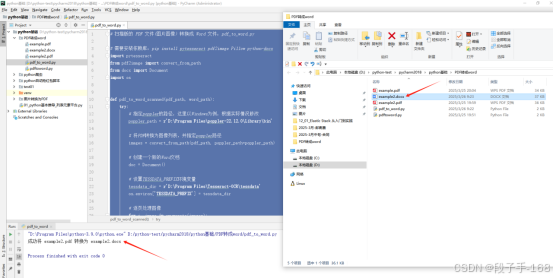
使用python写一个PDF文件转换成word 文件
一、前言:
要使用 Python 将 PDF 文件转换成 Word 文件,可以借助PyPDF2库来读取 PDF 文件内容,再使用python-docx库将内容写入 Word 文件。不过,PyPDF2只能处理文本类型的 PDF,如果 PDF 是扫描版的(即图像类型),则需要使用pytesseract库结合Pillow库进行 OCR(光学字符识别)。
二、以下是一个简单的示例代码,用于处理文本类型的 PDF 文件:
1、下载安装 python 如:python3.9
2、安装 PyPDF2 库。
bash
pip install PyPDF2 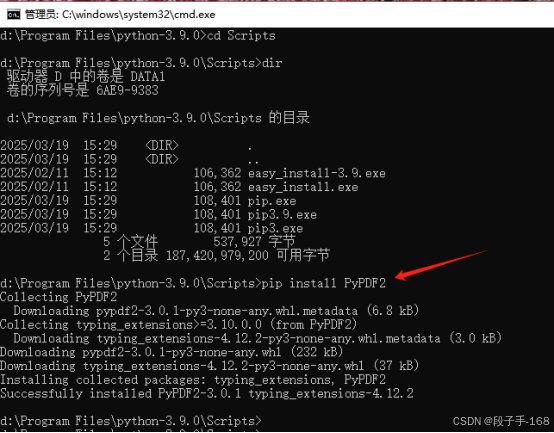
3、安装 python-docx 库。
bash
pip install python-docx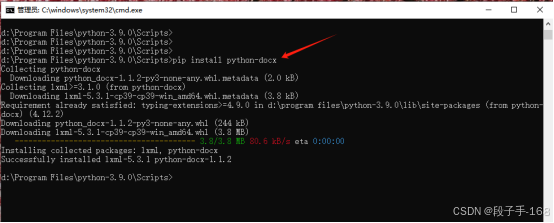
4、打开 pycharm(如:pycharm2018社区免费版),创建python文件 pdftoword.py。
bash
# PDF文件转成word
# (此代码仅适用于文本类型的 PDF 文件,如果是扫描版 PDF,需要使用 OCR 技术进行处理。)
import PyPDF2 # pip3 install PyPDF2
from docx import Document # pip install python-docx
# 定义转换函数(接受 PDF 文件路径和 Word 文件路径作为参数)
def pdf_to_word(pdf_path, word_path):
try:
# 打开PDF文件
with open(pdf_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
# 创建一个新的Word文档
doc = Document()
# 逐页读取PDF内容
for page in pdf_reader.pages:
text = page.extract_text()
if text:
doc.add_paragraph(text)
# 保存Word文档
doc.save(word_path)
print(f"成功将 {pdf_path} 转换为 {word_path}")
except Exception as e:
print(f"转换过程中出现错误: {e}")
if __name__ == "__main__":
pdf_file = 'example.pdf'
word_file = 'example.docx'
pdf_to_word(pdf_file, word_file)5、在pdftoword.py 所在目录准备 example.pdf 文件,打开pycharm2018 ,运行 pdftoword.py 会在当前目前生成 example.docx 文件。
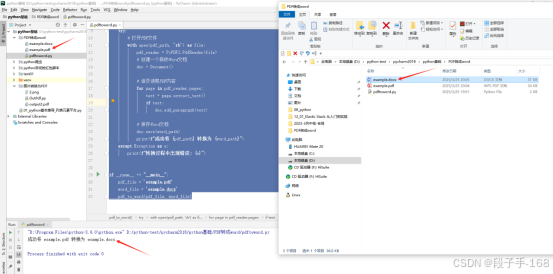
三、扫描版的 PDF 文件转换成 Word 文件:
1、若要把扫描版的 PDF 文件转换成 Word 文件,得借助 OCR(光学字符识别)技术来识别 PDF 中的文字。在 Python 里,可以使用pytesseract库实现 OCR,同时结合Pillow库来处理图像,以及pdf2image库把 PDF 文件转换为图像。
2、安装依赖库:pytesseract、pdf2image、Pillow和python-docx库。
bash
pip install pytesseract pdf2image Pillow python-docx
3、安装 Tesseract OCR 和 poppler 工具:pytesseract依赖于 Tesseract OCR 引擎,需要下载并安装 Tesseract OCR,并根据实际安装路径设置(如:D:\Program Files\Tesseract-OCR)。
1)下载安装 Tesseract OCR
https://soft.3dmgame.com/down/233782.html
https://github.com/UB-Mannheim/tesseract/wiki
https://digi.bib.uni-mannheim.de/tesseract/
2)设置 Tesseract OCR 的路径(如果需要)
pytesseract.pytesseract.tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
3)下载安装 poppler 并指定poppler的安装或解压路径(如:D:\Program Files\poppler-22.12.0\Library\bin)
Poppler 是一个基于GPL和LGPL开源协议的 PDF 渲染库,同时也是一组用于处理 PDF 文件的实用工具集合。
https://github.com/oschwartz10612/poppler-windows/releases/
4、打开 pycharm(如:pycharm2018社区免费版),创建python文件 pdf_to_word.py。
bash
# 扫描版的 PDF 文件(图片图像) 转换成 Word 文件:pdf_to_word.py
# 需要安装依赖库:pip install pytesseract pdf2image Pillow python-docx
import pytesseract
from pdf2image import convert_from_path
from docx import Document
import os
def pdf_to_word_scanned(pdf_path, word_path):
try:
# 指定poppler的路径,这里以Windows为例,根据实际情况修改
poppler_path = r'D:\Program Files\poppler-22.12.0\Library\bin'
# 将PDF转换为图像列表,并指定poppler路径
images = convert_from_path(pdf_path, poppler_path=poppler_path)
# 创建一个新的Word文档
doc = Document()
# 设置TESSDATA_PREFIX环境变量
tessdata_dir = r'D:\Program Files\Tesseract-OCR\tessdata'
os.environ['TESSDATA_PREFIX'] = tessdata_dir
# 逐页处理图像
for i, image in enumerate(images):
# 使用pytesseract进行OCR识别(需有chi_sim.traineddata 和 eng.traineddata 字符集)
text = pytesseract.image_to_string(image, lang='chi_sim+eng')
# 将识别的文本添加到Word文档中
if text:
doc.add_paragraph(text)
# 保存Word文档
doc.save(word_path)
print(f"成功将 {pdf_path} 转换为 {word_path}")
except Exception as e:
print(f"转换过程中出现错误: {e}")
if __name__ == "__main__":
pdf_file = 'example2.pdf'
word_file = 'example2.docx'
# 设置Tesseract OCR的路径(如果需要)
pytesseract.pytesseract.tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
pdf_to_word_scanned(pdf_file, word_file)5、在pdf_to_word.py 所在目录准备 example2.pdf 文件,打开pycharm2018 ,运行 pdf_to_word.py 会在当前目前生成 example2.docx 文件。