概率论是统计分析和机器学习的核心。掌握概率论对于理解和开发稳健的模型至关重要,因为数据科学家需要掌握概率论。本博客将带您了解概率论中的关键概念,从集合论的基础知识到高级贝叶斯推理,并提供详细的解释和实际示例。
目录
·简介
·概率分布
·贝叶斯推理
·结论
·行动呼吁
介绍
概率论是量化不确定性的数学框架。它使我们能够对随机现象进行建模和分析,在统计学、机器学习和数据科学中不可或缺。概率论帮助我们做出明智的决策、评估风险并建立预测模型。
基本集合论
首先,让我们定义几个关键术语。
集合**(Set)**是对象的集合。这些对象称为集合的元素。
集合a 的子集 b是其元素均为 a 的元素的集合*,即* 𝑏 ⊂ 𝑎。
空间 S 是最大的集合;因此,所有其他集合都在考虑之中𝑠ᵢ ⊂ 𝑆 。
空集 O 是空集或零集。O不 包含任何元素。
让我们将集合论的组成部分形象化。
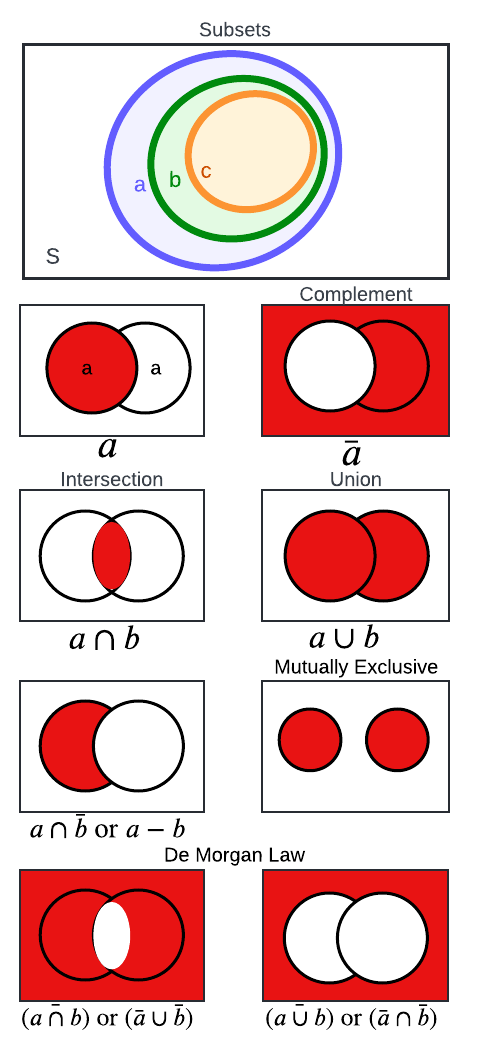
维恩图描绘了集合逻辑和运算。最上面的图显示样本空间S ,其中集合A 、B 和C 作为子集(即,B是 A 的子集,而C是 B 的子集;因此, C 是A 的子集)。其余行描绘了两个集合,A 和B。文本包含每个集合的描述和数学。作者创建了视觉效果。
上图描绘了我们在使用集合时遇到的各种场景。让我们来描述集合论的不同方面。鼓励读者在阅读定义和回顾数学表达式时参考每个小节后面的视觉图,以加深他们的直觉。
子集
子集𝑏 ⊂ 𝑎 ,或者集合a 包含b ,如果b 的所有元素也是a 的元素,则𝑎 ⊃ 𝑏。也就是说,
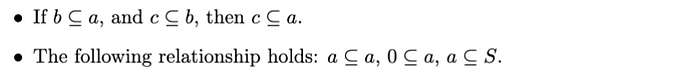
英文: 语句"如果b ⊆ a ,且c ⊆ b ,则c ⊆ a "表达了集合包含的传递性。如果集合b是集合 a 的子集,集合c是集合 b 的子集,则c也一定是 a 的子集。第二项"以下关系成立:a ⊆ a ,0 ⊆ a ,a ⊆ S "强调了集合包含的基本性质。因此:
- a ⊆ a表示每个集合都是其自身的子集。
- 0⊆a 表示 空集是任意集合a的子集。
- a⊆S 表示 任意集合a 都是全集S的子集。
集合运算
相等: 两个集合相等,则a 的每个元素都必须在b中,而 b 的每个元素都必须在a中。从数学上来说:
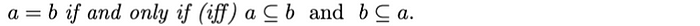
并集(和):两个集合 a 和b 的并集是由a 或b 或两者的所有元素组成的集合。并集运算满足以下性质:
