参考
Redis/Redis Stack/Redis Enterprise
Redis应该是除了MySQL最为熟知的数据库了,其高性能、丰富的数据结构和灵活的扩展性而被广泛使用。随着其应用场景的复杂化和企业需求的多样化,Redis 的生态也在不断扩展。
Redis
基本概念与核心特性
Redis(Remote Dictionary Server)是一个开源的内存键值存储系统,支持多种数据结构(字符串、哈希、列表、集合、有序集合等),并通过内存存储实现毫秒级甚至亚毫秒级的读写速度。其核心优势包括:
- 高性能:基于内存存储,单线程模型配合事件驱动和非阻塞 I/O,支持每秒数十万次读写操作。
- 丰富的数据结构:提供灵活的数据模型,满足计数器、排行榜、队列、会话缓存等多样化需求。
- 持久化支持:通过 RDB 快照和 AOF 日志实现数据持久化,防止数据丢失。
- 分布式能力:支持集群模式(Redis Cluster)和主从复制,实现横向扩展和高可用性。
2. 常见应用场景
- 缓存:作为数据库的缓存层,降低后端压力(如 MySQL、MongoDB)。
- 实时分析:利用内存计算快速处理实时数据(如用户行为统计、排行榜)。
- 消息队列:通过列表(List)实现高效的消息发布与订阅。
- 分布式锁:在分布式系统中实现互斥操作(如秒杀、分布式任务调度)。

这是大家都熟知的内容,但是提到Redis Stack不知道是否都有所了解
Redis Stack
Redis Stack 是 Redis 的官方扩展套件,通过添加现代数据模型和处理引擎,进一步扩展了 Redis 的功能,使其能够应对更复杂的实时应用需求。
核心组件与功能
Redis Stack 包含以下核心模块:
- RedisSearch:支持全文搜索、多字段查询和复杂索引,可直接在 JSON 或哈希数据中执行 SQL 类查询。
- RedisJSON:提供对 JSON 数据的原生支持,支持嵌套对象和数组操作。
- RedisGraph:基于图数据库技术,支持复杂关系查询(如社交网络、推荐系统)。
- RedisTimeSeries:高效存储和查询时间序列数据(如 IoT 设备数据、监控指标)。
- RedisBloom:用于概率数据结构(如布隆过滤器、TopK 算法),优化空间和计算效率。
技术优势与适用场景
- 实时分析与搜索:适用于需要复杂查询的场景,如电商商品搜索、日志分析、实时推荐系统。
- 多模型支持:结合键值、JSON、图等多种数据模型,满足混合数据存储需求。
- 开发效率提升:通过 RedisInsight 管理工具实现可视化监控和调试。
示例场景:电商商品搜索
假设一个电商平台需要支持商品的多条件搜索(如价格、品牌、评分),传统 Redis 可能需要复杂的索引管理,而 Redis Stack 的 RedisSearch 模块可直接通过 SQL-like 语句实现:
sql
FT.SEARCH myIndex "@price:[100 500] @category:electronics" Redis Enterprise
Redis Enterprise 是 Redis 的商业版本,由 Redis Labs 提供支持,专注于大规模生产环境中的高可用性、扩展性和成本优化。
核心功能与技术亮点
- 自动分层(Auto-Sharding) :
自动将数据分片分布到多个节点,支持无缝水平扩展,适用于 TB 级数据集。 - 持久化与容灾 :
支持跨数据中心的多主复制(Multi-Master Replication),确保数据零丢失和高可用性。 - 自动分层存储(Redis Enterprise Automatic Tiering) :
结合 DRAM(内存)和 SSD(固态硬盘),将热数据保留在内存中,冷数据自动迁移到 SSD,降低存储成本。例如:- 吞吐量提升 100%,延迟降低 50%(与纯内存部署相比)。
- 成本节省高达 70%(通过减少 DRAM 使用)。
- 缓存预取(Cache Prefetching) :
利用 CDC(Change Data Capture)技术,将数据库的更新自动复制到 Redis 缓存,减少缓存穿透和延迟。
企业级应用场景
- 大规模缓存:支持高并发场景(如电商秒杀、社交媒体动态流)。
- 混合负载优化:同时处理读密集型和写密集型工作负载。
- 多云与混合云部署:支持跨云或本地部署,确保数据一致性。
示例场景:用户配置文件缓存
某社交平台的用户配置文件频繁读取但很少更新,传统缓存可能因频繁读取导致数据库压力。Redis Enterprise 的缓存预取功能可自动将数据从数据库同步到 Redis,减少 90% 的数据库查询,同时利用自动分层技术将冷数据存储在 SSD,降低成本。

这些模版文档都能在官网找到,下面介绍一下TimeSeries模块。
TimeSeries
介绍
官网TimeSeries模块文档:redis.io/docs/latest...
