感谢西农听雨同学对本文提供的大力支持!
一、引言
非度量多维尺度分析(NMDS)是一种用来简化复杂数据的工具,特别适合处理那些难以直接理解的高维数据(微生物群落数据)。它的主要目的是把数据"压缩"到更低的维度(降维操作),比如二维或三维,这样我们就能更容易地用图形来展示和理解数据之间的关系。
NMDS的核心思想是,它不直接使用原始数据,而是基于数据点之间的相似性或距离矩阵。通过一系列的迭代计算,它试图在低维空间中重新排列这些点,使得它们之间的相对距离尽可能接近原始高维空间中的距离。这样一来,即使数据被简化了,我们仍然能大致看出它们之间的相似性或差异性。
这种方法在生态学、生物统计学和社会科学等领域特别有用,它能帮助研究人员直观地展示复杂的模式或关系。简单来说,NMDS就是帮你把复杂的数据"画"出来,让你一眼就能看出其中的规律。
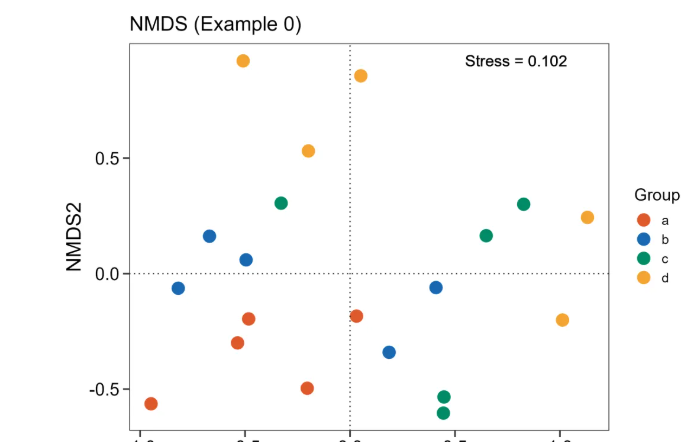
1.1 本代码绘图结果
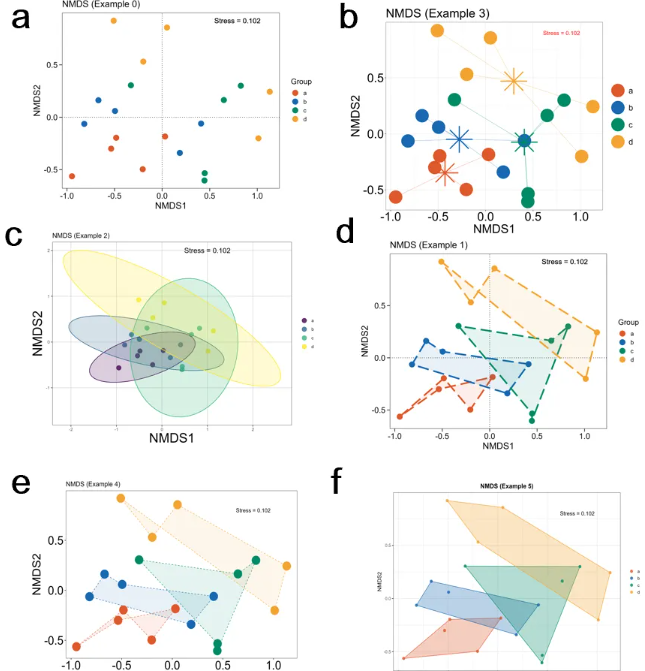
图源:本R代码输出图
1.2 NMDS计算原理
NMDS是一种非度量方法,可作为主坐标分析(PCoA)的替代方案。它能够使用任意样本间的相异性测度,核心目标是将样本投射到低维排序空间(通常为二维或三维),使其欧几里得距离尽可能匹配原始相异性指数所表示的相异程度。之所以称为"非度量",是因为 NMDS 不直接使用原始的相异性数值,而是将其转换为秩次(ranks),并在计算过程中基于这些秩次进行优化。
该算法采用迭代方式,首先从初始样本分布开始,在排序空间中不断调整样本位置,以寻找最优的最终分布。由于其迭代特性,每次运行可能会得到不同的解决方案。
1.3 算法流程简述:
****1.指定维度数 m:设定目标维度m,即希望将样本的高维分布降维至 m 维,这也是"尺度缩放(scaling)"的本质。
****2.构建初始样本配置:在m 维空间中生成所有样本的初始位置,作为迭代优化的起点。这个初始配置至关重要,因为它可能影响最终结果。初始配置可以随机生成,但更优的方法是利用其他排序方式(例如基于相同相异性矩阵的 PCoA 结果)提供更合理的起始位置。
3.迭代优化样本位置:在设定的维度数内,不断调整样本的位置,使排序空间中的真实(欧几里得)距离尽可能匹配样本间的相异性指数。拟合程度由"应力值(stress value)"衡量,应力值越低,拟合效果越好。
4.终止条件:当新的迭代无法进一步降低应力值时,算法停止,最终解确定。
5.旋转最终解:由于 NMDS 本身不会直接生成排序轴(ordination axes),算法完成后通常会通过主成分分析(PCA)对最终解进行旋转,以便更容易解释数据。这也是最终排序图仍然带有排序轴的原因。
6.添加物种得分:与 PCoA 类似,NMDS 结果本身不包含物种得分(species scores),这些得分需要在最终样本配置的基础上通过加权平均法(weighted averaging)添加。
二、示例数据和R代码
2.1 准备数据
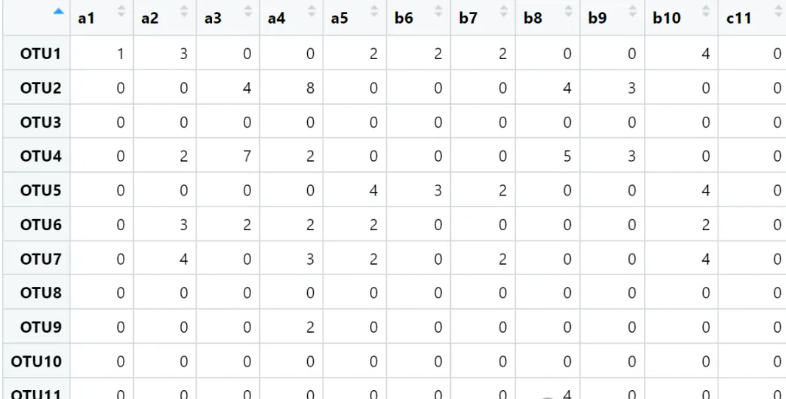
otus.txt,物种丰度表,该表格是模拟的数据,不具备实际意义!
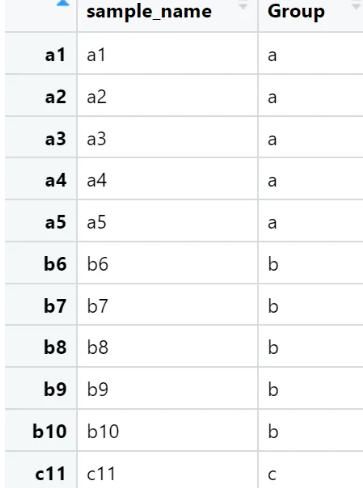
group.txt,分组信息表,用于后续样本绘制等,也不具备实际意义
⚠️根据自己的数据进行整理后绘图,有问题可以留言获取帮助
2.2 R代码
⚠️ 该代码适用于上述数据,要完成自己的任务适当调整!
