缓存设计模式是优化系统性能、降低数据库负载的重要手段,以下是常见的缓存设计模式及其核心逻辑:
一、Cache-Aside(旁路缓存)
核心思想 :应用直接管理缓存与数据库的交互
适用场景:读多写少(如商品详情页)
读操作流程
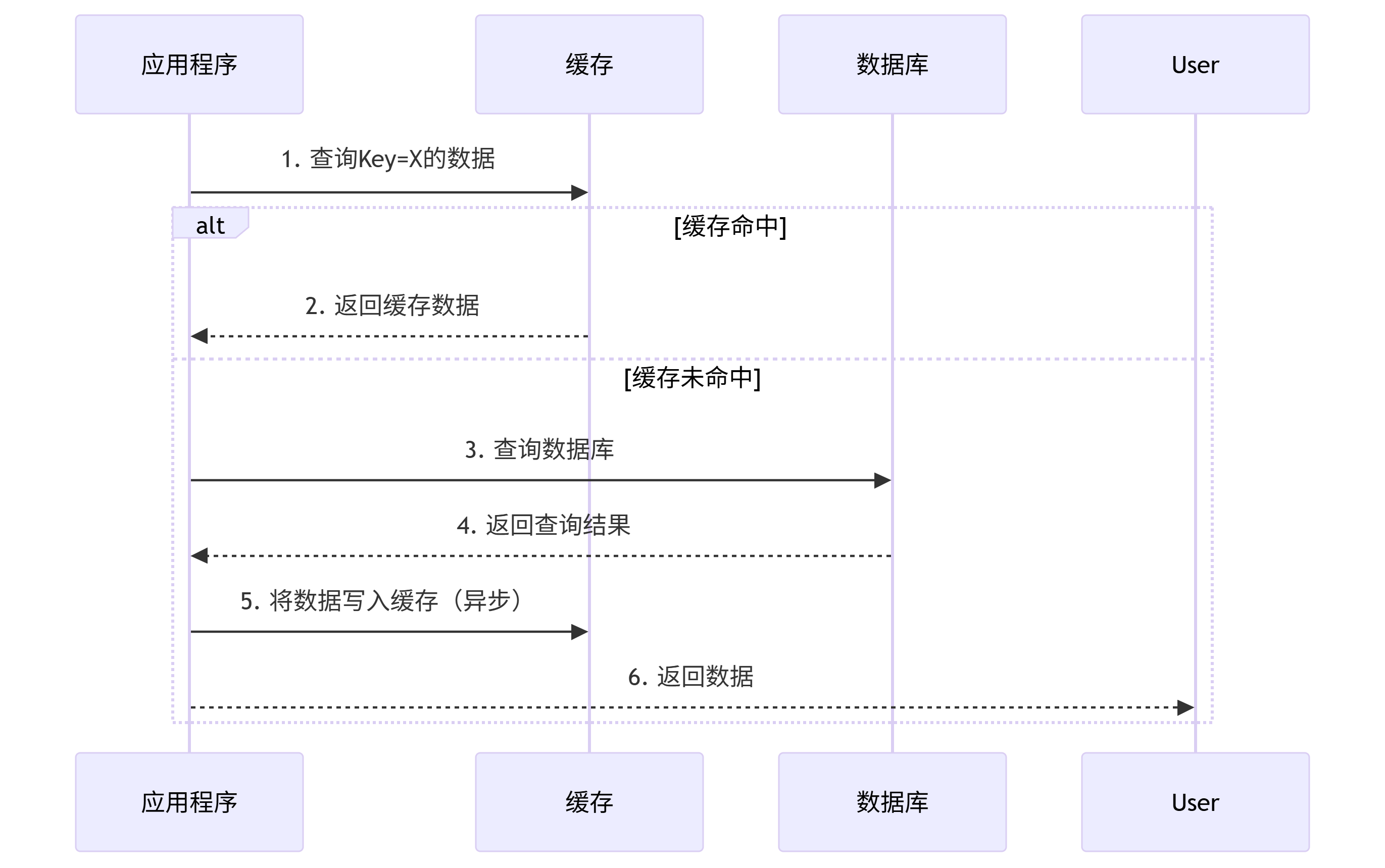
写操作流程
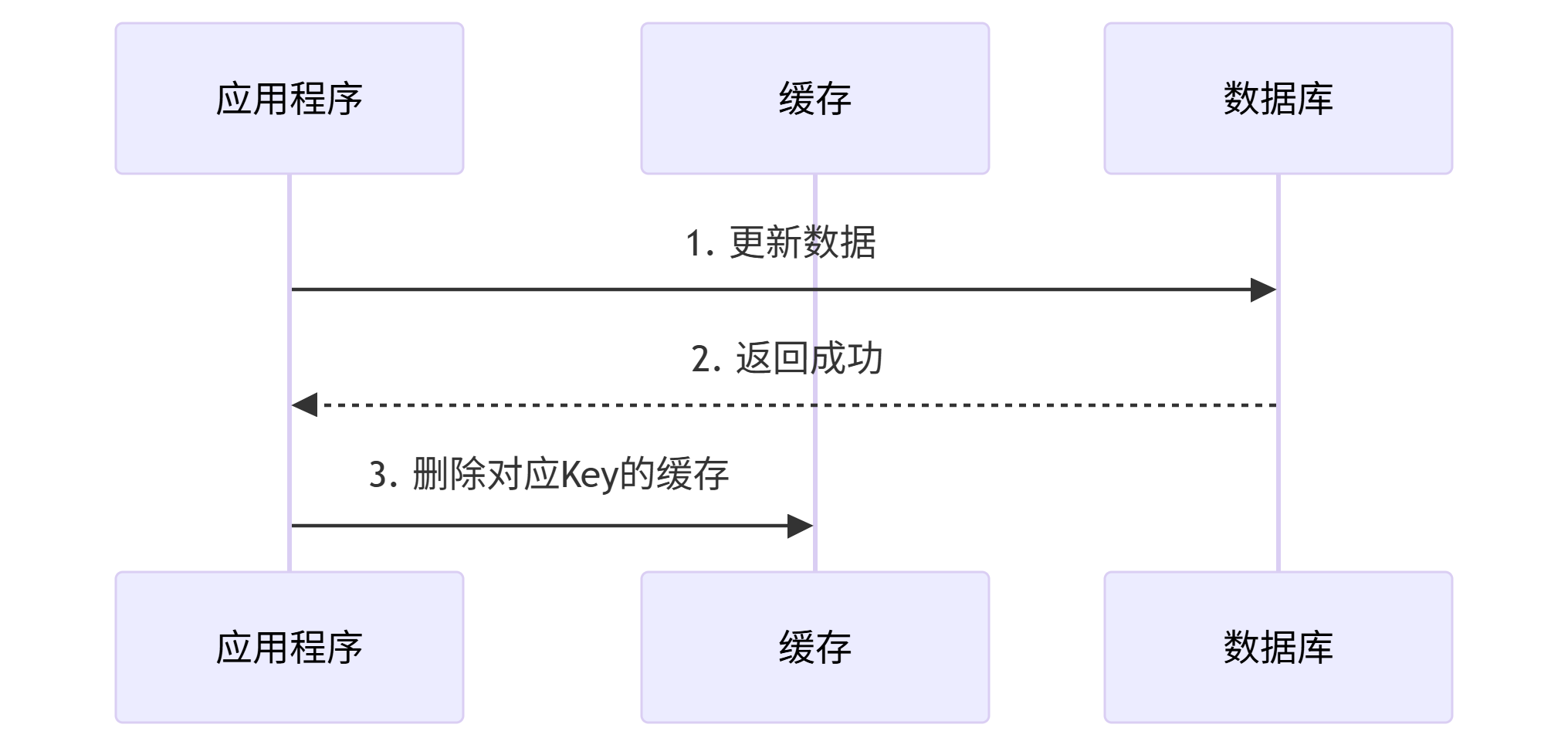
关键特点:
-
缓存不作为数据源的代理
-
存在"先更新数据库后删缓存"的并发问题(需配合延时双删)
-
优点:实现简单,缓存控制灵活
-
缺点:存在缓存击穿风险
二、Read-Through(读穿透)
核心思想 :缓存系统封装数据加载逻辑
适用场景:需要简化应用代码(如用户画像系统)
标准流程
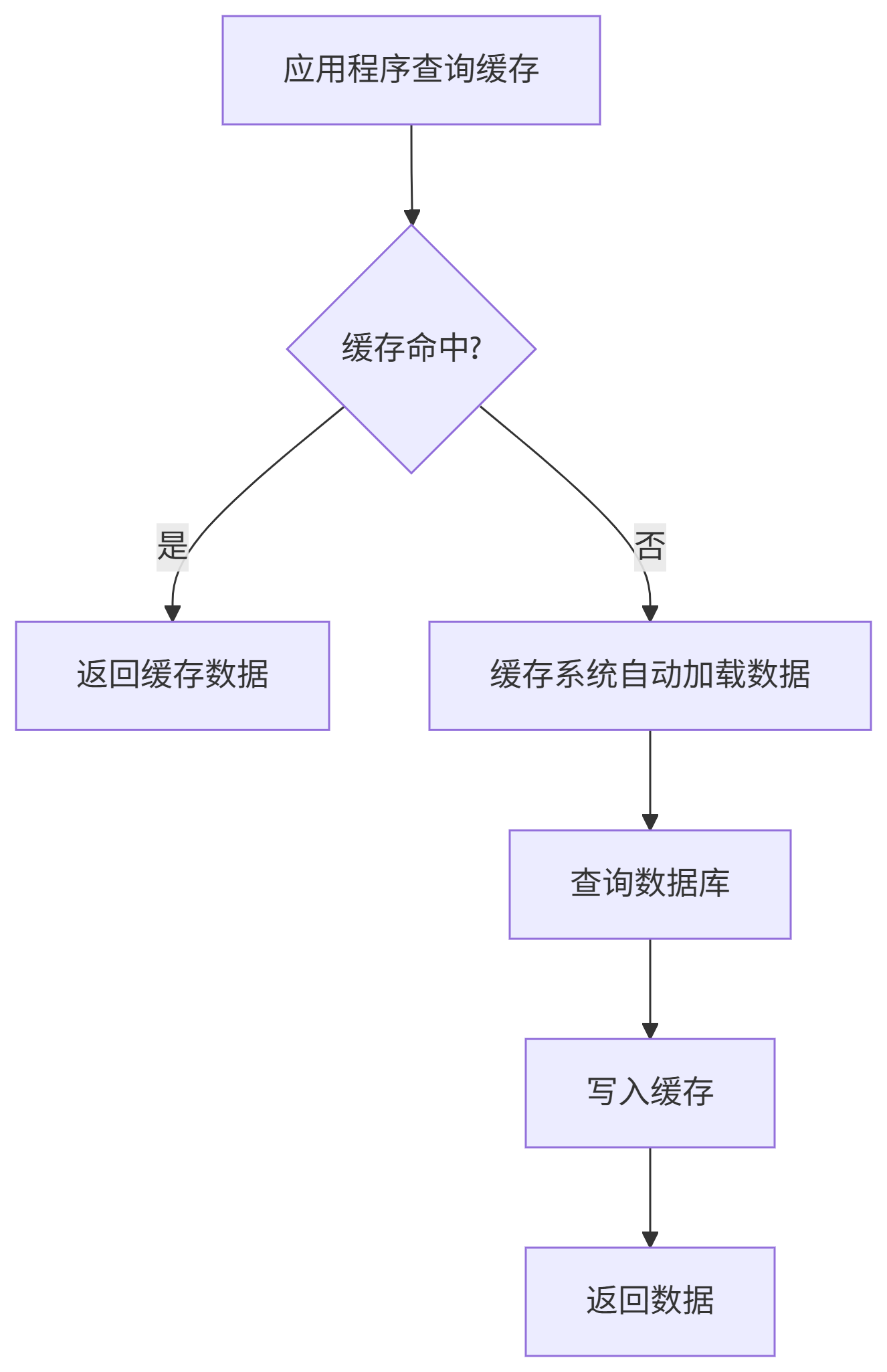
