如题,这不是入门教程,而是对 Nextjs 中的知识点进行查漏补缺,方便回顾复习,所以对于没接触过 Nextjs 的童鞋来说,本文可能会理解起来有些吃力,欢迎评论区讨论👏👏
Nextjs 中的概念
其实很多概念都是 React 提出的,比如 RSC、Suspense 等等,但是现在 Nextjs 框架在做 SSR 渲染的时候也用到了这些东西,在框架层面集成了这些功能的同时还做了增强。
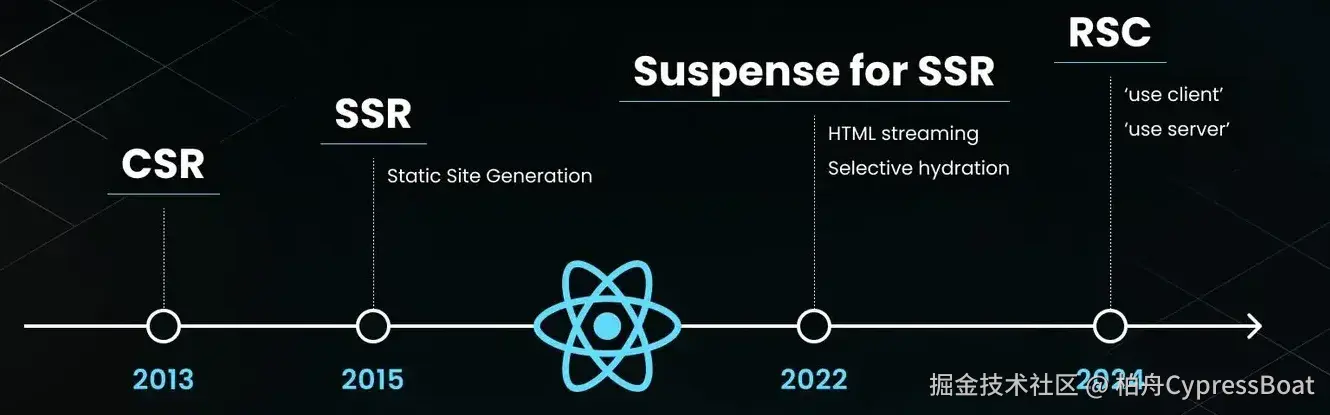
RSC
RSC(React Server Component) 是 React 的原生特性,允许组件在服务端运行并直接访问后端资源(如数据库、文件系统),同时通过流式传输(Streaming)将渲染结果与客户端组件动态结合。其目标是解决客户端渲染的性能瓶颈(如数据请求的瀑布流问题)和减少客户端包体积。
但是现阶段真正实现的是 Next.js, Next.js 的服务端组件是对 RSC 的框架级封装,依赖 RSC 的底层能力,但扩展了开发工具和优化策略。Next.js 在 App Router 模式中默认使用 RSC 规范,通过 "use client" 和 "use server" 指令区分客户端和服务端组件。正是因为 React 提出的 RSC 概念,所以 Next.js 新版(如 V13)采用 App Router 作为默认架构。
RSC Payload 包含以下信息:
- 服务端组件的渲染结果
- 客户端组件的占位符及其 JavaScript 引用。
- 从服务端组件传给客户端组件的数据;
App Router
Next.js 13+ 的 App Router 引入了 React Server Components(RSC),彻底改变了渲染逻辑:流式渲染(Streaming SSR)、部分水合(Partial Hydration)。
这些改进使 App Router 脱离了传统 SSR 的"全量渲染"模式,但 Page Router 仍属于传统 SSR 的范畴。
传统 SSR 渲染的逻辑 :每次请求生成 HTML。 以 Nextjs 为例, 在 Page Router 中,若使用 getServerSideProps 函数,则与传统 SSR 的核心逻辑完全一致( getServerSideProps 封装了服务端逻辑,开发者无需直接操作 Node.js 底层) 。但 Nextjs 的 Page Router 并非仅支持传统 SSR *,还提供了多种渲染策略的混合: SSG、CSR、ISR。 若只使用 getServerSideProps ,则与传统 SSR 无异。
流式渲染: 使用 loading.js 或者 <Suspense> 组 件会开启流式渲染;
部分水合:是 指仅对需要交互的组件进行客户端水合。在服务器渲染过程中,Next.js 生成 React Server Component Payload(RSC Payload),当客户端接收到 RSC Payload 后,React 会对比服务端生成的静态 DOM 与客户端的组件树,仅对客户端组件进行水合,跳过服务端组件的重复渲染。
在 Next.js 中,流式渲染(Streaming Rendering)与服务端组件(RSC)的结合涉及 Transfer-Encoding: chunked 和 RSC Payload 两种不同机制:首次加载、全页面刷新的时候,会利用 Transfer-Encoding: chunked 请求头,返回包含新内容的 HTML 分块,快速首屏渲染,渐进式内容展示;后续在该页面上发生交互产生的动态更新请求,或者该页面用到客户端导航(如组件),就会返回 RSC payload,来局部更新 DOM,保留客户端状态。 (PS: 最佳的纯静态导出(SSG)框架是 Astro!)


