技术栈
Spark-SQL 四(实验)
Gvemis⁹
2025-04-22 17:34
用idea实验hive的常用代码
将数据放到项目·的目录下
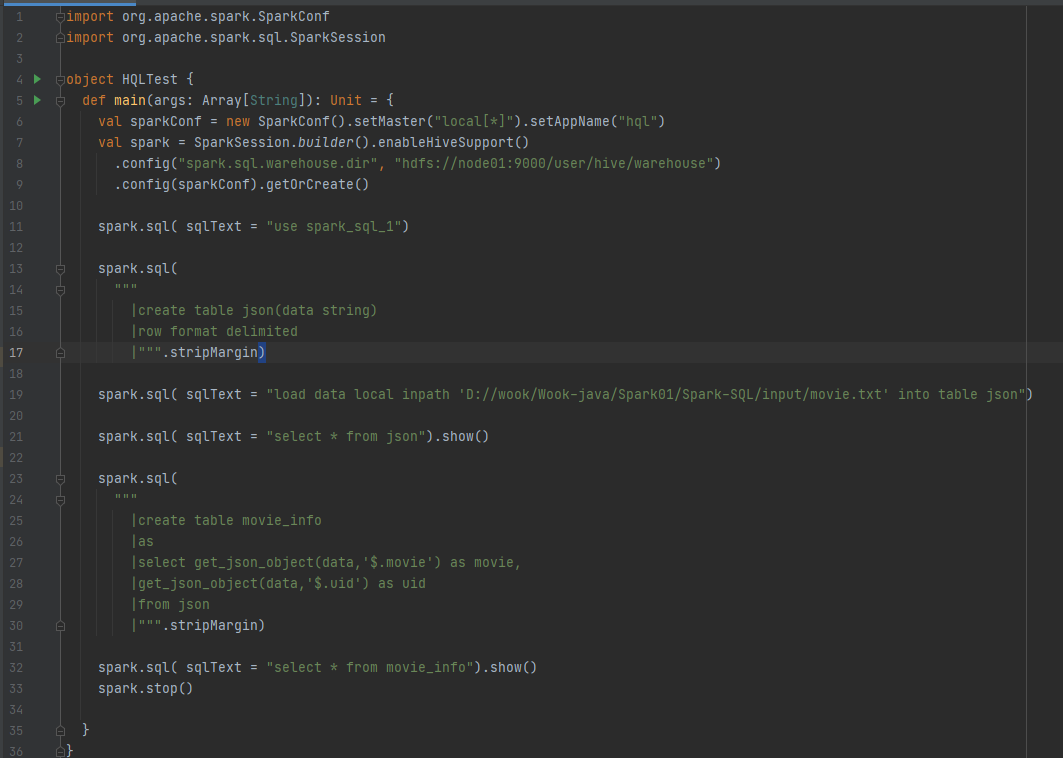
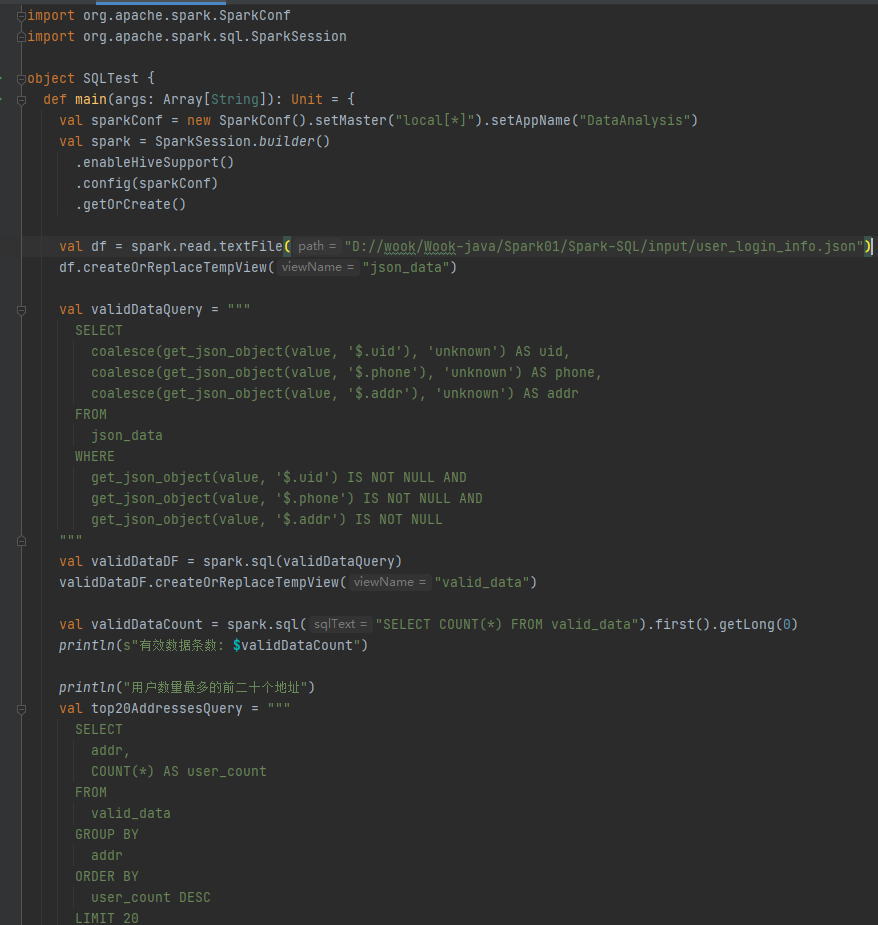
代码实现
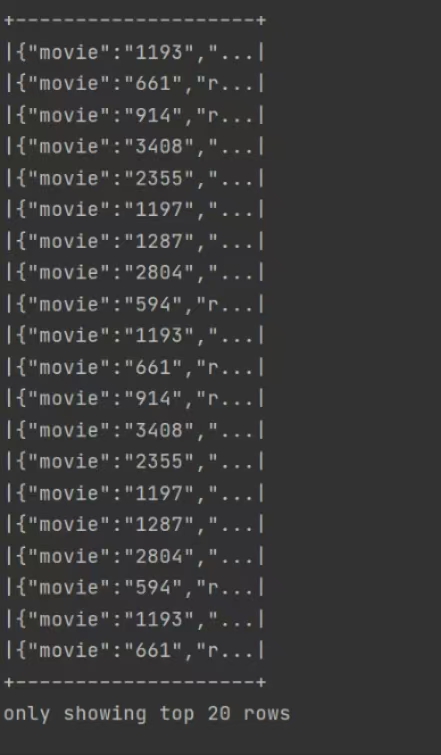
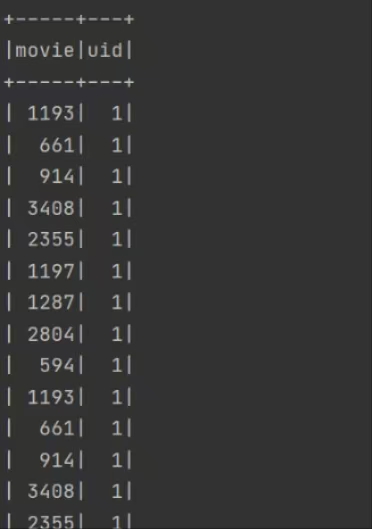
运行结果:
实验
统计
有效数据条数
及
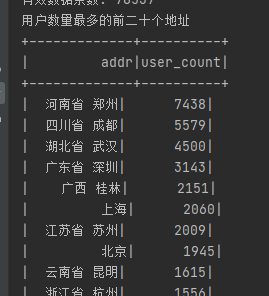
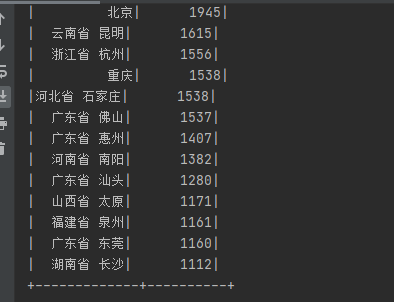
用户数量最多的前二十个地址
将数据放到Spark-SQL/input目录下
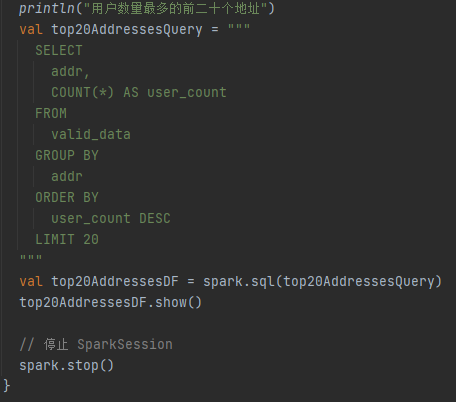
代码实现:
运行结果:
大数据
分布式
spark
上一篇:
Redis客户端连不上?可以通过以下方法排查,亲测可用!
下一篇:
Spark SQL概述(专业解释+生活化比喻)
相关推荐
phltxy
4 分钟前
LangGraph智能租房助手实践
大数据
·
人工智能
·
python
·
深度学习
·
语言模型
·
langchain
zqrgkjyxgs
9 分钟前
GEO垂直行业实战:医疗、制造、教育、金融的分行业差异化优化策略
大数据
·
人工智能
·
搜索引擎
北京晶数信息科技
12 分钟前
加油站成品油智慧监管系统项目建设实施汇报(一)
大数据
·
物联网
·
产品经理
·
需求分析
夜影风
17 分钟前
我国AI智能体产业发展洞察:为何能在AI应用层实现“换道超车“
大数据
·
人工智能
AvatarAI_Walker
40 分钟前
2026年7月安徽本地健康IP孵化行业观察:不同需求下的服务方向梳理