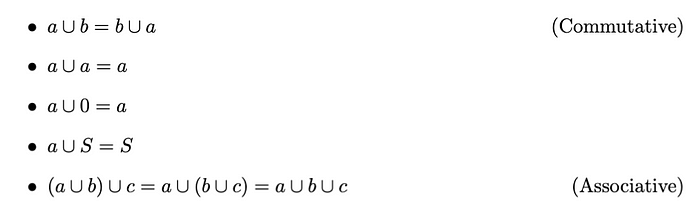
集合a 和b 的交集(积) 由集合a 和b 共有的所有元素组成。交集运算满足以下属性:
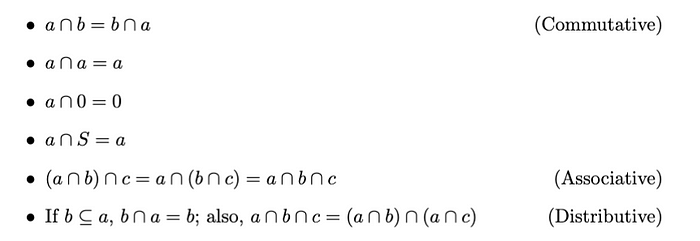
互斥集
如果两个集合a 和b没有共同元素,我们称它们互斥或不相交,即

补充
集合 a 的补集 a 定义为由 S 中所有不属于 a 的元素组成的集合。补集满足以下性质:

两集合之差
a − b 的差集是a 中不属于b的元素的集合***。***差集满足以下性质:
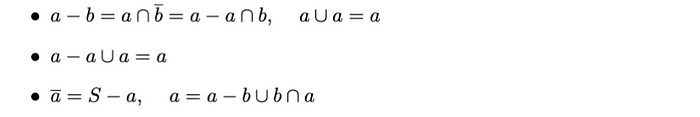
基本概率概念
样本空间(S):随机实验的所有可能结果的集合。
事件(E):样本空间的子集,包含特定结果或一组结果。
随机变量 (RV): 可能值为随机现象的数值结果的变量。**例如:**人的身高、抛硬币或掷骰子的结果。
事件的概率
事件E 的概率(即***P(E))***是衡量该事件发生可能性的指标。它满足以下性质:
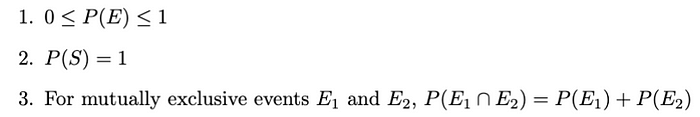
例子
考虑一个公平的六面骰子。样本空间为S = {1, 2, 3, 4, 5, 6}。掷出 3 的概率为 P({3}) = 1/6。掷出 1 或 3 呢?P({1, 3}) = 2/6 = 1/3。最后,掷出偶数呢?P({2, 4, 6}) = 3/6 = 1/2。
随机变量和期望
请注意,我们在本部分中使用了求和与积分。请参阅本系列的上一部分,其中涵盖了微积分和线性代数。
机器学习的基础数学
深入探究向量范数、线性代数、微积分
随机变量(RV)
RV 是一种变量,其值由随机实验的结果决定。有两种类型:离散随机变量 (取可数个值)和连续随机变量(取不可数个值)。
例如离散随机变量的分布:
- 它可以取每个值的概率。
- 符号:P(X=xi)。
- 这些数字满足以下条件:
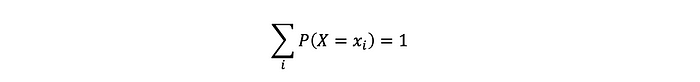
期望和方差
期望值(平均值):随机变量的平均值。
- 对于离散随机变量:
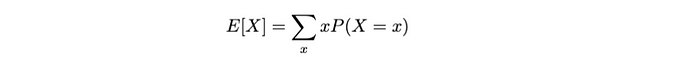
这个期望值(即平均值)是一个离散随机变量X 。因此,我们将其计算为所有可能值 x 乘以其各自概率**P(X = x)**的加权总和。
- 对于连续随机变量:
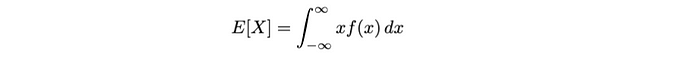
这个期望值(即平均值)是连续随机变量X的。我们将其计算为 x 乘以其概率密度函数**f(x)**在整个可能值范围内的积分。
总之:

方差:我们可以计算一个二阶统计测量,表示随机变量与预期值的偏离。
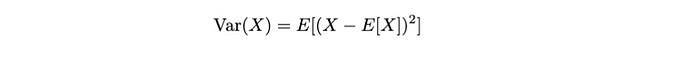
上述方程表示随机变量X的方差,测量 X 值围绕其均值**EX**的扩展或分散。
例子
对于一个公平的六面骰子,预期值是:
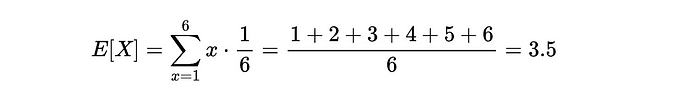
边际概率、联合概率和条件概率
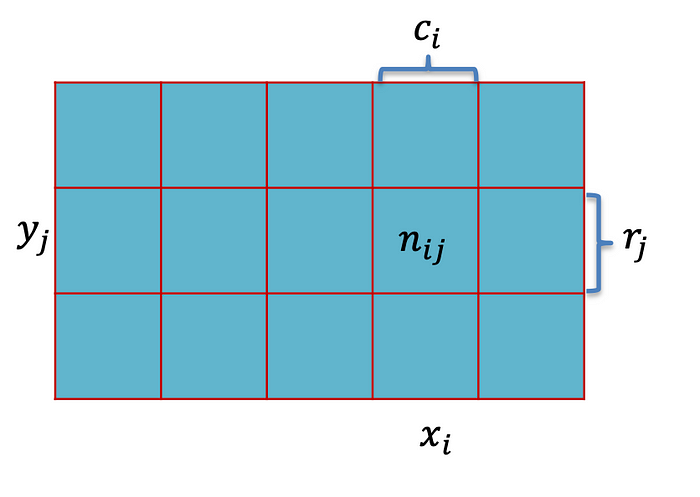
在本小节中,我们将使用一张图来解释边际概率、联合概率和条件概率。因此,表格是两个 RV 的联合概率分布,正如作者在此处所描绘的那样。
检查上面的图片。我们将使用这个视觉效果来学习概率论的基本概念:边际概率、联合概率和条件概率。这些概念对于理解随机变量之间的关系至关重要,尤其是在处理分类或计数数据时。
边际概率
边际概率是指在不考虑任何其他事件的情况下,单个事件发生的概率。在图中,**p(X = xᵢ)**表示它。然后,我们计算如下:

这表示随机变量X 取特定值xᵢ的概率,该概率被边缘化为其他变量的所有可能值。因此,它有助于通过将该事件的联合概率与另一个变量的所有可能结果相加来找到单个事件的概率。
联合概率
联合概率是两个事件同时发生的概率。参考上图,它是概率p(X = xᵢ, Y = yⱼ),计算如下:
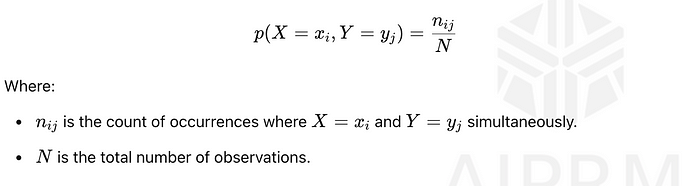
这个联合概率衡量两个事件X = xᵢ 和Y = yⱼ同时发生的可能性。
条件概率
条件概率衡量在另一个事件已经发生的情况下,发生另一事件的概率。图像将其定义为p(Y = yⱼ | X = xᵢ),计算方法如下:
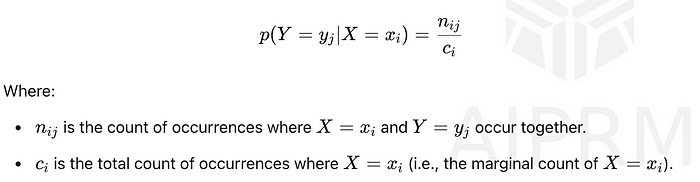
该公式显示在X = xᵢ 已经发生的情况下,Y = yⱼ的可能性有多大。
概率规则:边缘化和产品
边缘化是概率论中用到的一个过程,用于从所有变量的联合概率分布中推导出与变量子集相关的事件的概率。
在这个等式中,我们通过对另一个变量Y 的所有可能值求和来计算边际概率p(X = xᵢ):

乘积规则是概率中的一个基本概念,它使我们能够根据边际概率和条件概率来表示两个事件的联合概率。
