-
Spark-SQL连接Hive概述:Spark SQL编译时可选择包含Hive支持,包含后能支持Hive表访问、UDF、HQL等功能,且无需事先安装Hive,编译时引入Hive支持为佳。
-
连接方式
内嵌Hive:使用简单,直接可用,但实际生产中很少使用。
外部Hive:在spark-shell中连接外部Hive,需拷贝hive-site.xml到conf/目录并修改其中的url、将MySQL驱动拷贝到jars/目录、把core-site.xml和hdfs-site.xml拷贝到conf/目录,最后重启spark-shell。
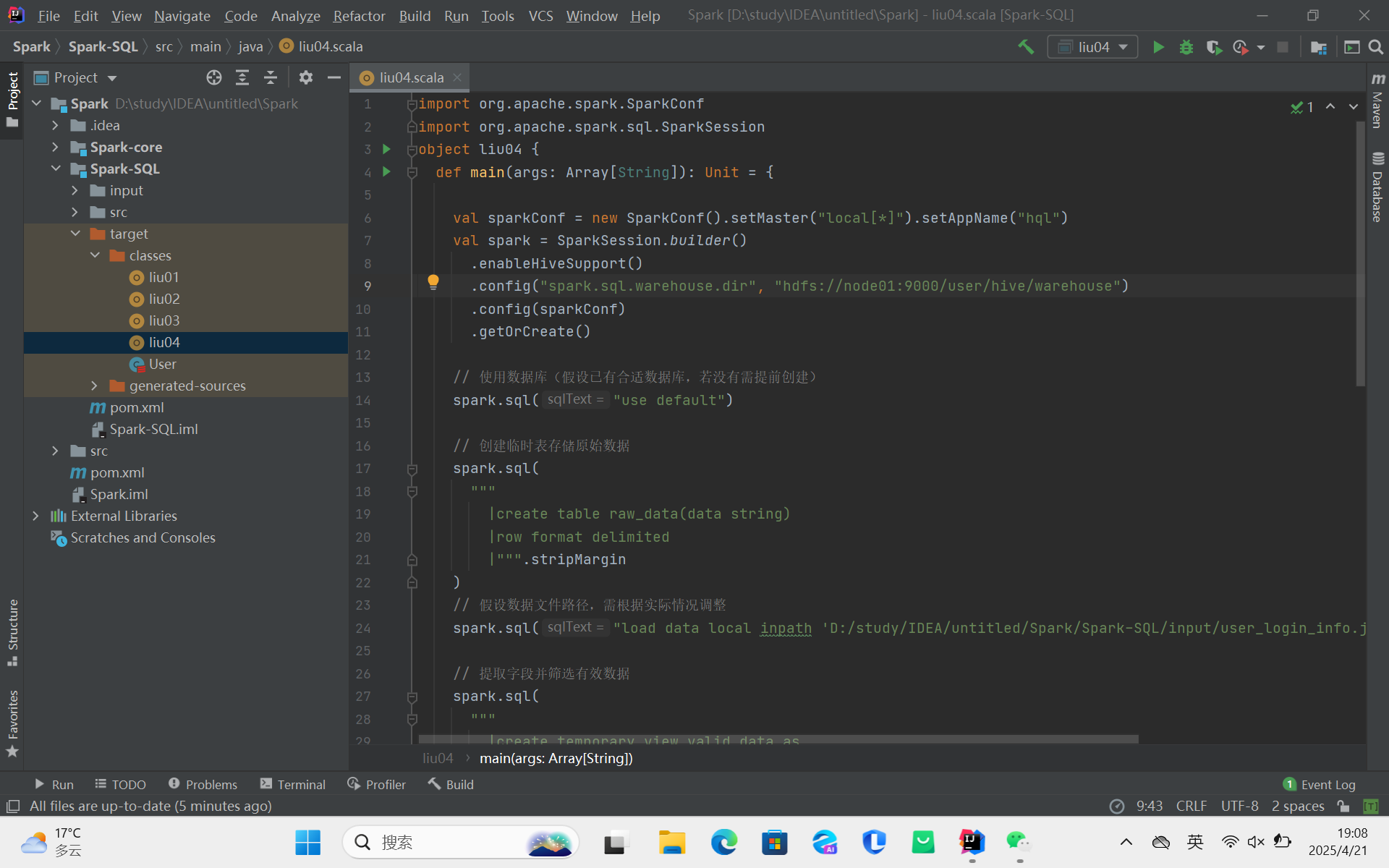
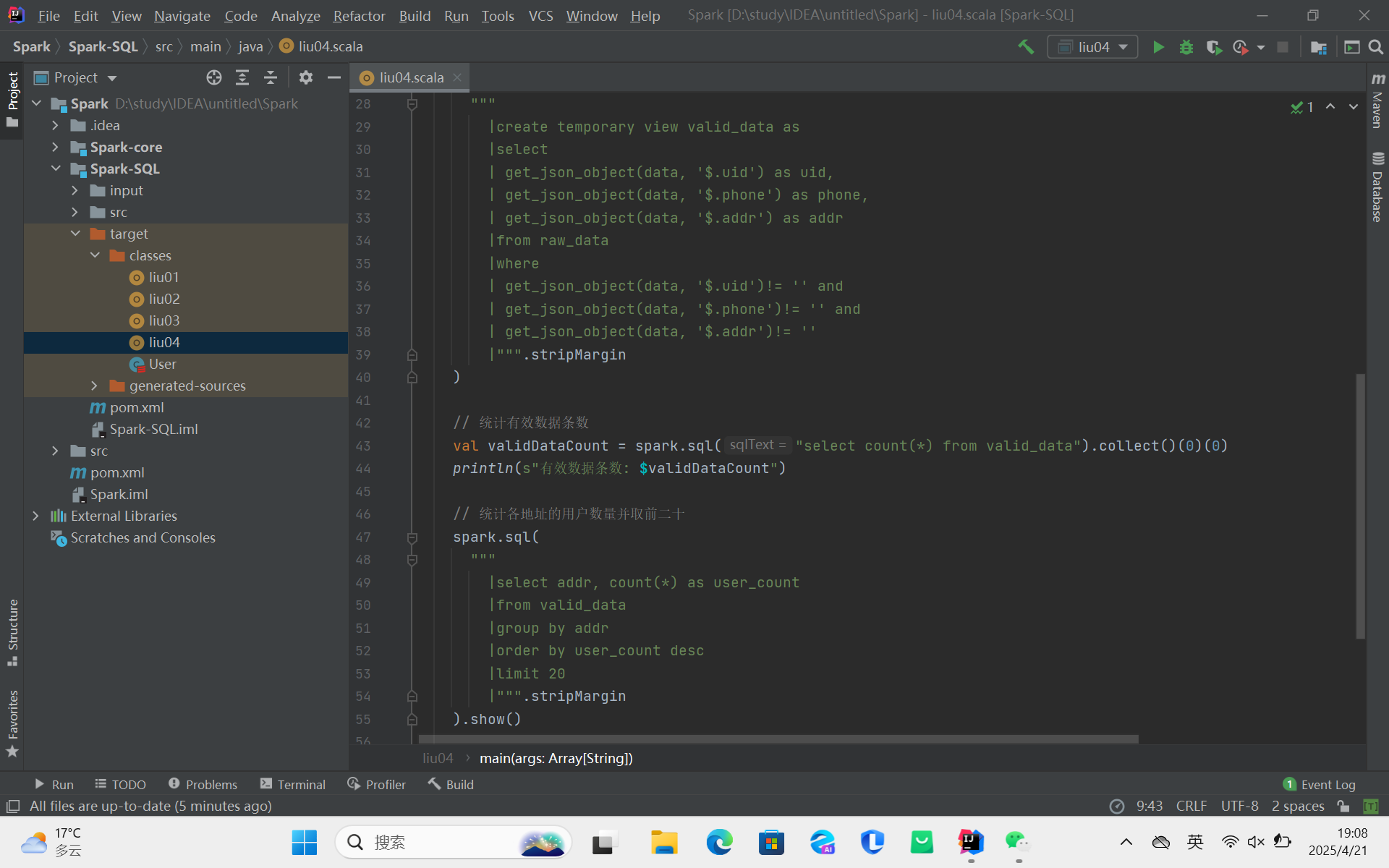
代码操作Hive:先导入spark-hive_2.12和hive-exec依赖;接着把hive-site.xml拷贝到项目resources目录;然后编写代码设置Spark配置、启用Hive支持。若报错,可设置HADOOP_USER_NAME解决;还可通过配置修改数据库仓库地址,解决数据库位置异常问题。