🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到: Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下内容:
- Kafka 一致性保证
- LogAndOffset(LEO)
- HightWatermark(HW)
- Leader和Follower何时更新 LEO
- Leader和Follower何时更新 HW

基本介绍
消息重复和丢失是Kafka中很常见的问题,主要发生在以下三个阶段:
- 生产者阶段
- Broke阶段
- 消费者阶段
生产者阶段丢失
出现场景
生产者发送消息没有收到正确Broke的响应,导致生产者重试。 生产者发送出一条消息,Broker落盘以后因为网络等种种原因发送端得到一个发送失败的响应或者网络中断,然后生产者收到一个可恢复的Exception重试消息导致消息重复。
重试过程
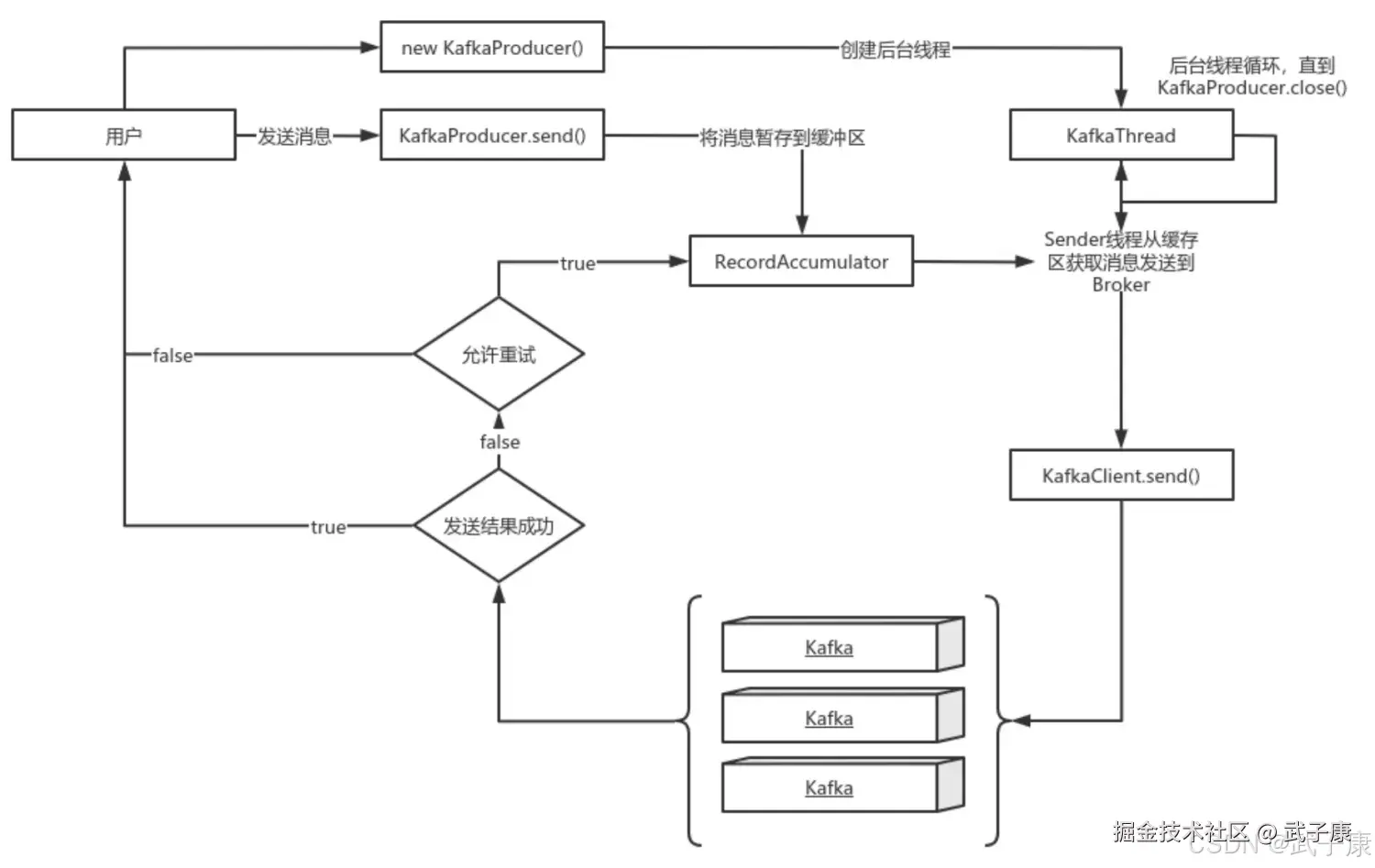 上图说明:
上图说明:
- new KafkaProducer()创建一个后台线程KafkaThread扫描RecordAccumulator中是否有消息
- 调用KafkaProducer.send()发送消息,实际上只是把消息保存到RecordAccumulator中
- 后台线程KafkaThread扫描到RecordAccumulator中有消息后,将消息发送到Kafka集群
- 如果发送成功,那么返回成功
- 如果发送失败,判断是否重试,如果不允许重试则失败。允许重试则再保存到RecordAccumulator中,等待后台线程KafkaThread扫描再次发送
可恢复异常
异常是 RetriableException类型 或者 TransactionManager允许重试,RetriableException类集成关系如下: 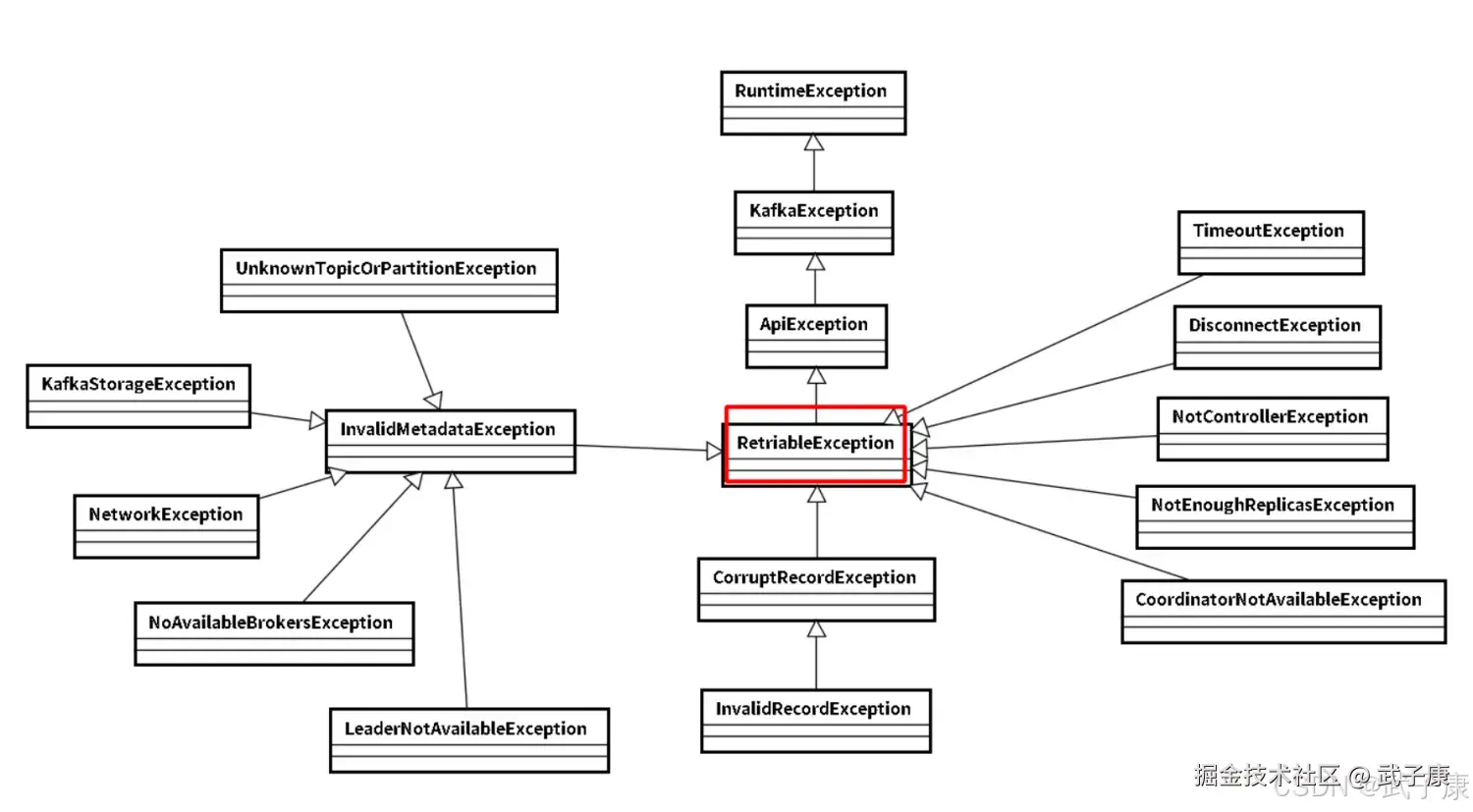
消息顺序问题
- 如果设置max.in.flight.requests.per.connection大于1(默认5,单个连接上发送的未确认的请求的最大数量,表示上一个发出的请求没有确认下一个请求又发出去了)。大于1可能会改变记录的顺序,因为如果将两个Batch发送到单个分区,第一个batch处理失败并重试,但是第二个batch处理成功,那么第二个batch处理中的记录可能先出现被消费掉。
- 如果设置max.in.flight.requests.per.connection等于1,则可能会影响吞吐量,可以解决单个生产者发送顺序问题,如果多个生产者,生产者1先发送一个请求,生产者2后发送请求,此时生产者1返回可恢复异常,且重试成功,此时虽然1先发送,但是2是先被消费的。
解决方案
幂等性
启动Kafka幂等性:
- enable.idempotence=true
- ack=all
- retries>=1
ack=0且不重试
可能会丢失消息,适用于吞吐量指标重要性高于数据丢失,比如:日志采集。
生产者-Broker阶段丢失
出现场景
ack=0且不重试
生产者发送消息完,不管结果了,如果发送失败也就丢失了
ack=1, Leader宕机