该等式显示了联合概率***p(X = xᵢ, Y = yⱼ)***如何分解:
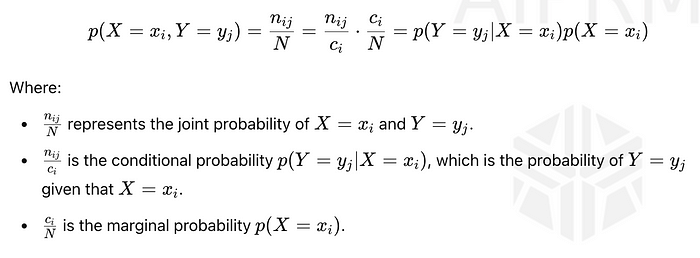
具体来说,用数学的方式表达,乘积法则允许使用一个事件的边际概率和在第一个事件的条件下另一个事件的条件概率来计算两个事件的联合概率。
概括
这些概念是概率论的基础,对于理解数据科学中更复杂的概率模型和推理技术至关重要。总结如下。
最后,如果P(Y | X) = P(Y) ,则𝑋 和𝑌 是独立的,这意味着P(Y | X) = P(Y) 。这意味着P(𝑋, 𝑌) = P(X)P(Y)。
贝叶斯定理
贝叶斯定理是贝叶斯推理的基石,是一个强大的概率结构,它使我们能够将先验知识融入到我们的计算中。
回到条件概率并在此基础上构建:回想一下我们之前定义的p(Y = yⱼ | X = xᵢ) 。我们可以使用事件A 和B来概括这一点,并将其进一步扩展到贝叶斯。
因此,条件概率量化了在另一事件发生的情况下发生某事件的概率。因此,在事件B发生的情况下 ,事件 A的概率是 A 和B 的联合概率与B 的概率之比。我们将其表示为P(A | B),并定义为:
管道字符"|"在概率论中翻译为"给定"。
因此,贝叶斯定理将两个事件的条件概率关联如下:
该术语根据似然P (B | A) 、先验P(A) 和边际概率***P(B)***来表达条件概率P(A | B) 。同样,这个构造是贝叶斯推理的基础,它使我们能够根据新证据更新我们的信念。
例子
假设我们对某种疾病进行测试,其概率如下:

利用贝叶斯定理,我们可以找到P(疾病|阳性):
我们可以这样计算P(Positive):
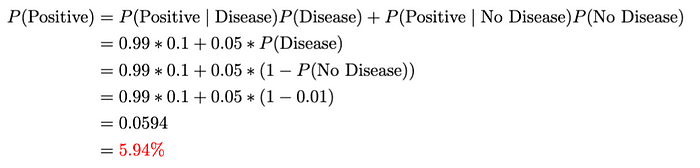
该方程表示考虑两种情况(即患有和不患有疾病)的检测呈阳性的总概率:直接应用总概率定律。
概率分布
典型趋势遵循已知分布。因此,一个常见的问题是假设一个特定的分布来拟合我们的数据。以下是离散和连续随机变量的几个分布。
离散分布
- 二项分布:描述固定次数的独立伯努利试验中的成功次数。
- 泊松分布:对固定时间间隔或空间内发生的事件数量进行建模。
连续分布
- 正态分布:以钟形曲线为特征,用平均值 μ 和标准差 σ 描述。
- 指数分布:描述泊松过程中事件之间的时间。
我们可以通过了解期望值、方差或其他统计指标来近似数据分布。以下备忘单总结了一些连续和离散 RV 的备忘单。
