11.15
连接符
python
name='mcl'
print('我叫',name)
print('我叫'+name)#连接符
age=18
print('我叫'+name+'年龄'+str(age))
#连接符需要数据类型相同11.17随记
除法运算神奇
python
8/5 #1.6
8//5 #1
-8/5 #-1.6
-8//5 #-2##次方表示---两个**
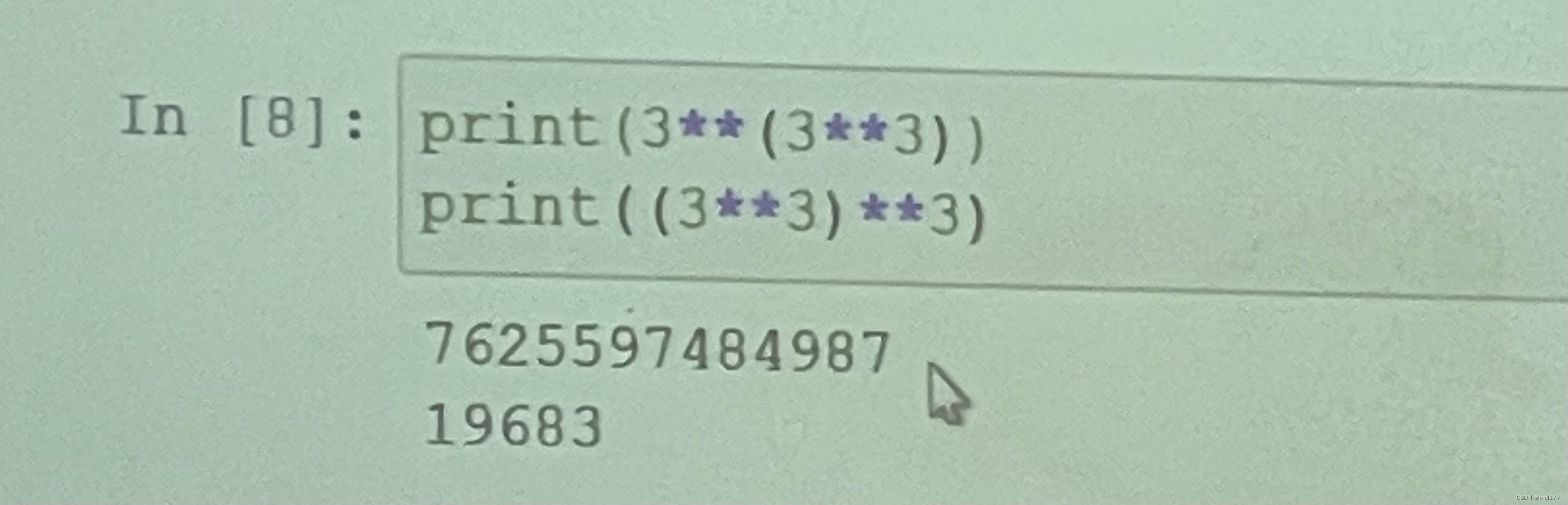
3的27次方
27的3次方
小结
程序的书写,包括代码缩进、注释、语句续行、关键字区分大小写等
内容
Python的数值类型数据和字符类型数据
Python的运算符包括算术运算符、比较运算符、逻辑运算符、赋值运算符等
Python不要求在使用变量之前声明其数据类型,但数据集类型决定了数的存储和操作的方式不同
3个函数:bool(),type(),len()
12.8随记
二分查找法
python
#ex0518.py
list1 = [1,42,3,-7,8,9,-10,5]
#二分查找要求查找的序列时有序的,假设是升序列表
list1.sort()
print(list1)
find=eval(input("请输入要查看的数据:"))
low = 0
high = len(list1)-1
flag=False
while low <= high :
mid = int((low + high) / 2)
if list1[mid] == find :
flag=True
break
#左半边
elif list1[mid] > find :
high = mid -1
#右半边
else :
low = mid + 1
if flag==True:
print("您查找的数据{},是第{}个元素".format(find,mid+1))
else:
print("没有您要查找的数据")统计单词出现的次数
python
#ex0517.py
sentence='Beautiful is better than ugly.Explicit is better than implicit.\
Simple is better than complex.Complex is better than complicated.'
#将文本中涉及标点用空格替换
for ch in ",.?!":
sentence=sentence.replace(ch," ")
#利用字典统计词频
words=sentence.split()
map1={}
for word in words:
if word in map1:
map1[word]+=1
else:
map1[word]=1
#对统计结果排序
items=list(map1.items())
items.sort(key=lambda x:x[1],reverse=True)
#打印控制
for item in items:
word,count=item
print("{:<12}{:>5}".format(word,count))12.13随记
6.1函数的定义和调用