大数据
·
网络
·
tcp/ip
·
搜索引擎
·
精选
xlrqx
41 分钟前
2026年平顶山家电清洗培训设备是否齐全依据多因素来判断
大数据
·
python
Georgeviewer
8 小时前
商业落地评测|实体门店GEO优化性价比与服务体系深度复盘
大数据
·
人工智能
腻害兔
9 小时前
【若依项目-产品经理视角】深度拆解 RuoYi-Vue-Pro 商城模块:从商品管理到交易引擎,50 张表撑起一整套电商系统
java
·
大数据
·
vue.js
·
产品经理
·
ai编程
GIR123
10 小时前
官方出品 | 多通道土壤呼吸测量系统市场现状与十五五规划深度报告:行业分析+趋势预测全收录
大数据
·
人工智能
·
机器学习
南讯股份Nascent
11 小时前
洽洽全域会员项目启动会圆满召开
大数据
·
人工智能
热门推荐
01
GitHub 镜像站点
02
如何新建文件夹? 电脑新建文件夹的4种方法
03
2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片
04
AI科技热点日报 | 2026年07月01日
05
国内可直接用、免费额度/永久免费的大模型API清单(含 SiliconFlow、火山、阿里、智谱、百度、Kimi、DeepSeek、DMXAPI 等)
06
AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路
07
幻兽帕鲁 - 服务器管理员权限与 GM 命令完全指南
08
2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?
09
微信历史版本含下载地址( Windows PC | 安卓 | MAC )及设置微信不更新
10
【解构】DeepSeek V4 发布:技术报告深度解读 + 横向对比六大开源模型,我们的判断是……