- 序言:什么是 MNIST?
- MNIST 数据集简介
- 如何配置 MNIST 示例
- 搭建一个简单的神经网络
- 开始训练你的模型
- 如何评估训练结果
- 总结:你已经走出了第一步!
1. 序言:什么是 MNIST?
如果你刚刚接触深度学习,或者正准备踏入这片神奇的领域,那么你肯定听过 MNIST 数据集。这是深度学习的"入门级"经典教程,就像"Hello World"一样,是你理解机器学习和神经网络如何工作的起点。
MNIST(Modified National Institute of Standards and Technology)是一个包含手写数字的数据集,里面有上万张数字图片,每张图片都标注了对应的数字标签(0到9)。这个数据集对我们来说,几乎可以算作一个"练手项目"。我们会用它来训练一个神经网络,让它学会识别这些手写数字。
在本篇文章里,我将带你一步步走过如何使用 DeepLearning4J(一个基于 Java 的深度学习框架)来处理 MNIST 数据集,训练一个神经网络,最后测试它的准确度。
2. MNIST 数据集简介
主要功能
- MNIST 包含 60,000 张手写数字训练图像和 10,000 张测试图像。
- 数据集由大小为 28x28 像素的灰度图像组成。
- 对图像进行归一化处理,使其适合 28x28 像素的边界框,并进行抗锯齿处理,引入灰度级。
- MNIST 广泛用于机器学习领域的训练和测试,尤其是图像分类任务。
数据集结构
MNIST 数据集分为两个子集:
- 训练集:该子集包含 60,000 张手写数字图像,用于训练机器学习模型。
- 测试集:该子集由 10,000 张图像组成,用于测试和基准测试训练有素的模型。
每张图片的尺寸是 28x28 像素,也就是 784 个数据点(28 * 28)。这些图片是灰度图,不包含颜色信息,每个像素的亮度值从 0(黑)到 255(白)。我们的任务就是训练一个模型,让它学会从这些 28x28 的图片中识别出数字。
3. 如何配置 MNIST 示例
好啦,接下来我们需要设置一下环境。首先,确保你已经安装了 DeepLearning4J 和相关的依赖库。这里不需要你从零开始配置,只需要下载并配置好一个现成的代码示例。
假设你已经有 IntelliJ IDEA 作为开发工具(如果没有的话,可以参考官网教程来安装)。打开 IntelliJ,找到 dl4j-examples 文件夹,进入 src\main\java\org\deeplearning4j\examples\quickstart\modeling\feedforward\classification 目录,打开文件 MNISTSingleLayer.java。这是我们要用的示例文件。

4. 搭建一个简单的神经网络
好了,接下来是最有趣的一部分------搭建神经网络。我们将用一个非常基础的 前馈神经网络(Feedforward Neural Network)。简单来说,前馈神经网络就是将数据一层一层地传递,直到最后给出一个预测结果。请将下图牢记心中,这就是我们将要搭建的单层神经网络。
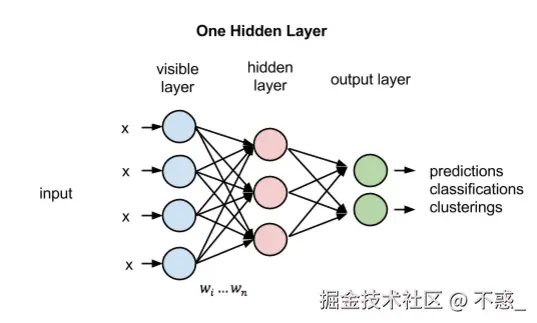
输入参数和设置
这部分代码定义了神经网络的基本配置,包括图片的大小、输出类别数、批次大小、随机种子和训练的轮次。MNIST 数据集的每张图片大小是 28x28 ,每次训练使用 128 张图片,并且训练总共进行 15 次。
javascript
final int numRows = 28; // 图片的行数,MNIST 图片是 28x28 像素
final int numColumns = 28; // 图片的列数
int outputNum = 10; // 输出的类别数,数字 0 到 9 共 10 类
int batchSize = 128; // 每个批次的样本数,控制每次训练时网络处理的数据量
int rngSeed = 123; // 随机数种子,确保每次训练得到的初始权重一致,便于复现结果
int numEpochs = 15; // 训练的轮次,定义神经网络将遍历数据集的次数获取训练集和测试集数据
这里使用 MnistDataSetIterator 来加载 MNIST 数据集。mnistTrain 用于加载训练数据,mnistTest 用于加载测试数据。每次训练和测试时都会以批次(batch)的形式处理数据,batchSize 就是每次加载的样本数量。
javascript
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, rngSeed);
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, rngSeed);设置超参数
我们的网络就只有两个层:一个 隐藏层 和一个 输出层。隐藏层会接收数据并进行处理,输出层则根据隐藏层的计算结果给出最终的预测。