实现示例:
// 缓存客户端封装数据加载器
public class ReadThroughCache {
private DataLoader loader; // 数据加载接口
public Object get(String key) {
Object value = redis.get(key);
if(value == null) {
value = loader.load(key); // 自动加载
redis.set(key, value);
}
return value;
}
}优势:
-
业务代码无需关心缓存未命中逻辑
-
天然避免缓存穿透(通过Loader约束)
-
架构特点:缓存层封装数据加载逻辑
-
优势:业务代码更简洁
-
典型应用:搭配分布式缓存使用
三、Write-Through(写穿透)
核心思想 :写操作同时更新缓存和数据库
适用场景:金融账户系统等强一致性场景
原子化流程
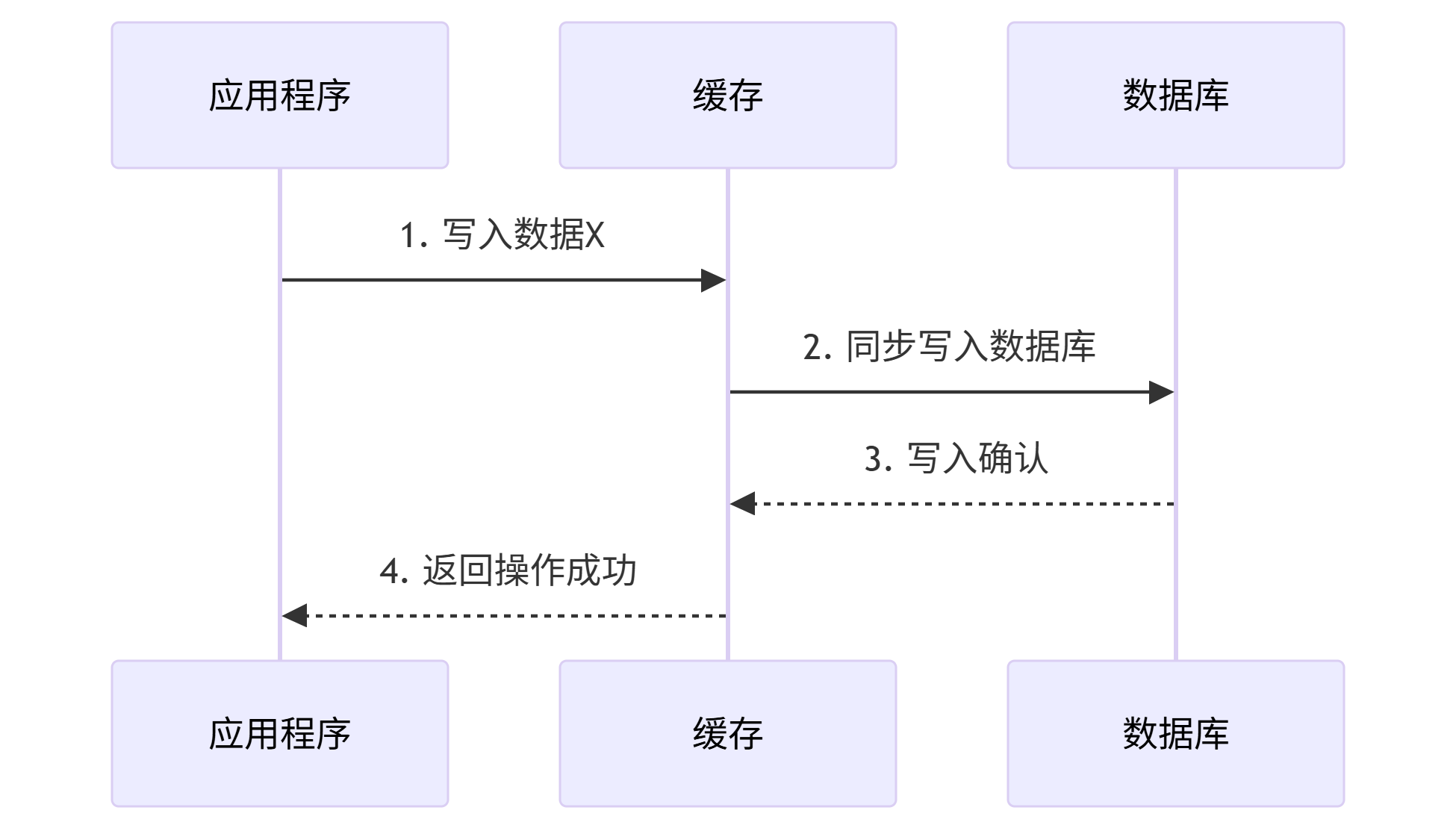
关键约束:
-
必须使用支持事务的存储(如Redis事务+关系型数据库)
-
典型实现:
def write_through(key, value): with cache.transaction(): # 开启缓存事务 cache.set(key, value) db.update(key, value) # 同步写数据库
性能影响 :
写操作延迟增加30%-50%(需权衡一致性需求)
- 特点:强一致性保障
- 代价:写入延迟较高
四、Write-Behind(异步回写)
核心思想 :先更新缓存,异步批量持久化
适用场景:高频写入场景(如点击流日志)