生产者发送完消息,只等待Leader写入成功就返回了,Leader分区丢失了,此时Follower没来得及同步,消息丢失。
unclean.leader.election.enable配置为true
允许选举ISR以外的副本作为Leader,会导致数据丢失,默认为False。生产者发送异步消息,只等待Leader写入成功就返回,Leader分区丢失,此时ISR中就没有Follower,Leader从OSR中选举,因为OSR中本来就落后于Leader,造成了消息的丢失。
解决方案
禁用unclean选举 ACK=ALL
- ack=all 或者 -1
- tries > 1
- unclean.leader.election.enable = false 生产者发送完消息后,等待Follower同步完再返回,如果异常则重试。副本的数量可能影响吞吐量,不超过5个,一般是3个。 不允许unclean的Leader参与选举。
min.insync.replicas > 1 详细解析
核心概念
当生产者将 acks 参数设置为 all(或 -1)时,min.insync.replicas 参数用于指定确认消息写入成功所需的最小同步副本数量。如果存活的同步副本数低于这个最小值,生产者将收到以下异常之一:
NotEnoughReplicasException:表示当前没有足够的副本可用NotEnoughReplicasAfterAppendException:表示消息已发送但最终未能达到要求的副本数
参数协同工作原理
这两个参数的组合使用可以增强数据持久性保证:
- 典型配置组合 :
- 创建复制因子(replication factor)为3的主题
- 设置
min.insync.replicas=2 - 生产者配置
acks=all
- 工作流程 :
- 生产者发送消息后,会等待至少2个副本确认写入(包括leader)
- 如果只有1个副本可用(例如2个broker宕机),生产者将收到异常
- 系统会确保大多数副本(2/3)都确认写入后才认为消息提交成功
实际应用场景
-
金融交易系统:
- 需要严格保证交易记录的持久性
- 配置示例:5个副本,
min.insync.replicas=3,可以容忍2个节点故障
-
关键业务日志:
- 在3节点集群中设置
min.insync.replicas=2 - 即使1个节点故障,系统仍能正常接收新消息
- 在3节点集群中设置
-
异常处理建议:
- 捕获
NotEnoughReplicasException后应实现重试机制 - 监控同步副本数量变化,提前发现潜在问题
- 捕获
注意事项
- 该参数需要与
unclean.leader.election.enable=false配合使用 - 过高的设置可能影响可用性(如设置
min.insync.replicas=3,当2个节点故障时将拒绝写入) - 可以通过
kafka-topics.sh --describe命令查看实际同步副本数
失败的offset单独记录
生产者发送消息,会自动重试,遇到不可能恢复异常会跳出。这是可以捕获异常记录到数据库或者缓存,进行单独的处理。
消费者数据重复场景
出现场景
数据消费完没有及时的提交offset到Broker。 消费消息端在消费过程中挂掉没有及时的提交offset到Broker,另一个消费端启动之后拿到之前的offset记录开始消费,由于offset的滞后性可能会导致启动的客户端有少量的重复消费。
