本节内容比较初级,故接着躺平攻略写
一、官网的下载
1.1 下载解压
首先,去官网下载jar包,放进linux中,解压到对应位置。
我的位置放在/WORK/MIDDLEWARE/kafka/4.0
1.2 常见配置
bash
# 每个topic默认的分片数
num.properties=4
# 数据被删除的时间
log.retention.hours=168
# 文件存储路径,注意,这不是日志,而是数据
log.dirs=/WORK/MIDDLEWARE/kafka/4.0/kraft-combined-logs
# 这个地方一定要修改,不然客户端无法连通
# 这里要写成ip
advertised.listeners=PLAINTEXT://192.168.0.64:9092,CONTROLLER://192.168.0.64:90931.3 自启动
创建 /etc/systemd/system/kafka.service
bash
[Unit]
Description=Apache Kafka Server
Documentation=http://kafka.apache.org/documentation.html
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
Group=kafka
ExecStart=/bin/bash -c 'source /etc/profile && /WORK/MIDDLEWARE/kafka/4.0/bin/kafka-server-start.sh /WORK/MIDDLEWARE/kafka/4.0/config/server.properties'
ExecStop=/bin/bash -c 'source /etc/profile && /WORK/MIDDLEWARE/kafka/4.0/bin/kafka-server-stop.sh'
Restart=on-failure
[Install]
WantedBy=multi-user.target 启用
bash
systemctl daemreload
systemctl enable kafka1.4 创建topic
bash
bin/kafka-topics.sh --create --topic my-test-topic --bootstrap-server localhost:9092
bin/kafka-topics.sh --describe --topic my-test-topic --bootstrap-server localhost:9092描述信息展示如下:
bash
Topic: my-test-topic Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:
Topic: my-test-topic Partition: 1 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:
Topic: my-test-topic Partition: 2 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:
Topic: my-test-topic Partition: 3 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:毕竟我们是学习环境,搭的单机节点,对于每个分区没有做副本。生产环境下,注意把副本分配到不同的节点上
使用参数如下:
bash
--replica-assignment "<partition0>:<brokerA>,<brokerB>,...;<partition1>:<brokerC>,<brokerD>,...;..."
#如:
--replica-assignment "0:1,2;1:2,3;2:1,3解释一下,':'前面的是分区的编号;':'后面是这个分区的数据,分别放到哪个broker下
1.5 安装kafka-ui
bash
cd /WORK/MIDDLEWARE/kafka
mkdir kafka-ui
cd kafka-ui
vim docker-compose.yml编辑docker-compose文件
yml
services:
kafka-ui:
container_name: kafka-ui
image: provectuslabs/kafka-ui:latest
ports:
- 9100:8080
environment:
DYNAMIC_CONFIG_ENABLED: 'true'二、SpringBoot的生产者接入
2.1 pom引用
注意,我这里的indi.zhifa.engine-cloud:common-web-starter是自己写的库,便于快速创建web项目,大家可以去 我的码云 下载
xml
<dependencies>
<dependency>
<groupId>indi.zhifa.engine-cloud</groupId>
<artifactId>common-web-starter</artifactId>
<version>${zhifa-engine.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.1.10</version>
</dependency>
</dependencies>2.2 生产者java核心代码:
service
java
@Slf4j
@Component
public class KafkaSendDataImpl implements IKafkaSendData {
private final KafkaTemplate<String, String> mKafkaTemplate;
private final FastJsonConfig mFastJsonConfig;
public KafkaSendDataImpl(KafkaTemplate<String, String> pKafkaTemplate,
@Qualifier("simple-fastJson-config") FastJsonConfig pFastJsonConfig) {
mKafkaTemplate = pKafkaTemplate;
mFastJsonConfig = pFastJsonConfig;
}
@Override
public void sendAsync(String topic,KafkaData pKafkaData) {
String str = JSON.toJSONString(pKafkaData);
try{
mKafkaTemplate.send(topic,pKafkaData.getName(),str);
}catch (Exception e){
log.error("发送kafka时发成错误,错误信息是"+ e.getMessage());
}
}
}controller
java
@Slf4j
@Validated
@RequiredArgsConstructor
@Tag(name = "生产者")
@ZhiFaRestController
@RequestMapping("/kafka/produce")
public class KafkaProduceController {
final IKafkaSendData mKafkaSendData;
@PostMapping("/{topic}")
public void sendAsync(@PathVariable("topic") String pTopic, @RequestBody KafkaData pKafkaData){
mKafkaSendData.sendAsync(pTopic,pKafkaData);
}
}配置:
yml
server:
# 服务端口
port: 8083
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
group-configs:
- group: "管理接口"
paths-to-match: '/**'
packages-to-scan:
- indi.zhifa.study2025.test.kafka.producer.controller
zhifa:
enum-memo:
enabled: true
enum-packages:
- indi.zhifa.**.enums
uri: /api/enum
web:
enabled: true
spring:
profiles:
active: local
kafka:
bootstrap-servers: 192.168.0.64:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
compression-type: zstd
#0 的时候,吞吐量最高,不管是否成功
#1 leader收到后才响应
#-1 要求所有的follow都写成功
#通常iot项目,日志采集等,该值设为0.仅仅用来解耦时,比如订单处理业务,一般设成all,避免丢失,并且在回调监控。并且会自动开启幂等性。
acks: all
# 重试次数
retries: 3我们创建几条消息,观察现象:
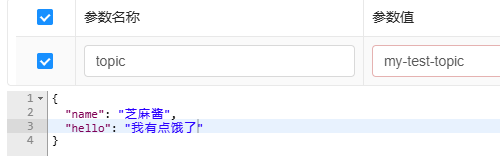
打开swagger-ui,看到确实有消息数量了

2.3 key的作用
额外解释一点,发送时,指定消息的key。kafka默认会把同一个key放在一个partition(分区)中。我这里用name做key,可以保证同一个name的消息被顺序消费。
三、SpringBoot的消费者接入
消费者非常简单,这里略写
3.1 java核心代码
java
@Component
public class KafkaConsumerListener {
private Map<String,Long> mMsgIdx;
public KafkaConsumerListener() {
mMsgIdx = new ConcurrentHashMap<>();
}
@KafkaListener(topics = "my-test-topic", groupId = "my-group")
public void listen(ConsumerRecord<String, String> record) {
String key = record.key(); // 获取消息的 key
String value = record.value(); // 获取消息的 value
String topic = record.topic(); // 获取消息的 topic
int partition = record.partition(); // 获取消息的分区
long offset = record.offset(); // 获取消息的偏移量
long timestamp = record.timestamp(); // 获取消息的时间戳
// 处理消息(这里我们只是打印消息)
System.out.println("Consumed record: ");
System.out.println("Key: " + key);
System.out.println("Value: " + value);
System.out.println("Topic: " + topic);
System.out.println("Partition: " + partition);
System.out.println("Offset: " + offset);
System.out.println("Timestamp: " + timestamp);
if(StringUtils.hasText(key)){
Long idx = mMsgIdx.get(key);
if(idx == null){
idx = 0l;
}
idx = idx + 1;
mMsgIdx.put(key, idx);
System.out.println(key+"的第"+idx+"个消息");
}
}
}3.2 配置
yml
spring:
profiles:
active: local
kafka:
bootstrap-servers: 192.168.0.64:9092
consumer:
group-id: my-group # 消费者组ID
auto-offset-reset: earliest # 消费者从头开始读取(如果没有已提交的偏移量)
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 设置key的反序列化器
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer