Spark-SQL核心编程
MySQL
Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对
DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。
IDEA通过JDBC对MySQL进行操作:
- 导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
MySQL8 <version>8.0.11</version>
- 读取数据
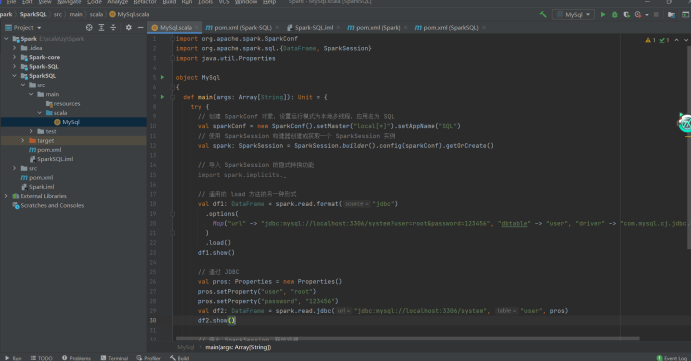
val sparkConf = new SparkConf().setMaster("local\*").setAppName("SQL")
val spark:SparkSession = SparkSession.builder ().config(sparkConf).getOrCreate()
import spark.implicits._
// 通用的 load 方式读取
spark.read.format("jdbc")
.option("url","jdbc:mysql://localhost:3306/system")
.option("driver","com.mysql.jdbc.Driver")//com.mysql.cj.jdbc.Driver
.option("user","root")
.option("password","123456")
.option("dbtable","user")
.load().show()
spark.stop()
// 通用的 load 方法的另一种形式
spark.read.format("jdbc")
.options( Map ("url"->"jdbc:mysql://localhost:3306/system?user=root&password=123456","dbtable"->"user","driver"->"com.mysql.jdbc.Driver"))
.load().show()
// 通过 JDBC
val pros :Properties = new Properties()
pros.setProperty("user","root")
pros.setProperty("password","123456")
val df :DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/system","user",pros)
df.show()
- 写入数据
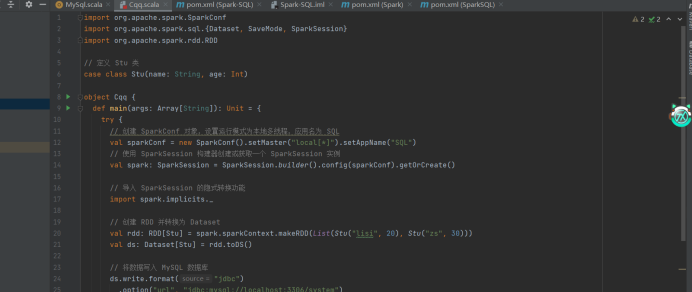
val sparkConf = new SparkConf().setMaster("local\*").setAppName("SQL")
val spark:SparkSession = SparkSession.builder ().config(sparkConf).getOrCreate()
import spark.implicits._
val rdd: RDDStu = spark.sparkContext.makeRDD(List (Stu ("lisi", 20),
Stu ("zs", 30)))
val ds:DatasetStu = rdd.toDS()
ds.write.format("jdbc")
.option("url","jdbc:mysql://localhost:3306/system")
.option("driver","com.mysql.jdbc.Driver")
.option("user","root")
.option("password","123456")
.option("dbtable","user2")
.mode(SaveMode.Append )
.save()
spark.stop()
Spark-SQL连接Hive
1)内嵌的 HIVE
如果使用 Spark 内嵌的 Hive, 则什么都不用做, 直接使用即可。但是在实际生产活动当中,几乎没有人去使用内嵌Hive这一模式。
2)外部的 HIVE
在虚拟机中下载以下配置文件:

如果想在spark-shell中连接外部已经部署好的 Hive,需要通过以下几个步骤:
➢ Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下,并将url中的localhost改为node01
➢ 把 MySQL 的驱动 copy 到 jars/目录下

➢ 把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
➢ 重启 spark-shell
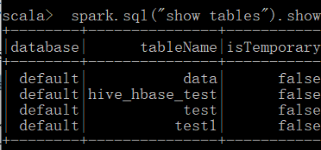
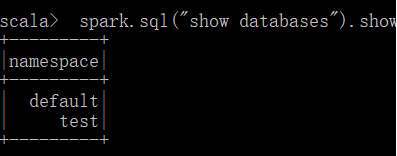
3)运行Spark-SQL CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
操作步骤:
- 将mysql的驱动放入jars/当中;
- 将hive-site.xml文件放入conf/当中;
- 运行bin/目录下的spark-sql.cmd 或者打开cmd,在
D:\spark\spark-3.0.0-bin-hadoop3.2\bin当中直接运行spark-sql
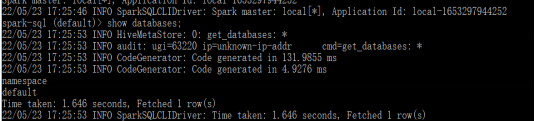
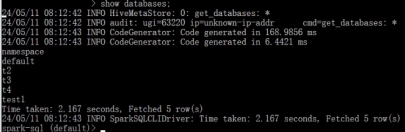
可以直接运行SQL语句,如下所示:
5)代码操作Hive
- 导入依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.3</version>
</dependency>
-
将hive-site.xml 文件拷贝到项目的 resources 目录中。
-
代码实现。
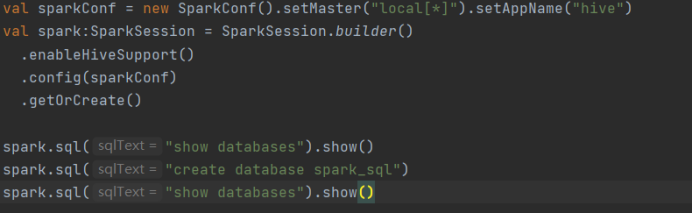
val sparkConf = new SparkConf().setMaster("local\*").setAppName("hive")
val spark:SparkSession = SparkSession.builder ()
.enableHiveSupport()
.config(sparkConf)
.getOrCreate()
spark.sql("show databases").show()
spark.sql("create database spark_sql")
spark.sql("show databases").show()