python
def getarea(x,y):
return x*y
print(getarea(3,2))
print(getarea("hello",2))
函数嵌套调用
python
def sum(n):
def fact(a):
t = 1
for i in range(1,a+1):
t*=i
return t
s = 0
for i in range(1,n+1):
s+=fact(i)
return s
n = 5
print("{}以内的阶乘之和为{}".format(n,sum(n)))
6.2函数的参数和返回值

python
def getscore(pe,eng,math,phy,chem):
return pe*0.5+eng*1+math*1.2+phy*1+chem*1
getscore(93,89,78,89,72) #按位置传递
getscore(pe=93,math=78,chem=72,eng=89,phy=89) #赋值传递 直接指定
参数数据类型:数值型 字符串型
组合数据类型:列表 元组 字典 集合 #传递地址
数值型
python
a = 10
def func(num):
num += 1
print("形参的地址 {}".format(id(num)))
print("形参的值 {}".format(num))
a = 1
func(a)
a,id(a)组合数据类型
python
tup =(1,5,7,8,12,9)
ls = []
def getOdd(tup1,ls1):
for i in tup1:
if i%2:
ls1.append(i)
return ls1
getOdd(tup,ls)
print(ls)
python
#ex0608.py
def showmessage(name,age=18):
"打印任何传入的字符串"
print ("姓名: ",name)
print ("年龄: ",age)
return
#调用showmessage函数
showmessage(age=19,name="Kate" )
print ("------------------------")
showmessage(name="John")
python
#program0510.py
def showmessage(name,*p_info,**scores):
print ("姓名: ",name)
for e in p_info:
print(e,end=" ")
for item in scores.items():
print(item,end=" ")
print()
return
#调用showmessage函数
showmessage("Kate","male",18,"Dalian");
print("------------------------------")
showmessage("Kate","male",18,"Dalian",math=86,pe=92,eng=88)
python
def compare( arg1, arg2 ):
result = arg1 >arg2
return result # 函数体内result值
btest= compare(10,9.99) # 调用sum函数
print ("函数的返回值: ",btest)
python
#ex0612.py
def findwords(sentence):
"统计参数中含有字符e的单词,保存到列表中,并返回"
result=[]
words=sentence.split()
for word in words:
if word.find("e")!=-1:
result.append(word)
return result
ss="Return the lowest index in S where substring sub is found,"
print(findwords(ss))12.15

闭包


python
print("okllll");
print("终于好了 姐要吐了")
def getarea(x,y):
return x*y
print(getarea(3,2))
print(getarea("hello",2)乱七八糟
python
#判断奇偶
def isodd(x):
if type(x) != int:
print("{}不是整数,退出程序!".format(x))
return
elif x%2==0:
print("{}is even!".format(x))
return False
elif x%2==1:
print("{}is odd!".format(x))
return True
print(isodd(1))
print(isodd(2))
a=[1,2,3]
print(isodd(a))练习
编写函数,计算某班级学生考试的平均分。
要求:
(1)班级共 10 人,计算平均分时可以根据全部人数或者实际参加考试人数计算。
(2)完成 avgScore()函数。
提示:
(1)定义函数 avgScore()时,参数 n 为默认参数,其默认值为 10。在调用函数 avgScore() 时,如果没有传入 n 的实参,则 n 取默认值;如果传入 n 的实参,则函数会使用传递给 n 的新值。
(2)函数 avgScore()用于计算考试成绩的平均分,接收列表类型的参数 scores。
12.20
python文件操作
主要考虑文件的读写

