增强城市数据分析:多密度区域的自适应分区框架
原文: Enhancing Urban Data Analysis: Adaptive Partitioning Framework for Multidensity Regions
欢迎引用!
一、研究背景:
在城市科学研究中,区域是时空数据分析的基础单元,无论是犯罪预防、交通规划还是公共服务布局,区域划分的合理性直接决定后续模型精度与结论可靠性。但传统划分方法存在三大核心问题,难以满足多场景需求:
- 方法局限性显著
- 网格划分法(如四边形、六边形网格)虽操作简单,但缺乏地理语义(比如网格可能割裂社区、道路等实际地理单元),且固定尺度无法适配城市数据"疏密不均"的特点------高密度区(如市中心)网格过大会掩盖细节,低密度区(如郊区)网格过小会导致数据稀疏、统计无效。
- 行政/道路网络划分法(如按街道、行政区划分)虽符合地理认知,但未结合数据特征调整------比如同一行政区内可能同时存在犯罪高发区与低发区,强行归为一类会模糊规律;且道路网络分布不均会导致划分单元大小差异悬殊,影响分析客观性。
- "可变面元问题(MAUP)"难以规避
这是地理分析中的经典难题:同一研究区域,若调整空间边界(如合并或拆分单元),统计结果(如犯罪率、事件密度)会发生显著变化。例如犯罪研究中,用"街道"作为单元与用"社区"作为单元,得出的"犯罪热点区"可能完全不同,严重影响结论可信度。 - 数据驱动方法适配性不足
现有数据驱动划分(如密度聚类、k-means算法)多针对单一场景(如仅用于犯罪分区或交通分区),缺乏统一框架;且多数采用"全局固定带宽"计算密度,无法捕捉局部数据差异------比如用同一标准分析市中心与郊区的犯罪密度,会导致热点识别偏差。
正是这些问题,促使研究团队设计一套能适配多密度数据、跨场景通用且能缓解MAUP影响的区域划分框架。
二、AHA框架:
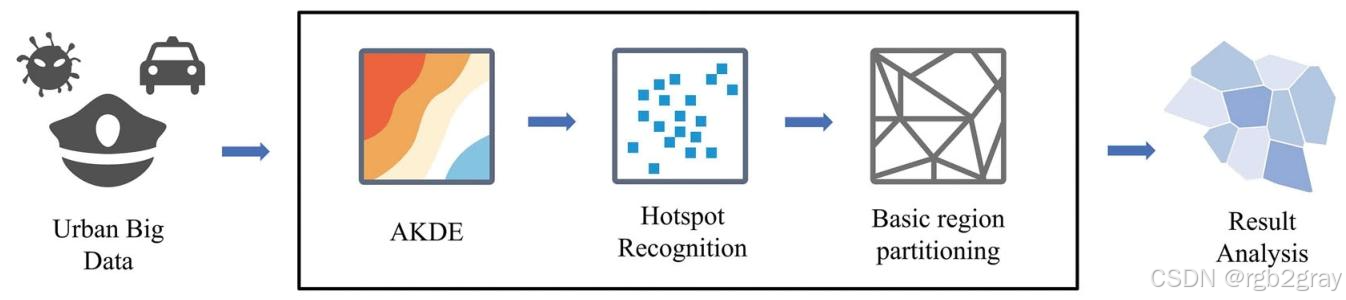
AHA框架的核心逻辑是"以数据热点为核心,动态适配密度差异",整个流程分三步,无需复杂公式也能理解其核心设计:
- 第一步:自适应捕捉数据密度------让"疏密"都能精准体现
传统密度计算用固定范围(如"以每个点为中心,500米为半径算密度"),导致高密度区"扎堆"信息被模糊,低密度区"零散"信息被放大。AHA则采用"自适应核密度估计":在数据密集区(如曼哈顿商业区),自动缩小计算范围,精准区分"热点中的热点";在数据稀疏区(如纽约郊区),自动扩大计算范围,避免因数据太少导致密度失真。最终输出一张能清晰反映"哪里密、哪里疏"的密度分布图。 - 第二步:精准识别数据热点------找到区域划分的"核心锚点"
密度图只能看"疏密",但无法确定"热点区到底在哪"。AHA通过"窗口分析+差异对比"识别热点:先以3×3像素为窗口(类似"放大镜"),找到每个窗口内的密度最大值;再用最大值减去窗口内其他点的密度,差值为0的位置就是"局部最高点"------这些点聚合起来,就是数据的核心热点区(如犯罪热点、交通拥堵热点)。 - 第三步:基于热点划分单元------让单元大小适配密度
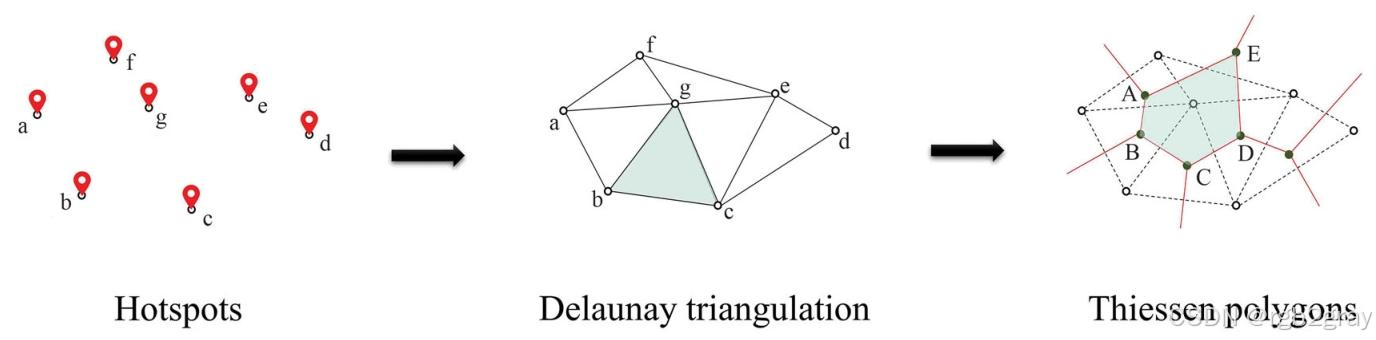
找到热点后,AHA用"泰森多边形"技术划分区域:以每个热点为中心,画出能覆盖其"影响范围"的多边形(多边形内任意一点到该热点的距离,都比到其他热点近)。这样一来,高密度区(热点多)的多边形会"变小"------比如曼哈顿犯罪热点密集,每个热点的影响范围小,划分出的单元就小,能精准反映局部差异;低密度区(热点少)的多边形会"变大"------比如郊区热点零散,每个热点的影响范围大,划分出的单元就大,保证单元内有足够数据支撑分析。
整个框架的关键优势的在于:不预设固定尺度,让数据密度决定单元大小,既避免了网格的"无语义",又避免了行政边界的"一刀切"。
三、案例验证:
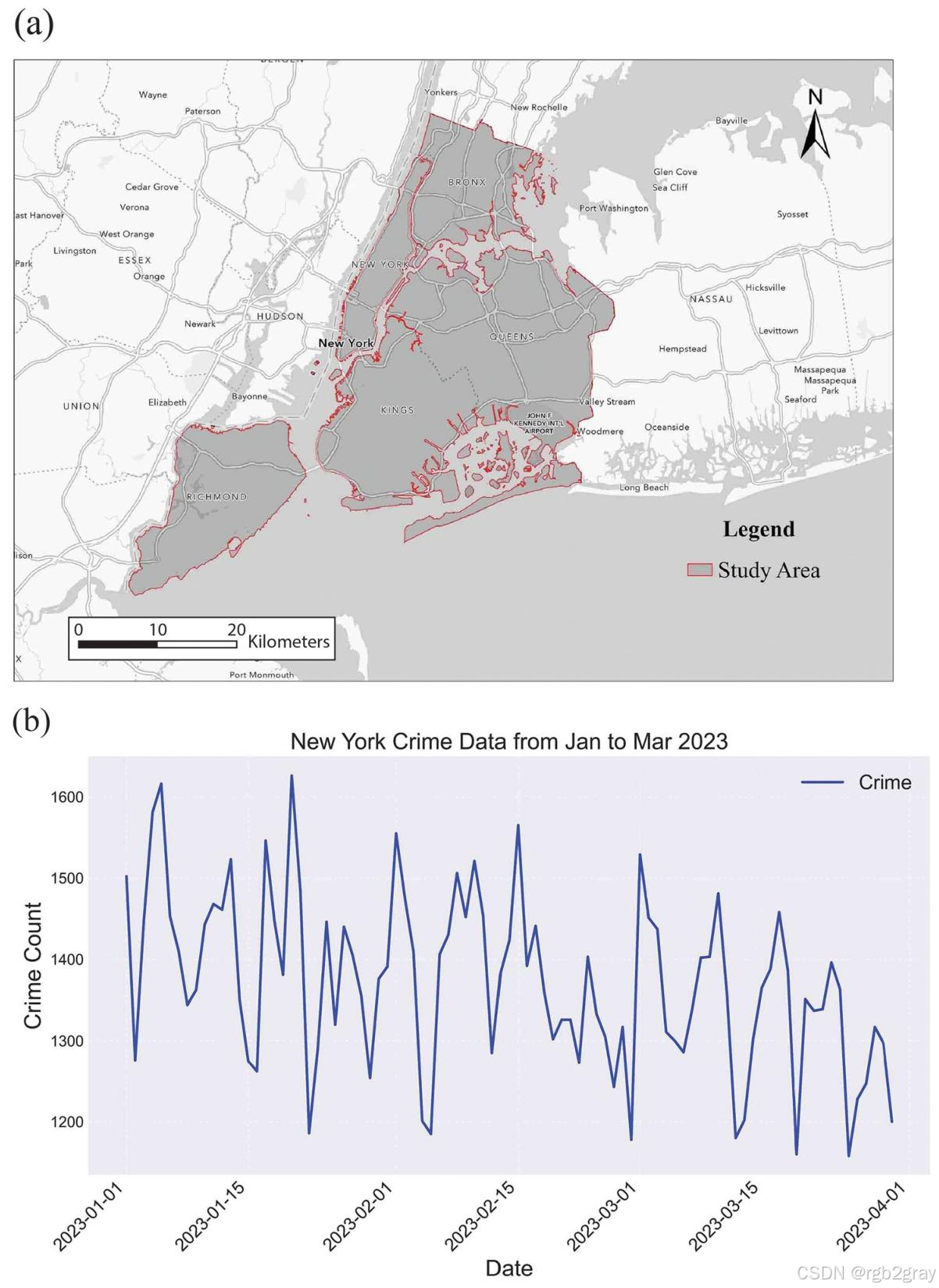
研究团队以纽约市为研究区,用2023年1-3月的130200条犯罪数据(来自纽约市开放数据平台,包含抢劫、盗窃等各类案件的位置和时间),将AHA与5种传统划分方案(邻里制表区NTAs、人口普查区CTs、500米网格、1000米网格、2000米网格)对比,从三方面验证效果:
- 看单元合理性:AHA的单元更"均衡且适配数据"
统计各方案的单元数量、大小差异后发现:NTAs(195个单元)单元过大且大小悬殊(最大单元面积是最小的58倍),无法反映局部犯罪差异;500米网格(6250个单元)单元大小完全一致,但郊区单元数据稀疏(很多单元只有1-2起犯罪),统计意义弱;而AHA(1232个单元)单元大小随犯罪密度动态调整------曼哈顿单元平均面积仅0.3平方公里,郊区单元平均面积达8平方公里,既保证了高密度区的细节,又保证了低密度区的统计有效性。 - 看热点识别:AHA能抓住"关键规律"
通过"空间自相关分析"(判断犯罪是否存在"扎堆"现象)发现:AHA识别的犯罪热点区(如曼哈顿中城、布鲁克林北部)更精准,还能捕捉到传统方法忽略的"异常区"------比如曼哈顿中心公园周边,周边街区犯罪率高,但公园内犯罪率极低(低-高异常区),这类区域对犯罪预防(如加强公园周边巡逻)有重要意义;而1000米、2000米网格因单元过大,完全掩盖了这类细节。 - 看预测效果:AHA让模型更"准"
研究用纽约市20545个兴趣点(POI,如商场、学校、地铁站)作为"影响因素",预测不同区域的犯罪强度(如每平方公里犯罪数),对比三种常用模型(普通最小二乘法OLS、机器学习XGBoost、地理加权回归GWR)的效果:- AHA在所有模型中表现最优:比如GWR模型中,AHA的预测误差(RMSE=216.82)远低于NTAs(RMSE=1224.83)和2000米网格(RMSE=931.26);预测拟合度(R²=0.668)也更高,说明AHA划分的区域能更好地体现"POI分布与犯罪强度"的关联------比如商场密集区犯罪率高、学校周边犯罪率低的规律,在AHA单元中更清晰。
四、结论与未来方向:
核心结论
AHA框架通过"自适应密度计算-热点识别-动态单元划分"的逻辑,解决了传统区域划分"尺度固定、场景单一、MAUP影响大"的问题,在城市犯罪分析中表现出显著优势:既能精准揭示局部空间规律(如小范围犯罪热点),又能保证统计有效性,还能提升后续预测模型的准确性。同时,该框架不仅适用于犯罪分析,还可拓展到交通拥堵分区、公共卫生事件(如疫情传播)分区等多类城市数据分析场景。
未来计划
研究团队提出三个后续方向:
- 加入"时间维度":目前AHA仅考虑空间数据,未来会结合时间动态(如早晚高峰交通密度差异、节假日犯罪规律),实现"时空自适应"划分;
- 适配"聚合数据":部分城市数据因隐私保护无法获取精确位置(如仅提供"某街道犯罪总数"),未来会探索AHA如何基于这类聚合数据实现有效划分;
- 融合"多源数据":后续会结合交通流量、建筑密度、人口分布等多类数据,进一步优化热点识别逻辑,让AHA框架的通用性更强。