解决方案
取消自动提交
每次消费完或者程序退出时手动提交,这可能也没法保证一条重复。
下游做幂等处理方案详解
在分布式消息系统中,确保消息处理的幂等性是保证数据一致性的重要手段。以下是几种常见的下游幂等处理方案及其实现细节:
1. 标准幂等消费模式
- 基本实现:让下游服务自身实现幂等逻辑
- 典型做法:下游系统在数据表中设计唯一约束(如订单ID+处理状态),通过数据库约束来防止重复处理
- 适用场景:订单处理、支付回调等业务场景
- 示例:在订单状态变更时,先检查当前状态是否允许变更,再执行更新
2. Offset记录方案
- 实现方式:消费者为每条处理成功的消息记录offset
- 存储选择 :
- 可存储在Redis等高速缓存中
- 也可持久化到数据库
- 注意事项 :
- 需要确保offset记录和业务处理是原子操作
- 系统重启时能正确恢复offset位置
- 优化建议:可以批量记录offset以提高性能
3. 严格事务方案
- 实现原理:将offset与业务数据放在同一事务中处理
- 技术实现 :
- 使用分布式事务框架(如Seata)
- 或通过本地事务+消息表模式
- 典型架构 :
- 创建业务数据表和offset记录表
- 在同一个事务中:
- 更新业务数据
- 记录当前消费offset
- 适用场景:金融交易、资金变动等对一致性要求极高的场景
4. 乐观锁方案
-
实现步骤 :
- 在下游表中添加version/offset字段
- 处理消息时比较传入offset与记录offset:
- 若新offset更大则处理并更新
- 否则拒绝处理
-
SQL示例 :
sqlUPDATE order_status SET status = 'paid', offset = 12345 WHERE order_id = 'ORD123' AND offset < 12345 -
优势 :
- 避免分布式事务开销
- 实现相对简单
-
注意事项 :
- 需要确保offset是单调递增的
- 要考虑offset字段的存储空间
方案对比
| 方案 | 实现复杂度 | 性能影响 | 一致性保证 | 适用场景 |
|---|---|---|---|---|
| 标准幂等 | 低 | 小 | 最终一致 | 普通业务 |
| Offset记录 | 中 | 中 | 最终一致 | 多数场景 |
| 严格事务 | 高 | 大 | 强一致 | 金融交易 |
| 乐观锁 | 中 | 中 | 最终一致 | 高并发系统 |
在实际应用中,需要根据业务场景的特点选择合适的方案。对于大多数业务场景,采用offset记录+业务幂等的组合方案即可满足需求;只有在极少数严格要求强一致的场景下,才需要考虑分布式事务方案。
__consumer_offsets:Kafka消费者位移管理机制
背景与演进
在早期版本的Kafka中,消费者位移信息是存储在ZooKeeper中的。然而,随着Kafka集群规模的扩大和消息吞吐量的增加,这种设计逐渐暴露出一些问题:
- ZooKeeper的性能瓶颈:ZooKeeper并不适合处理大批量的频繁写入操作,这会影响消费者位移提交的性能
- 扩展性问题:频繁的位移提交会给ZooKeeper带来较大压力,限制了Kafka集群的扩展能力
