本文我们将尝试使用tesseract识别电子发票上的信息并不断提高识别准确率,是一个逐渐调整的过程,仅用于记录研究过程。
- 图像识别:使用tesseract识别。
- 图像预处理:使用OpenCV等图像处理库对发票图像进行预处理,如灰度化、去噪、二值化等,以提高文字清晰度。
- 语言和数据集定制:根据具体需求训练Tesseract使用特定语言和数据集,特别是对于包含大量特定格式和术语的电子发票。
目录
[1. 基于tesseract识别电子发票](#1. 基于tesseract识别电子发票)
[2. 借助OpenCV对图像进行预处理](#2. 借助OpenCV对图像进行预处理)
[2.1 读取图像](#2.1 读取图像)
[2.2 转换为灰度图像](#2.2 转换为灰度图像)
[2.3 高斯模糊降噪](#2.3 高斯模糊降噪)
[2.4 二值化处理](#2.4 二值化处理)
[2.5 Opencv预处理代码与调优批处理](#2.5 Opencv预处理代码与调优[批处理])
[2.5.1 完整代码](#2.5.1 完整代码)
[2.5.2 调整后批处理代码](#2.5.2 调整后批处理代码)
1. 基于tesseract识别电子发票
tesseract安装参考:Tesseract OCR 的使用
确认安装成功:
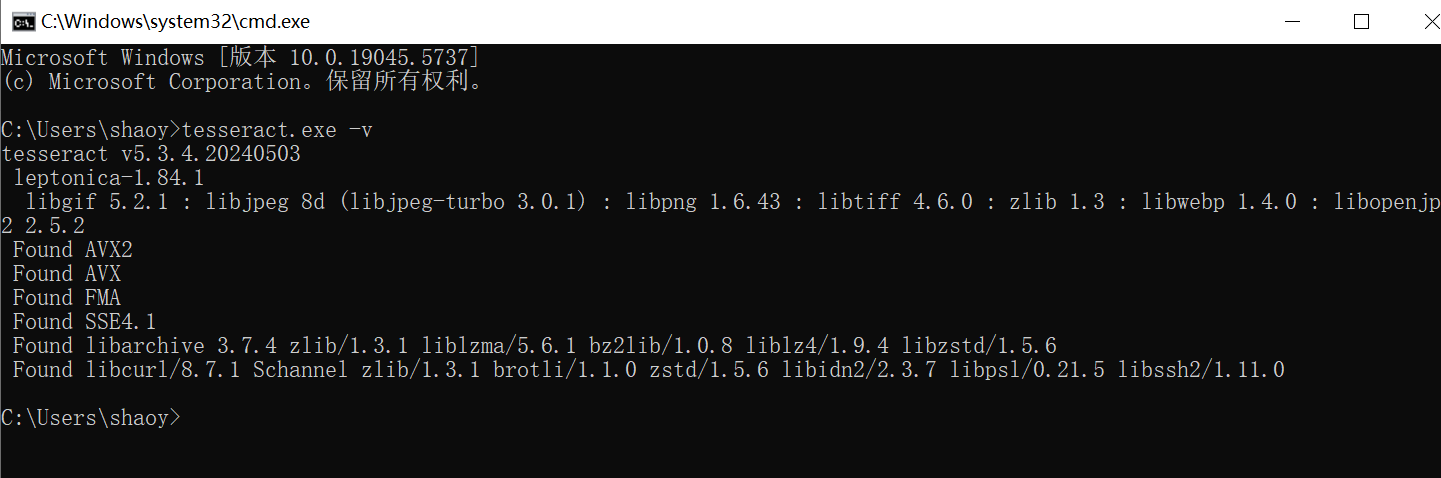
tesseract 命令行识别命令参考:tesseract 图片路径 识别结果 -l 使用的字符集
bash
tesseract 0008.jpg result -l chi_sim- 0008.jpg 是需要识别的图片
- result 是识别结果,识别完成后生成result.txt
- chi_sim 是我们使用的识别库,基于chi_sim.traineddata识别,横排汉字
识别参考:

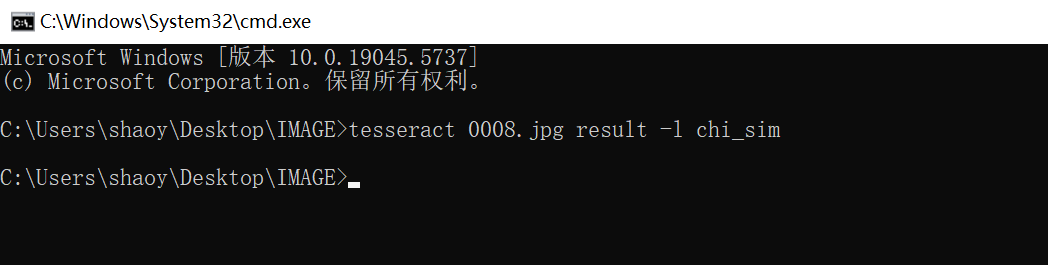
识别结果部分如下:

2. 借助OpenCV对图像进行预处理
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库,它包含了大量的图像处理和计算机视觉算法。OpenCV最初由英特尔公司于1999年发起,现在由多个组织维护,包括Willow Garage和Intel。它旨在推动计算机视觉领域的实时应用,是一个跨平台的开源库,支持多种编程语言,如C、C++、Python、Ruby和Java。
2.1 读取图像
使用cv2.imread()函数读取发票图片。
python
import cv2
# 读取图像
img = cv2.imread("0001.jpg")判断图像获取是否成功,成功获取则打开图片查看
python
#检查图片是否成功读取
if img is None:
print("图片读取失败,请检查路径是否正确!")