文件的打开和关闭


rb二进制读模式,wb二进制写模式

python文件读写的常用方法
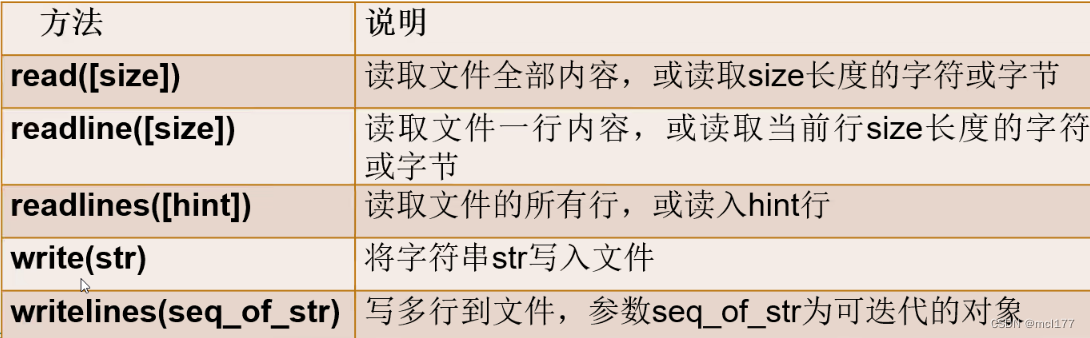
read
python
f=open("test.txt","r")
str1=f.read(13)
print(str1)
str2=f.read()
print(str2)
f.close()程序和文件需要放在同一个文件夹
python
#ex0903.py
f=open("test.txt","r")
flist=f.readlines() # flist是包含文件内容的列表
print(flist)
for line in flist:
print(line) #使用print(line,end="")将不显示文件中的空行。
f.close()
python
#ex0904.py
f=open("test.txt","r")
str1=f.readline()
while str1!="": #判断文件是否结束
print(str1)
str1=f.readline()
f.close()write
python
fname = input("请输入追加数据的文件名:")
f1 = open(fname,"w+")
f1.write("向文件中写入字符串\n")
f1.write("继续写入")
f1.close()跟指针相关,tell,seek