直观而言,每一项超参数就如同一道菜里的一种食材:取决于食材好坏,火候,调料的多少,这道菜也许非常可口,也可能十分难吃......所幸在深度学习中,如果结果不正确,超参数还可以进行调整。
在 DeepLearning4J 中,配置神经网络的基本代码如下:
java
public static void main(String[] args) throws Exception {
// 定义输入图片的行和列(每张图片的大小为 28x28)
final int numRows = 28;
final int numColumns = 28;
// 输出类别数量(MNIST 数据集包含数字 0 到 9,共 10 类)
int outputNum = 10;
// 每次训练时处理的批量样本数
int batchSize = 128;
// 随机数种子,用于确保结果的可重复性
int rngSeed = 123;
// 训练的总周期数
int numEpochs = 15;
// 获取训练集和测试集的数据迭代器
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, rngSeed);
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, rngSeed);
log.info("构建模型....");
// 配置神经网络的架构
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(rngSeed) // 设置随机种子,确保训练结果可重复
.updater(new Nesterovs(0.006, 0.9)) // 使用 Nesterov 动量优化器,学习率为 0.006,动量为 0.9
.l2(1e-4) // 使用 L2 正则化,防止过拟合
.list() // 开始定义网络的层次
.layer(new DenseLayer.Builder() // 第一层:全连接层(输入层)
.nIn(numRows * numColumns) // 输入层节点数:28x28 的图片展平为 784 个输入节点
.nOut(1000) // 隐藏层节点数:设定为 1000
.activation(Activation.RELU) // 激活函数:ReLU
.weightInit(WeightInit.XAVIER) // 权重初始化方法:Xavier 初始化
.build())
.layer(new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD) // 第二层:输出层
.nIn(1000) // 输入节点数:1000 个隐藏层节点
.nOut(outputNum) // 输出节点数:10 个类别(对应数字 0-9)
.activation(Activation.SOFTMAX) // 激活函数:Softmax,用于多类分类
.weightInit(WeightInit.XAVIER) // 权重初始化方法:Xavier 初始化
.build())
.build(); // 构建模型配置
// 创建神经网络模型
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init(); // 初始化模型
// 设置训练过程中每一轮的得分输出,1 表示每完成 1 次迭代输出一次得分
model.setListeners(new ScoreIterationListener(1));
log.info("开始训练模型....");
// 使用训练数据集训练模型,训练 15 个 epoch(训练周期)
model.fit(mnistTrain, numEpochs);
log.info("评估模型....");
// 使用测试数据集评估训练好的模型
Evaluation eval = model.evaluate(mnistTest);
log.info(eval.stats()); // 输出评估结果,包括准确率、精确率等指标
log.info("****************示例完成********************");
}这段代码定义了一个简单的 前馈神经网络(Feedforward Neural Network)。它包括两层:
- 第一层(输入层 + 隐藏层):该层将输入的 28x28 像素图像展开为 784 维的向量,并通过 ReLU 激活函数进行处理,输出到下一层。
- 第二层(输出层):该层有 10 个神经元,分别对应数字 0 到 9,使用 Softmax 激活函数进行多分类预测。
开始训练你的模型
网络架构搭建完毕后,我们就可以开始训练模型了。训练的过程实际上是通过不断调整神经网络中的权重,来使模型的预测误差逐渐变小。代码如下:这部分代码会让网络在训练集上进行多次学习,每次都会根据误差调整模型中的参数。你可以设置训练周期(epoch)的数量,通常来说,epoch 越多,模型越精确,但训练时间也越长。
在这一行中,模型开始训练,fit 方法会自动将训练数据送入神经网络,并进行前向传播、误差计算和反向传播,从而不断更新网络的权重。
java
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init(); // 初始化模型
// 开始训练
model.fit(mnistTrain, numEpochs); // 训练 15 个周期如何评估训练结果
训练完成后,我们使用测试数据集来评估模型的准确率。evaluate 方法会计算模型在测试集上的性能,包括准确率、精确率、召回率等常见的评价指标。
java
// 使用测试数据集评估训练好的模型
Evaluation eval = model.evaluate(mnistTest);
log.info(eval.stats()); // 输出评估结果,包括准确率、精确率等指标
5. 输出的结果
| 指示符 | 描述 |
|---|---|
| Accuracy | 准确率:模型准确识别出的MNIST图像数量占总数的百分比。 |
| Precision | 精确率:真正例的数量除以真正例与假正例数之和。 |
| Recall | 召回率:真正例的数量除以真正例与假负例数之和。 |
| F1 Score | F1值:精确率和召回率的加权平均值。 |
这些指标将帮助你了解模型是否能够在未见过的数据上做出准确的预测。
xml
# of classes: 10
Accuracy: 0.9723
Precision: 0.9723
Recall: 0.9720
F1 Score: 0.9721
Precision, recall & F1: macro-averaged (equally weighted avg. of 10 classes)
=========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9
---------------------------------------------------
966 0 1 2 0 3 5 1 2 0 | 0 = 0
0 1125 2 1 0 1 3 1 2 0 | 1 = 1
4 3 1004 5 3 1 1 7 4 0 | 2 = 2
0 0 2 992 0 3 0 6 5 2 | 3 = 3
1 0 5 0 960 0 3 2 2 9 | 4 = 4
3 1 0 8 1 863 8 1 5 2 | 5 = 5
5 3 1 0 7 7 932 0 3 0 | 6 = 6
1 10 11 3 1 1 0 992 0 9 | 7 = 7
3 1 2 9 3 6 5 5 938 2 | 8 = 8
4 8 1 13 20 2 1 6 3 951 | 9 = 9
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times评估指标(Evaluation Metrics)
| 评估指标 | 数值 | 解释 |
|---|---|---|
| Accuracy(准确率) | 0.9723 | 表示模型正确预测的样本占所有测试样本的比例,即 97.23% 的样本被正确分类。 |
| Precision(精确率) | 0.9723 | 在所有被模型预测为某一类别的样本中,真正属于该类别的比例。在此,精确率为 97.23%,表示大多数预测为某类别的样本是准确的。 |
| Recall(召回率) | 0.9720 | 在所有实际属于某一类别的样本中,模型能够正确预测为该类别的比例。召回率为 97.20%,说明模型在识别实际属于某类别的样本时表现得很好。 |
| F1 Score | 0.9721 | 精确率与召回率的调和平均数。F1分数为 97.21%,说明模型在这两个方面的表现非常均衡。 |
| Precision, Recall, & F1 | 宏平均(Macro-averaged) | 所有类别的精确率、召回率和 F1 分数的平均值,权重相等。 |
混淆矩阵(Confusion Matrix)
| 实际\预测 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 966 | 0 | 1 | 2 | 0 | 3 | 5 | 1 | 2 | 0 |
| 1 | 0 | 1125 | 2 | 1 | 0 | 1 | 3 | 1 | 2 | 0 |
| 2 | 4 | 3 | 1004 | 5 | 3 | 1 | 1 | 7 | 4 | 0 |
| 3 | 0 | 0 | 2 | 992 | 0 | 3 | 0 | 6 | 5 | 2 |
| 4 | 1 | 0 | 5 | 0 | 960 | 0 | 3 | 2 | 2 | 9 |