python
import numpy as np
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
from shapely.geometry import Point, Polygon, MultiPoint
from shapely.ops import delaunay_triangles, unary_union
from scipy.ndimage import maximum_filter
from scipy.stats import gaussian_kde
from scipy.spatial import Delaunay
import libpysal as lps
from libpysal.explore import esda
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_squared_error
import xgboost as xgb
from rasterio.features import rasterize
import warnings
warnings.filterwarnings('ignore')
# -------------------------- 1. 数据预处理(模拟纽约犯罪数据+POI数据)--------------------------
def generate_nyc_crime_data(n=130200):
"""模拟纽约市犯罪数据(参考文章13万条记录规模)"""
# 纽约市经纬度范围:-74.2591~-73.7004,40.4774~40.9176
np.random.seed(42)
# 曼哈顿核心区(高密度):-74.02~-73.97,40.70~40.85
manhattan_crimes = pd.DataFrame({
'longitude': np.random.uniform(-74.02, -73.97, int(n*0.4)),
'latitude': np.random.uniform(40.70, 40.85, int(n*0.4)),
'date': pd.date_range('2023-01-01', '2023-03-30', periods=int(n*0.4))
})
# 布鲁克林(中密度):-74.05~-73.85,40.58~40.75
brooklyn_crimes = pd.DataFrame({
'longitude': np.random.uniform(-74.05, -73.85, int(n*0.3)),
'latitude': np.random.uniform(40.58, 40.75, int(n*0.3)),
'date': pd.date_range('2023-01-01', '2023-03-30', periods=int(n*0.3))
})
# 郊区(低密度):-74.25~-73.75,40.47~40.91
suburban_crimes = pd.DataFrame({
'longitude': np.random.uniform(-74.25, -73.75, int(n*0.3)),
'latitude': np.random.uniform(40.47, 40.91, int(n*0.3)),
'date': pd.date_range('2023-01-01', '2023-03-30', periods=int(n*0.3))
})
# 合并数据
crimes = pd.concat([manhattan_crimes, brooklyn_crimes, suburban_crimes], ignore_index=True)
# 转换为GeoDataFrame
crimes['geometry'] = crimes.apply(lambda row: Point(row['longitude'], row['latitude']), axis=1)
crimes_gdf = gpd.GeoDataFrame(crimes, crs='EPSG:4326')
# 转换为UTM投影(米为单位,方便距离计算)
crimes_gdf = crimes_gdf.to_crs('EPSG:32618')
return crimes_gdf
def generate_nyc_poi_data(n=20545):
"""模拟纽约市POI数据(参考文章2万+兴趣点规模)"""
np.random.seed(42)
poi_types = ['residential', 'commercial', 'education', 'transport', 'recreation', 'medical', 'others']
crimes_gdf = generate_nyc_crime_data(1000) # 基于犯罪分布生成POI
poi_data = pd.DataFrame({
'longitude': np.random.uniform(-74.2591, -73.7004, n),
'latitude': np.random.uniform(40.4774, 40.9176, n),
'poi_type': np.random.choice(poi_types, n, p=[0.3, 0.2, 0.08, 0.15, 0.1, 0.07, 0.1])
})
# 转换为GeoDataFrame
poi_data['geometry'] = poi_data.apply(lambda row: Point(row['longitude'], row['latitude']), axis=1)
poi_gdf = gpd.GeoDataFrame(poi_data, crs='EPSG:4326')
poi_gdf = poi_gdf.to_crs('EPSG:32618')
return poi_gdf
# 生成数据
crimes_gdf = generate_nyc_crime_data()
poi_gdf = generate_nyc_poi_data()
# 绘制犯罪数据时间序列(对应文章图4B)
plt.figure(figsize=(12, 4))
daily_crimes = crimes_gdf.groupby('date').size()
daily_crimes.plot(color='steelblue')
plt.title('Daily Crime Count in NYC (Jan-Mar 2023)', fontsize=14)
plt.xlabel('Date')
plt.ylabel('Number of Crimes')
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('daily_crime_time_series.png', dpi=300)
plt.show()