Pages Router
Pages Router(旧版)与 App Router(新版)在目录结构上的区别是:旧版以 pages 文件夹为准,新版以 app 文件夹,通过目录路径自动映射路由。
App Router 引用了 react 的 RSC,脱离了传统的 SSR 渲染,默认就是服务端组件,可以直接 fetch 获取数据,废弃了 getStaticProps/getServerSidePropsff 方法,需在组件顶部通过"use client"声明客户端组件。而在客户端中,再想使用服务端方法,比如操作数据库,也需要加上 "use server"
"use client"
"use client" 用于声明服务端和客户端组件模块之间的边界,这意味着,在一个定义了"use client"文件中,导入的其他模块包括子组件,都会被视为客户端 bundle 的一部分。
但在 Nextjs 中其实所谓服务端组件、客户端组件并不直接对应于物理上的服务器和客户端。服务端组件运行在构建时和服务端,客户端组件运行在构建时、服务端(生成初始 HTML)和客户端(管理 DOM)。
混合使用时,服务端组件可以直接导入客户端组件,但客户端组件并 不能直接 导入服务端组件 (但是 如果服务端组件没有包含服务器专属逻辑 (如 fs、process.env),只是纯静态逻辑无副作用,客户端组件也能直接导入服务端组件,此时服务端组件实际已被视为客户端组件 。Nextjs 官方禁止客户端组件直接导入服务端组件,一方面是服务端组件不能在浏览器环境里运行,缺少 window、document 等,另一方面是渲染顺序不对,服务端是在构建时就确定好,客户端是在运行时渲染)。
最佳实践是利用两种 props 的形式将服务端组件传递给客户端组件:
jsx
<ClientComponent id="1">
<small>{dayjs(updateTime).format('YYYY-MM-DD hh:mm:ss')}</small>
</ClientComponent>注意,传递的数据必须是可序列化的,所以服务端组件不能传递方法函数给客户端组件 (但是可以传递 server action ) 。多使用服务端组件有很多好处比如代码(dayjs) 不会打包到客户端 bundle 中,所以尽可能利用服务端组件来处理逻辑数据、静态渲染,将交互事件部分抽离成一个客户端组件,这样最后打包出来的包才是最小的。
Suspense
- React 的 Suspense
React Suspense 的核心是协调客户端异步组件的加载状态 。它通过包裹需要异步加载的组件(如React.lazy动态导入的组件),在加载过程中显示fallback内容(如加载动画)。其原理分为两步:
-
- 异步依赖捕获:识别被包裹组件的异步操作(如代码分割、数据请求);
- 状态切换 :在异步操作完成前渲染
fallback,完成后替换为实际内容。
- Next.js 的 Suspense
Next.js 的 Suspense 不仅处理客户端组件,还深度集成了服务端组件(RSC)的异步协调。相当于通过框架内置能力增强 Suspense,其原理包括:
-
- 服务端渲染阶段:生成 React Server Component Payload(RSC Payload),标记异步依赖;
- 客户端激活阶段:基于 RSC Payload 协调服务端和客户端组件树,确保两者一致;
- 混合加载控制:支持在服务端预渲染部分内容,客户端按需加载剩余部分。
- React 的典型用例
-
- 代码分割 :配合
React.lazy实现按需加载组件; - 数据预取:在 Concurrent Mode 中管理数据请求的加载状态;
- 错误边界补充:与错误边界结合处理异步过程中的异常。
- 代码分割 :配合
- Next.js 的进阶场景
-
- 流式渲染(Streaming SSR) :将页面拆分为多个区块,优先渲染关键内容,非关键部分通过 Suspense 延迟加载;
- 服务端与客户端组件混合:在服务端渲染静态内容的同时,客户端动态加载交互组件(如表单);
- SEO 优化:通过 Suspense 控制服务端渲染的占位内容,避免爬虫获取未加载的空白区域。
创建一个 Nextjs 项目
利用脚手架
一般我们创建项目都会创建好一个新的文件夹,那么在已有的目录下创建ts版本的 next 项目可以使用这样命令:npx create-next-app@latest . --typescript
其中.代表在当前项目创建目录,这样就不用再另起名字创建一个新的目录了。
创建 next 项目时候还可以用官方示例模板:npx create-next-app --example xxx
纯手撸
next 项目的核心依赖就是安装npm install next@latest react@latest react-dom@latest这几个依赖,然后手动搭建 next 项目还需创建app文件夹,添加layout.js 和 page.js文件
script 命令
执行 package.json 中 script 字段里命令,背后就是执行 Nextjs CLI 提供的 next 命令。如果没全局安装create-next-app,可以使用 npx 来使用 next 命令:npx next build
