool 等 | 小数字更节省 | 编解码复杂,性能略差 | id、flag、状态位、枚举等 |
| 固定长度 | fixed32、fixed64 | 编解码快,CPU 缓存友好 | 小数字浪费空间 | 经纬度、时间戳、浮点数、hash值等 |
5. protobuf的数据组织,协议消息升级
- 新增字段
plain
message User {
uint32 id = 1;
string name = 2;
string email = 3; // 新增字段
}- 老版本:直接忽略
email - 新版本:可正常使用
email
- 删除字段的错误方式
plain
message User {
uint32 id = 1;
// 删除 name = 2 (错误❌)
}正确方式是:
plain
message User {
uint32 id = 1;
reserved 2;
reserved "name";
}- 字段编号变动(大坑)
plain
// 老版本
string nickname = 2;
// 新版本(错误)
string nickname = 4; // ❌ 改了 tag 编号老版本程序会错误地把别的字段解析成 nickname,数据混乱
向前兼容 vs 向后兼容
| 兼容方向 | 定义 | 例子 |
|---|---|---|
| 向前兼容 | 新代码能读取老数据 | 老版本写的 protobuf,新代码能读 |
| 向后兼容 | 老代码能读取新数据(忽略新增字段) | 老版本代码能跑新版消息 |
Protobuf 默认支持 向后兼容,即新增字段自动被老版本忽略
5. 扩充oneof
一种节省空间并简化协议字段表示的方法
- 可以安全添加新字段
plain
message Action {
oneof cmd {
string login = 1;
string logout = 2;
string heartbeat = 3; // ✅ 安全新增
}
}兼容性说明:
- 向后兼容 :老版本程序会忽略
heartbeat - 向前兼容 :新版本能正常解析老版本发出的
login/logout
- 不可删除已有字段
plain
// 错误示范
message Action {
oneof cmd {
string login = 1;
// 删除 logout = 2 ❌
}
}即使客户端不再使用某个字段,也不要删除,应该使用 reserved:
plain
reserved 2;
reserved "logout";6.示例
message.proto
plain
syntax = "proto3";
package demo;
message HelloRequest {
string name = 1;
}
message HelloReply {
string message = 1;
}main.cpp
plain
#include <iostream>
#include "message.pb.h"
int main() {
demo::HelloRequest req;
req.set_name("HIT");
demo::HelloReply rep;
rep.set_message("Hello " + req.name());
std::cout << rep.message() << std::endl;
return 0;
}CMakeLists.txt
plain
cmake_minimum_required(VERSION 3.10)
project(protobuf_demo)
#寻找系统中安装的 Protobuf 库
find_package(Protobuf REQUIRED)
# 编译 .proto 文件为 .pb.h 和 .pb.cc
protobuf_generate_cpp(PROTO_SRCS PROTO_HDRS message.proto)
#创建一个可执行程序 main,它会编译 main.cpp 和刚才生成的 .pb.cc 文件
add_executable(main main.cpp ${PROTO_SRCS} ${PROTO_HDRS})
#把 protobuf 的库链接进可执行程序中,比如 libprotobuf.a 或 libprotobuf.so
target_link_libraries(main PRIVATE ${Protobuf_LIBRARIES})
指定 .pb.h 的头文件路径,告诉编译器去哪里找
target_include_directories(main PRIVATE ${Protobuf_INCLUDE_DIRS})- 编译步骤
plain
mkdir build
cd build
cmake ..
make
./main
# 输出:Hello HIT