这段 R 代码首先清理环境并加载必要的 R 包(如 ggplot2、vegan、tidyverse 等),然后读取 OTU 表 (otus.txt) 和分组信息 (group.txt)。接着,对数据进行稀释(Rarefaction),确保所有样本测序深度一致,并计算 Bray-Curtis 距离矩阵,以衡量样本间的相似性。随后,使用 PERMANOVA(置换多元方差分析) 检测不同实验组之间的微生物群落组成是否存在显著差异。之后,利用 NMDS(非度量多维尺度分析) 对距离矩阵进行降维,并计算应力值 (stress),判断拟合优度。最后,代码生成多种 NMDS 可视化图(如基本散点图、多边形包络、椭圆包络、凸包等),并保存为 PDF 文件,以展示群落结构的差异性。
2.2.1R包加载并导入数据
R
############清理环境############
rm(list=ls())
##########加载必要的包##############
library(ggplot2)
library(ggrepel) # 用于更好地显示文本标签,防止标签重叠
library(ggthemes) # 提供更多主题
library(viridis) # 连续或离散调色板
library(ggforce) # 有一些特殊几何体函数,比如 geom_mark_ellipse
library(tidyverse)
library(vegan)
###############读取OTU表和分组表#################
bac_asv <- read.delim("otus.txt", row.names = 1, sep = '\t', header = T)
bac_group <- read.delim("group.txt",row.names = 1 , sep = '\t' , header = T)2.3 数据整理
R
# ###############对样本进行抽平#################
set.seed(125)
bac_asv_rari <- as.data.frame(t(rrarefy(t(bac_asv),min(colSums(bac_asv))))) %>% # 先计算每一列(即每个样本)的序列总和,并找出最小的总和。rrarefy() 函数对 "转置后" 的矩阵进行稀有化处理,使得每个样本(现在是每一行)的序列计数等于最小的样本序列总和,然后再转回原来的行列关系。
filter(.,rowSums(.)>0) # 筛选出每个asv(相当于行的总数)大于0的
colSums(bac_asv_rari)
bac_asv_rari
###################计算距离矩阵##################
##> 计算bray_curtis距离:NMDS分析或PCoA分析
bac_distance <- bac_asv_rari %>%
t() %>% # 行名是样本
vegdist(method = 'bray') # Bray-Curtis 距离是一genus度量两个样本在物genus组成上差异的方法
bac_data <- bac_asv_rari %>%
t() %>%
as.data.frame() %>%
rownames_to_column(var = 'sample_name') %>%
left_join(.,bac_group,by = 'sample_name')
#PERMANOVA是一种非参数检验方法,用于评估不同组别间的差异是否具有统计学意义。
#与后续绘图没有直接关联,可不运行
# 置换多元方差分析(PERMANOVA):不符合正态分布
PERMANOVA_bac <- adonis2(bac_distance ~ Group ,
data = bac_data , permutations = 999)
PERMANOVA_bac
#######NMDS用于可视化样本间的相似性或差异性,但它本身无法判断差异是否显著。
###> NMDS分析:应力值小于0.2被认为是一个很好的拟合
set.seed(156)
# #NMDS排序,定义2个维度,详情?metaMDS
bac_NMDS <- metaMDS(bac_distance, k = 2)
# 应力函数值,一般不大于 0.2 为合理
bac_NMDS$stress
bac_NMDS_points <- as.data.frame(bac_NMDS$points) %>%
rownames_to_column(var = 'sample_name') %>%
left_join(.,bac_group,by='sample_name')2.3.1绘图模板1
R
# Draw Plot
# 获取世界地图数据
# https://rdrr.io/cran/maps/man/world.html
world <- map_data("world")
p1 <- ggplot() +
geom_polygon(
data = world,