next build输出的文件压缩信息:First Load JS(加载该 JS 的总大小) = Size(该 JS 的大小) + First load JS shared by all(共享 JS 大小)next build --profile配合React.Profiler可以在控制台看到性能检测next info可以打印系统和本项目用到的相关信息,这些信息可以贴到 GitHub Issues 中方便官方人员排查问题
文件目录
App Router 下的文件层级:

其中定义页面的page.js/index.js、定义布局的layout.js、定义模板的template.js、定义加载界面的loading.js、定义错误处理的error.js、定义 404 页面的not-found.js
注意点:
- React 的 state 和 ref 等数据存储在组件实例中,只要组件未被卸载(unmount),这些状态就会保留。layout 作为共享布局组件,在路由切换的时候不会被卸载组件,所以定义在 layout 里的状态会保存下来。但 layout 的
{children}则会重新加载。而 Template 在底层设计上通过 key 变化强制触发组件重建 app/error.js捕获不了同级的layout.js或者template.js中的错误,app/global-error.js用来处理根布局和根模板中的错误,当它触发的时候,它会替换掉根布局的内容,所以global-error.js中也要定义<html>和<body>标签。- 如果
not-found.js放到了任何子文件夹下,它只能由notFound函数手动触发,import { notFound } from'next/navigation'。执行 notFound 函数时,会由最近的 not-found.js 来处理。但如果直接访问不存在的路由,则都是由app/not-found.js来处理。
路由
路由导航
在 Next.js 中,有 4 种方式可以实现路由导航:
- 使用
<Link>组件。(拓展了原生 HTML<a>标签的内置组件,用来实现预获取(prefetching) 和客户端路由导航) - 使用
useRouterHook(客户端组件) - 使用
redirect函数(服务端组件) - 使用浏览器原生 History API。通常与 usePathname(获取路径名的 hook) 和 useSearchParams(获取页面参数的 hook) 一起使用。
动态路由
- folderName:比如
[id]、[slug]。这个路由的名字会作为paramsprop 传给布局 、 页面 、 路由处理程序 以及 generateMetadata 函数。 - ...folderName:捕获所有后面所有的路由片段。比如在
app/shop/[...slug]/page.js中,当浏览器访问/shop/a的时候,params的值为{ slug: ['a'] }。当访问/shop/a/b的时候,params的值为{ slug: ['a', 'b'] }。当访问/shop/a/b/c的时候,params的值为{ slug: ['a', 'b', 'c'] }。 - \[...folderName]:可选的捕获所有后面所有的路由片段。与上一种的区别就在于,不带参数的路由也会被匹配(就比如
/shop),app/shop/[[...slug]]/page.js会匹配/shop,当访问/shop的时候,params 的值为{}。
路由组
- 在
app目录下,文件夹名称通常会被映射到 URL 中,如果把文件夹用括号括住,就比如(dashboard),就可以将该文件夹标记为路由组,阻止文件夹名称被映射到 URL 中。 - 使用路由组,你可以将路由和项目文件按照逻辑进行分组或者创建不同布局,但不会影响 URL 路径结构。
- 如果是要创建多个根布局,需要删除掉
app/layout.js文件,然后在每组都创建一个layout.js文件。创建的时候要注意,因为是根布局,所以要有<html>和<body>标签。这个功能很实用,比如将前台 C 端页面和后台 B 端管理页面都放在一个项目里,两个项目的布局肯定不一样,借助路由组,就可以轻松实现区分。因为删除了顶层的app/layout.js文件,访问/会报错,所以app/page.js需要定义在其中一个路由组中。跨根布局导航会导致页面完全重新加载(full page load)
平行路由
- 平行路由可以使你在同一个布局中同时或者有条件的渲染一个或者多个页面(类似于 Vue 的插槽功能)。
- 平行路由的使用方式是将文件夹以
@作为开头进行命名,比如定义两个插槽@team和@analytics。

- 平行路由可以让你为每个路由定义独立的错误处理和加载界面:

- 平行路由下面还可以添加子页面,而且平行路由跟路由组一样,不会影响 URL。但是当导航至这些子页面的时候,子页面的内容会取代
/@analytics/page.js以 props 的形式注入到布局中。