| 5 | 3 | 1 | 0 | 8 | 1 | 863 | 8 | 1 | 5 | 2 |
| 6 | 5 | 3 | 1 | 0 | 7 | 7 | 932 | 0 | 3 | 0 |
| 7 | 1 | 10 | 11 | 3 | 1 | 1 | 0 | 992 | 0 | 9 |
| 8 | 3 | 1 | 2 | 9 | 3 | 6 | 5 | 5 | 938 | 2 |
| 9 | 4 | 8 | 1 | 13 | 20 | 2 | 1 | 6 | 3 | 951 |
解读混淆矩阵
混淆矩阵的行表示 实际类别 ,列表示 预测类别,每个数字表示该类别样本被预测为其他类别的次数。接下来逐一分析一下每一行的含义。
| 实际类别\预测类别 | 0 类别预测正确的样本数 | 1 类别预测正确的样本数 | 2 类别预测正确的样本数 | 3 类别预测正确的样本数 | 4 类别预测正确的样本数 | 5 类别预测正确的样本数 | 6 类别预测正确的样本数 | 7 类别预测正确的样本数 | 8 类别预测正确的样本数 | 9 类别预测正确的样本数 |
|---|---|---|---|---|---|---|---|---|---|---|
| 实际 0 | 966 | 0 | 1 | 2 | 0 | 3 | 5 | 1 | 2 | 0 |
| 实际 1 | 0 | 1125 | 2 | 1 | 0 | 1 | 3 | 1 | 2 | 0 |
| 实际 2 | 4 | 3 | 1004 | 5 | 3 | 1 | 1 | 7 | 4 | 0 |
| 实际 3 | 0 | 0 | 2 | 992 | 0 | 3 | 0 | 6 | 5 | 2 |
| 实际 4 | 1 | 0 | 5 | 0 | 960 | 0 | 3 | 2 | 2 | 9 |
| 实际 5 | 3 | 1 | 0 | 8 | 1 | 863 | 8 | 1 | 5 | 2 |
| 实际 6 | 5 | 3 | 1 | 0 | 7 | 7 | 932 | 0 | 3 | 0 |
| 实际 7 | 1 | 10 | 11 | 3 | 1 | 1 | 0 | 992 | 0 | 9 |
| 实际 8 | 3 | 1 | 2 | 9 | 3 | 6 | 5 | 5 | 938 | 2 |
| 实际 9 | 4 | 8 | 1 | 13 | 20 | 2 | 1 | 6 | 3 | 951 |
混淆矩阵中的几个关键点
- 行中的大数字 表示该类别预测得很好。例如,类别 0 (数字 0)的样本大部分被正确预测为 0 ,有 966 个正确预测,错误的预测数量非常少。
- 行中的小数字 表示该类别的误分类情况。例如,类别 5 (数字 5)有 863 个正确预测,但也有误分类为其他类别的情况,如 3 和 8。
一些典型的误分类
- 类别 1 (数字 1)几乎没有误分类,只有少数样本被误分类为其他类别(如 2 和 3)。
- 类别 7 (数字 7)的误分类较为显著,尤其是将 7 预测为 3 和 2,这些是模型较难分辨的数字。
通过表格的方式,可以清晰地看到模型在各个类别上的表现。整体来看,模型的 准确率 和 F1 分数 都很高,接近 97%,表示模型的性能非常好。混淆矩阵中的 大多数样本 都被正确分类,但也有少数类别存在误分类,尤其是一些形状较为相似的数字,如 7 和 3。
如果需要进一步改进模型,可能需要:
- 调整 超参数,如学习率、隐藏层大小等。
- 使用更复杂的网络结构,如 卷积神经网络(CNN),尤其适合处理图像分类问题。
6. 总结:你已经走出了第一步!
恭喜你,经过一系列的步骤,你已经成功地训练出了一个神经网络,并用它来对 MNIST 数据集进行分类!这只是深度学习的开始,你的模型准确率已经接近 97%。这个结果虽然还可以提升,但它已经说明了你掌握了训练神经网络的基本流程。
下一步,你可以做些什么?
- 尝试改进模型:可以调整学习率、隐藏层神经元数量等超参数。
- 使用更复杂的模型:例如,使用卷积神经网络(CNN),它在图像识别方面表现更好。
- 深挖其他数据集:尝试其他机器学习任务,了解更多深度学习的应用场景。
Deeplearning4J 的优势
Deeplearning4J 是一个强大的深度学习框架,支持以下特点:
- 与大数据工具(如 Spark、Hadoop)集成,适合大规模分布式计算。
- 优化了基于 CPU 和 GPU 的训练,提供高效的训练体验。
- 支持 Java 和 Scala 用户,并且有商业化支持。
7. 结语
通过本教程,你已经迈出了深度学习的第一步,学习了如何使用 DeepLearning4J 来训练一个简单的神经网络。随着你继续深入,你会发现神经网络的世界比你想象的要丰富得多。未来,你将学会更多关于如何优化模型、使用更复杂的架构,甚至在真实的应用场景中部署这些模型!
我也是一名刚刚入门深度学习的小学生,欢迎友好指正和交流~