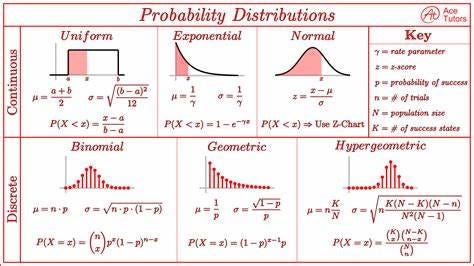
这是显示连续和离散概率分布的图表。每个分布都有其平均值、标准差和概率的公式------图片来源。
例子
让我们仔细看看正态分布的概率密度函数。从数学上讲,它表示如下:
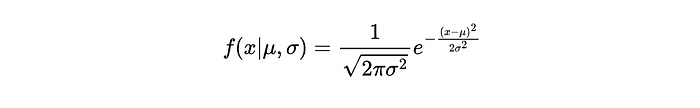
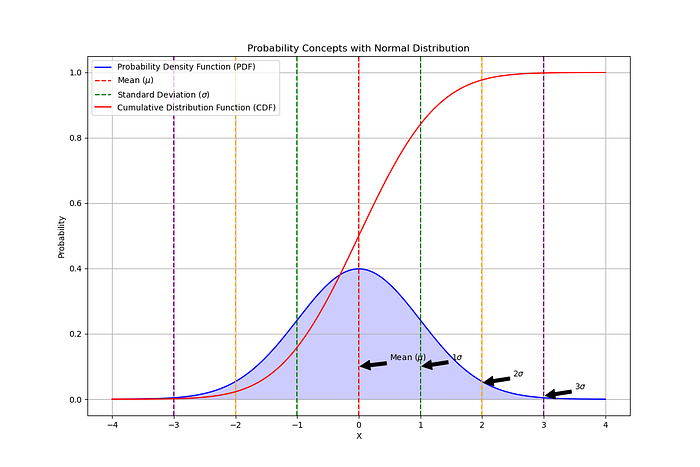
使用正态分布的概率概念可视化,显示概率密度函数 (PDF)、累积分布函数 (CDF)、平均值 (µ) 和标准差 (σ)。
该图以正态分布为基础,直观地展现了关键的概率概念。图中蓝色部分为概率密度函数 (PDF),表示分布中不同结果出现的可能性。PDF 曲线下方的面积表示随机变量落在特定范围内的概率。
累积分布函数 (CDF) 以红色显示。它从左到右累积概率,从 0 开始,渐近于 1。CDF 帮助我们确定随机变量小于或等于某个值的概率。
垂直虚线标记平均值 (μ) 和与平均值的标准差 (σ)。平均值在 x=0 处用红色虚线表示,而绿色、橙色和紫色虚线分别表示第一、第二和第三个标准差 (±1σ、±2σ、±3σ)。这些标准差说明了数据如何分布在平均值周围,其中约 68%、95% 和 99.7% 分别在平均值的 1σ、2σ 和 3σ 范围内。
图中的箭头有助于识别这些关键点,使视觉效果更易于理解。对于任何想要掌握概率基本概念的人来说,该图都是一个有用的工具,尤其是正态分布,它是统计分析和许多机器学习算法的基石。
使用概率进行学习
例如,在对垃圾邮件进行分类时,我们可以估计𝑃(𝑌 | 𝑉𝑖𝑎𝑔𝑎𝑟𝑎, 𝑙𝑜𝑡𝑡𝑒𝑟𝑦)。
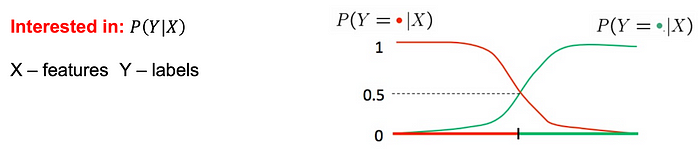
--- 如果𝑃(𝑌 | 𝑋) <0.5 ,我们会将示例归类为垃圾邮件。 --- 但是,对𝑃(𝑋 | 𝑌)
进行建模通常更容易。
这就给我们带来了最大似然法。
最大似然法

例如:抛硬币
根据n 次 抛硬币的结果(其中h 次都是正面),估计硬币掷出"正面"的概率p 。
数据的可能性:
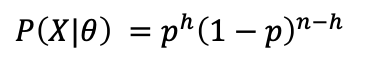
对数似然:
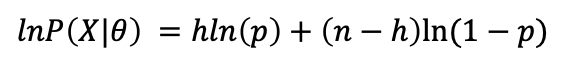
取导数并将其设置为 0:
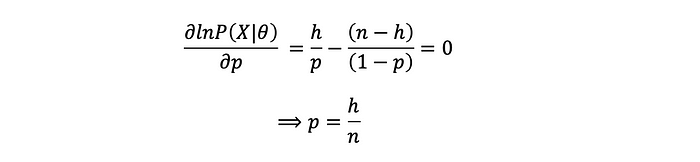
贝叶斯推理
贝叶斯推理是一种统计推断方法,其中贝叶斯定理用于随着更多证据的出现而更新假设的概率。