- 如果访问平行路由子页面的时候,在软导航的时候(Link),为了更好的用户体验,如果有一个插槽 URL 不匹配,Next.js 会继续保持该插槽之前的状态,而不渲染 404 错误。但当发生硬导航的时候(浏览器刷新),Next.js 会渲染 404 错误。解决方案是给每个平行路由都加一个 default.js,Next.js 会为不匹配的插槽呈现 default.js 中定义的内容,如果 default.js 没有定义,再渲染 404 错误。
拦截路由
在当前路由拦截其他路由地址并在当前路由中展示内容。
- 主要区别在软路由(Link)和地址栏来中输入同一地址,路由匹配结果会不一样。在地址栏中输入地址会优先匹配拦截路由,软路由则是正常匹配。
- 实现拦截路由需要在命名文件夹的时候以
(..)开头,比如app/(..)shop,这个匹配的是路由的层级而不是文件夹路径的层级,就比如路由组、平行路由这些不会影响 URL 的文件夹就不会被计算层级。其中:比如/feed/(..)photo对应的路由是/feed/photo,要拦截的路由是/photo,两者只差了一个层级,所以使用(..)。
-
(.)表示匹配同一层级(..)表示匹配上一层级(..)(..)表示匹配上上层级(...)表示匹配根目录
路由处理程序
指使用 Web Request 和 Response API 对于给定的路由自定义处理逻辑,简单来说就是后端接口请求。
- 使用新的约定文件
route.js,该文件必须在app目录下,可以在app嵌套的文件夹下,但是要注意page.js和route.js不能在同一层级同时存在。(page.js和route.js本质上都是对路由的响应。page.js主要负责渲染 UI,route.js主要负责处理请求。如果同时存在,Next.js 就不知道用谁的逻辑了)。 - 在开发的时候,尽可能使用 NextRequest 和 NextResponse,它们是基于原生 Request 和 Response 的封装,提供了快捷处理 url 和 cookie 的方法。
- Next.js 优先推荐使用原生的 fetch 方法获取数据,因为 Next.js 拓展了 fetch 的功能,添加了记忆缓存功能,相同的请求和参数,返回的数据会做缓存,所以多个组件共用一个数据直接 fetch 请求即可,不需要 React Context(当然服务端也用不了),也不需要通过 props 传递数据。
- 当 Next.js 遇到频繁重复的数据库操作时,记住使用 React 的 cache 函数,这是数据缓存
- Next.js 中的缓存主要分为:Router Cache、Full Route Cache、 Request Memoization、Data Cache
路由缓存
- Router Cache(客户端路由缓存) :客户端缓存机制,存放在浏览器的临时缓存中,用于在用户会话期间缓存已访问页面的 RSC Payload(如通过前进/后退导航快速加载)。在 Next.js 14 中,Router Cache 默认保留较长时间,可能导致旧数据展示(如通过
<Link>跳转,Link 组件的 prefetch 默认为 true,或者在动态渲染路由中调用router.prefetch,可以进入缓存 5 分钟)。Next.js 15 中,客户端导航时优先请求最新数据,仅当数据未变化时复用缓存,减少过时内容问题(默认staleTime设为 0)。共享布局(Layout)的缓存仍保留,避免重复加载公共部分。 - Full Route Cache(整页路由缓存) :在 Next.js 14 及之前,静态生成的页面(如通过
getStaticProps)默认启用 Full Route Cache,HTML 和 RSC Payload 会被缓存以加速后续请求。Next.js 15 中,默认行为改为no-store,即不再自动缓存,需显式配置revalidate参数或路由段设置(如export const revalidate = 3600)来启用缓存 - Request Memoization(请求记忆) :用于在 React 组件树中复用相同请求的响应数据。Next.js 14 自动对所有 GET 方法的
fetch请求启用请求记忆,包括布局、页面和其他服务端组件。Next.js 15仍支持请求记忆,但更严格限定于服务端组件(如Layout、Page),且对动态路由和客户端组件的兼容性优化。 - Data Cache(数据缓存) :主要用于服务端数据的持久化存储,其核心目标是减少对后端数据源(如数据库、API)的重复请求。Next.js 14 自动缓存,需手动退出(
fetch请求和 GET 路由处理程序默认启用数据缓存)。Next.js 15 默认不缓存,需显式启用(fetch 请求默认使用no-store)

js
// 直接使用原生 Response 也是可以的,但是推荐使用 NextResponse,因为它是 Next.js 基于 Response 的封装,它对 TypeScript 更加友好,同时提供了更为方便的用法,比如获取 Cookie 等。
import { NextResponse } from 'next/server'
import { cookies, headers } from 'next/headers'
import { redirect } from 'next/navigation'
export async function GET(request, context) {
// request, context 都是可选参数
// request 对象是一个 NextRequest 对象,它是基于 Web Request API 的扩展。使用 request ,你可以快捷读取 cookies 和处理 URL。
// context 只有一个值就是 params,它是一个包含当前动态路由参数的对象
const pathname = request.nextUrl.pathname // 访问 /home, pathname 的值为 /home
const searchParams = request.nextUrl.searchParams // 访问 /home?name=lee, searchParams 的值为 { 'name': 'lee' }
const id = searchParams.get("id")
const team = context.params
// 例如 app/dashboard/[team]/route.js,当访问 /dashboard/1 时,params 的值为 { team: '1' }
// 例如 app/shop/[tag]/[item]/route.js,当访问 /shop/1/2 时,params 的值为 { tag: '1', item: '2' }
// 例如 app/blog/[...slug]/route.js,当访问 /blog/1/2时,params 的值为 { slug: ['1', '2'] }
const token = request.cookies.get('token')
request.cookies.set(`token2`, 123)
// 处理 headers 方式1:request.headers
const headersList = new Headers(request.headers)
const referer = headersList.get('referer')
// 处理 headers 方式2:next/headers 包提供的 headers 方法。
const headersList = headers()
const referer = headersList.get('referer')
// Next.js 拓展了原生的 fetch 方法
const res = await fetch('https://jsonplaceholder.typicode.com/posts')
const data = await res.json()
// return NextResponse.json({ data })
return new Response('Hello, Next.js!', {
status: 200,
headers: {
'Set-Cookie': `token=${token}`,
referer,
// 设置 CORS
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET, POST, PUT, DELETE, OPTIONS',
'Access-Control-Allow-Headers': 'Content-Type, Authorization'
},
})
}
export async function POST(request) {
const article = await request.json() // 获取请求体内容
// 如果请求正文是 FormData 类型
// const formData = await request.formData()
// const name = formData.get('name')
// const email = formData.get('email')
return NextResponse.json({
id: Math.random().toString(36).slice(-8),
data: article
}, { status: 201 })
}
export async function HEAD(request) {}
export async function PUT(request) {}
export async function DELETE(request) {}
export async function PATCH(request) {}
// 如果 `OPTIONS` 没有定义, Next.js 会自动实现 `OPTIONS`
export async function OPTIONS(request) {}Server Actions
在 Next.js 中,Server Actions 和 路由处理程序(Route Handlers) 是两种处理服务端逻辑的不同方案:
Server Actions
-
- 定义位置:在 React 组件文件中使用
"use server"指令声明,或通过单独文件action.js导入 - 触发方式:通过表单的
action属性或客户端事件(如按钮点击)调用。
- 定义位置:在 React 组件文件中使用
路由处理程序
-
- 定义位置:在
app/api目录下创建route.js文件,并导出 HTTP 方法函数(如GET、POST) - 触发方式:通过客户端
fetch或直接访问 API 端点 URL(如/api/users)。
- 定义位置:在
Next.js 的渲染原理:Next.js 使用 React 的 API 来编排渲染。当渲染的时候,渲染工作会根据路由和 Suspense 拆分成多个 chunk,每个 chunk 分为两步进行渲染:
- React 会将服务端组件渲染成一种特殊的数据格式,我们称之为 React Server Component Payload,简写为 RSC payload。比如一个服务端组件的代码为:
jsx
<div>
Don't give up and don't give in.
<ClientComponent />
</div>React 会将其转换为如下的 Payload:这个格式针对流做了优化,它们可以以流的形式逐行从服务端发送给客户端,客户端可以逐行解析 RSC Payload,渐进式渲染页面。
kotlin
["$","div",null,{"children":["Don't give up and don't give in.", ["$","$L1",null,{}]]}]
1:I{"id":123,"chunks":["chunk/[hash].js"],"name":"ClientComponent","async":false}当然这个 RSC payload 代码肯定是不能直接执行的,它包含的更多是信息:
- 服务端组件的渲染结果
- 客户端组件的占位和引用文件
- 从服务端组件传给客户端组件的数据
比如这个 RSC Payload 中的 $L1 表示的就是 ClientComponent,客户端会在收到 RSC Payload 后,解析下载 ClientComponent 对应的 bundle 地址,然后将执行的结果渲染到 $L1 占位的位置上。
- Next.js 会用 RSC payload 和客户端组件代码在服务端渲染 HTML:简单来说,路由渲染的产物有两个,一个是 RSC Payload,一个是 HTML。完整页面路由缓存,缓存的就是这两个产物。

middleware 原理
中间件代码的维护,可以借助高阶函数,原理就是洋葱模型
js
import { NextResponse } from 'next/server'
function chain(functions, index = 0) {
const current = functions[index];
if (current) {
const next = chain(functions, index + 1);
// 关键是理解这里:即返回当前函数包裹下一个函数
return current(next);
}
return () => NextResponse.next();
}
function withMiddleware1(middleware) {
return async (request) => {
console.log('middleware1 ' + request.url)
return middleware(request)
}
}
function withMiddleware2(middleware) {
return async (request) => {
console.log('middleware2 ' + request.url)
return middleware(request)
}
}
export default chain([withMiddleware1, withMiddleware2])
export const config = {
matcher: '/api/:path*',
}
// chain([withMiddleware1, withMiddleware2]) 整个递归下来就相当于 withMiddleware1(withMiddleware2(()=>NextResponse.next()))
// 那么就会先执行withMiddleware1(),这是一个典型的洋葱模型Middleware1 开始 → Middleware2 开始 → NextResponse.next() → Middleware2 结束 → Middleware1 结束上面洋葱模型只有调用前的逻辑,可以补上调用后的执行逻辑,模拟完整的洋葱调用模型:
js
function chain(functions, index = 0) {
const current = functions[index];
if (current) {
const next = chain(functions, index + 1);