aes(x = long, y = lat, group = group),
color = "grey20", fill = "#FCF8E5", linewidth = 0.2
) +
theme(panel.background = element_rect(fill = "#A0C7E3", colour = "white"))+
ylim(c(-55, 83)) +
coord_quickmap()
p1
p2 <- p1 +
geom_scatterpie(
data = data,
aes(x = Longitude, y = Latitude, r = log10(Size + 1)*2),
cols = colnames(data[, 4:15]),
color = "black", linewidth = 0.3
) +
scale_fill_manual(values = colors) +
geom_scatterpie_legend(r = log10(data$Size + 1)*2, x = -150, y = -30, labeller = function(x) (10^(x/2)), size = 2, n = 4) +
theme(
legend.text = element_text(size = 6, colour = 'grey20'),
legend.key.size = unit(0.3,'cm'),
legend.key.spacing.y = unit(0, 'cm'),
legend.title = element_blank(),
legend.position = "bottom",
panel.grid = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank()
)
p2
ggsave("map.png",height=6,width=12,dpi=300)
ggsave("map.pdf",height=6,width=12,dpi=300)输出结果
2.3.2 绘图模板2
R
#####################绘图模板2##################
bac_NMDS_p1 <- bac_NMDS_p +
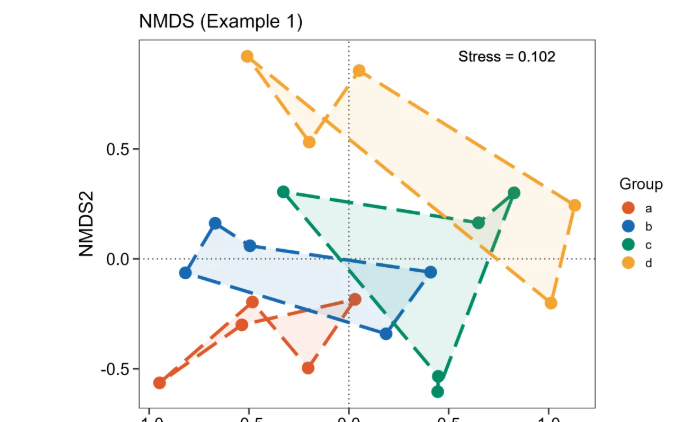
geom_polygon(aes(x = MDS1, y = MDS2, fill = Group, group = Group, color = Group),alpha = 0.1, linetype = "longdash", linewidth = 1.5 ,show.legend = FALSE)+
labs(title = "NMDS (Example 1)",
x = "NMDS1",
y = "NMDS2")
bac_NMDS_p1
ggsave(plot = bac_NMDS_p1,filename = "NMDS1.pdf",dpi = 300,width = 8,height = 6)
ggsave(plot = bac_NMDS_p1,filename = "NMDS1.png",dpi = 300,width = 8,height = 6)输出结果
2.3.3 绘图模板3
R
########################绘图模板3##########################
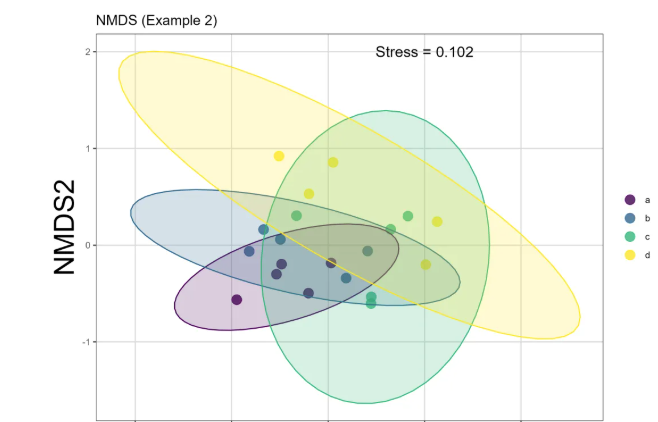
bac_NMDS_p2 <- ggplot(bac_NMDS_points, aes(x = MDS1, y = MDS2, color = Group)) +
geom_point(size = 4, alpha = 0.8) +
# 椭圆包络
stat_ellipse(aes(fill = Group),
geom = "polygon",
alpha = 0.2,
show.legend = FALSE) +
# 在图中加上 stress 值
annotate("text",
x = 1,
y = 2,
label = paste0("Stress = ", round(bac_NMDS$stress, 3)),
size = 5) +
# 手动设置颜色和填充,也可用 scale_color_manual
scale_color_viridis(discrete = TRUE, option = "D") +
scale_fill_viridis(discrete = TRUE, option = "D") +
theme_bw() +
theme(
panel.grid.major = element_line(color = "grey85"),
panel.grid.minor = element_blank(),
legend.position = "right",
axis.title.y = element_text(size = 26,color="black"),