python
file = open("d:\\shiyan\\test.txt","r+")
str1 = file.read(6)
str1
file.tell()
file.readline()
file.tell()
file.readlines()
file.tell()
file.close()
python
file = open("d:\\shiyan\\test.txt","r+")
file.seek(6)
str1 = file.read(8)
str1
file.tell()
file.seek(6)
file.write("@@@@@@@")
file.seek(0)
file.readline()
python
#以'wb'方式打开二进制文件
fileb = open(r"d:\\shiyan\\mydata.dat","wb")
fileb.write(b"Hello Python")
n = 123
fileb.write(bytes(str(n),encoding='utf-8'))
fileb.write(b"\n3.14")
fileb.close()
#以'rb'方式打开二进制文件
file = open(r"d:\\shiyan\\mydata.dat","rb")
print(file.read())
file.close()
#以'r'方式打开二进制文件
filec = open(r"d:\\shiyan\\mydata.dat","r")
print(filec.read())
filec.close()12.27随记
python
#ex0911.py
lst1 = ["read","write","tell","seek"]
dict1 = {"type1":"TextFile","type2":"BinaryFile"}
fileb = open(r"d:\\shiyan\\mydata.dat","wb")
#写入数据
import pickle
pickle.dump(lst1,fileb)
pickle.dump(dict1,fileb)
fileb.close()
#读取数据
fileb = open(r"d:\\shiyan\\mydata.dat","rb")
fileb.read()
fileb.seek(0)
x = pickle.load(fileb)
y = pickle.load(fileb)
x,y
fileb.close()
#ex0912.py
import shutil
shutil.copyfile("d:\\shiyan\\test.txt","d:\\shiyan\\testb.py")
#ex0913.py
import os,os.path
fname = input("请输入需要删除的文件名:")
if os.path.exists(fname):
os.remove(fname)
else:
print("{}文件不存在".format(fname))
python
#program0714.py
import os,os.path,sys
fname=input("请输入需要更名的文件:")
gname=input("请输入更名后的文件名:")
if not os.path.exists(fname):
print("{}文件不存在".format(fname))
sys.exit(0)
elif os.path.exists(gname):
print("{}文件已存在".format(gname))
sys.exit(0)
else:
os.rename(fname,gname)
print("rename success")
python
#ex0915.py
import os
os.getcwd()
os.listdir()
os.mkdir('myforder')
os.removedirs('yourforder\f1\f2')
os.makedirs('aforder\\ff1\\ff2')
import shutil
shutil.rmtree('yourforder')
python
#ex0916.py
# 向CSV文件中写入一维数据并读取
lst1 = ["name","age","school","address"]
filew= open('d:\\shiyan\\asheet.csv','w')
filew.write(",".join(lst1))
filew.close()
filer= open('d:\\shiyan\\asheet.csv','r')
line=filer.read()
print(line)
filer.close()
python
#ex0917.py
# 使用内置csv模块写入和读取二维数据
datas = [['Name', 'DEP', 'Eng','Math', 'Chinese'],
['Rose', '法学', 89, 78, 65],
['Mike', '历史', 56,'', 44],
['John', '数学', 45, 65, 67]
]
import csv
filename = 'd:\\shiyan\\bsheet.csv'
with open(filename, 'w',newline="") as f:
writer = csv.writer(f)
for row in datas:
writer.writerow(row)
ls=[]
with open(filename,'r') as f:
reader = csv.reader(f)
#print(reader)
for row in reader:
print(reader.line_num, row) # 行号从1开始
ls.append(row)
print(ls)
python
#ex0919.py
filename=input("请输入要添加行号的文件名:")
filename2=input("请输入新生成的文件名:")
sourcefile=open(filename,'r',encoding="utf-8")
targetfile=open(filename2,'w',encoding="utf-8")
linenumber=""
for (num,value) in enumerate(sourcefile):
if num<9:
linenumber='0'+str(num+1)
else:
linenumber=str(num+1)
str1=linenumber+" "+value
print(str1)
targetfile.write(str1)
sourcefile.close()
targetfile.close()
python
#ex0920.py
from datetime import datetime
filename=input("请输入日志文件名:")
file=open(filename,'a')
print("请输入日志,exit结束")
s=input("log:")
while s.lower()!="exit":
file.write("\n"+s)
file.write("\n----------------------\n")
file.flush()
s=input("log:")
file.write("\n====="+str(datetime.now())+"=====\n")
file.close()
12.29 模块和库编程
python
from datetime import datetime
aday = datetime.now()
aday
print(aday)
dt1 = datetime(2021,9,10,13,59)
dt1
type(dt1)
print("当前时间是{}:{}:{}".format(dt1.hour,dt1.minute,dt1.second))筛选key words
python
# program0617.py
'''
使用jieba库分解中文文本,并使用字典实现词频统计
'''
# encoding=utf-8
import jieba
# read need analyse file
article = open("shuihu70.txt",encoding='utf-8').read()
words = jieba.lcut(article)
# count word freq
word_freq = {}
for word in words:
if len(word)==1:
continue
else:
word_freq[word]= word_freq.get(word,0)+1
# sorted
freq_word = []
for word, freq in word_freq.items():
freq_word.append((word, freq))
freq_word.sort(key = lambda x:x[1], reverse=True)
max_number = eval(input("显示前多少位高频词? "))
# display
for word, freq in freq_word[:max_number]:
print(word, freq)
python
# program0618.py
'''
使用jieba库分解中文文本,并使用字典实现词频统计,统计结果中排除
部分单词,被排除单词保存在文件stopwords.txt中
'''
import jieba
stopwords = [line.strip() for line in open('stopwords.txt', 'r', \
encoding='utf-8').readlines()]
# add extra stopword
stopwords.append('')
# read need analyse file
article = open("sanguo60.txt",encoding='utf-8').read()
words = jieba.cut(article, cut_all = False)
# count word freq
word_freq = {}
for word in words:
if (word in stopwords) or len(word)==1:
continue
if word in word_freq:
word_freq[word] += 1
else:
word_freq[word] = 1
# sorted
freq_word = []
for word, freq in word_freq.items():
freq_word.append((word, freq))
freq_word.sort(key = lambda x:x[1], reverse=True)
max_number = eval(input("需要前多少位高频词? "))
# display
for word, freq in freq_word[:max_number]:
print(word, freq)
python
# program0619.py
'''
使用jieba库分解中文文本,并使用字典实现词频统计,统计结果中排除
部分单词,被排除单词保存在文件stopwords.txt中,合并了部分同义词
'''
import jieba
stopwords=[line.strip() for line in open('stopwords.txt',\
encoding='utf-8').readlines()]
# add extra stopword
stopwords.append('')
# read need analyse file
article = open("sanguo60.txt",encoding='utf-8').read()
words = jieba.lcut(article)
# count word freq
word_freq = {}
for word in words:
if (word in stopwords) or len(word)==1:
continue
elif word=='玄德' or word=='玄德曰':
newword='刘备'
elif word=='关公' or word=='云长':
newword='关羽'
elif word=='丞相':
newword='曹操'
elif word=='孔明' or word=='孔明曰':
newword='诸葛亮'
else:
newword=word
if newword in word_freq:
word_freq[newword] += 1
else:
word_freq[newword] = 1
# sorted
freq_word = []
for word, freq in word_freq.items():
freq_word.append((word, freq))
freq_word.sort(key = lambda x:x[1], reverse=True)
max_number = eval(input("需要前多少位高频词? "))
# display
for word, freq in freq_word[:max_number]:
print(word, freq)