技术栈
spark和hadoop的区别
哈哈la
2025-04-23 8:40
一、spark概述
二、处理速度
三、 编程模型
四、实时性处理
五、spark内置模块
六、spark的运行模式
大数据
hadoop
spark
上一篇:
案例速成k8s,个人笔记快速入门
下一篇:
使用Java调用TensorFlow与PyTorch模型:DJL框架的应用探索
相关推荐
REDcker
7 分钟前
Git浅克隆详解与实践
大数据
·
git
陕西企来客
43 分钟前
陕西企来客科技 AI 营销大模型深度解析:GEO 赛道技术优势与落地实践
大数据
·
人工智能
·
科技
石像鬼₧魂石
1 小时前
钢结构ERP管理系统 —— 玻璃拟态 · 单文件HTML(系统为开发测试虚拟数据)
大数据
·
数据仓库
·
制造
·
数据库开发
·
数据库架构
软件技术新观察
1 小时前
2026年北京教育医疗小程序与APP定制开发:十大服务商实力测评
大数据
·
小程序
石像鬼₧魂石
1 小时前
贵州商会管理系统 —— 商协会数字化运营一站式平台
大数据
·
数据结构
·
物联网
·
eclipse
·
数据库架构
jkyy2014
11 小时前
深耕AI健康医疗数据智库,赋能企业构建主动健康管理新生态
大数据
·
人工智能
·
健康医疗
2601_96194608
13 小时前
AI API 网关实战:从单 Key 管理到企业级多租户架构
大数据
·
人工智能
·
金融
·
架构
·
api
·
个人开发
大大大大晴天
15 小时前
Flink CDC 深度解析:从原理到实践的全链路指南
大数据
·
flink
IT新视界
16 小时前
Elasticsearch信创国产化替代
大数据
·
elasticsearch
·
搜索引擎
汇策研习社
16 小时前
改良版ADX指标实战指南:告别传统ADX滞后、震荡误判难题
大数据
·
经验分享
·
金融
·
区块链
·
fastbull
热门推荐
01
GitHub 镜像站点
02
2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片
03
AI科技热点日报 | 2026年07月01日
04
幻兽帕鲁 - 服务器管理员权限与 GM 命令完全指南
05
2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?
06
GPT-5.5 对比 GPT-5.6 Sol、Terra、Luna:官方性能数据与选型分析
07
AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路
08
2026 年 AI 大模型 & AI 编程工具实战全总结
09
2026 年 AI 编程工具终极横评:Cursor vs Claude Code vs Copilot vs Windsurf
10
2026 AI 编程工具终极实战指南:Cursor vs Claude Code vs Copilot,开发者该怎么选?

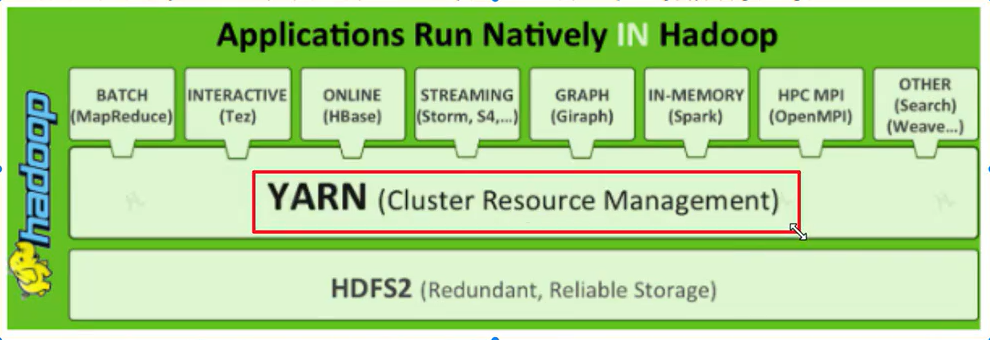 二、处理速度
二、处理速度

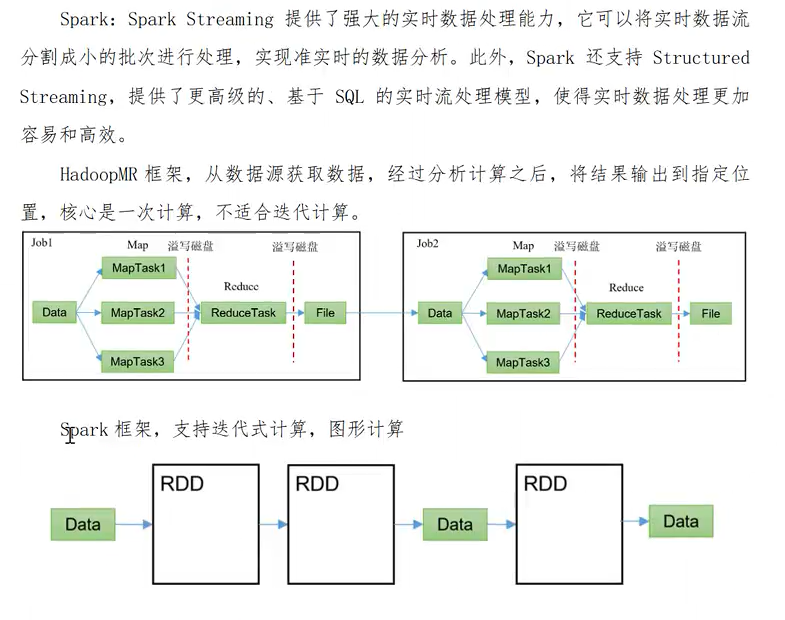


 二、处理速度
二、处理速度