axis.title.x = element_text(size = 26,color="black"),
legend.title = element_blank()
) +
labs(title = "NMDS (Example 2)",
x = "NMDS1",
y = "NMDS2")
bac_NMDS_p2
ggsave(plot = bac_NMDS_p2,filename = "NMDS2.pdf",dpi = 300,width = 8,height = 6)
ggsave(plot = bac_NMDS_p2,filename = "NMDS2.png",dpi = 300,width = 8,height = 6)输出结果
2.3.4 绘图模板4
R
############################模板4############################
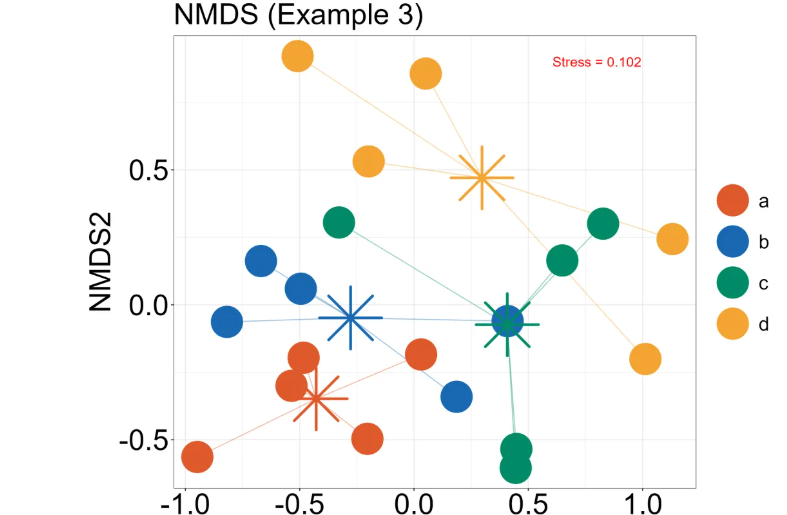
# 计算各组的中心(这里用平均值)
centroids <- bac_NMDS_points %>%
group_by(Group) %>%
summarise(MDS1 = mean(MDS1), MDS2 = mean(MDS2))
bac_NMDS_p3 <- ggplot(bac_NMDS_points, aes(x = MDS1, y = MDS2, color = Group)) +
# 绘制星形连接线:每个点 -> 对应分组的中心
geom_segment(
data = bac_NMDS_points %>% left_join(centroids, by="Group", suffix = c("", "_centroid")),
aes(xend = MDS1_centroid, yend = MDS2_centroid),
alpha = 0.4
) +
geom_point(size = 15) +
# 绘制分组中心点
geom_point(data = centroids,
aes(x = MDS1, y = MDS2, color = Group),
size = 20, shape = 8, stroke = 2,show.legend = F) +
# 标注 stress
annotate("text",
x = 0.8,
y = 0.9,
label = paste0("Stress = ", round(bac_NMDS$stress, 3)),
size = 5, color = "red") +
scale_color_manual(values = c("#DE582B","#1868B2","#018A67","#F3A332"))+
# ggdark::dark_theme_bw(base_size = 14) + # 来自 ggdark
theme_bw()+
theme(
legend.position = "right",
legend.title = element_blank(),
axis.text = element_text(size = 30,color="black"),
axis.title = element_text(size = 30,color="black"),
legend.text = element_text(size = 20),
plot.title = element_text(size = 30)
) +
labs(title = "NMDS (Example 3)",
x = "NMDS1",
y = "NMDS2")
bac_NMDS_p3
ggsave(plot = bac_NMDS_p3,filename = "NMDS3.pdf",dpi = 300,width = 10,height = 8)
ggsave(plot = bac_NMDS_p3,filename = "NMDS3.png",dpi = 300,width = 10,height = 8)输出结果
2.3.5 绘图模板5
R
###########################模板5###############################
bac_NMDS_p4 <- ggplot(bac_NMDS_points, aes(x = MDS1, y = MDS2)) +
# 多边形包络
geom_polygon(aes(color = Group, fill = Group),
alpha = 0.1,
show.legend = FALSE,
linetype = "dashed") +
# 散点
geom_point(aes(color = Group), size = 10) +
# repel 标签,避免重叠
# geom_text_repel(aes(label = sample_name, color = Group),
# size = 3.5,
# box.padding = 0.3,
# max.overlaps = 10) +
# 加入 stress
annotate("text",