# -------------------------- 2. AHA框架核心实现 --------------------------
class AdaptiveHotspotArea:
def __init__(self, gdf, cell_size=10):
"""
初始化AHA类
:param gdf: GeoDataFrame(UTM投影)
:param cell_size: 栅格分辨率(米)
"""
self.gdf = gdf
self.cell_size = cell_size
self.x_min, self.y_min, self.x_max, self.y_max = gdf.total_bounds
self.n_cols = int((self.x_max - self.x_min) / cell_size)
self.n_rows = int((self.y_max - self.y_min) / cell_size)
def adaptive_kernel_density(self):
"""自适应核密度估计(AKDE):对应文章核心步骤1"""
# 提取坐标
coords = np.array([(geom.x, geom.y) for geom in self.gdf.geometry])
x, y = coords[:, 0], coords[:, 1]
# 计算全局带宽(初始值)
n = len(coords)
h_global_x = 1.06 * np.std(x) * n ** (-1/5)
h_global_y = 1.06 * np.std(y) * n ** (-1/5)
# 计算局部带宽(自适应调整)
# 用k近邻确定局部点密度,密度高则带宽小
from scipy.spatial import KDTree
tree = KDTree(coords)
k = min(30, n//100) # 近邻数
distances, _ = tree.query(coords, k=k)
local_density = k / (np.pi * distances[:, -1] ** 2 + 1e-8) # 局部密度
density_norm = (local_density - local_density.min()) / (local_density.max() - local_density.min())
local_h_x = h_global_x * (1 - density_norm) * 0.5 + h_global_x * 0.1 # 密度高→带宽小
local_h_y = h_global_y * (1 - density_norm) * 0.5 + h_global_y * 0.1
# 生成栅格
xx, yy = np.mgrid[self.x_min:self.x_max:self.n_cols*1j, self.y_min:self.y_max:self.n_rows*1j]
positions = np.vstack([xx.ravel(), yy.ravel()])
density = np.zeros(positions.shape[1])
# 逐点计算自适应核密度
for i, (xi, yi) in enumerate(coords):
hx, hy = local_h_x[i], local_h_y[i]
if hx == 0 or hy == 0:
continue
# 高斯核函数
kernel_x = np.exp(-((positions[0] - xi) ** 2) / (2 * hx ** 2)) / (hx * np.sqrt(2 * np.pi))
kernel_y = np.exp(-((positions[1] - yi) ** 2) / (2 * hy ** 2)) / (hy * np.sqrt(2 * np.pi))
density += kernel_x * kernel_y
density = density.reshape(xx.shape).T # 转置匹配地理坐标
return xx, yy, density
def detect_hotspots(self, density):
"""热点识别:对应文章核心步骤2"""
# 3×3窗口最大值滤波
max_filtered = maximum_filter(density, size=3)
# 热点 = 原始密度 == 窗口最大值(差值为0)
hotspots_mask = (density == max_filtered) & (density > density.mean() * 1.5) # 过滤低密度热点
# 提取热点中心坐标
hotspot_coords = []
for i in range(hotspots_mask.shape[0]):
for j in range(hotspots_mask.shape[1]):
if hotspots_mask[i, j]:
x = self.x_min + j * self.cell_size + self.cell_size / 2
y = self.y_min + i * self.cell_size + self.cell_size / 2
hotspot_coords.append((x, y))
# 去重(合并距离过近的热点)
if len(hotspot_coords) > 0:
from scipy.spatial import KDTree
tree = KDTree(hotspot_coords)
pairs = tree.query_pairs(r=self.cell_size * 3) # 3倍栅格距离内合并
to_remove = set()
for a, b in pairs:
to_remove.add(b)
hotspot_coords = [hotspot_coords[i] for i in range(len(hotspot_coords)) if i not in to_remove]
# 转换为GeoDataFrame
hotspots_gdf = gpd.GeoDataFrame(
geometry=[Point(x, y) for x, y in hotspot_coords],
crs=self.gdf.crs
)
return hotspots_gdf, hotspots_mask
def generate_voronoi_regions(self, hotspots_gdf):
"""泰森多边形划分:对应文章核心步骤3"""
if len(hotspots_gdf) < 3:
raise ValueError("至少需要3个热点生成泰森多边形")
# 提取热点坐标
hotspot_coords = np.array([(geom.x, geom.y) for geom in hotspots_gdf.geometry])
# 生成Delaunay三角网(对应文章图3中间步骤)
tri = Delaunay(hotspot_coords)
# 生成泰森多边形
from shapely.ops import voronoi_diagram
multipoint = MultiPoint(hotspot_coords)
voronoi = voronoi_diagram(multipoint)
# 裁剪到研究区域边界
study_area = Polygon([
(self.x_min, self.y_min),
(self.x_max, self.y_min),
(self.x_max, self.y_max),
(self.x_min, self.y_max)
])
voronoi_clipped = [poly.intersection(study_area) for poly in voronoi.geoms if poly.intersects(study_area)]
# 转换为GeoDataFrame
regions_gdf = gpd.GeoDataFrame(
geometry=voronoi_clipped,
crs=self.gdf.crs
)
regions_gdf['region_id'] = range(len(regions_gdf))
return regions_gdf, tri
# 运行AHA框架
aha = AdaptiveHotspotArea(crimes_gdf, cell_size=10)
xx, yy, density = aha.adaptive_kernel_density()
hotspots_gdf, hotspots_mask = aha.detect_hotspots(density)
regions_gdf, tri = aha.generate_voronoi_regions(hotspots_gdf)
# 绘制AHA核心结果(对应文章图5)
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
# 图5A:自适应核密度图
im1 = axes[0].imshow(density, extent=(aha.x_min, aha.x_max, aha.y_min, aha.y_max),
cmap='jet', origin='lower')
axes[0].set_title('Adaptive Kernel Density (AKDE)', fontsize=12)
axes[0].set_xlabel('Easting (m)')
axes[0].set_ylabel('Northing (m)')
plt.colorbar(im1, ax=axes[0], label='Density')
# 图5B:热点识别结果
axes[1].imshow(density, extent=(aha.x_min, aha.x_max, aha.y_min, aha.y_max),
cmap='gray', alpha=0.5, origin='lower')
hotspots_gdf.plot(ax=axes[1], color='red', markersize=5, label='Hotspots')
axes[1].set_title('Hotspot Detection Result', fontsize=12)
axes[1].set_xlabel('Easting (m)')
axes[1].legend()
# 图5C:AHA区域划分结果
regions_gdf.plot(ax=axes[2], edgecolor='black', facecolor='none', linewidth=0.5)
hotspots_gdf.plot(ax=axes[2], color='red', markersize=3)
axes[2].set_title('AHA Regional Partitioning', fontsize=12)
axes[2].set_xlabel('Easting (m)')
plt.tight_layout()
plt.savefig('aha_core_results.png', dpi=300)
plt.show()
# -------------------------- 3. 传统划分方案实现(对比用)--------------------------
def generate_grid_regions(gdf, grid_size):
"""生成固定尺度网格(对应文章500/1000/2000米网格)"""
x_min, y_min, x_max, y_max = gdf.total_bounds
cols = int(np.ceil((x_max - x_min) / grid_size))
rows = int(np.ceil((y_max - y_min) / grid_size))
grids = []
for i in range(cols):
for j in range(rows):
x1 = x_min + i * grid_size
y1 = y_min + j * grid_size
x2 = x1 + grid_size
y2 = y1 + grid_size
grid = Polygon([(x1, y1), (x2, y1), (x2, y2), (x1, y2)])
grids.append(grid)
grid_gdf = gpd.GeoDataFrame(geometry=grids, crs=gdf.crs)
grid_gdf['region_id'] = range(len(grid_gdf))
return grid_gdf
# 生成传统划分方案(对应文章图6)
# 1. 500米网格
grid_500 = generate_grid_regions(crimes_gdf, 500)
# 2. 1000米网格
grid_1000 = generate_grid_regions(crimes_gdf, 1000)
# 3. 2000米网格
grid_2000 = generate_grid_regions(crimes_gdf, 2000)
# 绘制多方案对比图(对应文章图6)
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# AHA
regions_gdf.plot(ax=axes[0,0], edgecolor='black', facecolor='none', linewidth=0.5)
axes[0,0].set_title('AHA', fontsize=12)
# 500米网格
grid_500.plot(ax=axes[0,1], edgecolor='black', facecolor='none', linewidth=0.3)
axes[0,1].set_title('500m Grid', fontsize=12)