先验、似然和后验
- 先验(P (H)):对假设的初始信念。
- 可能性(P (E | H)):根据假设观察到证据的概率。
- 后验(P (H | E)):观察证据后对假设的更新信念。
贝叶斯推理中的贝叶斯定理:
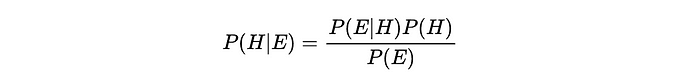
我们是如何得到这个结果的?让我们回到使用X 和Y进行泛化。
根据乘积法则
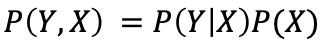
和
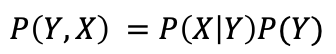
所以:
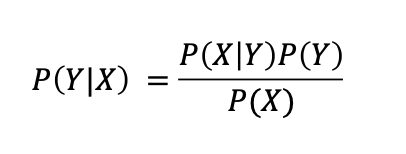
这被称为贝叶斯规则。
总之:

𝑷(𝑿) 可以计算为
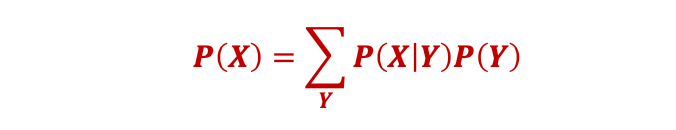
然而,推断标签并不重要。
例子
让我们回到我们的案例,我们正在接受罕见疾病的检测。这一次,我们的检测结果已经呈阳性。让我们使用贝叶斯来确定它是真阳性的概率(即使用贝叶斯检查测试是否为假阳性,即测试结果被错误地归类为真)。
- 在假阳性率为 5% 的测试中检测结果为阳性。
- 出现这种疾病的可能性有多大?
- 假设每 100 人中就有 1 人患有此病。这会有什么不同吗?
- 该测试的假阴性率为 10%;实际上,十分之一的错误预测是正确的。这可以用来改善我们的预测吗?
我们首先从视觉上看一下。
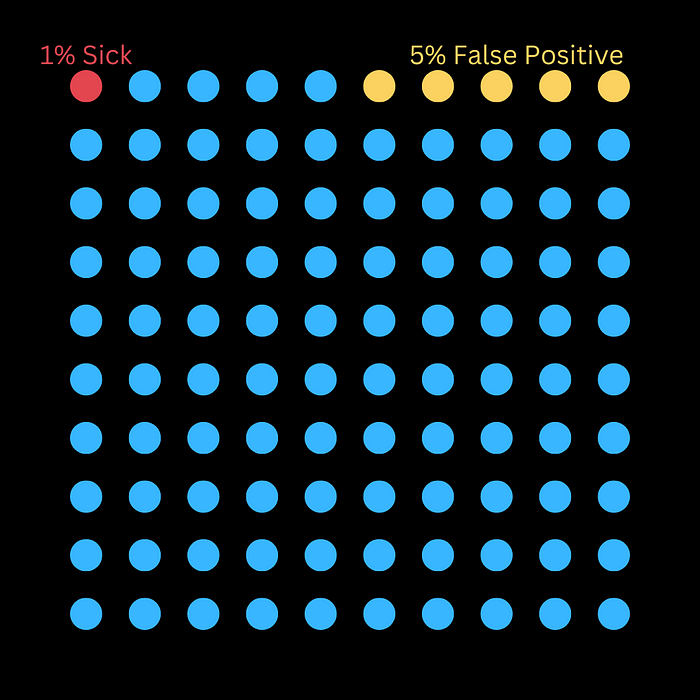
该图片显示,每 100 人中就有 5 人被错误地标记为患有该疾病(即假阳性),而 1 人确实患有该疾病。
让我们使用贝叶斯定理。
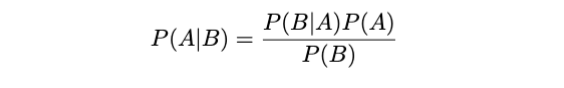
请查看《我们拥有 什么和想要什么》。
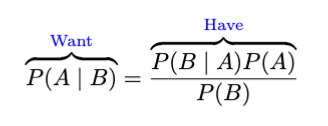
让我们进一步研究一下。

因此,先验(即分母中的P(B))由两个子集组成,我们可以将其表示为并集(或和)。
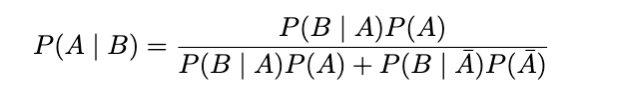
现在,插上电源并喝水:

因此,我们患病的概率为 15.4%!这比仅考虑假阳性率而不使用检测阳性和假阴性的百分比时原来的 95% 要好得多。
如果我们接受两次检测,每次都得到阳性结果,那会怎样?这种疾病存在的可能性有多大?