官网Timeseries模块api文档:redis.io/docs/latest...
官网支持TimeSeries模块的客户端:redis.io/docs/latest...
官网jedis:redis.io/docs/latest...
DockerHub redis-stack:hub.docker.com/r/redis/red...
yaml
services:
redis-stack:
image: redis/redis-stack:latest
container_name: redis-stack
volumes:
- redisdata:/data
ports:
- "6379:6379"
- "8001:8001"
environment:
REDIS_ARGS: "--requirepass ${redis_password}"
TZ: Asia/Shanghai
networks:
- custom_network
volumes:
redisdata:
driver: local
networks:
custom_network:
driver: bridge首先一般的社区版是没有TimeSeries模块的,可以自己在社区版的基础上增加,当然简单的方式是安装redis-stack,这样的redis是带上了redissearch、redistimeseries、redisjson等等模块的,而且还会带上redis insight,也就是docker-compose里配置的除6379外8001端口对应的进程。

先学习几个api
plain
创建时间序列
TS.CREATE key
[RETENTION retentionPeriod]
[ENCODING <COMPRESSED|UNCOMPRESSED>]
[CHUNK_SIZE size]
[DUPLICATE_POLICY policy]
[IGNORE ignoreMaxTimediff ignoreMaxValDiff]
[LABELS [label value ...]]
时间序列新增
TS.ADD key timestamp value
[RETENTION retentionPeriod]
[ENCODING <COMPRESSED|UNCOMPRESSED>]
[CHUNK_SIZE size]
[DUPLICATE_POLICY policy]
[ON_DUPLICATE policy_ovr]
[IGNORE ignoreMaxTimediff ignoreMaxValDiff]
[LABELS [label value ...]]统计计算方法
plain
时间序列范围统计
TS.RANGE key fromTimestamp toTimestamp
[LATEST]
[FILTER_BY_TS ts...]