分层处理流程

实现机制:
// 使用Disruptor高性能队列
public class WriteBehindProcessor {
private RingBuffer<WriteTask> ringBuffer;
public void write(String key, Object value) {
cache.put(key, value);
ringBuffer.publishEvent((task, seq) -> {
task.setKey(key);
task.setValue(value);
});
}
// 批量消费线程
class BatchConsumer implements EventHandler<WriteTask> {
public void onEvent(WriteTask event, long sequence, boolean endOfBatch) {
batchBuffer.add(event);
if(batchBuffer.size() >= 500 || endOfBatch) {
db.batchUpdate(batchBuffer); // 批量提交
batchBuffer.clear();
}
}
}
}风险控制:
- 内存队列需持久化防丢失
- 设置最大延迟阈值(如60秒强制提交)
- 优势:极高写吞吐量
- 风险:数据丢失可能性
五、Refresh-Ahead(预刷新)
核心思想 :在缓存过期前主动刷新
适用场景:热点数据维护(如秒杀商品库存)
智能刷新流程
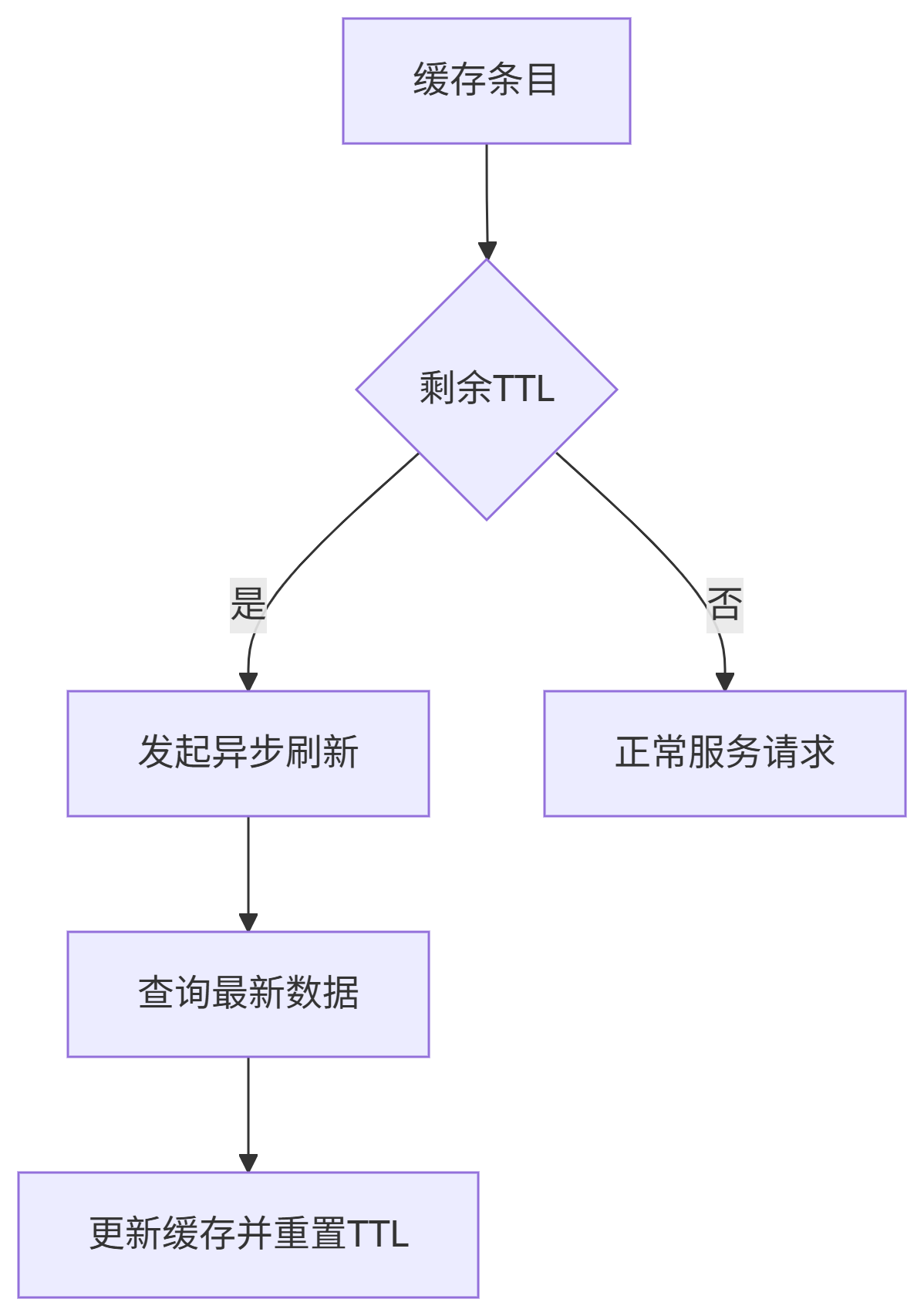
动态阈值计算:
-
热度指标:
刷新阈值 T = 基础阈值 * log(访问频率) -
示例配置:
refresh: base_ttl: 30s # 基础缓存时间 threshold_ratio: 0.2 # 剩余20%TTL时触发 concurrency: 10 # 最大并发刷新数 -
优势:避免大量请求穿透到DB
-
实现:需预测数据访问模式
-
应用:热点数据维护
六、组合模式案例:CQRS+缓存
特点
- 读写分离架构
- 写模型直连DB
- 读模型通过缓存提供数据
架构流程:
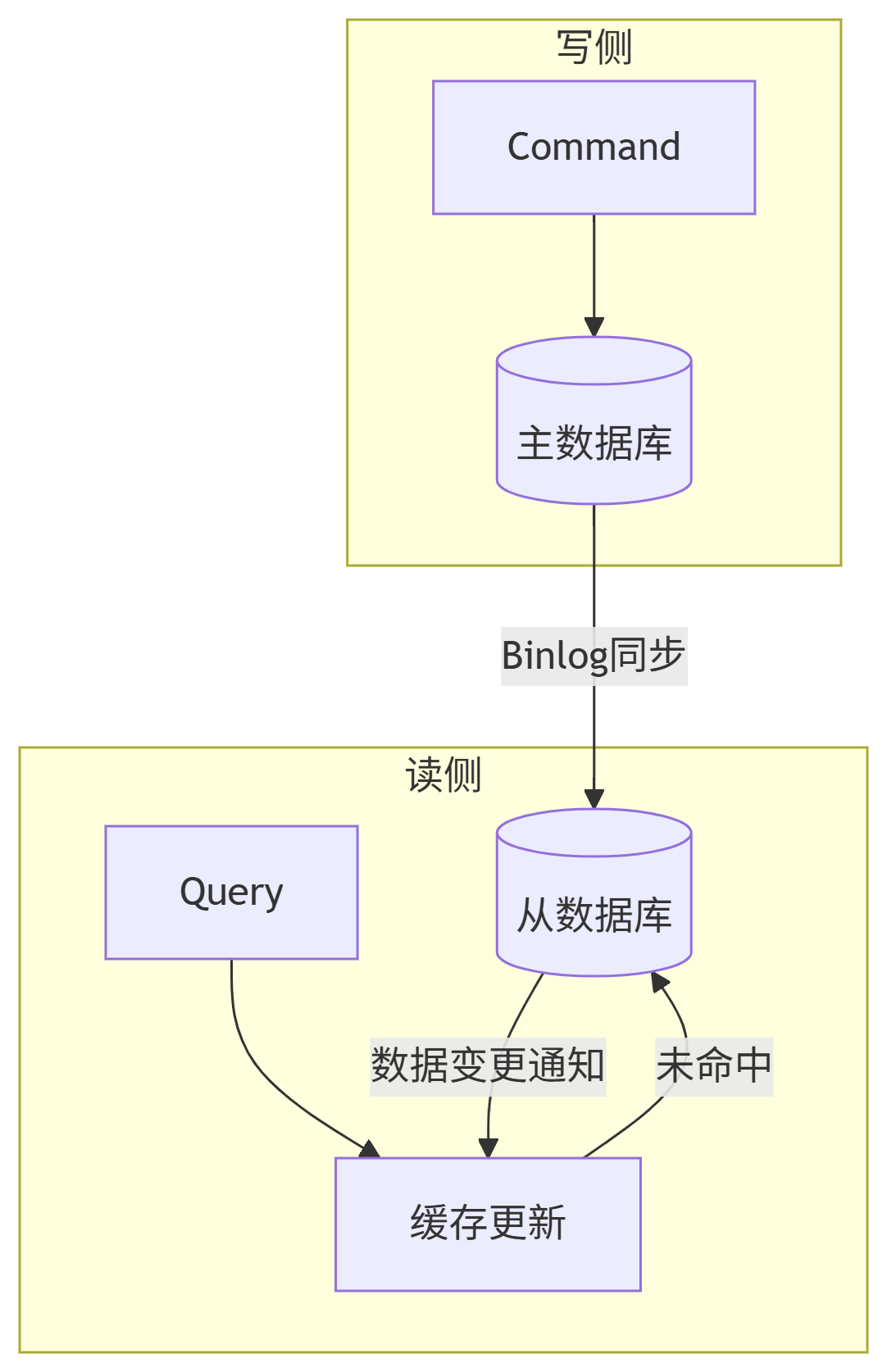
数据同步机制:
# 使用Canal监听数据库变更
canal_client = CanalClient()
canal_client.subscribe("table_x")
while True:
events = canal_client.get_events()
for event in events:
if event.type == UPDATE:
cache.delete(event.key) # 失效对应缓存七、多层缓存架构
多层缓存架构
- L1:本地缓存(Guava/Caffeine)
- L2:分布式缓存(Redis)
- L3:CDN边缘缓存
典型三级缓存流程:
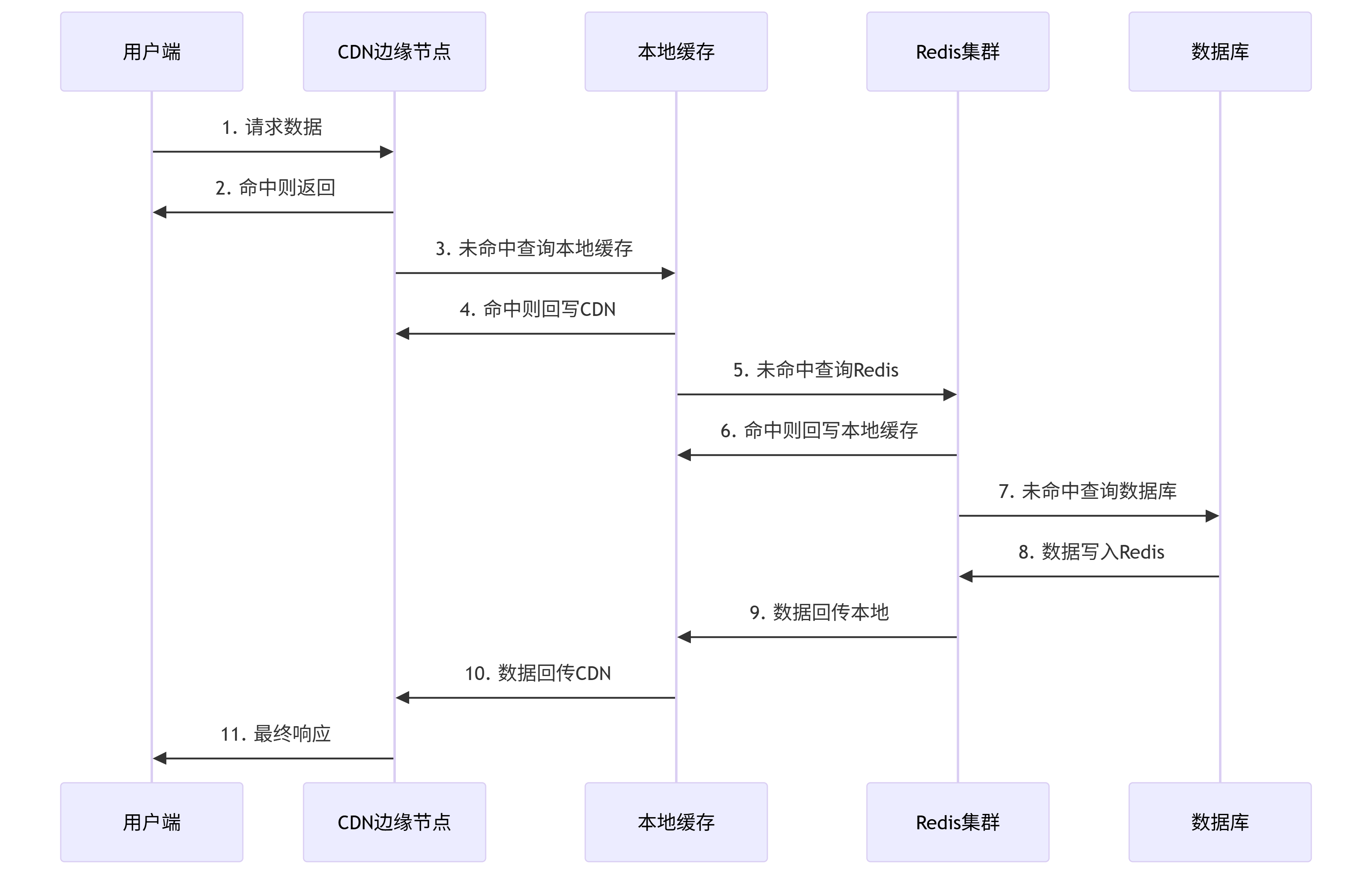
各层配置建议:
| 层级 | 技术选型 | TTL | 容量 |
|---|---|---|---|
| CDN | 边缘节点缓存 | 5-60秒 | 自动淘汰 |
| L1 | Caffeine | 30-300秒 | 堆内存20% |
| L2 | Redis集群 | 10-30分钟 | 最大内存80% |