else:
# 显示图片
cv2.imshow('图片', img)
# 等待用户按键,0表示无限等待,直到用户按下任意键
cv2.waitKey(0)
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()图片太大的问题,可以提前增加命令,调整窗口大小
python
# 调整窗口大小
cv2.namedWindow('图片', cv2.WINDOW_NORMAL)
cv2.resizeWindow('图片', 800, 600)2.2 转换为灰度图像
将彩色图像转换为灰度图像,不仅简化了图像信息,还增强了文字的对比度,使得后续文字识别更加高效和准确。
python
# 转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)cvtColor()方法是OpenCV库中用于图像颜色空间转换的函数,它支持多种颜色空间的相互转换,如BGR到灰度图、BGR到HSV等。cv2.cvtColor(img, cv2.COLOR_BGR2GRAY),使用cvtColor()方法将图片img从BGR颜色空间转换为了灰度图。
2.3 高斯模糊降噪
使用高斯模糊来减少图像中的噪声。使用高斯降噪的原因:消除噪声对OCR的干扰,平衡去噪与边缘保留。
例如,发票上的细小划痕或墨点经高斯滤波后,会被均匀分散为低强度信号,减少对文字特征的干扰。
python
# 高斯模糊降噪
blurred = cv2.GaussianBlur(gray, (5, 5), 0)2.4 二值化处理
将图像转换为二值图像,以便于字符分割和识别。
二值化处理的核心优势在于:(1)增强文字与背景对比度,通过将彩色或灰度图像转换为黑白二值图像,可显著提升文字区域与背景的区分度。(2)降低计算复杂度,二值化将像素值简化为0(黑)和255(白),相比原始RGB图像的每个像素24位数据量,存储和处理效率提升约24倍。(3)提升特征提取精度,黑白分明的图像结构更有利于关键区域的定位与分割。
python
# 二值化处理
binary = cv2.threshold(blurred, 127, 255, cv2.THRESH_BINARY)2.5 Opencv预处理代码与调优批处理
2.5.1 完整代码
python
import cv2
# 读取图像
img = cv2.imread("0080.jpg")
# 调整窗口大小
cv2.namedWindow('图片', cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO)
cv2.resizeWindow('图片', 800, 600)
# 转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 高斯模糊降噪
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 二值化处理
_,binary = cv2.threshold(blurred, 180, 255, cv2.THRESH_BINARY)
#_,binary = cv2.threshold(blurred, 180, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C)
# 输出图片
cv2.imshow('图片', rotated)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('output.bmp', rotated)2.5.2 调整后批处理代码
python
import cv2
import os
def process_images(input_folder, output_folder):
# 创建输出文件夹(若不存在)
os.makedirs(output_folder, exist_ok=True)
# 获取所有图片文件
valid_ext = ('.jpg', '.jpeg', '.png', '.bmp')
image_files = [f for f in os.listdir(input_folder)
if f.lower().endswith(valid_ext)]
for filename in image_files:
# 读取原始图片
img_path = os.path.join(input_folder, filename)
image = cv2.imread(img_path)
if image is not None:
try:
# 图像处理示例(可根据需求修改)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
_,binary = cv2.threshold(blurred, 180, 255, cv2.THRESH_BINARY)
# 构建输出路径
base_name = os.path.splitext(filename)[0]
output_path = os.path.join(output_folder, f"{base_name}.jpg")
# 保存处理结果
if cv2.imwrite(output_path, binary):
print(f"成功保存: {output_path}")
else:
print(f"保存失败: {filename}")
except Exception as e:
print(f"处理异常 {filename}: {str(e)}")
else:
print(f"读取失败: {filename}")
if __name__ == "__main__":
input_dir = "input" # 输入图片文件夹
output_dir = "output" # 输出文件夹
process_images(input_dir, output_dir)测试成果:部分图片预处理之前识别不到发票号,预处理之后可以识别发票号。
发现问题:部分图片识别到的发票号码会有乱码的情况。