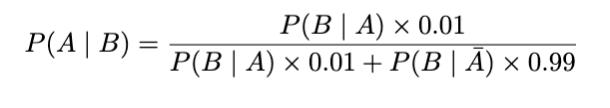
其中A 患有该疾病,而B两次检测结果呈阳性。

请注意,即使经过两次测试,我们的机会仍然低于原来的 95%。
这就是贝叶斯的美妙之处:随着我们获得更多知识,我们可以将其融入到我们的数字理解中,从而提高概率的精确度!
在 Python 中实现概率概念
我们将使用该numpy库进行数值计算和scipy.stats概率分布。
示例:抛硬币模拟
ba
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 导入必要的库</span>
<span style="color:#aa0d91">import</span> numpy <span style="color:#aa0d91">as</span> np
<span style="color:#aa0d91">import</span> scipy.stats <span style="color:#aa0d91">as</span> stats
<span style="color:#aa0d91">import</span> matplotlib.pyplot <span style="color:#aa0d91">as</span> plt
<span style="color:#007400"># 抛硬币次数</span>
n_flips = <span style="color:#1c00cf">100 </span>
<span style="color:#007400"># 模拟抛硬币(1 表示正面,0 表示反面)</span>
coin_flips = np.random.binomial( <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">0.5</span> , n_flips)
<span style="color:#007400"># 计算正面的次数</span>
n_heads = np.sum (coin_flips) <span style="color:#5c2699">print </span>
<span style="color:#5c2699">(</span> f <span style="color:#c41a16">"正面数量:<span style="color:#000000">{n_heads}</span> "</span> )
<span style="color:#007400"># 计算正面的概率</span>
p_heads = n_heads / n_flips
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">f"估计正面的概率:<span style="color:#000000">{p_heads: <span style="color:#1c00cf">.2</span> f}</span> "</span> )</span></span></span></span>输出:
正面次数:51
预计正面概率:0.51
概率分布可视化
ba
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 绘制二项分布</span>
n_trials = <span style="color:#1c00cf">10</span>
p_success = <span style="color:#1c00cf">0.5</span>
x = np.arange( <span style="color:#1c00cf">0</span> , n_trials+ <span style="color:#1c00cf">1</span> )
binomial_pmf = stats.binom.pmf(x, n_trials, p_success)
plt.figure(figsize=( <span style="color:#1c00cf">10</span> , <span style="color:#1c00cf">5</span> ))
plt.stem(x, binomial_pmf)
plt.title( <span style="color:#c41a16">'二项分布 PMF'</span> )
plt.xlabel( <span style="color:#c41a16">'成功次数'</span> )
plt.ylabel( <span style="color:#c41a16">'概率'</span> )
plt.show()</span></span></span></span>生成:
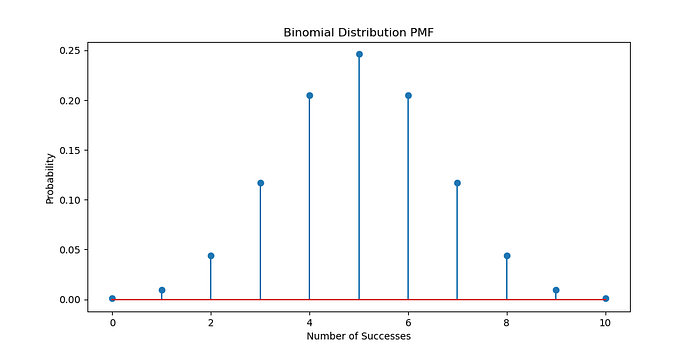
示例:硬币翻转的贝叶斯推理