八、模式选择决策树
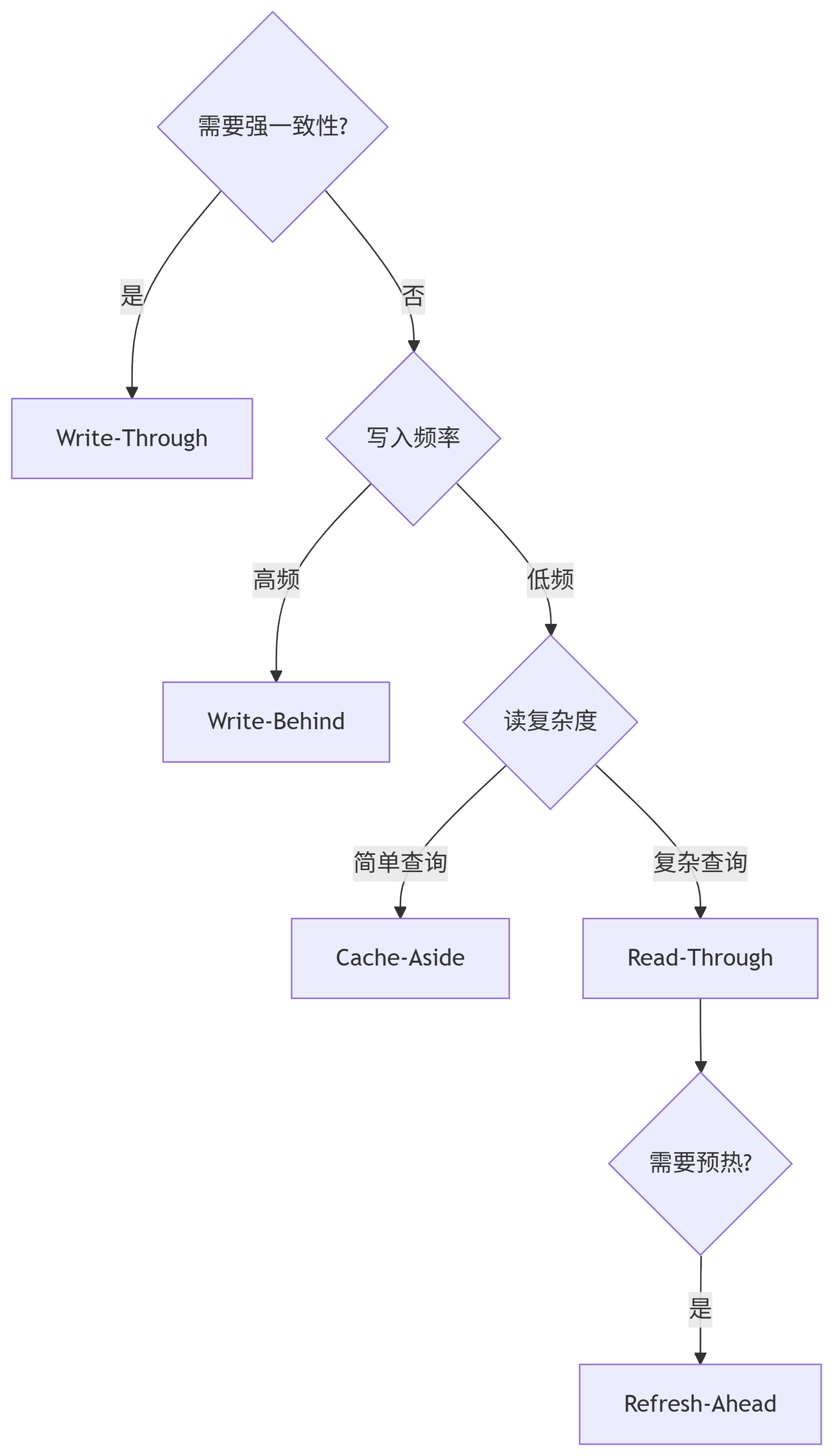
模式选择建议
- 读多写少 → Cache-Aside + Read-Through
- 写密集型 → Write-Behind + 批量提交
- 强一致性要求 → Write-Through + 事务管理
- 超高并发 → 多级缓存 + 预加载机制
性能优化指标
- 缓存命中率(建议>90%)
- 缓存加载耗时(P99<100ms)
- 内存使用率(<80%警戒线)
每种模式都有其独特的生命周期管理策略,实际系统往往采用混合模式(如:写操作使用Write-Behind保证吞吐,读操作使用Read-Through+Refresh-Ahead降低延迟),建议通过实时监控缓存命中率和数据新鲜度指标动态调整策略。