[FILTER_BY_VALUE min max]
[COUNT count]
[[ALIGN align] AGGREGATION aggregator bucketDuration [BUCKETTIMESTAMP bt] [EMPTY]]聚合计算支持如下max、min、avg、count等等
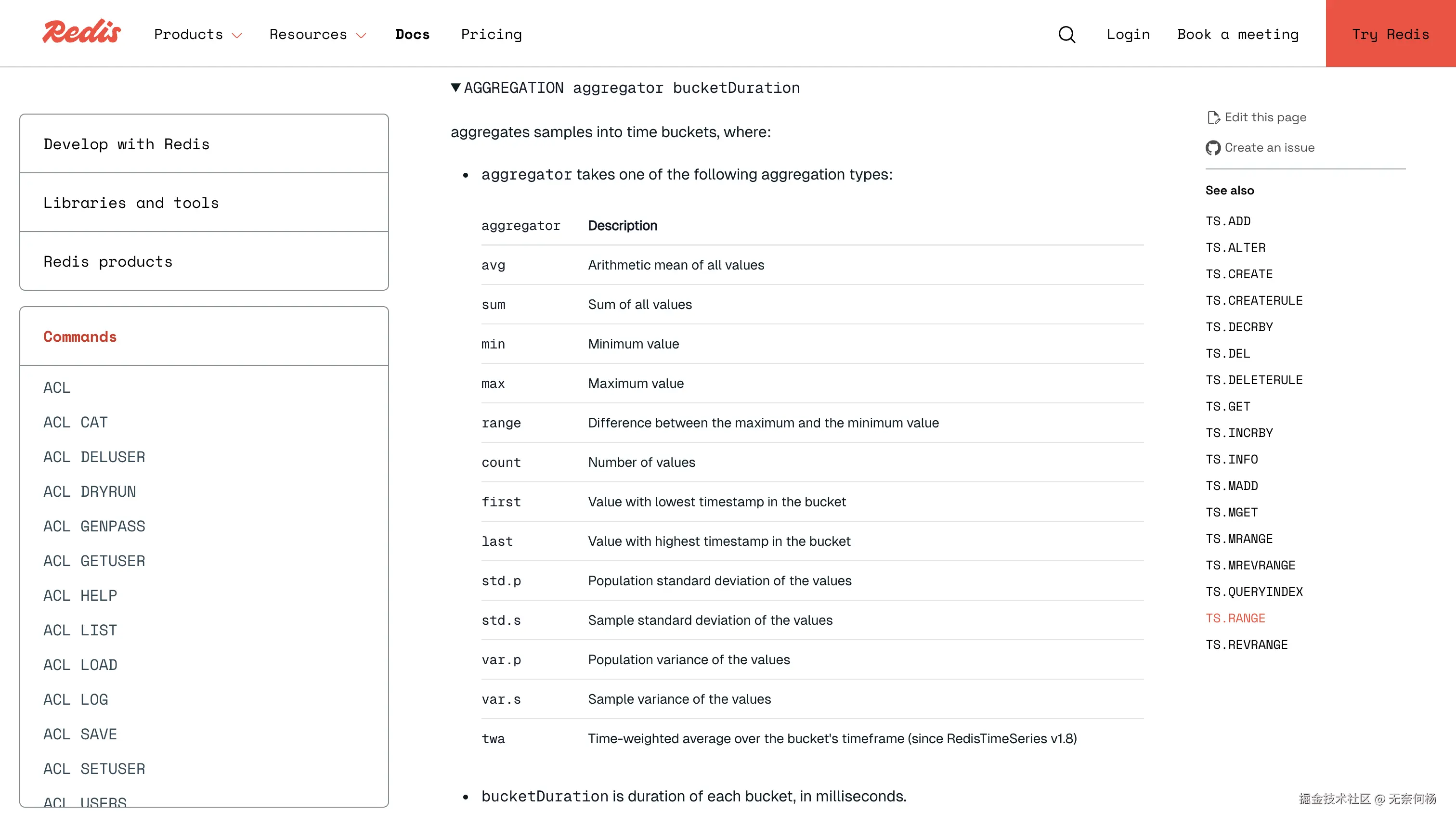
创建规则主要用于设置时间序列之间的聚合规则。通过此命令,可以将源时间序列(source key)中的数据按照指定的时间间隔(bucket size)进行聚合,并将结果存储到目标时间序列(dest key)中
plain
创建规则
TS.CREATERULE sourceKey destKey
AGGREGATION aggregator bucketDuration
[alignTimestamp]
条件查询
TS.QUERYINDEX filterExpr...例子
以下是一个物联网(IoT)设备温度监控与自动告警的详细示例
场景描述
某工厂部署了100个温度传感器(ID: sensor-001 到 sensor-100),每 5秒 采集一次设备温度。需实现:
- 实时存储所有传感器的温度数据(保留30天)。
- 每5分钟统计每个传感器的平均温度、最高温度。
- 当某个传感器温度 连续3次采集超过50℃ 时,触发告警并关闭设备。
- 支持按 时间段 或 传感器ID 查询历史温度趋势。
步骤实现
1、创建时间序列
为每个传感器创建两个时间序列:
- 原始数据序列(保留30天,启用压缩节省空间)
- 降采样后的聚合序列(每5分钟计算一次平均值和最大值)
bash
# 创建传感器001的原始数据序列(标签标明设备ID和类型)
TS.CREATE sensor:001:raw LABELS device_id 001 type temperature RETENTION 2592000000 COMPRESSED
# 创建传感器001的5分钟聚合序列(自动计算平均值)
TS.CREATE sensor:001:avg LABELS device_id 001 type aggregated
TS.CREATERULE sensor:001:raw sensor:001:avg AGGREGATION avg 300000 # 300000ms=5分钟
# 创建传感器001的5分钟最大值序列
TS.CREATE sensor:001:max LABELS device_id 001 type aggregated
TS.CREATERULE sensor:001:raw sensor:001:max AGGREGATION max 300000- RETENTION:30天后自动删除旧数据,避免存储膨胀。
- COMPRESSED:压缩存储高频原始数据,减少内存占用。
- CREATERULE + AGGREGATION:自动降采样计算,避免后期全量扫描。
2、插入实时数据