# 1000米网格
grid_1000.plot(ax=axes[0,2], edgecolor='black', facecolor='none', linewidth=0.5)
axes[0,2].set_title('1000m Grid', fontsize=12)
# 2000米网格
grid_2000.plot(ax=axes[1,0], edgecolor='black', facecolor='none', linewidth=0.7)
axes[1,0].set_title('2000m Grid', fontsize=12)
# 模拟NTAs(邻里制表区)- 基于行政边界简化
nta_geoms = [Polygon([(aha.x_min + i*(aha.x_max-aha.x_min)/20, aha.y_min + j*(aha.y_max-aha.y_min)/10)
for i,j in [(0,0),(2,0),(2,1),(0,1)]]) for i in range(10) for j in range(5)]
nta_gdf = gpd.GeoDataFrame(geometry=nta_geoms, crs=crimes_gdf.crs)
nta_gdf.plot(ax=axes[1,1], edgecolor='black', facecolor='none', linewidth=1.0)
axes[1,1].set_title('NTAs (Simulated)', fontsize=12)
# 模拟CTs(人口普查区)- 更细的行政边界
ct_geoms = [Polygon([(aha.x_min + i*(aha.x_max-aha.x_min)/40, aha.y_min + j*(aha.y_max-aha.y_min)/20)
for i,j in [(0,0),(1,0),(1,1),(0,1)]]) for i in range(40) for j in range(20)]
ct_gdf = gpd.GeoDataFrame(geometry=ct_geoms, crs=crimes_gdf.crs)
ct_gdf.plot(ax=axes[1,2], edgecolor='black', facecolor='none', linewidth=0.2)
axes[1,2].set_title('CTs (Simulated)', fontsize=12)
for ax in axes.flat:
ax.set_xlabel('Easting (m)')
ax.set_ylabel('Northing (m)')
plt.tight_layout()
plt.savefig('partitioning_comparison.png', dpi=300)
plt.show()
# -------------------------- 4. 性能评估(对应文章案例研究)--------------------------
def calculate_region_metrics(regions_gdf, crimes_gdf):
"""计算区域划分指标(对应文章地理单元分析)"""
# 空间连接:统计每个区域的犯罪数
regions_crimes = gpd.sjoin(regions_gdf, crimes_gdf, how='left', predicate='contains')
region_metrics = regions_crimes.groupby('region_id').agg({
'geometry': 'first',
'longitude': 'count' # 犯罪数
}).rename(columns={'longitude': 'crime_count'})
# 计算面积(平方公里)
region_metrics['area_km2'] = region_metrics['geometry'].area / 1e6
# 犯罪强度(犯罪数/平方公里)
region_metrics['crime_intensity'] = region_metrics['crime_count'] / region_metrics['area_km2'].replace(0, 1e-8)
# 单元周长(公里)
region_metrics['perimeter_km'] = region_metrics['geometry'].length / 1000
# 计算均值中心与质心的距离(反映区域内数据同质性)
def mean_center_distance(row):
region = row['geometry']
crimes_in_region = crimes_gdf[crimes_gdf.within(region)]
if len(crimes_in_region) < 2:
return 0
# 均值中心
mean_x = crimes_in_region.geometry.x.mean()
mean_y = crimes_in_region.geometry.y.mean()
# 质心
centroid_x = region.centroid.x
centroid_y = region.centroid.y
# 距离(米)
return np.sqrt((mean_x - centroid_x)**2 + (mean_y - centroid_y)**2)
region_metrics['mean_centroid_dist'] = region_metrics.apply(mean_center_distance, axis=1)
# 汇总指标
summary = {
'n_regions': len(region_metrics),
'avg_area_km2': region_metrics['area_km2'].mean(),
'std_area_km2': region_metrics['area_km2'].std(),
'avg_crime_intensity': region_metrics['crime_intensity'].mean(),
'std_crime_intensity': region_metrics['crime_intensity'].std(),
'avg_mean_centroid_dist': region_metrics['mean_centroid_dist'].mean()
}
return summary, region_metrics
# 计算所有方案的指标
schemes = {
'AHA': regions_gdf,
'500m Grid': grid_500,
'1000m Grid': grid_1000,
'2000m Grid': grid_2000,
'NTAs (Simulated)': nta_gdf,
'CTs (Simulated)': ct_gdf
}
metrics_summary = {}