return current(next);
}
return () => console.log('done');
}
function withMiddleware1(middleware) {
return async (request) => {
console.log('middleware1 ' + request.url);
const res = await middleware(request);
console.log('middleware1 end');
return res;
};
}
function withMiddleware2(middleware) {
return async (request) => {
console.log('middleware2 ' + request.url);
const result = await middleware(request); // 调用下一个中间件
console.log('middleware2 end'); // 在下一个中间件完成后执行
return result;
};
}
const fn = chain([withMiddleware1, withMiddleware2]);
// 相当于
// fn => withMiddleware1(
// withMiddleware2(
// () => console.log('done')
// )
// )
fn({ url: '/api' });
// 分析整个流程:
// 1. 首先进入 withMiddleware1
// async (request) => {
// console.log('middleware1 ' + request.url) // 1打印: middleware1 /api
// const res = await middleware(request) // 等待并进入 withMiddleware2
// console.log('middleware1 end') // 5 withMiddleware1 继续执行打印: middleware1 end
// return res
// }
// 2. 然后进入 withMiddleware2
// async (request) => {
// console.log('middleware1 ' + request.url) // 2打印: middleware2 /api
// const res = await middleware(request) // 等待并执行最后的函数
// console.log('middleware1 end') // 4 withMiddleware2 继续执行打印: middleware2 end
// return res
// }
// 3. 执行最后的函数
// () => console.log('done') // 3打印: done草稿模式
草稿模式(Draft mode):为了在生产环境实时预览一些未发布的草稿内容,这就涉及到需要动态渲染。
Nextjs 实现的方式也很简单,就是对外暴露了 draftMode() 函数,import { draftMode } from'next/headers';,该函数返回三个对象:const { isEnabled, enable, disable } = await draftMode();
isEnabled(布尔值):标识当前是否处于草稿模式。enable():启用草稿模式,设置__prerender_bypassCookie。disable():禁用草稿模式,删除 Cookie。
在 Nextjs15 版本启用草稿模式的流程是:
- 首先定义一个路由处理程序,例如
/app/api/enable-draft/route.ts(GET api),一般开启草稿模式的时机是:点击页面上的"保存草稿"按钮后请求该 GET api ,生成一个带密钥的预览链接https://your-site.com/api/preview?secret=<token>&userId=<user_id>&slug=<post_path>,后续点击页面上"预览"按钮会先请求刚刚生成的 api 来通过鉴权决定是否重定向到预览页面。 - 在预览页面也可以通过 isEnabled 的来判断是否开启草稿模式,如果开启,就请求草稿接口获取数据来展示。
- 默认在浏览器会话结束后会清理草稿模式的 Cookie,也可以定义一个路由处理程序比如
/app/api/disable-draft/routet.js(GET api),手动 disable() 禁用草稿模式。
rewrites
增量采用 Next.js: 通过在next.config.js配置rewrites重写,可以让 Next.js 在检查所有 Next.js 路由后,如果没有对应的路由,那就代理现有的网站,很适合老项目迁移。
重写与重定向(redirect)唯一的区别就是,重写相当于扮演 URL 代理的角色,会屏蔽目标路径,浏览器 URL 不会变化,但是路由内容变化。