文章目录
- 一、前言:AI算力革命与蓝耘元生代的崛起
- 二、蓝耘元生代智算云核心架构解析
-
- [2.1 技术基石:Kubernetes原生云与蜂巢式资源网络](#2.1 技术基石:Kubernetes原生云与蜂巢式资源网络)
- [2.2 核心功能模块](#2.2 核心功能模块)
- 三、蓝耘元生代快速入门指南
-
- [3.1 注册与资源申请](#3.1 注册与资源申请)
- [3.2 实战案例:部署DeepSeek-R1大模型](#3.2 实战案例:部署DeepSeek-R1大模型)
- [3.3 平台特色](#3.3 平台特色)
- [四、横向对比:蓝耘 vs. 主流AI云平台](#四、横向对比:蓝耘 vs. 主流AI云平台)
-
- [4.1 计算性能与成本](#4.1 计算性能与成本)
- [4.2 生态适配性](#4.2 生态适配性)
- [4.3 服务模式创新](#4.3 服务模式创新)
- 五、未来展望:蓝耘的挑战与机遇
- 六、结语:为什么选择蓝耘元生代?
一、前言:AI算力革命与蓝耘元生代的崛起
在人工智能技术高速发展的今天,算力已成为驱动AI创新的核心引擎。然而,传统云计算模式的高成本、低资源利用率及复杂部署流程,使得许多企业与开发者面临巨大挑战。蓝耘元生代智算云(以下简称"蓝耘")凭借其创新的异构算力调度 、弹性资源管理 和一站式AI开发平台,正逐步改写行业规则,成为AI算力服务的新标杆。
本文将深入探讨蓝耘的核心技术优势,并提供详细的快速入门指南,同时从计算性能、生态适配、服务模式三个维度,对比分析其与主流AI云平台的差异,帮助开发者与企业精准选择最适合的AI基础设施。
二、蓝耘元生代智算云核心架构解析
2.1 技术基石:Kubernetes原生云与蜂巢式资源网络
蓝耘采用Kubernetes原生云架构 ,实现计算资源的动态编排,支持裸金属服务器与容器化部署双模式,满足不同场景需求。其独创的蜂巢式资源网络通过强化学习算法优化GPU/CPU/TPU的协同调度,使算力利用率提升至95%以上,远超传统虚拟化方案的70%上限。
关键创新点:
- NUMA亲和性调度:减少CPU-GPU数据传输延迟,提升大模型训练效率。
- RDMA网络优化:动态调整通信协议,降低分布式训练中的跨节点延迟。
- 混合精度训练加速:自动切换FP16/FP32计算,提速30%。
2.2 核心功能模块
| 模块 | 核心能力 | 典型应用场景 |
|---|---|---|
| 智算调度 | 裸金属/容器混合部署,支持秒级扩容 | 千亿参数LLM训练、实时渲染 |
| 应用市场 | 预集成Stable Diffusion、YOLOv8等AI工具,一键部署 | AIGC内容生成、目标检测 |
| AI协作 | 团队开发环境统一管理,支持代码/数据/模型版本控制 | 多团队协同AI研发 |
三、蓝耘元生代快速入门指南
3.1 注册与资源申请
进入下面的...