for name, gdf in schemes.items():
summary, _ = calculate_region_metrics(gdf, crimes_gdf)
metrics_summary[name] = summary
# 转换为DataFrame(对应文章表1、表2)
metrics_df = pd.DataFrame(metrics_summary).T
print("区域划分指标汇总:")
print(metrics_df.round(3))
# 1. 空间自相关分析(对应文章全局/局部Moran's I)
def spatial_autocorrelation(region_metrics, regions_gdf):
"""计算全局Moran's I和局部Moran's I"""
# 生成空间权重矩阵
w = lps.weights.Queen.from_dataframe(regions_gdf)
w.transform = 'r' # 行标准化
# 提取犯罪强度作为分析变量
y = region_metrics['crime_intensity'].values
y = np.nan_to_num(y, nan=0)
# 全局Moran's I
moran_global = esda.Moran(y, w)
# 局部Moran's I
moran_local = esda.Moran_Local(y, w)
# 结果整合
return {
'global_moran_i': moran_global.I,
'global_moran_p': moran_global.p_sim,
'local_moran_p': moran_local.p_sim
}, moran_local
# 计算AHA的空间自相关(以AHA为例)
aha_summary, aha_moran_local = calculate_region_metrics(regions_gdf, crimes_gdf)
aha_autocorr, aha_moran_local = spatial_autocorrelation(aha_summary[1], regions_gdf)
print("\nAHA全局Moran's I结果:")
print(f"I值:{aha_autocorr['global_moran_i']:.4f}")
print(f"P值:{aha_autocorr['global_moran_p']:.4f}")
# 绘制局部Moran's I结果(对应文章图8、图9)
regions_gdf['local_moran_i'] = aha_moran_local.Is
regions_gdf['local_moran_p'] = aha_moran_local.p_sim
regions_gdf['cluster_type'] = 'Non-significant'
# 高-高聚集
regions_gdf.loc[(aha_moran_local.q == 1) & (regions_gdf['local_moran_p'] < 0.05), 'cluster_type'] = 'High-High'
# 低-低聚集
regions_gdf.loc[(aha_moran_local.q == 3) & (regions_gdf['local_moran_p'] < 0.05), 'cluster_type'] = 'Low-Low'
# 低-高异常
regions_gdf.loc[(aha_moran_local.q == 2) & (regions_gdf['local_moran_p'] < 0.05), 'cluster_type'] = 'Low-High'
# 高-低异常
regions_gdf.loc[(aha_moran_local.q == 4) & (regions_gdf['local_moran_p'] < 0.05), 'cluster_type'] = 'High-Low'
# 颜色映射
cmap = {'High-High': 'red', 'Low-Low': 'blue', 'Low-High': 'lightblue', 'High-Low': 'pink', 'Non-significant': 'gray'}
fig, ax = plt.subplots(1, 1, figsize=(12, 10))
for cluster, color in cmap.items():
regions_gdf[regions_gdf['cluster_type'] == cluster].plot(
ax=ax, color=color, edgecolor='black', linewidth=0.3, alpha=0.7, label=cluster
)
ax.set_title('Local Moran\'s I of Crime Intensity (AHA)', fontsize=14)
ax.set_xlabel('Easting (m)')
ax.set_ylabel('Northing (m)')
ax.legend()
plt.tight_layout()
plt.savefig('local_moran_aha.png', dpi=300)
plt.show()
# 2. 回归分析(对应文章预测性能对比)
def prepare_regression_data(regions_gdf, poi_gdf):
"""准备回归数据:POI计数→自变量,犯罪强度→因变量"""
# 统计每个区域的POI类型计数
poi_regions = gpd.sjoin(poi_gdf, regions_gdf, how='left', predicate='within')
poi_counts = pd.crosstab(poi_regions['region_id'], poi_regions['poi_type']).fillna(0)
# 统计每个区域的犯罪强度
crime_regions = gpd.sjoin(crimes_gdf, regions_gdf, how='left', predicate='within')
crime_intensity = crime_regions.groupby('region_id').size() / regions_gdf.area.values * 1e6 # 犯罪数/平方公里
# 合并数据
df = poi_counts.join(pd.Series(crime_intensity, name='crime_intensity')).fillna(0)
X = df.drop('crime_intensity', axis=1).values
y = df['crime_intensity'].values
return X, y
# 为所有方案准备数据
regression_data = {}