x = 0.8,
y = 0.8,
label = paste0("Stress = ", round(bac_NMDS$stress, 3)),
size = 5,color = "black") +
scale_color_manual(values = c("#DE582B","#1868B2","#018A67","#F3A332")) +
scale_fill_manual(values = c("#DE582B","#1868B2","#018A67","#F3A332")) +
labs(x = "NMDS1", y = "NMDS2", title = "NMDS (Example 4)") +
theme_bw(base_size = 14) +
theme(
legend.position = "bottom",
legend.title = element_blank(),
panel.grid = element_blank(),
axis.text = element_text(size = 30,color="black"),
axis.title = element_text(size = 30,color="black"),
legend.text = element_text(size = 20)
)
bac_NMDS_p4
ggsave(plot = bac_NMDS_p4,filename = "NMDS4.pdf",dpi = 300,width = 10,height = 8)
ggsave(plot = bac_NMDS_p4,filename = "NMDS4.png",dpi = 300,width = 10,height = 8)输出结果
2.3.6 绘图模板6
R
##########################模板6##############################
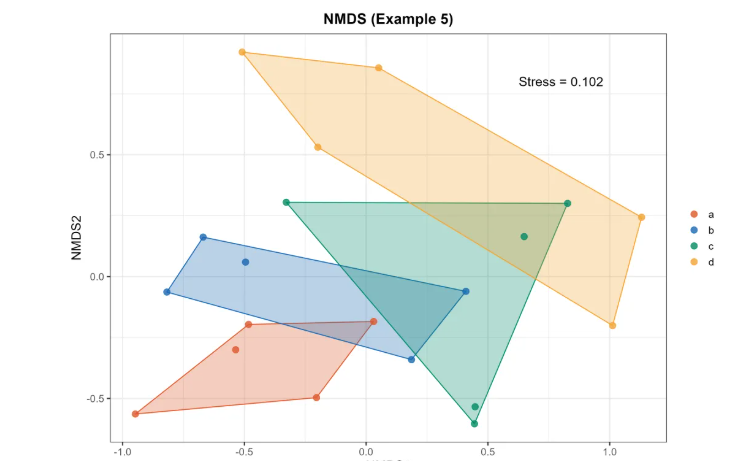
# 1. 计算每个分组的凸包:chull() 函数可以得到"围住"散点的最小多边形
hull_data <- bac_NMDS_points %>%
group_by(Group) %>%
slice(chull(MDS1, MDS2)) # 对每组数据分别计算凸包的索引,再取子集
# 2. 绘图
bac_NMDS_p5 <- ggplot(bac_NMDS_points, aes(x = MDS1, y = MDS2, color = Group)) +
# 填充凸包区域
geom_polygon(data = hull_data,
aes(fill = Group),
alpha = 0.3,
# color = "red",
show.legend = FALSE) +
# 绘制散点
geom_point(size = 3, alpha = 0.8) +
# 在图中加上 Stress 值
annotate("text",
x = 0.8,
y = 0.8,
label = paste0("Stress = ", round(bac_NMDS$stress, 3)),
size = 5,color = "black") +
scale_color_manual(values = c("#DE582B","#1868B2","#018A67","#F3A332"))+
scale_fill_manual(values = c("#DE582B","#1868B2","#018A67","#F3A332"))+
coord_fixed() + # X轴与Y轴1:1缩放
labs(title = "NMDS (Example 5)",
x = "NMDS1",
y = "NMDS2") +
theme_bw(base_size = 14) +
theme(
legend.position = "right",
legend.title = element_blank(),
plot.title = element_text(hjust = 0.5, face = "bold", size = 16)
)
bac_NMDS_p5
ggsave(plot = bac_NMDS_p5,filename = "NMDS5.pdf",dpi = 300,width = 10,height = 8)
ggsave(plot = bac_NMDS_p5,filename = "NMDS5.png",dpi = 300,width = 10,height = 8)输出结果
四、相关信息
!!!本文内容由小编总结互联网和文献内容总结整理,如若侵权,联系立即删除!
!!!有需要的小伙伴评论区获取今天的测试代码和实例数据。
📌示例代码中提供了数据和代码,小编已经测试,可直接运行。
以上就是本节所有内容。
如果这篇文章对您有用,请帮忙一键三连(点赞、收藏、评论、分享),让该文章帮助到更多的小伙伴。