注册链接:https://cloud.lanyun.net/#/registerPage?promoterCode=5b9e82cbb1

注册之后,我们就可以来到主页面了

这样我们就完成平台的注册了
- 企业认证(推荐):提交营业执照等信息,解锁私有化部署等高阶功能(看个人或企业选择)。
- 实例创建 :
- 选择镜像(如PyTorch框架)
- 配置GPU型号(V100/A100等等...)、内存(建议≥64GB)
- 按需选择计费模式
3.2 实战案例:部署DeepSeek-R1大模型
python
# 示例:通过OpenAI兼容接口调用DeepSeek-R1
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://maas-api.lanyun.net/v1"
)
response = client.chat.completions.create(
model="/maas/deepseek-ai/DeepSeek-R1",
messages=[{"role": "user", "content": "解释强化学习的核心原理"}]
)
print(response.choices[0].message.content) 这里若你有其他的想调用的模型可以参考官方文档
可以看到下面提供了一些必要的参数,官方还是十分用心的
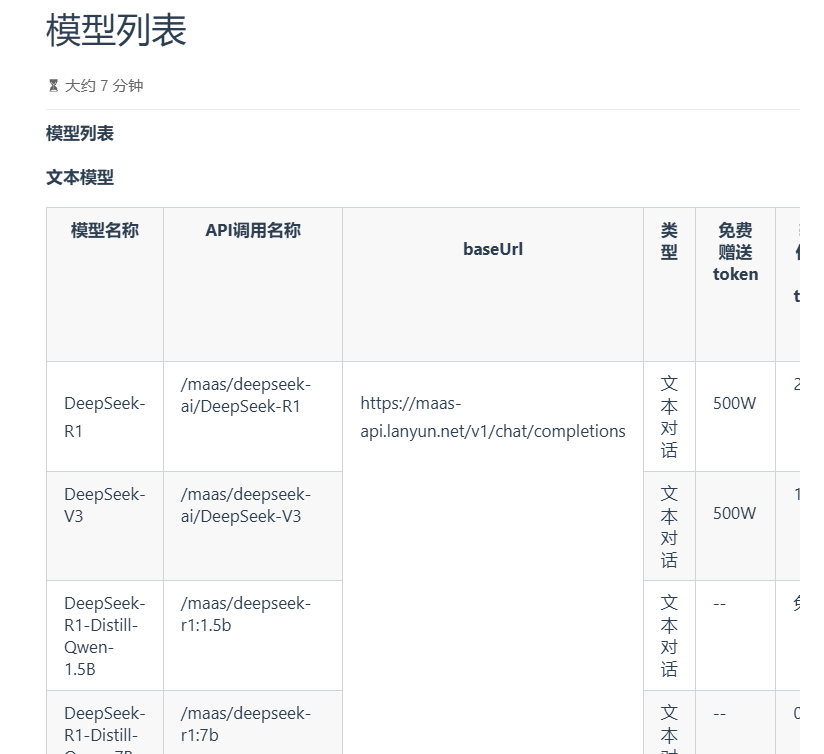
3.3 平台特色
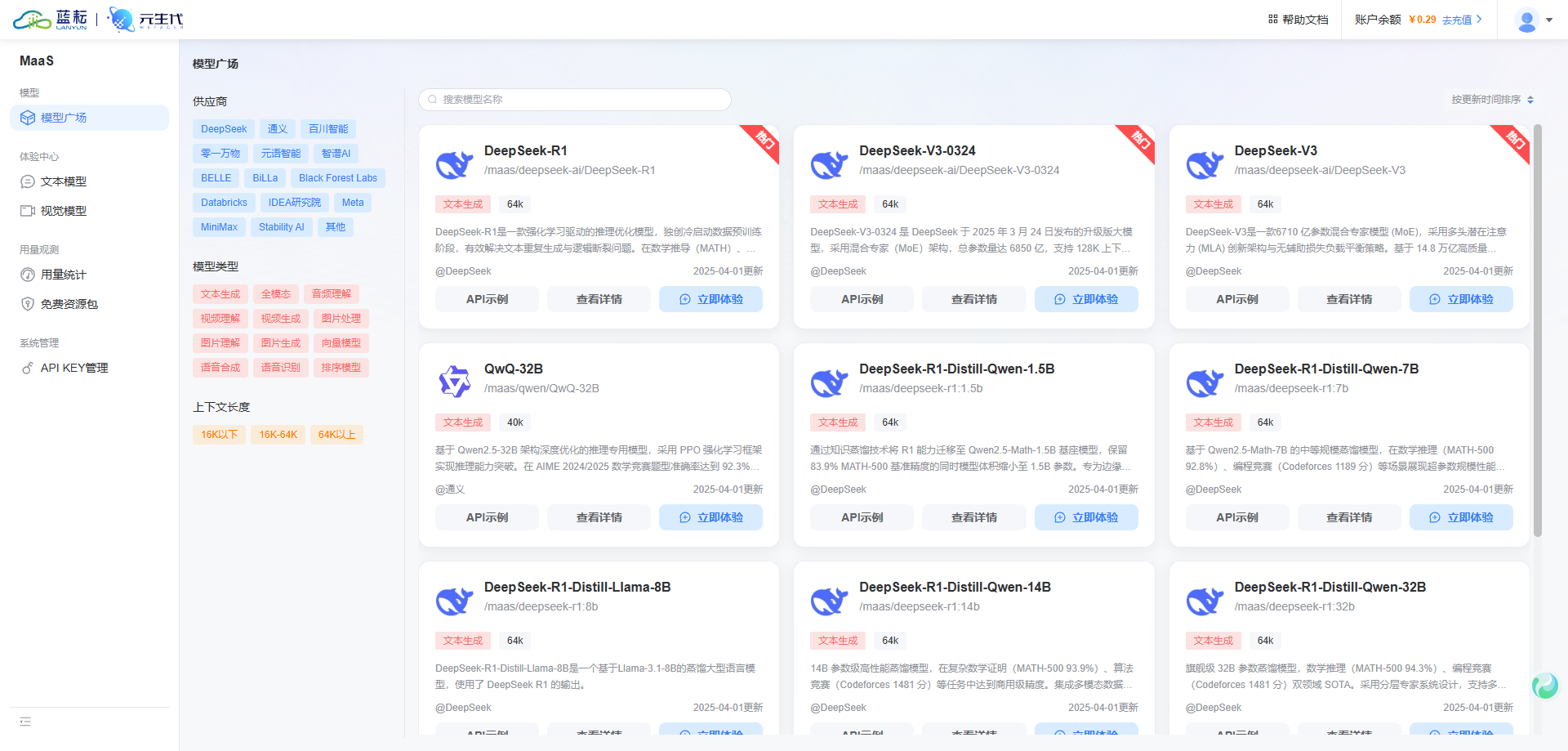
平台不光只有大量的GPU供你使用,同时还具备大模型MaaS平台,这里面提供了丰富的大模型
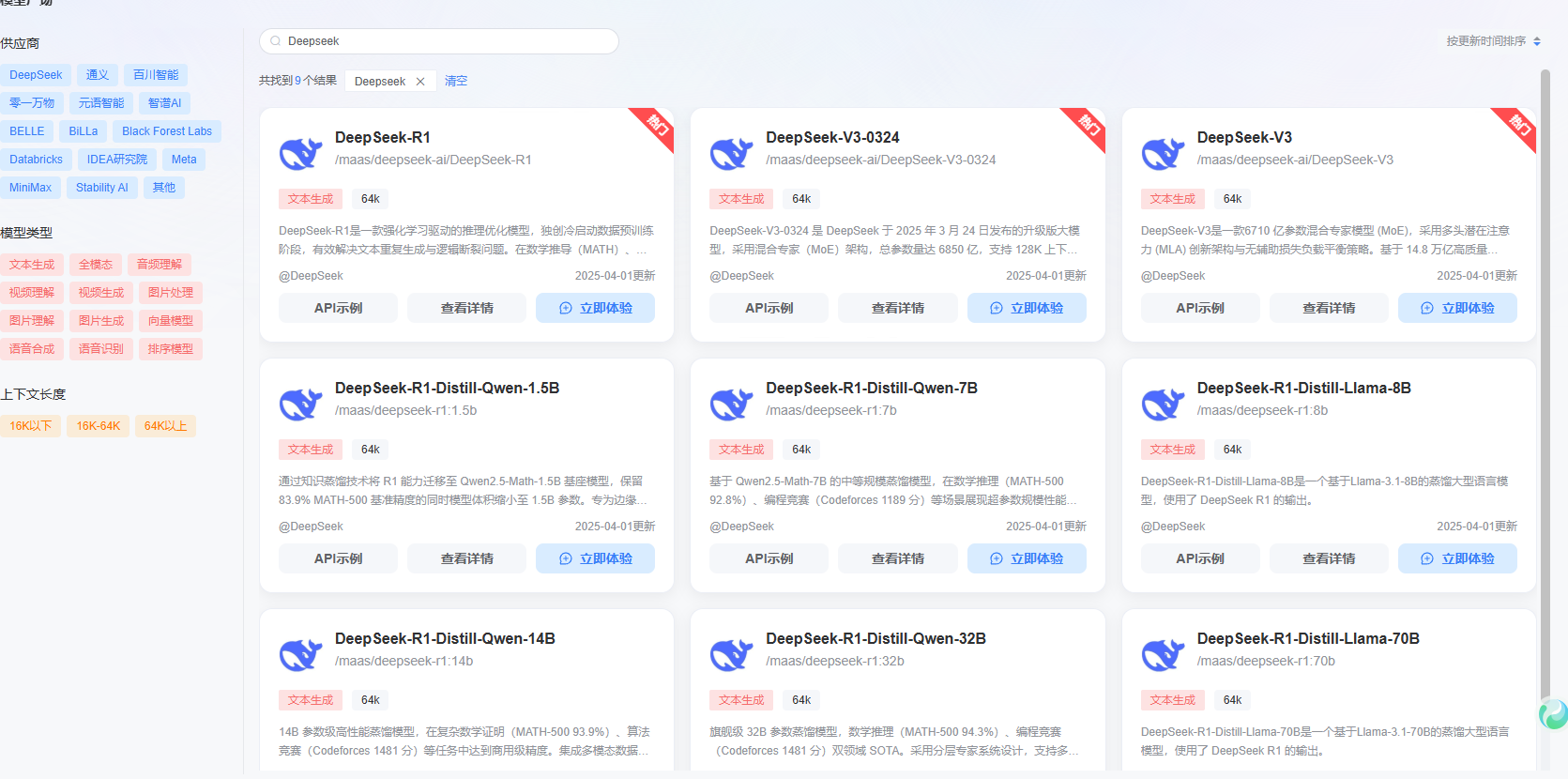
如果你想了解体验测试一下Deepseek,只需要搜一下就可以发现平台包含了若干个选择
在平台的左侧也包含了一些功能
文本模型、视觉模型
同时可以在左侧实时查看使用了多少Token
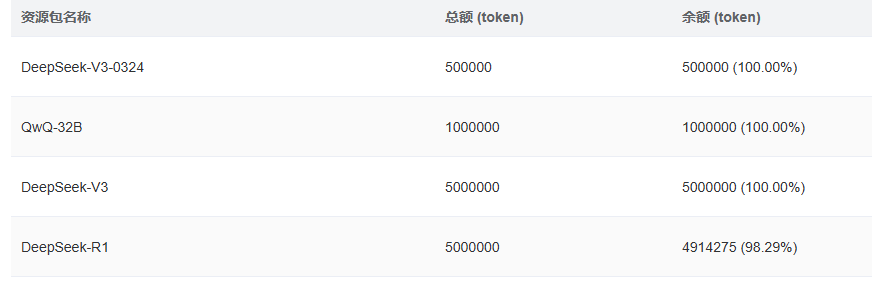
若有开发需要的小伙伴,也可以在功能栏的最后自行创建API KEY,这样就可以自行调用模型了
四、横向对比:蓝耘 vs. 主流AI云平台
4.1 计算性能与成本
| 指标 | 蓝耘元生代 | 行业平均水平 |
|---|---|---|
| GPU利用率 | 95%(裸金属直通) | 60-70%(虚拟化损耗) |
| 训练加速 | FP16自动优化+RDMA调优,提速38% | 依赖手动配置,加速约20% |
| 计费模式 | 按token/小时,闲置资源自动回收 | 预付费包月为主 |
数据来源:蓝耘技术白皮书与第三方测试报告