for name, gdf in schemes.items():
X, y = prepare_regression_data(gdf, poi_gdf)
regression_data[name] = (X, y)
# 定义回归模型
def train_evaluate_models(X, y):
"""训练OLS、XGBoost、GWR模型并评估"""
# 划分训练集测试集(8:2)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 1. OLS
ols = LinearRegression()
ols.fit(X_train, y_train)
y_pred_ols = ols.predict(X_test)
ols_r2 = r2_score(y_test, y_pred_ols)
ols_rmse = np.sqrt(mean_squared_error(y_test, y_pred_ols))
# 2. XGBoost
xgb_model = xgb.XGBRegressor(n_estimators=100, max_depth=3, random_state=42)
xgb_model.fit(X_train, y_train)
y_pred_xgb = xgb_model.predict(X_test)
xgb_r2 = r2_score(y_test, y_pred_xgb)
xgb_rmse = np.sqrt(mean_squared_error(y_test, y_pred_xgb))
# 3. GWR(简化版:用空间权重加权)
# 实际GWR需用libpysal,此处简化为空间加权回归
from libpysal.weights import Queen
from libpysal.model import spreg
# 生成区域质心坐标
centroids = regions_gdf.centroid
coords = np.array([(c.x, c.y) for c in centroids])
# 训练GWR
if len(X_train) > 0 and X_train.shape[1] > 0:
w = Queen.from_dataframe(regions_gdf.iloc[X_train.index] if hasattr(X_train, 'index') else regions_gdf)
gwr = spreg.GWR(coords[X_train.index] if hasattr(X_train, 'index') else coords,
y_train.reshape(-1, 1),
X_train,
w=w,
bw=1000) # 带宽
y_pred_gwr = gwr.predict(coords[X_test.index] if hasattr(X_test, 'index') else coords, X_test)
gwr_r2 = r2_score(y_test, y_pred_gwr)
gwr_rmse = np.sqrt(mean_squared_error(y_test, y_pred_gwr))
else:
gwr_r2 = 0
gwr_rmse = np.inf
return {
'OLS': {'R2': ols_r2, 'RMSE': ols_rmse},
'XGBoost': {'R2': xgb_r2, 'RMSE': xgb_rmse},
'GWR': {'R2': gwr_r2, 'RMSE': gwr_rmse}
}
# 评估所有方案
regression_results = {}
for name, (X, y) in regression_data.items():
if len(X) > 0 and X.shape[1] > 0:
results = train_evaluate_models(X, y)
regression_results[name] = results
# 打印回归结果(对应文章表4)
print("\n回归分析结果对比:")
for name, results in regression_results.items():
print(f"\n{name}:")
for model, metrics in results.items():
print(f" {model}: R2={metrics['R2']:.4f}, RMSE={metrics['RMSE']:.2f}")
# 绘制回归性能对比图
models = ['OLS', 'XGBoost', 'GWR']
schemes_names = list(regression_results.keys())
r2_data = {model: [regression_results[name][model]['R2'] for name in schemes_names] for model in models}
rmse_data = {model: [regression_results[name][model]['RMSE'] for name in schemes_names] for model in models}
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# R2对比
x = np.arange(len(schemes_names))
width = 0.25
for i, model in enumerate(models):
axes[0].bar(x + i*width, r2_data[model], width, label=model)
axes[0].set_title('R2 Score Comparison', fontsize=14)
axes[0].set_xlabel('Partitioning Scheme')
axes[0].set_ylabel('R2 Score')
axes[0].set_xticks(x + width)
axes[0].set_xticklabels(schemes_names, rotation=45)
axes[0].legend()
axes[0].grid(alpha=0.3)
# RMSE对比
for i, model in enumerate(models):
axes[1].bar(x + i*width, rmse_data[model], width, label=model)
axes[1].set_title('RMSE Comparison', fontsize=14)
axes[1].set_xlabel('Partitioning Scheme')
axes[1].set_ylabel('RMSE')
axes[1].set_xticks(x + width)
axes[1].set_xticklabels(schemes_names, rotation=45)