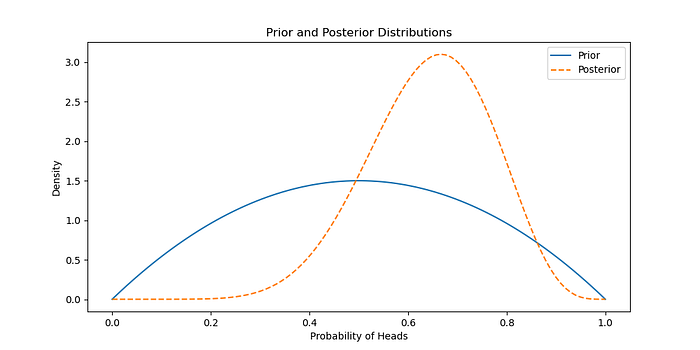
我们将使用贝叶斯推理来估计有偏差的硬币出现正面的概率。
先前的信念
假设 Beta 先验分布的参数为 α = 2 和 β = 2,表示统一的先验信念。
ba
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 定义先验分布</span>
alpha_prior = <span style="color:#1c00cf">2</span>
beta_prior = <span style="color:#1c00cf">2</span>
Prior = stats.beta(alpha_prior, beta_prior)
<span style="color:#007400"># 绘制先验分布</span>
x = np.linspace( <span style="color:#1c00cf">0</span> , <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">100</span> )
plt.figure(figsize=( <span style="color:#1c00cf">10</span> , <span style="color:#1c00cf">5</span> ))
plt.plot(x, Prior.pdf(x), label= <span style="color:#c41a16">'Prior'</span> )
plt.title( <span style="color:#c41a16">'Prior Distribution'</span> )
plt.xlabel( <span style="color:#c41a16">'Probability of Heads'</span> )
plt.ylabel( <span style="color:#c41a16">'Density'</span> )
plt.legend()
plt.show()</span></span></span></span>生成:
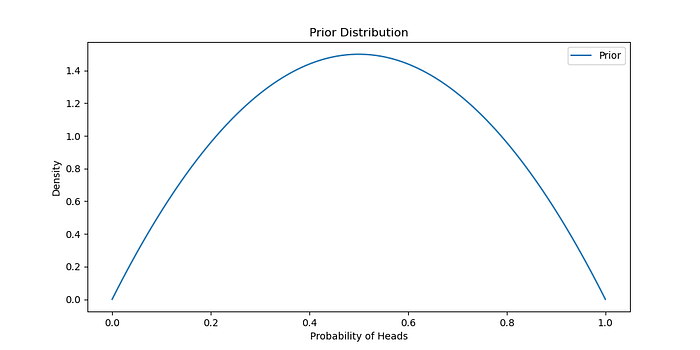
似然和后验
使用观察到的数据(证据)更新先验以获得后验分布。
ba
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 观察到的正面和反面的数量</span>
n_heads = <span style="color:#1c00cf">7</span>
n_tails = <span style="color:#1c00cf">3 </span>
<span style="color:#007400"># 更新后验分布</span>
alpha_posterior = alpha_prior + n_heads
beta_posterior = beta_prior + n_tails
posterior = stats.beta(alpha_posterior, beta_posterior)
<span style="color:#007400"># 绘制后验分布</span>
plt.figure(figsize=(
<span style="color:#1c00cf">10</span> , <span style="color:#1c00cf">5</span> ))
plt.plot(x, Prior.pdf(x), label= <span style="color:#c41a16">'Prior'</span> )
plt.plot(x, posterior.pdf(x), label= <span style="color:#c41a16">'Posterior'</span> , linestyle= <span style="color:#c41a16">'--'</span> )
plt.title( <span style="color:#c41a16">'先验和后验分布'</span> )
plt.xlabel( <span style="color:#c41a16">'正面的概率'</span> )
plt.ylabel( <span style="color:#c41a16">'密度'</span> )
plt.legend()
plt.show()</span></span></span></span>生成:
结论
概率论是支撑许多统计和机器学习技术的基本数据科学组成部分。本教程涵盖了概率的基本概念,从基本定义到高级贝叶斯推理,并提供了实际示例和 Python 实现。通过掌握这些概念,您可以构建更强大的模型,做出更好的决策,并从数据中获得更深入的见解。
尝试使用不同的概率分布、假设和数据集来探索概率论在数据科学项目中的广泛应用。