模拟传感器001每5秒上报一次温度(假设时间戳为手动递增):
bash
# 时间戳 1620000000000(假设为2021-05-03 00:00:00)
TS.ADD sensor:001:raw 1620000000000 45.3
TS.ADD sensor:001:raw 1620000005000 48.1 # +5秒
TS.ADD sensor:001:raw 1620000010000 51.2 # 触发告警的第三次数据- 直接按时间戳插入,支持高频写入(每秒百万级数据点)。
3、触发告警规则
当传感器001连续3次温度超过50℃时,触发告警:
bash
# 创建告警规则(基于原始数据序列)
TS.CREATERULE sensor:001:raw ALERT WHEN max > 50 FOR 3 EXEC "关闭设备001; 发送邮件告警"- WHEN + FOR:连续满足条件时触发动作,避免瞬时波动误报。
- EXEC:可调用外部脚本或Redis Pub/Sub通知运维系统。
4、 查询与分析数据
查询1 :获取传感器001在2023-05-03 00:00至00:15的 原始温度数据:
bash
TS.RANGE sensor:001:raw 1620000000000 1620000090000
# 返回:[ [1620000000000,45.3], [1620000005000,48.1], [1620000010000,51.2] ]查询2 :统计传感器001在当天 每小时的平均温度:
bash
TS.RANGE sensor:001:avg - + AGGREGATION avg 3600000
# 返回每小时的均值,如:[ [1620000000000, 47.5], [1620036000000, 49.1] ]查询3 :找出所有设备在当天 最高温度超过50℃的传感器:
bash
TS.QUERYINDEX type=temperature
FILTER "max(value) > 50"
RANGE 1620000000000 1620086400000
# 返回满足条件的传感器ID列表(如sensor:001:max)- TS.RANGE:毫秒级响应时间,支持灵活时间窗口。
- TS.QUERYINDEX:通过标签快速定位异常设备,无需全表扫描。
核心优势总结
- 高性能:每秒百万级数据写入,毫秒级查询响应。
- 高效存储:压缩 + 保留策略,节省90%内存(对比普通Redis Sorted Sets)。
- 实时计算 :内置聚合规则,直接支持
sum、count、max、avg等聚合操作,避免后期批处理(如对比Hadoop/Spark方案)。 - 数据生命周期 :通过
RETENTION自动清理旧数据,节省存储空间。 - 多维分析 :结合
LABELS实现多维筛选(如按服务器ID或指标类型过滤)。
小结
如今面对同样的问题总是有多种多样的解决方案,虽然那句话听起来有点虚"适合的就是最好的",但是确实是真理。