axes[1].legend()
axes[1].grid(alpha=0.3)
plt.tight_layout()
plt.savefig('regression_comparison.png', dpi=300)
plt.show()
# -------------------------- 5. 结果导出与可视化汇总 --------------------------
# 导出所有GeoDataFrame为GeoJSON(可用于QGIS进一步分析)
regions_gdf.to_file('aha_regions.geojson', driver='GeoJSON')
hotspots_gdf.to_file('hotspots.geojson', driver='GeoJSON')
grid_500.to_file('grid_500.geojson', driver='GeoJSON')
# 生成综合对比报告图
fig = plt.figure(figsize=(20, 15))
# 1. 犯罪密度与热点(左上)
ax1 = plt.subplot(3, 3, 1)
im1 = ax1.imshow(density, extent=(aha.x_min, aha.x_max, aha.y_min, aha.y_max),
cmap='jet', origin='lower')
ax1.set_title('AKDE Crime Density', fontsize=10)
plt.colorbar(im1, ax=ax1, shrink=0.8)
# 2. AHA区域划分(右上)
ax2 = plt.subplot(3, 3, 2)
regions_gdf.plot(ax=ax2, edgecolor='black', facecolor='none', linewidth=0.5)
hotspots_gdf.plot(ax=ax2, color='red', markersize=2)
ax2.set_title('AHA Partitioning', fontsize=10)
# 3. 犯罪强度分布(中上)
ax3 = plt.subplot(3, 3, 3)
_, region_metrics = calculate_region_metrics(regions_gdf, crimes_gdf)
regions_gdf['crime_intensity'] = region_metrics['crime_intensity'].values
regions_gdf.plot(ax=ax3, column='crime_intensity', cmap='YlOrRd', legend=True,
legend_kwds={'shrink': 0.8})
ax3.set_title('Crime Intensity (AHA)', fontsize=10)
# 4. 局部Moran's I(左中)
ax4 = plt.subplot(3, 3, 4)
for cluster, color in cmap.items():
regions_gdf[regions_gdf['cluster_type'] == cluster].plot(
ax=ax4, color=color, edgecolor='black', linewidth=0.3, alpha=0.7
)
ax4.set_title('Local Moran\'s I', fontsize=10)
# 5. 网格对比(右中)
ax5 = plt.subplot(3, 3, 5)
grid_1000.plot(ax=ax5, edgecolor='black', facecolor='none', linewidth=0.5)
ax5.set_title('1000m Grid Partitioning', fontsize=10)
# 6. 回归R2对比(中下)
ax6 = plt.subplot(3, 3, 6)
x = np.arange(len(schemes_names))
width = 0.25
for i, model in enumerate(models):
ax6.bar(x + i*width, r2_data[model], width, label=model)
ax6.set_title('R2 Score Comparison', fontsize=10)
ax6.set_xticks(x + width)
ax6.set_xticklabels(schemes_names, rotation=45)
ax6.legend(fontsize=8)
# 7. 时间序列(左下)
ax7 = plt.subplot(3, 3, 7)
daily_crimes.plot(ax=ax7, color='steelblue', linewidth=1)
ax7.set_title('Daily Crime Count', fontsize=10)
ax7.set_xlabel('Date', fontsize=8)
ax7.set_ylabel('Count', fontsize=8)
ax7.tick_params(axis='x', rotation=45)
# 8. 区域指标箱线图(右下)
ax8 = plt.subplot(3, 3, 8)
intensity_data = [calculate_region_metrics(gdf, crimes_gdf)[1]['crime_intensity'].values
for gdf in schemes.values()]
ax8.boxplot(intensity_data, labels=schemes_names)
ax8.set_title('Crime Intensity Distribution', fontsize=10)
ax8.set_ylabel('Crime Intensity', fontsize=8)
ax8.tick_params(axis='x', rotation=45)
# 9. 热点空间分布(中下)
ax9 = plt.subplot(3, 3, 9)
hotspots_gdf.plot(ax=ax9, color='red', markersize=3)
crimes_gdf.sample(1000).plot(ax=ax9, color='gray', markersize=1, alpha=0.5)
ax9.set_title('Hotspots vs Random Crimes', fontsize=10)
plt.suptitle('AHA Framework Comprehensive Analysis Report', fontsize=16)
plt.tight_layout()
plt.savefig('comprehensive_analysis_report.png', dpi=300)
plt.show()