4.2 生态适配性
-
多模态支持:除DeepSeek外,集成Llama、ChatGLM等主流模型,覆盖文本/图像/音视频处理6。
-
OpenAI兼容API:现有代码可无缝迁移,降低切换成本5。
-
私有化部署:满足金融、军工等高安全需求场景10。
4.3 服务模式创新
-
算力共享经济:企业可出租闲置GPU,获得额外收益(案例:某高校年增收15万元)10。
-
全链路监控:实时追踪GPU温度、任务损失函数,优化资源使用10。
五、未来展望:蓝耘的挑战与机遇
尽管蓝耘在异构算力调度和成本控制上表现突出,但仍面临:
-
巨头竞争:需持续优化体验以应对AWS SageMaker等成熟平台10
-
技术深化:进一步提升超长上下文(100万tokens+)的支持能力
-
市场教育:向非技术用户普及"动态算力调度"的价值10
六、结语:为什么选择蓝耘元生代?
对于中小团队,蓝耘的按需计费和500万免费额度大幅降低试错成本;对于大型企业,其私有化部署和资源纳管能力保障数据安全与资产复用。在AI算力日益成为战略资源的今天,蓝耘正以技术民主化和绿色计算的理念,推动行业向更高效、更公平的方向演进。感兴趣的小伙伴可以了解体验一下~
注册链接:https://cloud.lanyun.net/#/registerPage?promoterCode=5b9e82cbb1