- 功能限制:基于ZooKeeper的位移管理难以实现更复杂的位移管理功能
__consumer_offsets主题
从Kafka 0.9.0版本开始引入了内置的__consumer_offsets主题,并在Kafka 1.0.2版本中完全移除了对ZooKeeper的依赖。这个特殊的主题具有以下特点:
-
存储机制:
- 采用Kafka本身的存储机制来保存消费者位移
- 默认配置为50个分区(可通过
offsets.topic.num.partitions参数调整) - 采用紧凑压缩策略(compact)来定期清理过期数据
-
性能优势:
- 利用Kafka自身的高吞吐特性处理位移提交
- 批量写入机制显著提高了位移提交的性能
- 与消息处理使用相同的通信协议,减少额外开销
-
数据格式:
- 键(Key):由
group.id、主题名和分区号组成 - 值(Value):包含位移值、元数据和时间戳
- 键(Key):由
管理与监控工具
Kafka提供了kafka-consumer-groups.sh脚本(位于bin目录下)来管理消费者组和位移信息:
常用命令示例
- 查看所有消费者组:
bash
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list- 查看特定消费者组的详细信息:
bash
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --describe- 重置消费者位移(需要先停止消费者):
bash
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --topic my-topic --reset-offsets --to-earliest --execute输出解读
执行describe命令后,输出通常包含以下列:
- TOPIC:主题名称
- PARTITION:分区号
- CURRENT-OFFSET:消费者当前消费到的位移
- LOG-END-OFFSET:分区最新消息的位移
- LAG:未消费的消息数量(LOG-END-OFFSET - CURRENT-OFFSET)
- CONSUMER-ID:消费者ID
- HOST:消费者客户端主机信息
实际应用场景
- 监控消费者延迟:通过定期检查LAG值来监控消费者健康状况
- 故障恢复:在消费者故障时,可以手动重置位移到指定位置
- 重新处理数据:通过修改位移值实现历史数据的重新处理
- 测试验证:在测试环境中快速重置消费者状态
配置参数
与__consumer_offsets相关的几个重要配置参数:
offsets.retention.minutes:位移保留时间(默认1440分钟/24小时)offsets.topic.replication.factor:位移主题的副本数(建议≥2)offsets.commit.timeout.ms:位移提交超时时间(默认5000ms)offsets.topic.num.partitions:位移主题分区数(默认50)
注意事项
- 直接操作
__consumer_offsets主题可能导致数据不一致,应优先使用官方工具 - 消费者组在长时间无活动后,其位移信息可能被自动清理
- 在高安全要求的集群中,应限制对
__consumer_offsets主题的访问权限